 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Needs Labels? Adapting Vision Foundation Models With the Metadata You Already Have
Jun 03, 2026We propose a label-free approach to adapt powerful but generic vision foundation models to specialized scientific domains. Standard supervised fine-tuning is often ill-suited to these settings: labels are scarce, and task-specific training can collapse the model's generality and hurt robustness. We instead leverage metadata to adapt representations to new domains in a self-supervised manner. Our method, FINO, combines a standard self-supervised objective with flexible metadata guidance that handles both highly granular discrete metadata and continuous metadata. It encourages the representation to preserve informative factors while suppressing spurious ones. Across subcellular fluorescence microscopy, Earth observation, wildlife monitoring, and medical imaging, FINO consistently outperforms standard unsupervised domain adaptation and fully supervised adaptation. It also exceeds highly-specialized domain-specific state of the art, while using no task labels for backbone adaptation and only lightweight probes for supervision.
ReasonCACHE: Teaching LLMs To Reason Without Weight Updates
Feb 02, 2026Can Large language models (LLMs) learn to reason without any weight update and only through in-context learning (ICL)? ICL is strikingly sample-efficient, often learning from only a handful of demonstrations, but complex reasoning tasks typically demand many training examples to learn from. However, naively scaling ICL by adding more demonstrations breaks down at this scale: attention costs grow quadratically, performance saturates or degrades with longer contexts, and the approach remains a shallow form of learning. Due to these limitations, practitioners predominantly rely on in-weight learning (IWL) to induce reasoning. In this work, we show that by using Prefix Tuning, LLMs can learn to reason without overloading the context window and without any weight updates. We introduce $\textbf{ReasonCACHE}$, an instantiation of this mechanism that distills demonstrations into a fixed key-value cache. Empirically, across challenging reasoning benchmarks, including GPQA-Diamond, ReasonCACHE outperforms standard ICL and matches or surpasses IWL approaches. Further, it achieves this all while being more efficient across three key axes: data, inference cost, and trainable parameters. We also theoretically prove that ReasonCACHE can be strictly more expressive than low-rank weight update since the latter ties expressivity to input rank, whereas ReasonCACHE bypasses this constraint by directly injecting key-values into the attention mechanism. Together, our findings identify ReasonCACHE as a middle path between in-context and in-weight learning, providing a scalable algorithm for learning reasoning skills beyond the context window without modifying parameters. Our project page: https://reasoncache.github.io/
Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability
Jan 26, 2026Can a model learn to escape its own learning plateau? Reinforcement learning methods for finetuning large reasoning models stall on datasets with low initial success rates, and thus little training signal. We investigate a fundamental question: Can a pretrained LLM leverage latent knowledge to generate an automated curriculum for problems it cannot solve? To explore this, we design SOAR: A self-improvement framework designed to surface these pedagogical signals through meta-RL. A teacher copy of the model proposes synthetic problems for a student copy, and is rewarded with its improvement on a small subset of hard problems. Critically, SOAR grounds the curriculum in measured student progress rather than intrinsic proxy rewards. Our study on the hardest subsets of mathematical benchmarks (0/128 success) reveals three core findings. First, we show that it is possible to realize bi-level meta-RL that unlocks learning under sparse, binary rewards by sharpening a latent capacity of pretrained models to generate useful stepping stones. Second, grounded rewards outperform intrinsic reward schemes used in prior LLM self-play, reliably avoiding the instability and diversity collapse modes they typically exhibit. Third, analyzing the generated questions reveals that structural quality and well-posedness are more critical for learning progress than solution correctness. Our results suggest that the ability to generate useful stepping stones does not require the preexisting ability to actually solve the hard problems, paving a principled path to escape reasoning plateaus without additional curated data.
Compositional Risk Minimization
Oct 08, 2024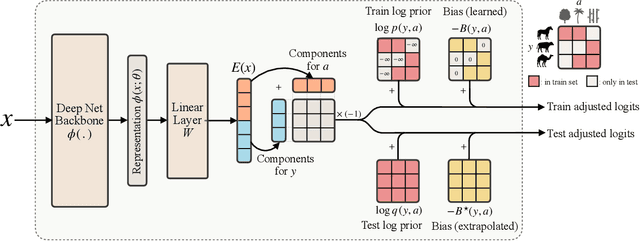


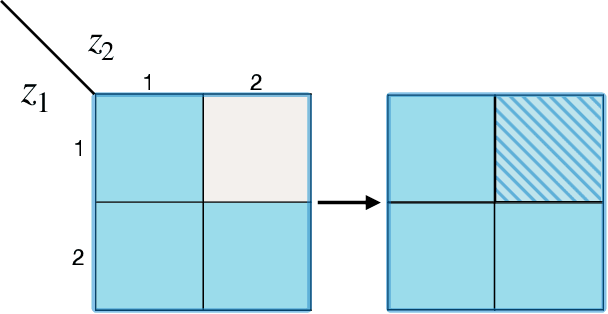
In this work, we tackle a challenging and extreme form of subpopulation shift, which is termed compositional shift. Under compositional shifts, some combinations of attributes are totally absent from the training distribution but present in the test distribution. We model the data with flexible additive energy distributions, where each energy term represents an attribute, and derive a simple alternative to empirical risk minimization termed compositional risk minimization (CRM). We first train an additive energy classifier to predict the multiple attributes and then adjust this classifier to tackle compositional shifts. We provide an extensive theoretical analysis of CRM, where we show that our proposal extrapolates to special affine hulls of seen attribute combinations. Empirical evaluations on benchmark datasets confirms the improved robustness of CRM compared to other methods from the literature designed to tackle various forms of subpopulation shifts.
Robust Data Pruning: Uncovering and Overcoming Implicit Bias
Apr 08, 2024



In the era of exceptionally data-hungry models, careful selection of the training data is essential to mitigate the extensive costs of deep learning. Data pruning offers a solution by removing redundant or uninformative samples from the dataset, which yields faster convergence and improved neural scaling laws. However, little is known about its impact on classification bias of the trained models. We conduct the first systematic study of this effect and reveal that existing data pruning algorithms can produce highly biased classifiers. At the same time, we argue that random data pruning with appropriate class ratios has potential to improve the worst-class performance. We propose a "fairness-aware" approach to pruning and empirically demonstrate its performance on standard computer vision benchmarks. In sharp contrast to existing algorithms, our proposed method continues improving robustness at a tolerable drop of average performance as we prune more from the datasets. We present theoretical analysis of the classification risk in a mixture of Gaussians to further motivate our algorithm and support our findings.
On Provable Length and Compositional Generalization
Feb 24, 2024Length generalization -- the ability to generalize to longer sequences than ones seen during training, and compositional generalization -- the ability to generalize to token combinations not seen during training, are crucial forms of out-of-distribution generalization in sequence-to-sequence models. In this work, we take the first steps towards provable length and compositional generalization for a range of architectures, including deep sets, transformers, state space models, and simple recurrent neural nets. Depending on the architecture, we prove different degrees of representation identification, e.g., a linear or a permutation relation with ground truth representation, is necessary for length and compositional generalization.
Multi-Domain Causal Representation Learning via Weak Distributional Invariances
Oct 09, 2023Causal representation learning has emerged as the center of action in causal machine learning research. In particular, multi-domain datasets present a natural opportunity for showcasing the advantages of causal representation learning over standard unsupervised representation learning. While recent works have taken crucial steps towards learning causal representations, they often lack applicability to multi-domain datasets due to over-simplifying assumptions about the data; e.g. each domain comes from a different single-node perfect intervention. In this work, we relax these assumptions and capitalize on the following observation: there often exists a subset of latents whose certain distributional properties (e.g., support, variance) remain stable across domains; this property holds when, for example, each domain comes from a multi-node imperfect intervention. Leveraging this observation, we show that autoencoders that incorporate such invariances can provably identify the stable set of latents from the rest across different settings.
Context is Environment
Sep 20, 2023



Two lines of work are taking the central stage in AI research. On the one hand, the community is making increasing efforts to build models that discard spurious correlations and generalize better in novel test environments. Unfortunately, the bitter lesson so far is that no proposal convincingly outperforms a simple empirical risk minimization baseline. On the other hand, large language models (LLMs) have erupted as algorithms able to learn in-context, generalizing on-the-fly to eclectic contextual circumstances that users enforce by means of prompting. In this paper, we argue that context is environment, and posit that in-context learning holds the key to better domain generalization. Via extensive theory and experiments, we show that paying attention to context$\unicode{x2013}\unicode{x2013}$unlabeled examples as they arrive$\unicode{x2013}\unicode{x2013}$allows our proposed In-Context Risk Minimization (ICRM) algorithm to zoom-in on the test environment risk minimizer, leading to significant out-of-distribution performance improvements. From all of this, two messages are worth taking home. Researchers in domain generalization should consider environment as context, and harness the adaptive power of in-context learning. Researchers in LLMs should consider context as environment, to better structure data towards generalization.
Identifiability of Discretized Latent Coordinate Systems via Density Landmarks Detection
Jun 28, 2023Disentanglement aims to recover meaningful latent ground-truth factors from only the observed distribution. Identifiability provides the theoretical grounding for disentanglement to be well-founded. Unfortunately, unsupervised identifiability of independent latent factors is a theoretically proven impossibility in the i.i.d. setting under a general nonlinear smooth map from factors to observations. In this work, we show that, remarkably, it is possible to recover discretized latent coordinates under a highly generic nonlinear smooth mapping (a diffeomorphism) without any additional inductive bias on the mapping. This is, assuming that latent density has axis-aligned discontinuity landmarks, but without making the unrealistic assumption of statistical independence of the factors. We introduce this novel form of identifiability, termed quantized coordinate identifiability, and provide a comprehensive proof of the recovery of discretized coordinates.
A Closer Look at In-Context Learning under Distribution Shifts
May 26, 2023

In-context learning, a capability that enables a model to learn from input examples on the fly without necessitating weight updates, is a defining characteristic of large language models. In this work, we follow the setting proposed in (Garg et al., 2022) to better understand the generality and limitations of in-context learning from the lens of the simple yet fundamental task of linear regression. The key question we aim to address is: Are transformers more adept than some natural and simpler architectures at performing in-context learning under varying distribution shifts? To compare transformers, we propose to use a simple architecture based on set-based Multi-Layer Perceptrons (MLPs). We find that both transformers and set-based MLPs exhibit in-context learning under in-distribution evaluations, but transformers more closely emulate the performance of ordinary least squares (OLS). Transformers also display better resilience to mild distribution shifts, where set-based MLPs falter. However, under severe distribution shifts, both models' in-context learning abilities diminish.