 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouteJudge: An Open Platform for Reproducible and Preference-Aware LLM Routing
Jun 17, 2026We present RouteJudge, an online pairwise preference evaluation framework for LLM routing systems, with a public platform available at https://routejudge.cn. Different from model-level response evaluation, RouteJudge focuses on router-level decision quality. For each user query, multiple routing strategies independently recommend candidate models under the same model pool and budget constraints. The selected model responses are then presented to users through anonymous pairwise comparisons, and the resulting user preferences are attributed back to the routing strategies behind the compared responses. Each evaluation record stores the query, routing decisions, model responses, preference labels, cost, latency, and task metadata, enabling preference-aware, cost-aware, and task-conditioned analysis of LLM routers. To support the continuous expansion of routing methods in RouteJudge, we further release ORBIT (Optimal Routing and Budgeted Inference Toolbox), a modular and extensible toolbox that standardizes the end-to-end workflow of LLM routing. ORBIT provides unified interfaces for benchmark loading, query representation, router implementation, budget-aware evaluation, and method comparison, allowing researchers to develop and evaluate routing algorithms under consistent protocols. It also serves as the submission and integration layer for RouteJudge: researchers can implement routing methods within ORBIT, validate them on existing routing benchmarks, and submit compatible routers for online preference-based evaluation. The code of ORBIT is available at https://github.com/AIGNLAI/LAMDA-ORBIT.
From Sampled Outcomes to Capability Distributions: Rethinking Supervision for LLM Routing
Jun 05, 2026Existing LLM routing methods typically treat a model's single response to a query as its capability label for training routers. However, because LLM generation is inherently stochastic, such single-shot supervision provides only a noisy observation of a query-model pair's behavior rather than a reliable capability estimate. We show that this assumption introduces systematic noise into routing supervision, making learned routing policies less reliable. To address this issue, we propose DARS (Distribution-Aware Routing Supervision), a framework that constructs routing supervision from a distributional view of model behavior. Instead of relying on a single generated response, DARS considers uncertainty from both the input side and the output side, capturing how semantically equivalent query formulations and stochastic generations affect model performance. Based on these distribution-aware observations, DARS builds more reliable supervision signals for routing. Experiments across diverse tasks show that single-shot labels can be misleading for model selection, while distribution-aware supervision provides more stable labels and improves learned routing behavior. Our results suggest that reliable LLM routing should move beyond single-response observations and be grounded in query-level model capability distributions.
Exact Stiefel Optimization for Probabilistic PLS: Closed-Form Updates, Error Bounds, and Calibrated Uncertainty
May 12, 2026Probabilistic partial least squares (PPLS) is a central likelihood-based model for two-view learning when one needs both interpretable latent factors and calibrated uncertainty. Building on the identifiable parameterization of Bouhaddani et al.\ (2018), existing fitting pipelines still face two practical bottlenecks: noise--signal coupling under joint EM/ECM updates and nontrivial handling of orthogonality constraints. Following the fixed-noise scalar-likelihood line of Hu et al.\ (2025), we develop an end-to-end framework that combines noise pre-estimation, constrained likelihood optimization, and prediction calibration in one pipeline. Relative to Hu et al.\ (2025), we replace full-spectrum noise averaging with noise-subspace estimation and replace interior-point penalty handling with exact Stiefel-manifold optimization. The noise-subspace estimator attains a signal-strength-independent leading finite-sample rate and matches a minimax lower bound, while the full-spectrum estimator is shown to be inconsistent under the same model. We further extend the framework to sub-Gaussian settings via optional Gaussianization and provide closed-form standard errors through a block-structured Fisher analysis. Across synthetic high-noise settings and two multi-omics benchmarks (TCGA-BRCA and PBMC CITE-seq), the method achieves near-nominal coverage without post-hoc recalibration, reaches Ridge-level point accuracy on TCGA-BRCA at rank $r=3$, matches or exceeds PO2PLS on cross-view prediction while providing native calibrated uncertainty, and improves stability of parameter recovery.
MedAgentBoard: Benchmarking Multi-Agent Collaboration with Conventional Methods for Diverse Medical Tasks
May 18, 2025The rapid advancement of Large Language Models (LLMs) has stimulated interest in multi-agent collaboration for addressing complex medical tasks. However, the practical advantages of multi-agent collaboration approaches remain insufficiently understood. Existing evaluations often lack generalizability, failing to cover diverse tasks reflective of real-world clinical practice, and frequently omit rigorous comparisons against both single-LLM-based and established conventional methods. To address this critical gap, we introduce MedAgentBoard, a comprehensive benchmark for the systematic evaluation of multi-agent collaboration, single-LLM, and conventional approaches. MedAgentBoard encompasses four diverse medical task categories: (1) medical (visual) question answering, (2) lay summary generation, (3) structured Electronic Health Record (EHR) predictive modeling, and (4) clinical workflow automation, across text, medical images, and structured EHR data. Our extensive experiments reveal a nuanced landscape: while multi-agent collaboration demonstrates benefits in specific scenarios, such as enhancing task completeness in clinical workflow automation, it does not consistently outperform advanced single LLMs (e.g., in textual medical QA) or, critically, specialized conventional methods that generally maintain better performance in tasks like medical VQA and EHR-based prediction. MedAgentBoard offers a vital resource and actionable insights, emphasizing the necessity of a task-specific, evidence-based approach to selecting and developing AI solutions in medicine. It underscores that the inherent complexity and overhead of multi-agent collaboration must be carefully weighed against tangible performance gains. All code, datasets, detailed prompts, and experimental results are open-sourced at https://medagentboard.netlify.app/.
A Comparative and Experimental Study on Automatic Question Answering Systems and its Robustness against Word Jumbling
Nov 27, 2023



Question answer generation using Natural Language Processing models is ubiquitous in the world around us. It is used in many use cases such as the building of chat bots, suggestive prompts in google search and also as a way of navigating information in banking mobile applications etc. It is highly relevant because a frequently asked questions (FAQ) list can only have a finite amount of questions but a model which can perform question answer generation could be able to answer completely new questions that are within the scope of the data. This helps us to be able to answer new questions accurately as long as it is a relevant question. In commercial applications, it can be used to increase customer satisfaction and ease of usage. However a lot of data is generated by humans so it is susceptible to human error and this can adversely affect the model's performance and we are investigating this through our work
A Modified PINN Approach for Identifiable Compartmental Models in Epidemiology with Applications to COVID-19
Aug 01, 2022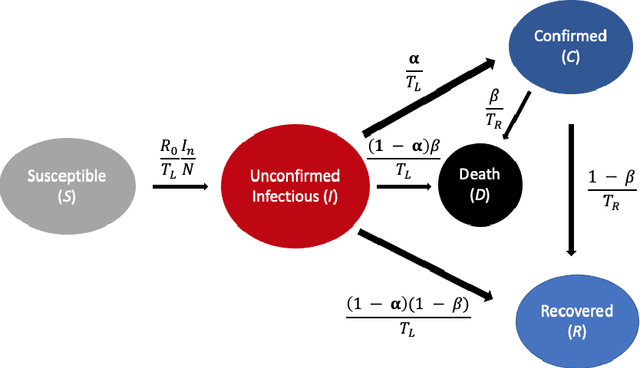

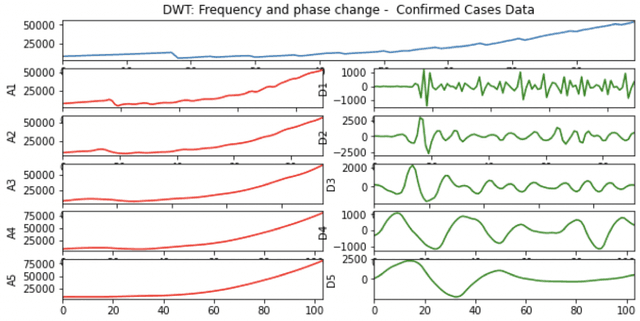
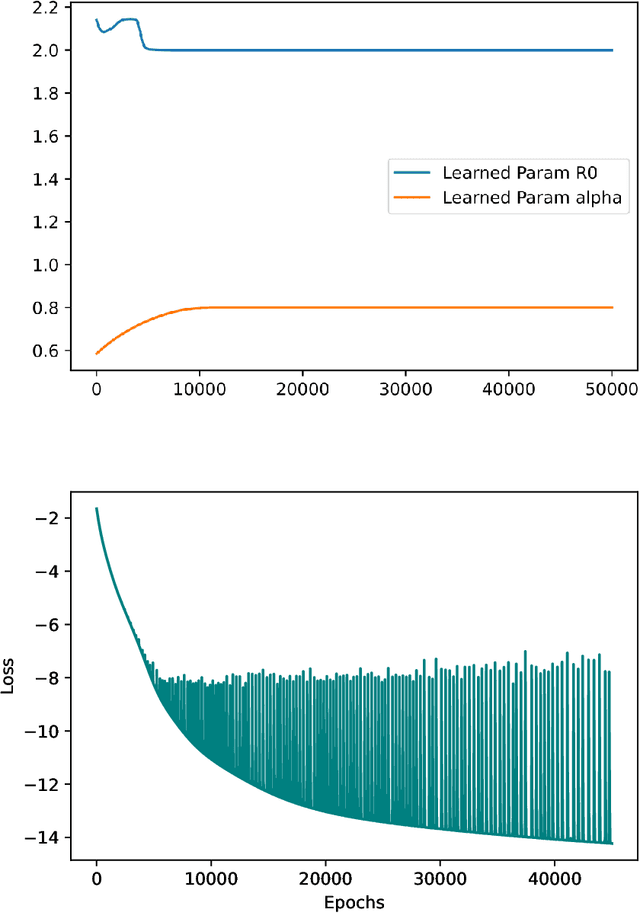
A variety of approaches using compartmental models have been used to study the COVID-19 pandemic and the usage of machine learning methods with these models has had particularly notable success. We present here an approach toward analyzing accessible data on Covid-19's U.S. development using a variation of the "Physics Informed Neural Networks" (PINN) which is capable of using the knowledge of the model to aid learning. We illustrate the challenges of using the standard PINN approach, then how with appropriate and novel modifications to the loss function the network can perform well even in our case of incomplete information. Aspects of identifiability of the model parameters are also assessed, as well as methods of denoising available data using a wavelet transform. Finally, we discuss the capability of the neural network methodology to work with models of varying parameter values, as well as a concrete application in estimating how effectively cases are being tested for in a population, providing a ranking of U.S. states by means of their respective testing.