 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep 360$^\circ$ Optical Flow Estimation Based on Multi-Projection Fusion
Jul 27, 2022
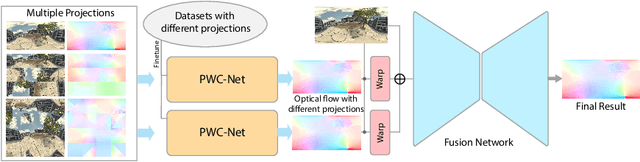


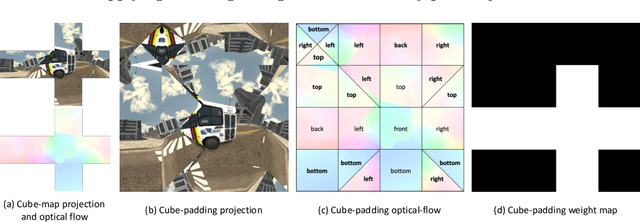
Optical flow computation is essential in the early stages of the video processing pipeline. This paper focuses on a less explored problem in this area, the 360$^\circ$ optical flow estimation using deep neural networks to support increasingly popular VR applications. To address the distortions of panoramic representations when applying convolutional neural networks, we propose a novel multi-projection fusion framework that fuses the optical flow predicted by the models trained using different projection methods. It learns to combine the complementary information in the optical flow results under different projections. We also build the first large-scale panoramic optical flow dataset to support the training of neural networks and the evaluation of panoramic optical flow estimation methods. The experimental results on our dataset demonstrate that our method outperforms the existing methods and other alternative deep networks that were developed for processing 360{\deg} content.
Transformers as Meta-Learners for Implicit Neural Representations
Aug 05, 2022



Implicit Neural Representations (INRs) have emerged and shown their benefits over discrete representations in recent years. However, fitting an INR to the given observations usually requires optimization with gradient descent from scratch, which is inefficient and does not generalize well with sparse observations. To address this problem, most of the prior works train a hypernetwork that generates a single vector to modulate the INR weights, where the single vector becomes an information bottleneck that limits the reconstruction precision of the output INR. Recent work shows that the whole set of weights in INR can be precisely inferred without the single-vector bottleneck by gradient-based meta-learning. Motivated by a generalized formulation of gradient-based meta-learning, we propose a formulation that uses Transformers as hypernetworks for INRs, where it can directly build the whole set of INR weights with Transformers specialized as set-to-set mapping. We demonstrate the effectiveness of our method for building INRs in different tasks and domains, including 2D image regression and view synthesis for 3D objects. Our work draws connections between the Transformer hypernetworks and gradient-based meta-learning algorithms and we provide further analysis for understanding the generated INRs.
Low-data? No problem: low-resource, language-agnostic conversational text-to-speech via F0-conditioned data augmentation
Jul 29, 2022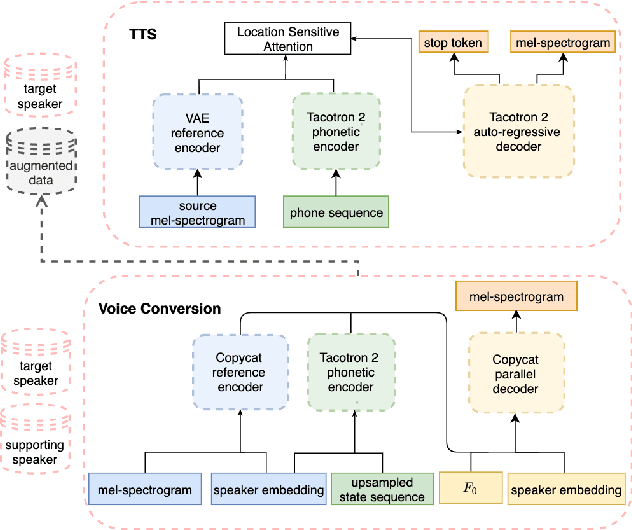

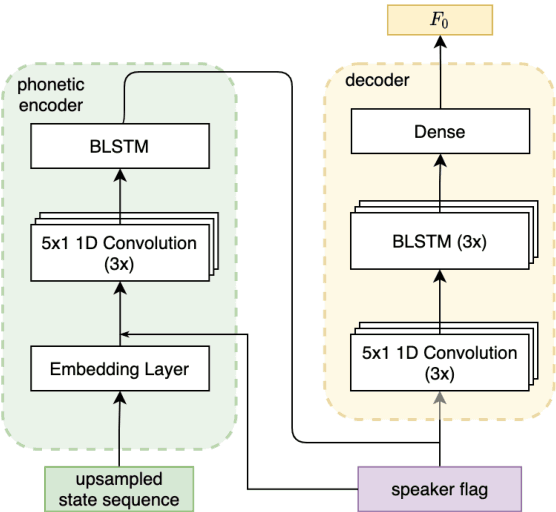
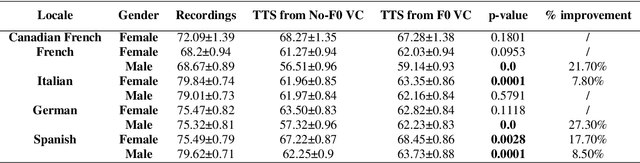
The availability of data in expressive styles across languages is limited, and recording sessions are costly and time consuming. To overcome these issues, we demonstrate how to build low-resource, neural text-to-speech (TTS) voices with only 1 hour of conversational speech, when no other conversational data are available in the same language. Assuming the availability of non-expressive speech data in that language, we propose a 3-step technology: 1) we train an F0-conditioned voice conversion (VC) model as data augmentation technique; 2) we train an F0 predictor to control the conversational flavour of the voice-converted synthetic data; 3) we train a TTS system that consumes the augmented data. We prove that our technology enables F0 controllability, is scalable across speakers and languages and is competitive in terms of naturalness over a state-of-the-art baseline model, another augmented method which does not make use of F0 information.
A Modified PINN Approach for Identifiable Compartmental Models in Epidemiology with Applications to COVID-19
Aug 01, 2022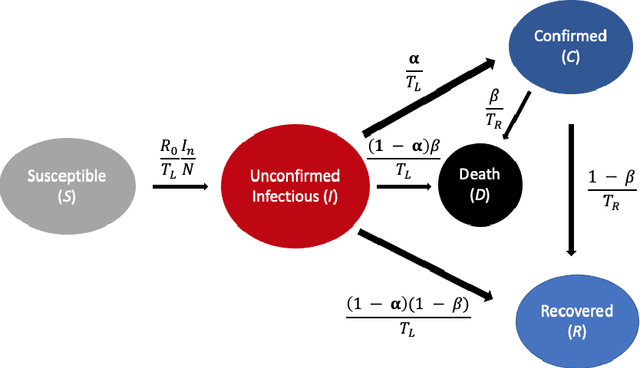

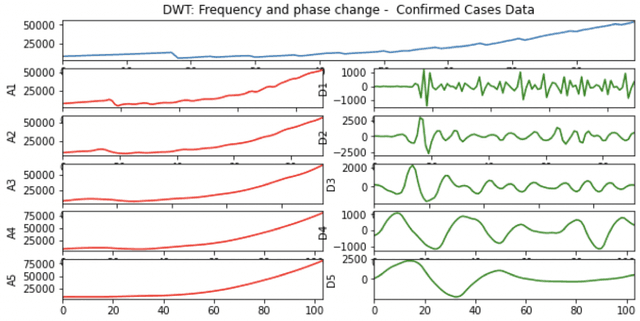
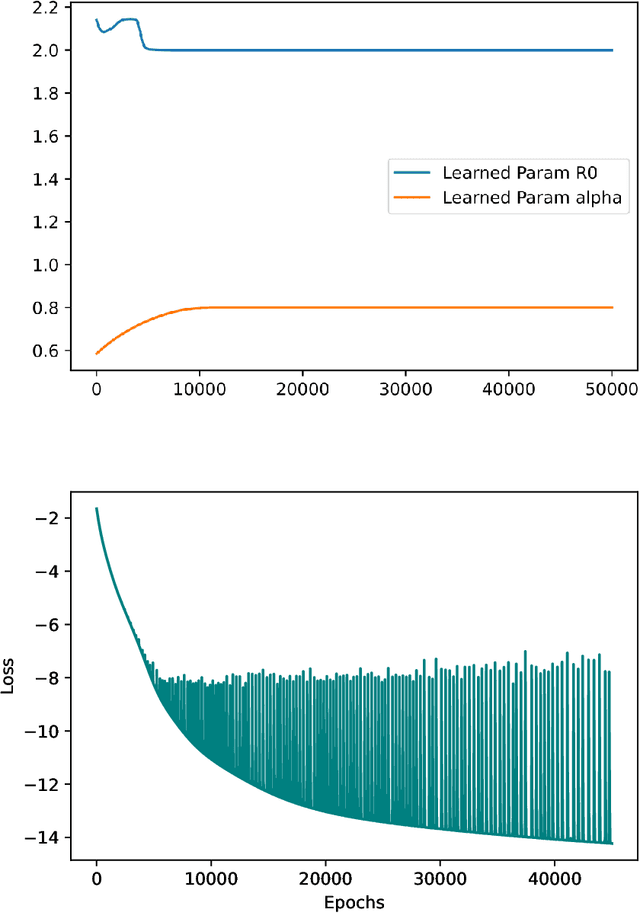
A variety of approaches using compartmental models have been used to study the COVID-19 pandemic and the usage of machine learning methods with these models has had particularly notable success. We present here an approach toward analyzing accessible data on Covid-19's U.S. development using a variation of the "Physics Informed Neural Networks" (PINN) which is capable of using the knowledge of the model to aid learning. We illustrate the challenges of using the standard PINN approach, then how with appropriate and novel modifications to the loss function the network can perform well even in our case of incomplete information. Aspects of identifiability of the model parameters are also assessed, as well as methods of denoising available data using a wavelet transform. Finally, we discuss the capability of the neural network methodology to work with models of varying parameter values, as well as a concrete application in estimating how effectively cases are being tested for in a population, providing a ranking of U.S. states by means of their respective testing.
Environment Sensing Considering the Occlusion Effect: A Multi-View Approach
Jul 02, 2022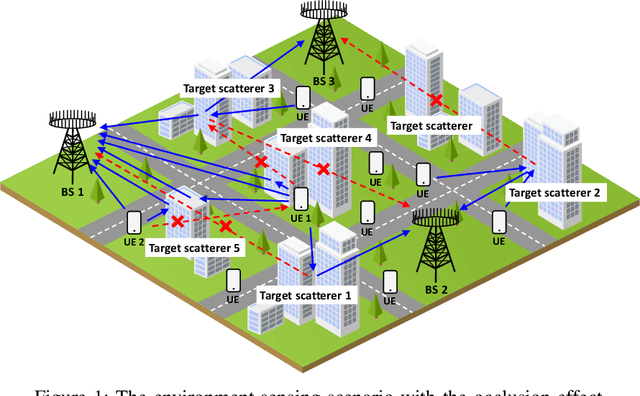
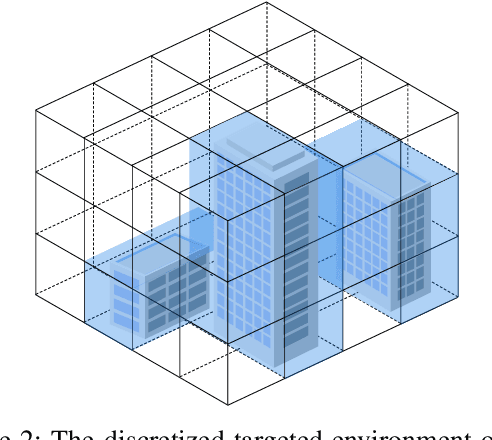
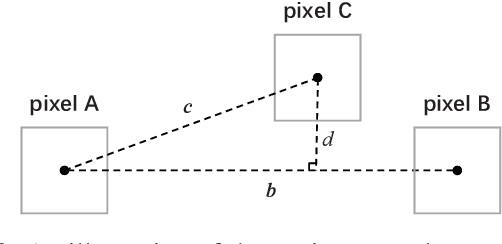
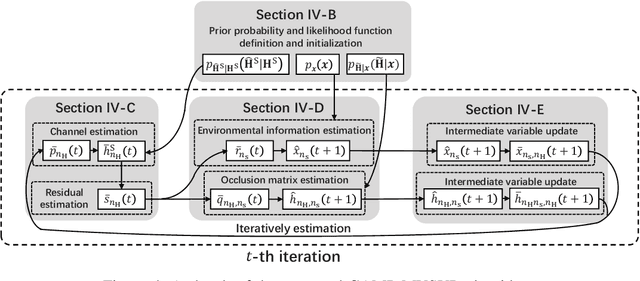
In this paper, we consider the problem of sensing the environment within a wireless cellular framework. Specifically, multiple user equipments (UEs) send sounding signals to one or multiple base stations (BSs) and then a centralized processor retrieves the environmental information from all the channel information obtained at the BS(s). Taking into account the occlusion effect that is common in the wireless context, we make full use of the different views of the environment from different users and/or BS(s), and propose an effective sensing algorithm called GAMP-MVSVR (generalized-approximate-message-passing-based multi-view sparse vector reconstruction). In the proposed algorithm, a multi-layer factor graph is constructed to iteratively estimate the scattering coefficients of the cloud points and their occlusion relationship. In each iteration, the occlusion relationship between the cloud points of the sparse environment is recalculated according to a simple occlusion detection rule, and in turn, used to estimate the scattering coefficients of the cloud points. Our proposed algorithm can achieve improved sensing performance with multi-BS collaboration in addition to the multi-views from the UEs. The simulation results verify its convergence and effectiveness.
* Paper accepted for publication on IEEE Transactions on Signal Processing
Invariance Principle Meets Information Bottleneck for Out-of-Distribution Generalization
Jun 11, 2021
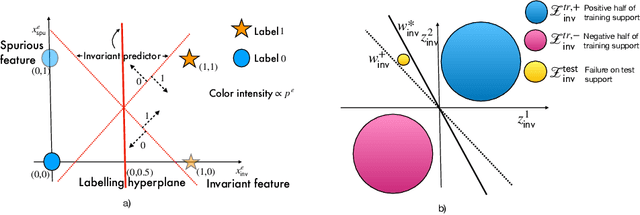

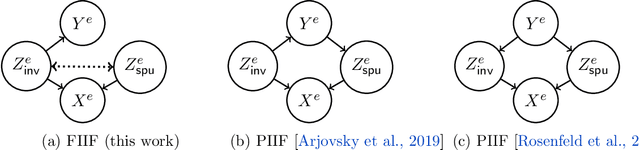
The invariance principle from causality is at the heart of notable approaches such as invariant risk minimization (IRM) that seek to address out-of-distribution (OOD) generalization failures. Despite the promising theory, invariance principle-based approaches fail in common classification tasks, where invariant (causal) features capture all the information about the label. Are these failures due to the methods failing to capture the invariance? Or is the invariance principle itself insufficient? To answer these questions, we revisit the fundamental assumptions in linear regression tasks, where invariance-based approaches were shown to provably generalize OOD. In contrast to the linear regression tasks, we show that for linear classification tasks we need much stronger restrictions on the distribution shifts, or otherwise OOD generalization is impossible. Furthermore, even with appropriate restrictions on distribution shifts in place, we show that the invariance principle alone is insufficient. We prove that a form of the information bottleneck constraint along with invariance helps address key failures when invariant features capture all the information about the label and also retains the existing success when they do not. We propose an approach that incorporates both of these principles and demonstrate its effectiveness in several experiments.
Language Models as Knowledge Embeddings
Jun 25, 2022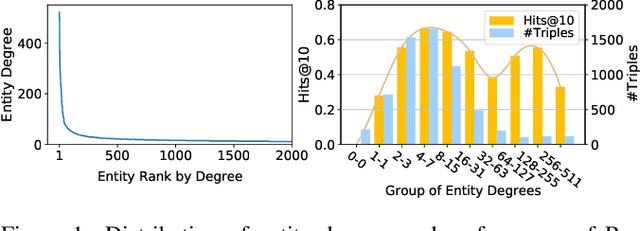
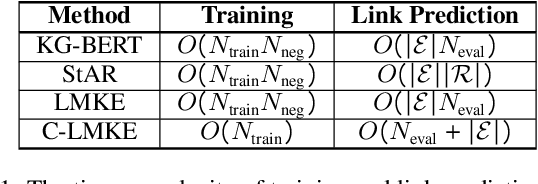
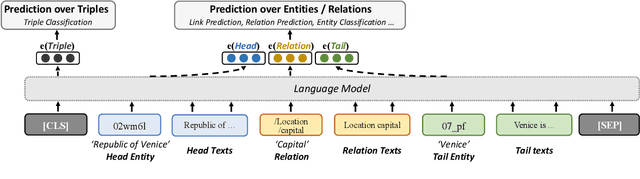
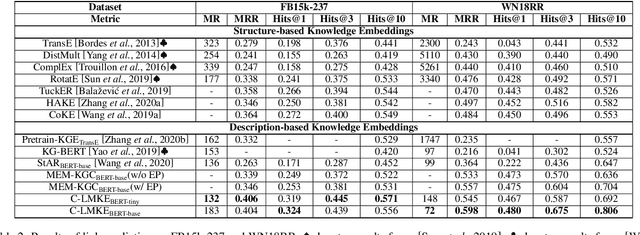
Knowledge embeddings (KE) represent a knowledge graph (KG) by embedding entities and relations into continuous vector spaces. Existing methods are mainly structure-based or description-based. Structure-based methods learn representations that preserve the inherent structure of KGs. They cannot well represent abundant long-tail entities in real-world KGs with limited structural information. Description-based methods leverage textual information and language models. Prior approaches in this direction barely outperform structure-based ones, and suffer from problems like expensive negative sampling and restrictive description demand. In this paper, we propose LMKE, which adopts Language Models to derive Knowledge Embeddings, aiming at both enriching representations of long-tail entities and solving problems of prior description-based methods. We formulate description-based KE learning with a contrastive learning framework to improve efficiency in training and evaluation. Experimental results show that LMKE achieves state-of-the-art performance on KE benchmarks of link prediction and triple classification, especially for long-tail entities.
Entity Type Prediction Leveraging Graph Walks and Entity Descriptions
Jul 29, 2022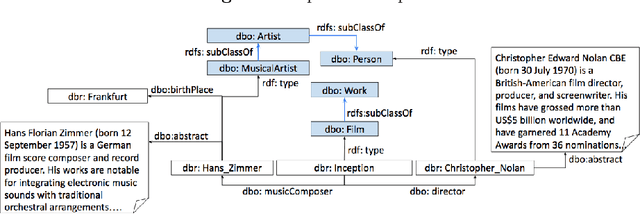
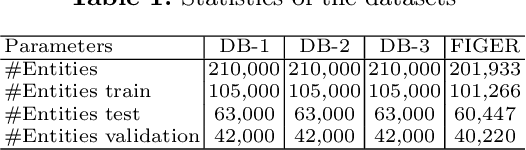
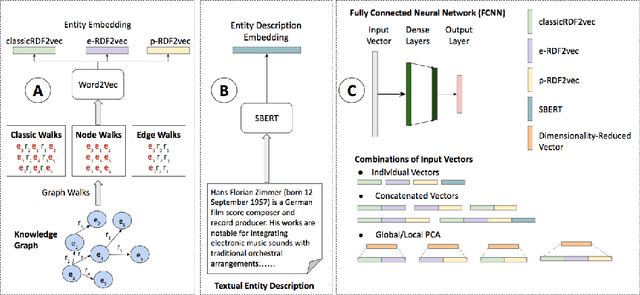
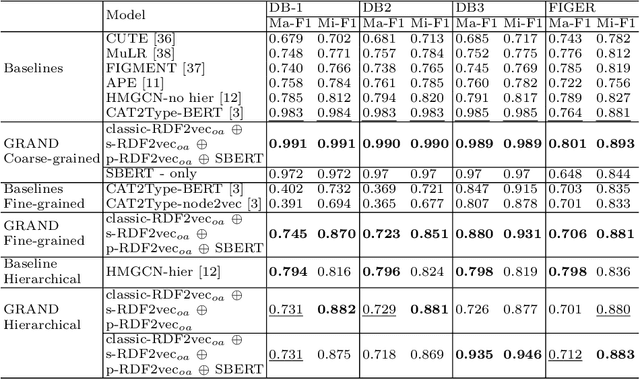
The entity type information in Knowledge Graphs (KGs) such as DBpedia, Freebase, etc. is often incomplete due to automated generation or human curation. Entity typing is the task of assigning or inferring the semantic type of an entity in a KG. This paper presents \textit{GRAND}, a novel approach for entity typing leveraging different graph walk strategies in RDF2vec together with textual entity descriptions. RDF2vec first generates graph walks and then uses a language model to obtain embeddings for each node in the graph. This study shows that the walk generation strategy and the embedding model have a significant effect on the performance of the entity typing task. The proposed approach outperforms the baseline approaches on the benchmark datasets DBpedia and FIGER for entity typing in KGs for both fine-grained and coarse-grained classes. The results show that the combination of order-aware RDF2vec variants together with the contextual embeddings of the textual entity descriptions achieve the best results.
Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
Jun 23, 2022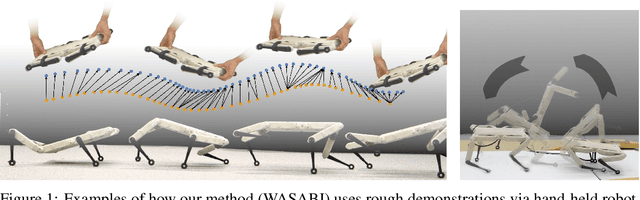

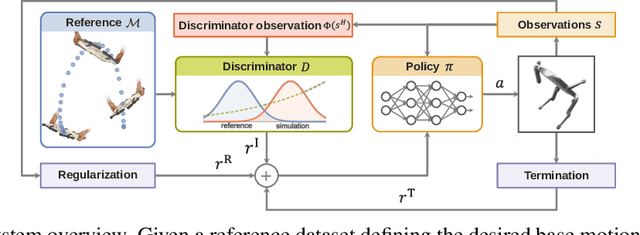

Learning agile skills is one of the main challenges in robotics. To this end, reinforcement learning approaches have achieved impressive results. These methods require explicit task information in terms of a reward function or an expert that can be queried in simulation to provide a target control output, which limits their applicability. In this work, we propose a generative adversarial method for inferring reward functions from partial and potentially physically incompatible demonstrations for successful skill acquirement where reference or expert demonstrations are not easily accessible. Moreover, we show that by using a Wasserstein GAN formulation and transitions from demonstrations with rough and partial information as input, we are able to extract policies that are robust and capable of imitating demonstrated behaviors. Finally, the obtained skills such as a backflip are tested on an agile quadruped robot called Solo 8 and present faithful replication of hand-held human demonstrations.
Open-Vocabulary Multi-Label Classification via Multi-modal Knowledge Transfer
Jul 05, 2022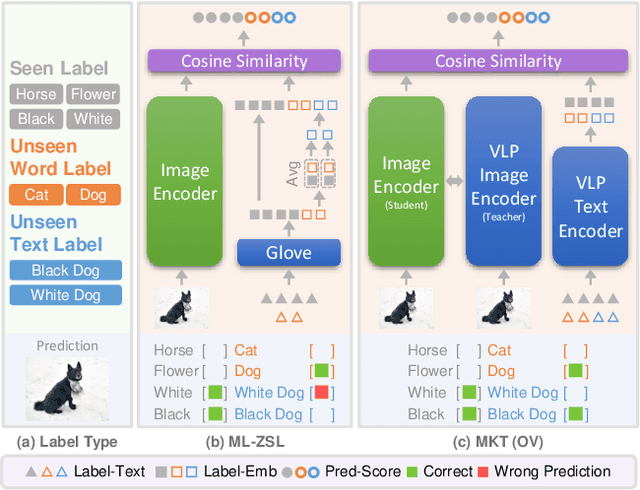



Real-world recognition system often encounters a plenty of unseen labels in practice. To identify such unseen labels, multi-label zero-shot learning (ML-ZSL) focuses on transferring knowledge by a pre-trained textual label embedding (e.g., GloVe). However, such methods only exploit singlemodal knowledge from a language model, while ignoring the rich semantic information inherent in image-text pairs. Instead, recently developed open-vocabulary (OV) based methods succeed in exploiting such information of image-text pairs in object detection, and achieve impressive performance. Inspired by the success of OV-based methods, we propose a novel open-vocabulary framework, named multimodal knowledge transfer (MKT), for multi-label classification. Specifically, our method exploits multi-modal knowledge of image-text pairs based on a vision and language pretraining (VLP) model. To facilitate transferring the imagetext matching ability of VLP model, knowledge distillation is used to guarantee the consistency of image and label embeddings, along with prompt tuning to further update the label embeddings. To further recognize multiple objects, a simple but effective two-stream module is developed to capture both local and global features. Extensive experimental results show that our method significantly outperforms state-of-theart methods on public benchmark datasets. Code will be available at https://github.com/seanhe97/MKT.