 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Personalized Image Aesthetics Assessment with Rich Attributes
Mar 31, 2022

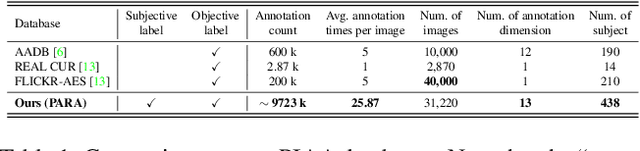
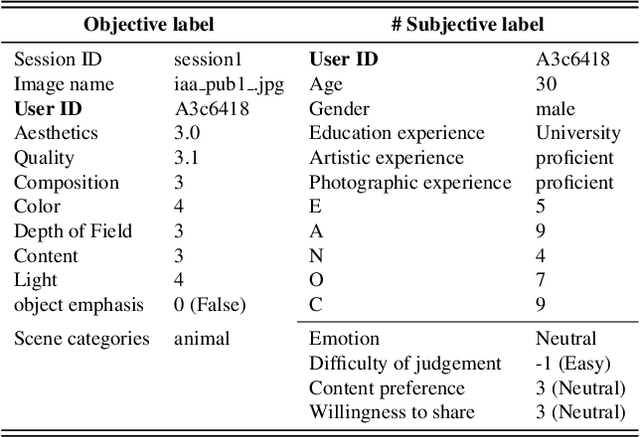
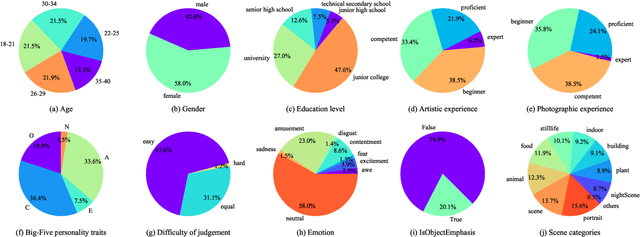
Personalized image aesthetics assessment (PIAA) is challenging due to its highly subjective nature. People's aesthetic tastes depend on diversified factors, including image characteristics and subject characters. The existing PIAA databases are limited in terms of annotation diversity, especially the subject aspect, which can no longer meet the increasing demands of PIAA research. To solve the dilemma, we conduct so far, the most comprehensive subjective study of personalized image aesthetics and introduce a new Personalized image Aesthetics database with Rich Attributes (PARA), which consists of 31,220 images with annotations by 438 subjects. PARA features wealthy annotations, including 9 image-oriented objective attributes and 4 human-oriented subjective attributes. In addition, desensitized subject information, such as personality traits, is also provided to support study of PIAA and user portraits. A comprehensive analysis of the annotation data is provided and statistic study indicates that the aesthetic preferences can be mirrored by proposed subjective attributes. We also propose a conditional PIAA model by utilizing subject information as conditional prior. Experimental results indicate that the conditional PIAA model can outperform the control group, which is also the first attempt to demonstrate how image aesthetics and subject characters interact to produce the intricate personalized tastes on image aesthetics. We believe the database and the associated analysis would be useful for conducting next-generation PIAA study. The project page of PARA can be found at: https://cv-datasets.institutecv.com/#/data-sets.
Learning Graph Regularisation for Guided Super-Resolution
Mar 27, 2022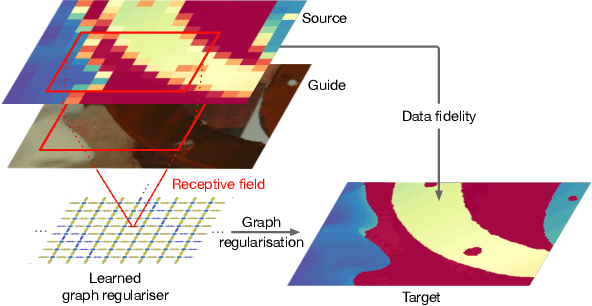
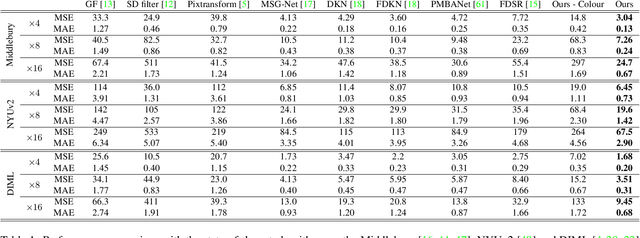
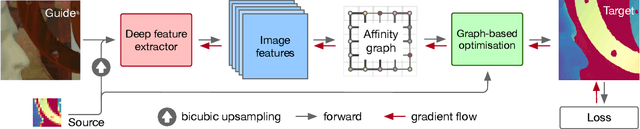

We introduce a novel formulation for guided super-resolution. Its core is a differentiable optimisation layer that operates on a learned affinity graph. The learned graph potentials make it possible to leverage rich contextual information from the guide image, while the explicit graph optimisation within the architecture guarantees rigorous fidelity of the high-resolution target to the low-resolution source. With the decision to employ the source as a constraint rather than only as an input to the prediction, our method differs from state-of-the-art deep architectures for guided super-resolution, which produce targets that, when downsampled, will only approximately reproduce the source. This is not only theoretically appealing, but also produces crisper, more natural-looking images. A key property of our method is that, although the graph connectivity is restricted to the pixel lattice, the associated edge potentials are learned with a deep feature extractor and can encode rich context information over large receptive fields. By taking advantage of the sparse graph connectivity, it becomes possible to propagate gradients through the optimisation layer and learn the edge potentials from data. We extensively evaluate our method on several datasets, and consistently outperform recent baselines in terms of quantitative reconstruction errors, while also delivering visually sharper outputs. Moreover, we demonstrate that our method generalises particularly well to new datasets not seen during training.
FERMI: Fair Empirical Risk Minimization via Exponential Rényi Mutual Information
Feb 24, 2021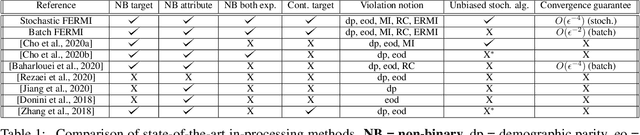
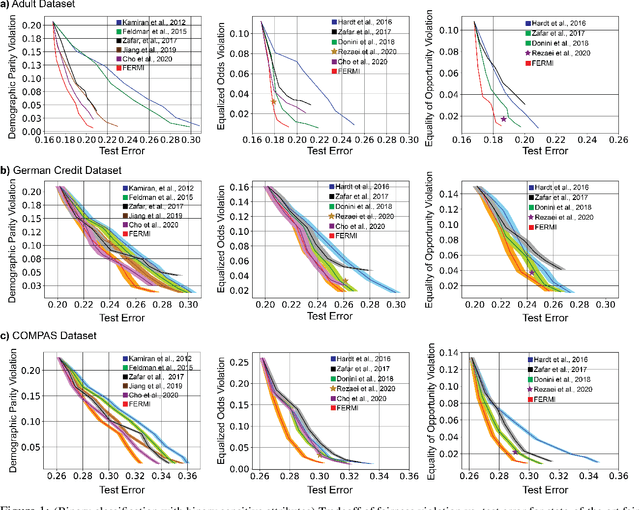
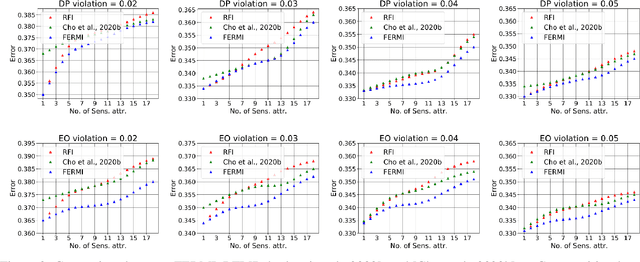
In this paper, we propose a new notion of fairness violation, called Exponential R\'enyi Mutual Information (ERMI). We show that ERMI is a strong fairness violation notion in the sense that it provides upper bound guarantees on existing notions of fairness violation. We then propose the Fair Empirical Risk Minimization via ERMI regularization framework, called FERMI. Whereas most existing in-processing fairness algorithms are deterministic, we provide the first stochastic optimization method with a provable convergence guarantee for solving FERMI. Our stochastic algorithm is amenable to large-scale problems, as we demonstrate experimentally. In addition, we provide a batch (deterministic) algorithm for solving FERMI with the optimal rate of convergence. Both of our algorithms are applicable to problems with multiple (non-binary) sensitive attributes and non-binary targets. Extensive experiments show that FERMI achieves the most favorable tradeoffs between fairness violation and test accuracy across various problem setups compared with state-of-the-art baselines.
A Unifying Multi-sampling-ratio CS-MRI Framework With Two-grid-cycle Correction and Geometric Prior Distillation
May 14, 2022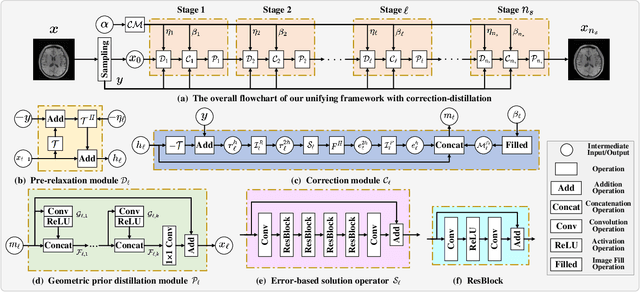
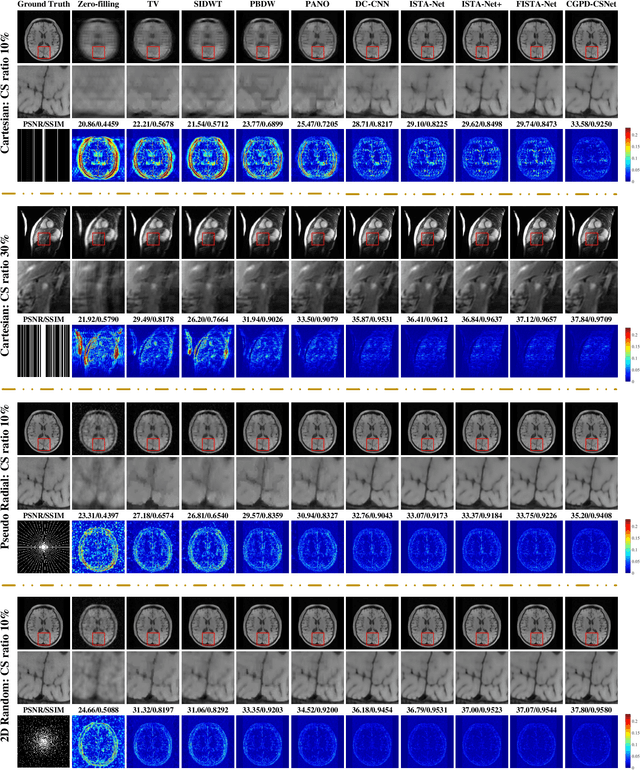
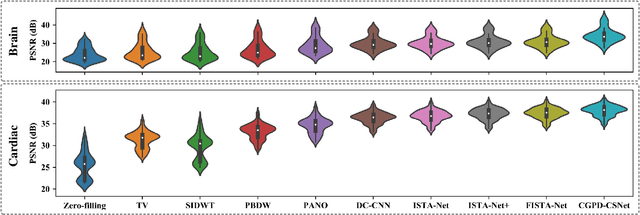

CS is an efficient method to accelerate the acquisition of MR images from under-sampled k-space data. Although existing deep learning CS-MRI methods have achieved considerably impressive performance, explainability and generalizability continue to be challenging for such methods since most of them are not flexible enough to handle multi-sampling-ratio reconstruction assignments, often the transition from mathematical analysis to network design not always natural enough. In this work, to tackle explainability and generalizability, we propose a unifying deep unfolding multi-sampling-ratio CS-MRI framework, by merging advantages of model-based and deep learning-based methods. The combined approach offers more generalizability than previous works whereas deep learning gains explainability through a geometric prior module. Inspired by multigrid algorithm, we first embed the CS-MRI-based optimization algorithm into correction-distillation scheme that consists of three ingredients: pre-relaxation module, correction module and geometric prior distillation module. Furthermore, we employ a condition module to learn adaptively step-length and noise level from compressive sampling ratio in every stage, which enables the proposed framework to jointly train multi-ratio tasks through a single model. The proposed model can not only compensate the lost contextual information of reconstructed image which is refined from low frequency error in geometric characteristic k-space, but also integrate the theoretical guarantee of model-based methods and the superior reconstruction performances of deep learning-based methods. All physical-model parameters are learnable, and numerical experiments show that our framework outperforms state-of-the-art methods in terms of qualitative and quantitative evaluations.
Divide and Conquer: Text Semantic Matching with Disentangled Keywords and Intents
Mar 06, 2022
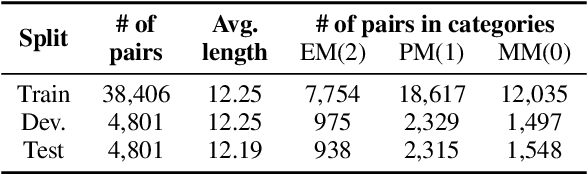
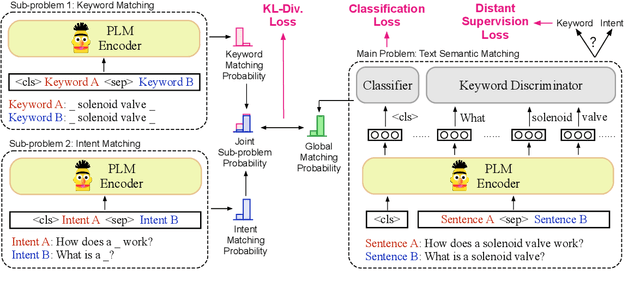
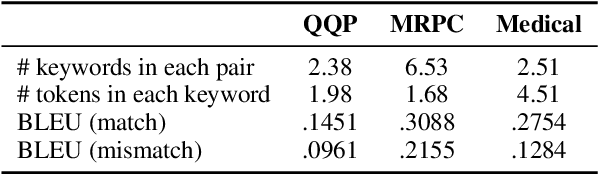
Text semantic matching is a fundamental task that has been widely used in various scenarios, such as community question answering, information retrieval, and recommendation. Most state-of-the-art matching models, e.g., BERT, directly perform text comparison by processing each word uniformly. However, a query sentence generally comprises content that calls for different levels of matching granularity. Specifically, keywords represent factual information such as action, entity, and event that should be strictly matched, while intents convey abstract concepts and ideas that can be paraphrased into various expressions. In this work, we propose a simple yet effective training strategy for text semantic matching in a divide-and-conquer manner by disentangling keywords from intents. Our approach can be easily combined with pre-trained language models (PLM) without influencing their inference efficiency, achieving stable performance improvements against a wide range of PLMs on three benchmarks.
Exploiting Embodied Simulation to Detect Novel Object Classes Through Interaction
Apr 17, 2022
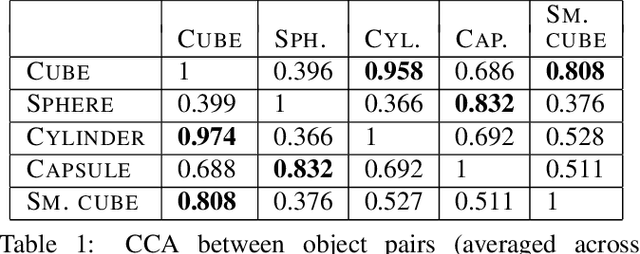
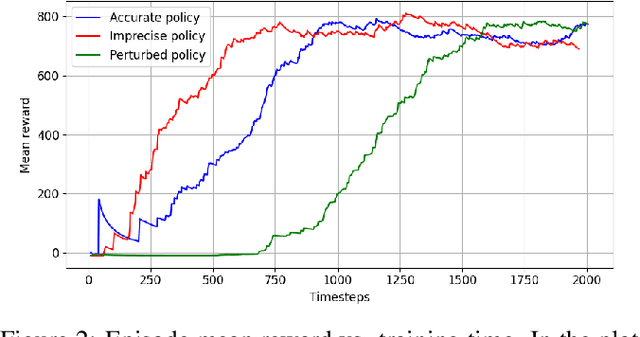

In this paper we present a novel method for a naive agent to detect novel objects it encounters in an interaction. We train a reinforcement learning policy on a stacking task given a known object type, and then observe the results of the agent attempting to stack various other objects based on the same trained policy. By extracting embedding vectors from a convolutional neural net trained over the results of the aforementioned stacking play, we can determine the similarity of a given object to known object types, and determine if the given object is likely dissimilar enough to the known types to be considered a novel class of object. We present the results of this method on two datasets gathered using two different policies and demonstrate what information the agent needs to extract from its environment to make these novelty judgments.
Anomaly Detection by Leveraging Incomplete Anomalous Knowledge with Anomaly-Aware Bidirectional GANs
May 01, 2022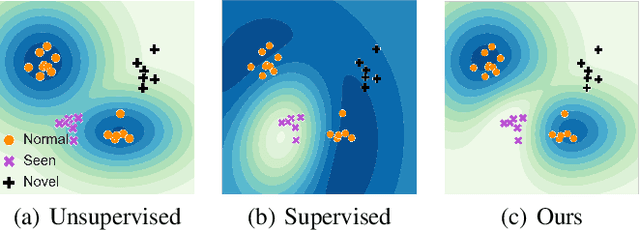
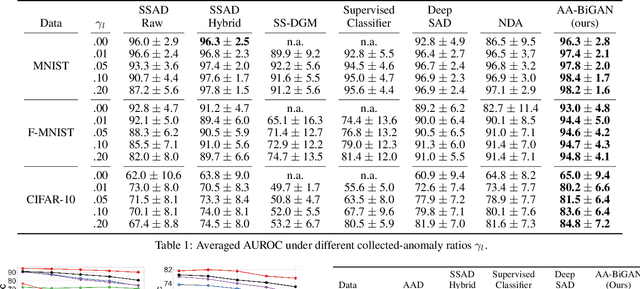
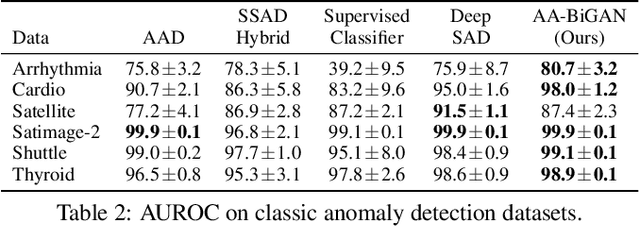
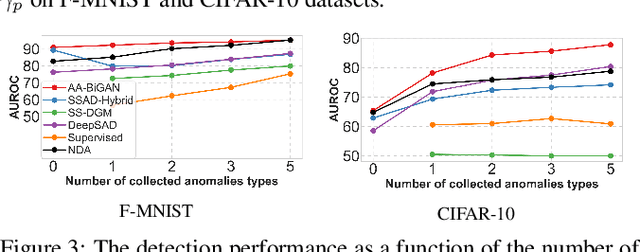
The goal of anomaly detection is to identify anomalous samples from normal ones. In this paper, a small number of anomalies are assumed to be available at the training stage, but they are assumed to be collected only from several anomaly types, leaving the majority of anomaly types not represented in the collected anomaly dataset at all. To effectively leverage this kind of incomplete anomalous knowledge represented by the collected anomalies, we propose to learn a probability distribution that can not only model the normal samples, but also guarantee to assign low density values for the collected anomalies. To this end, an anomaly-aware generative adversarial network (GAN) is developed, which, in addition to modeling the normal samples as most GANs do, is able to explicitly avoid assigning probabilities for collected anomalous samples. Moreover, to facilitate the computation of anomaly detection criteria like reconstruction error, the proposed anomaly-aware GAN is designed to be bidirectional, attaching an encoder for the generator. Extensive experimental results demonstrate that our proposed method is able to effectively make use of the incomplete anomalous information, leading to significant performance gains compared to existing methods.
Detecting early signs of depression in the conversational domain: The role of transfer learning in low-resource scenarios
Apr 22, 2022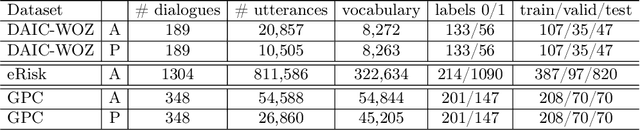
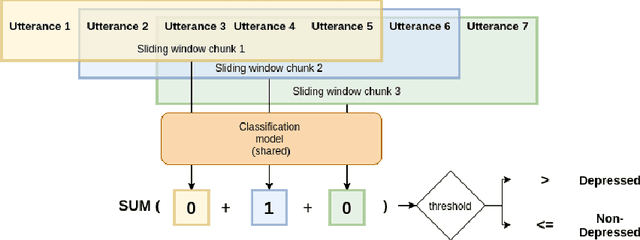
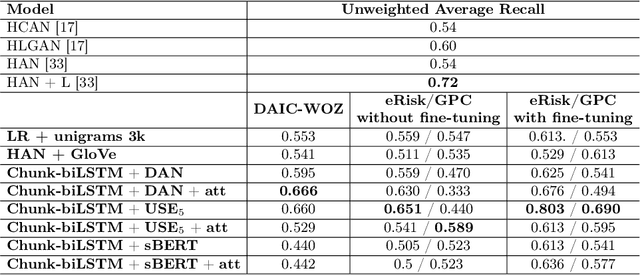

The high prevalence of depression in society has given rise to the need for new digital tools to assist in its early detection. To this end, existing research has mainly focused on detecting depression in the domain of social media, where there is a sufficient amount of data. However, with the rise of conversational agents like Siri or Alexa, the conversational domain is becoming more critical. Unfortunately, there is a lack of data in the conversational domain. We perform a study focusing on domain adaptation from social media to the conversational domain. Our approach mainly exploits the linguistic information preserved in the vector representation of text. We describe transfer learning techniques to classify users who suffer from early signs of depression with high recall. We achieve state-of-the-art results on a commonly used conversational dataset, and we highlight how the method can easily be used in conversational agents. We publicly release all source code.
Learning to Adapt Clinical Sequences with Residual Mixture of Experts
Apr 06, 2022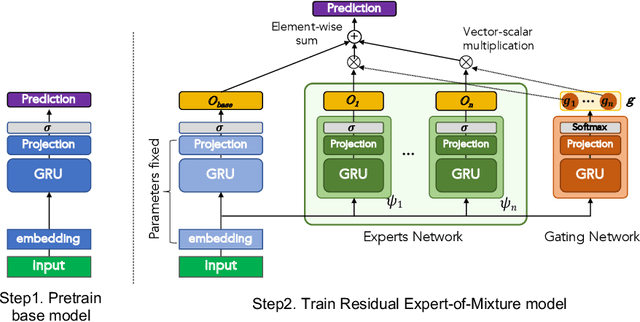

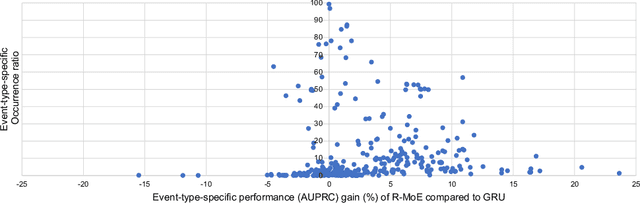
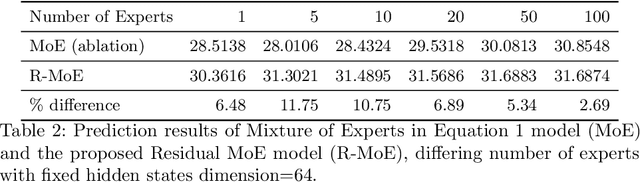
Clinical event sequences in Electronic Health Records (EHRs) record detailed information about the patient condition and patient care as they occur in time. Recent years have witnessed increased interest of machine learning community in developing machine learning models solving different types of problems defined upon information in EHRs. More recently, neural sequential models, such as RNN and LSTM, became popular and widely applied models for representing patient sequence data and for predicting future events or outcomes based on such data. However, a single neural sequential model may not properly represent complex dynamics of all patients and the differences in their behaviors. In this work, we aim to alleviate this limitation by refining a one-fits-all model using a Mixture-of-Experts (MoE) architecture. The architecture consists of multiple (expert) RNN models covering patient sub-populations and refining the predictions of the base model. That is, instead of training expert RNN models from scratch we define them on the residual signal that attempts to model the differences from the population-wide model. The heterogeneity of various patient sequences is modeled through multiple experts that consist of RNN. Particularly, instead of directly training MoE from scratch, we augment MoE based on the prediction signal from pretrained base GRU model. With this way, the mixture of experts can provide flexible adaptation to the (limited) predictive power of the single base RNN model. We experiment with the newly proposed model on real-world EHRs data and the multivariate clinical event prediction task. We implement RNN using Gated Recurrent Units (GRU). We show 4.1% gain on AUPRC statistics compared to a single RNN prediction.
Price graphs: Utilizing the structural information of financial time series for stock prediction
Jun 04, 2021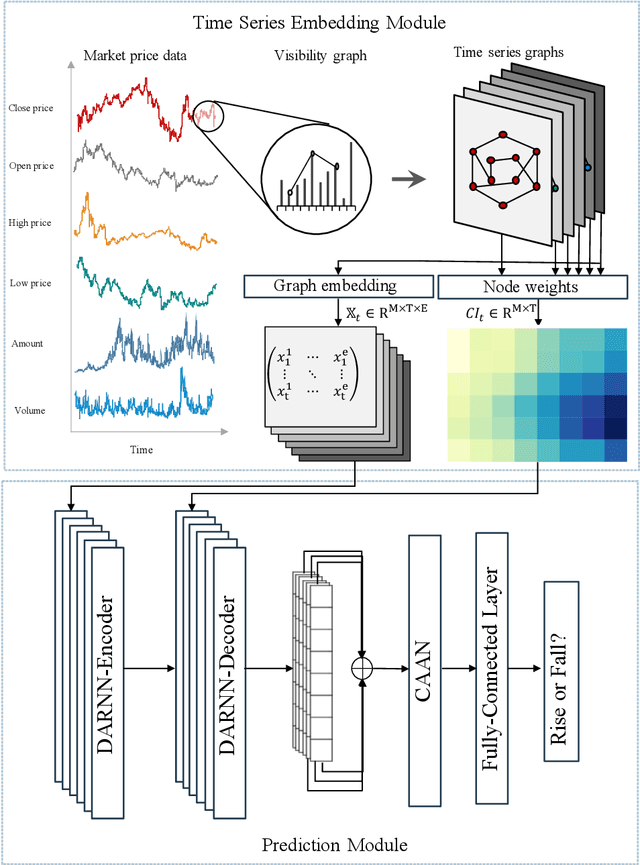
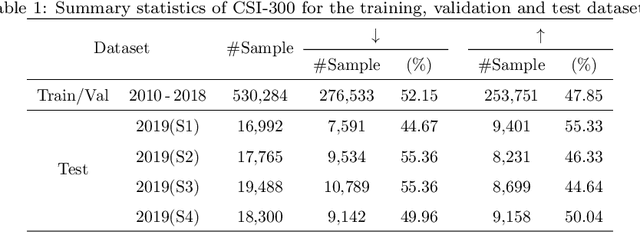
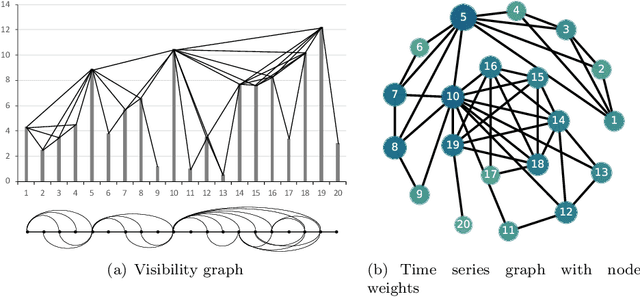
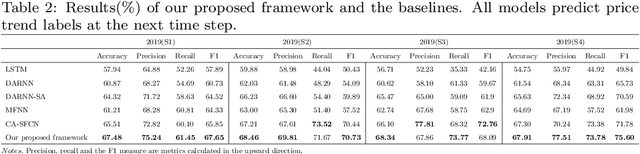
Stock prediction, with the purpose of forecasting the future price trends of stocks, is crucial for maximizing profits from stock investments. While great research efforts have been devoted to exploiting deep neural networks for improved stock prediction, the existing studies still suffer from two major issues. First, the long-range dependencies in time series are not sufficiently captured. Second, the chaotic property of financial time series fundamentally lowers prediction performance. In this study, we propose a novel framework to address both issues regarding stock prediction. Specifically, in terms of transforming time series into complex networks, we convert market price series into graphs. Then, structural information, referring to associations among temporal points and the node weights, is extracted from the mapped graphs to resolve the problems regarding long-range dependencies and the chaotic property. We take graph embeddings to represent the associations among temporal points as the prediction model inputs. Node weights are used as a priori knowledge to enhance the learning of temporal attention. The effectiveness of our proposed framework is validated using real-world stock data, and our approach obtains the best performance among several state-of-the-art benchmarks. Moreover, in the conducted trading simulations, our framework further obtains the highest cumulative profits. Our results supplement the existing applications of complex network methods in the financial realm and provide insightful implications for investment applications regarding decision support in financial markets.