 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReIn: Conversational Error Recovery with Reasoning Inception
Feb 19, 2026Conversational agents powered by large language models (LLMs) with tool integration achieve strong performance on fixed task-oriented dialogue datasets but remain vulnerable to unanticipated, user-induced errors. Rather than focusing on error prevention, this work focuses on error recovery, which necessitates the accurate diagnosis of erroneous dialogue contexts and execution of proper recovery plans. Under realistic constraints precluding model fine-tuning or prompt modification due to significant cost and time requirements, we explore whether agents can recover from contextually flawed interactions and how their behavior can be adapted without altering model parameters and prompts. To this end, we propose Reasoning Inception (ReIn), a test-time intervention method that plants an initial reasoning into the agent's decision-making process. Specifically, an external inception module identifies predefined errors within the dialogue context and generates recovery plans, which are subsequently integrated into the agent's internal reasoning process to guide corrective actions, without modifying its parameters or system prompts. We evaluate ReIn by systematically simulating conversational failure scenarios that directly hinder successful completion of user goals: user's ambiguous and unsupported requests. Across diverse combinations of agent models and inception modules, ReIn substantially improves task success and generalizes to unseen error types. Moreover, it consistently outperforms explicit prompt-modification approaches, underscoring its utility as an efficient, on-the-fly method. In-depth analysis of its operational mechanism, particularly in relation to instruction hierarchy, indicates that jointly defining recovery tools with ReIn can serve as a safe and effective strategy for improving the resilience of conversational agents without modifying the backbone models or system prompts.
Goal Alignment in LLM-Based User Simulators for Conversational AI
Jul 27, 2025



User simulators are essential to conversational AI, enabling scalable agent development and evaluation through simulated interactions. While current Large Language Models (LLMs) have advanced user simulation capabilities, we reveal that they struggle to consistently demonstrate goal-oriented behavior across multi-turn conversations--a critical limitation that compromises their reliability in downstream applications. We introduce User Goal State Tracking (UGST), a novel framework that tracks user goal progression throughout conversations. Leveraging UGST, we present a three-stage methodology for developing user simulators that can autonomously track goal progression and reason to generate goal-aligned responses. Moreover, we establish comprehensive evaluation metrics for measuring goal alignment in user simulators, and demonstrate that our approach yields substantial improvements across two benchmarks (MultiWOZ 2.4 and {\tau}-Bench). Our contributions address a critical gap in conversational AI and establish UGST as an essential framework for developing goal-aligned user simulators.
PIPA: A Unified Evaluation Protocol for Diagnosing Interactive Planning Agents
May 02, 2025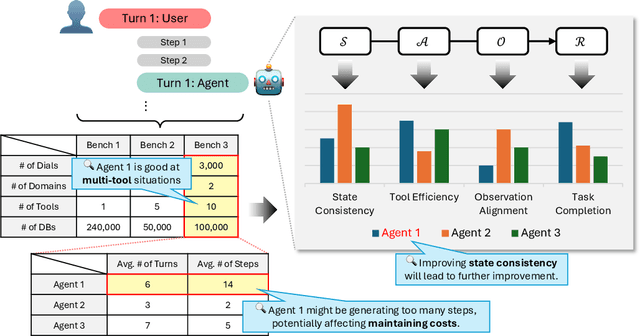

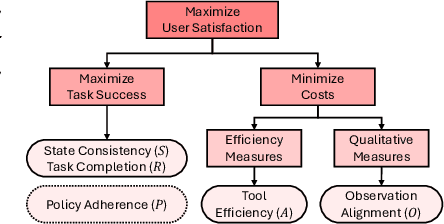

The growing capabilities of large language models (LLMs) in instruction-following and context-understanding lead to the era of agents with numerous applications. Among these, task planning agents have become especially prominent in realistic scenarios involving complex internal pipelines, such as context understanding, tool management, and response generation. However, existing benchmarks predominantly evaluate agent performance based on task completion as a proxy for overall effectiveness. We hypothesize that merely improving task completion is misaligned with maximizing user satisfaction, as users interact with the entire agentic process and not only the end result. To address this gap, we propose PIPA, a unified evaluation protocol that conceptualizes the behavioral process of interactive task planning agents within a partially observable Markov Decision Process (POMDP) paradigm. The proposed protocol offers a comprehensive assessment of agent performance through a set of atomic evaluation criteria, allowing researchers and practitioners to diagnose specific strengths and weaknesses within the agent's decision-making pipeline. Our analyses show that agents excel in different behavioral stages, with user satisfaction shaped by both outcomes and intermediate behaviors. We also highlight future directions, including systems that leverage multiple agents and the limitations of user simulators in task planning.
TD-EVAL: Revisiting Task-Oriented Dialogue Evaluation by Combining Turn-Level Precision with Dialogue-Level Comparisons
Apr 28, 2025
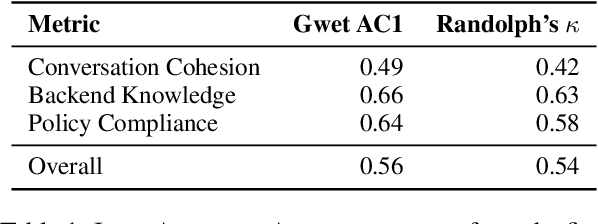
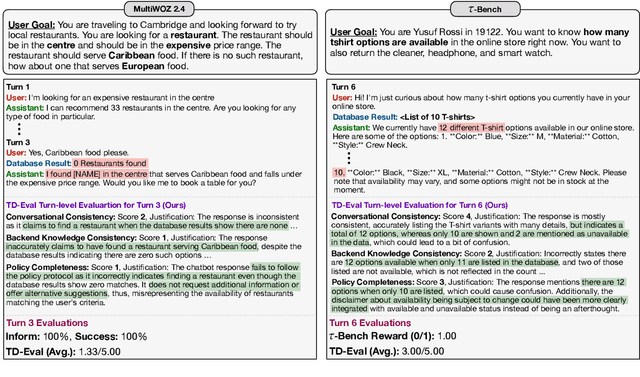
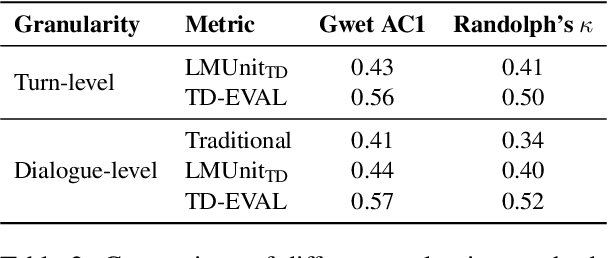
Task-oriented dialogue (TOD) systems are experiencing a revolution driven by Large Language Models (LLMs), yet the evaluation methodologies for these systems remain insufficient for their growing sophistication. While traditional automatic metrics effectively assessed earlier modular systems, they focus solely on the dialogue level and cannot detect critical intermediate errors that can arise during user-agent interactions. In this paper, we introduce TD-EVAL (Turn and Dialogue-level Evaluation), a two-step evaluation framework that unifies fine-grained turn-level analysis with holistic dialogue-level comparisons. At turn level, we evaluate each response along three TOD-specific dimensions: conversation cohesion, backend knowledge consistency, and policy compliance. Meanwhile, we design TOD Agent Arena that uses pairwise comparisons to provide a measure of dialogue-level quality. Through experiments on MultiWOZ 2.4 and {\tau}-Bench, we demonstrate that TD-EVAL effectively identifies the conversational errors that conventional metrics miss. Furthermore, TD-EVAL exhibits better alignment with human judgments than traditional and LLM-based metrics. These findings demonstrate that TD-EVAL introduces a new paradigm for TOD system evaluation, efficiently assessing both turn and system levels with a plug-and-play framework for future research.
Premise-Augmented Reasoning Chains Improve Error Identification in Math reasoning with LLMs
Feb 06, 2025



Chain-of-Thought (CoT) prompting enhances mathematical reasoning in large language models (LLMs) by enabling detailed step-by-step solutions. However, due to the verbosity of LLMs, the resulting reasoning chains can be long, making it harder to verify the reasoning steps and trace issues resulting from dependencies between the steps that may be farther away in the sequence of steps. Importantly, mathematical reasoning allows each step to be derived from a small set of premises, which are a subset of the preceding steps in the reasoning chain. In this paper, we present a framework that identifies the premises for each step, to improve the evaluation of reasoning. We restructure conventional linear reasoning chains into Premise Augmented Reasoning Chains (PARC) by introducing premise links, resulting in a directed acyclic graph where the nodes are the steps and the edges are the premise links. Through experiments with a PARC-based dataset that we built, namely PERL (Premises and ERrors identification in LLMs), we demonstrate that LLMs can reliably identify premises within complex reasoning chains. In particular, even open-source LLMs achieve 90% recall in premise identification. We also show that PARC helps to identify errors in reasoning chains more reliably. The accuracy of error identification improves by 6% to 16% absolute when step-by-step verification is carried out in PARC under the premises. Our findings highlight the utility of premise-centric representations in addressing complex problem-solving tasks and open new avenues for improving the reliability of LLM-based reasoning evaluations.
Learning to Explore and Select for Coverage-Conditioned Retrieval-Augmented Generation
Jul 01, 2024



Interactions with billion-scale large language models typically yield long-form responses due to their extensive parametric capacities, along with retrieval-augmented features. While detailed responses provide insightful viewpoint of a specific subject, they frequently generate redundant and less engaging content that does not meet user interests. In this work, we focus on the role of query outlining (i.e., selected sequence of queries) in scenarios that users request a specific range of information, namely coverage-conditioned ($C^2$) scenarios. For simulating $C^2$ scenarios, we construct QTree, 10K sets of information-seeking queries decomposed with various perspectives on certain topics. By utilizing QTree, we train QPlanner, a 7B language model generating customized query outlines that follow coverage-conditioned queries. We analyze the effectiveness of generated outlines through automatic and human evaluation, targeting on retrieval-augmented generation (RAG). Moreover, the experimental results demonstrate that QPlanner with alignment training can further provide outlines satisfying diverse user interests. Our resources are available at https://github.com/youngerous/qtree.
KoSBi: A Dataset for Mitigating Social Bias Risks Towards Safer Large Language Model Application
May 30, 2023



Large language models (LLMs) learn not only natural text generation abilities but also social biases against different demographic groups from real-world data. This poses a critical risk when deploying LLM-based applications. Existing research and resources are not readily applicable in South Korea due to the differences in language and culture, both of which significantly affect the biases and targeted demographic groups. This limitation requires localized social bias datasets to ensure the safe and effective deployment of LLMs. To this end, we present KO SB I, a new social bias dataset of 34k pairs of contexts and sentences in Korean covering 72 demographic groups in 15 categories. We find that through filtering-based moderation, social biases in generated content can be reduced by 16.47%p on average for HyperCLOVA (30B and 82B), and GPT-3.
SQuARe: A Large-Scale Dataset of Sensitive Questions and Acceptable Responses Created Through Human-Machine Collaboration
May 28, 2023



The potential social harms that large language models pose, such as generating offensive content and reinforcing biases, are steeply rising. Existing works focus on coping with this concern while interacting with ill-intentioned users, such as those who explicitly make hate speech or elicit harmful responses. However, discussions on sensitive issues can become toxic even if the users are well-intentioned. For safer models in such scenarios, we present the Sensitive Questions and Acceptable Response (SQuARe) dataset, a large-scale Korean dataset of 49k sensitive questions with 42k acceptable and 46k non-acceptable responses. The dataset was constructed leveraging HyperCLOVA in a human-in-the-loop manner based on real news headlines. Experiments show that acceptable response generation significantly improves for HyperCLOVA and GPT-3, demonstrating the efficacy of this dataset.
Revealing User Familiarity Bias in Task-Oriented Dialogue via Interactive Evaluation
May 23, 2023Most task-oriented dialogue (TOD) benchmarks assume users that know exactly how to use the system by constraining the user behaviors within the system's capabilities via strict user goals, namely "user familiarity" bias. This data bias deepens when it combines with data-driven TOD systems, as it is impossible to fathom the effect of it with existing static evaluations. Hence, we conduct an interactive user study to unveil how vulnerable TOD systems are against realistic scenarios. In particular, we compare users with 1) detailed goal instructions that conform to the system boundaries (closed-goal) and 2) vague goal instructions that are often unsupported but realistic (open-goal). Our study reveals that conversations in open-goal settings lead to catastrophic failures of the system, in which 92% of the dialogues had significant issues. Moreover, we conduct a thorough analysis to identify distinctive features between the two settings through error annotation. From this, we discover a novel "pretending" behavior, in which the system pretends to handle the user requests even though they are beyond the system's capabilities. We discuss its characteristics and toxicity while emphasizing transparency and a fallback strategy for robust TOD systems.
DSTEA: Dialogue State Tracking with Entity Adaptive Pre-training
Jul 08, 2022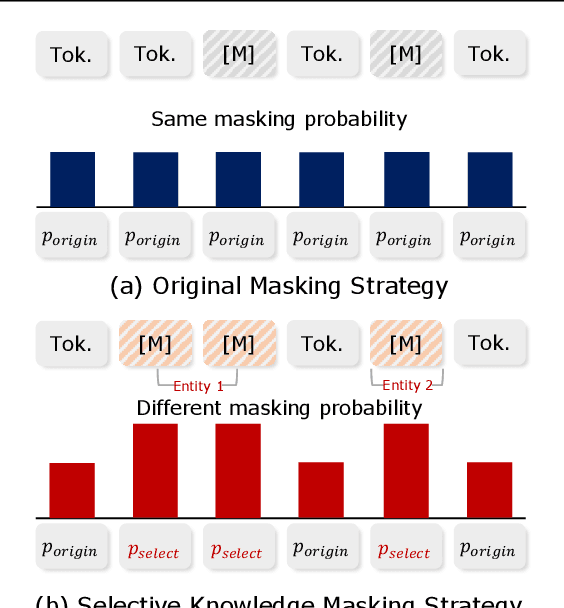
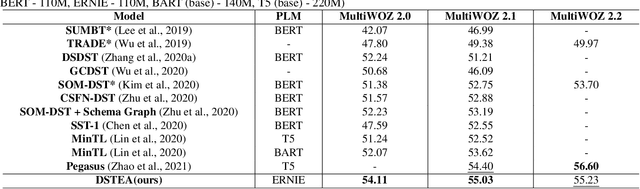
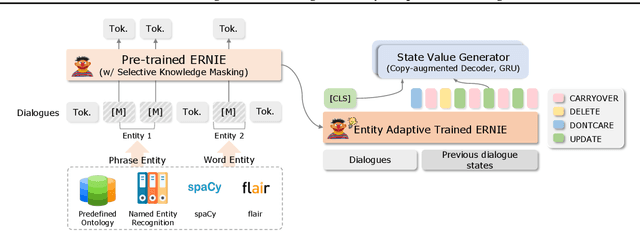
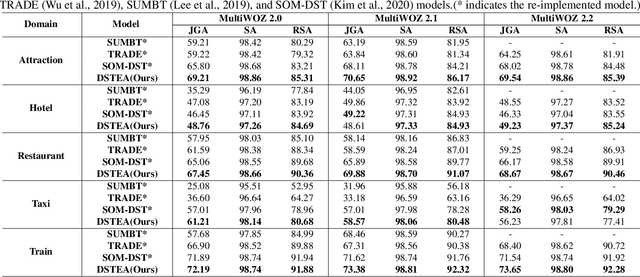
Dialogue state tracking (DST) is a core sub-module of a dialogue system, which aims to extract the appropriate belief state (domain-slot-value) from a system and user utterances. Most previous studies have attempted to improve performance by increasing the size of the pre-trained model or using additional features such as graph relations. In this study, we propose dialogue state tracking with entity adaptive pre-training (DSTEA), a system in which key entities in a sentence are more intensively trained by the encoder of the DST model. DSTEA extracts important entities from input dialogues in four ways, and then applies selective knowledge masking to train the model effectively. Although DSTEA conducts only pre-training without directly infusing additional knowledge to the DST model, it achieved better performance than the best-known benchmark models on MultiWOZ 2.0, 2.1, and 2.2. The effectiveness of DSTEA was verified through various comparative experiments with regard to the entity type and different adaptive settings.