 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
M^4I: Multi-modal Models Membership Inference
Sep 15, 2022

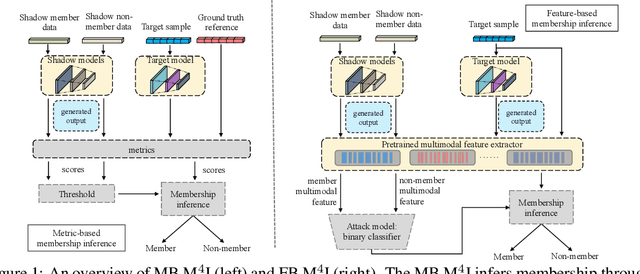
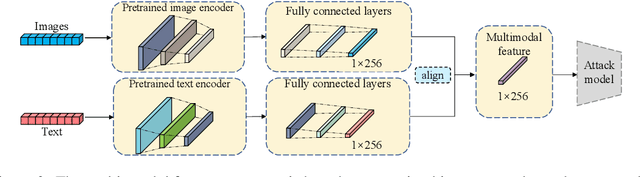
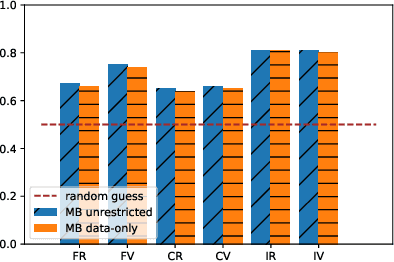
With the development of machine learning techniques, the attention of research has been moved from single-modal learning to multi-modal learning, as real-world data exist in the form of different modalities. However, multi-modal models often carry more information than single-modal models and they are usually applied in sensitive scenarios, such as medical report generation or disease identification. Compared with the existing membership inference against machine learning classifiers, we focus on the problem that the input and output of the multi-modal models are in different modalities, such as image captioning. This work studies the privacy leakage of multi-modal models through the lens of membership inference attack, a process of determining whether a data record involves in the model training process or not. To achieve this, we propose Multi-modal Models Membership Inference (M^4I) with two attack methods to infer the membership status, named metric-based (MB) M^4I and feature-based (FB) M^4I, respectively. More specifically, MB M^4I adopts similarity metrics while attacking to infer target data membership. FB M^4I uses a pre-trained shadow multi-modal feature extractor to achieve the purpose of data inference attack by comparing the similarities from extracted input and output features. Extensive experimental results show that both attack methods can achieve strong performances. Respectively, 72.5% and 94.83% of attack success rates on average can be obtained under unrestricted scenarios. Moreover, we evaluate multiple defense mechanisms against our attacks. The source code of M^4I attacks is publicly available at https://github.com/MultimodalMI/Multimodal-membership-inference.git.
Continuous Decomposition of Granularity for Neural Paraphrase Generation
Sep 05, 2022
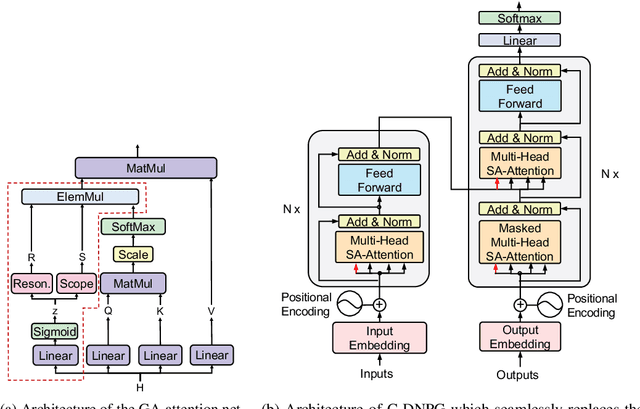

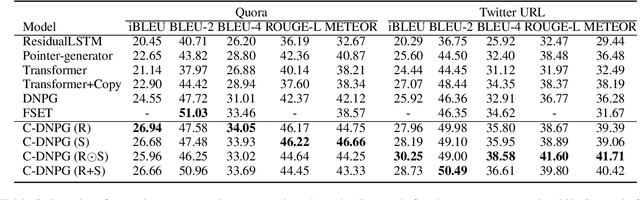
While Transformers have had significant success in paragraph generation, they treat sentences as linear sequences of tokens and often neglect their hierarchical information. Prior work has shown that decomposing the levels of granularity~(e.g., word, phrase, or sentence) for input tokens has produced substantial improvements, suggesting the possibility of enhancing Transformers via more fine-grained modeling of granularity. In this work, we propose a continuous decomposition of granularity for neural paraphrase generation (C-DNPG). In order to efficiently incorporate granularity into sentence encoding, C-DNPG introduces a granularity-aware attention (GA-Attention) mechanism which extends the multi-head self-attention with: 1) a granularity head that automatically infers the hierarchical structure of a sentence by neurally estimating the granularity level of each input token; and 2) two novel attention masks, namely, granularity resonance and granularity scope, to efficiently encode granularity into attention. Experiments on two benchmarks, including Quora question pairs and Twitter URLs have shown that C-DNPG outperforms baseline models by a remarkable margin and achieves state-of-the-art results in terms of many metrics. Qualitative analysis reveals that C-DNPG indeed captures fine-grained levels of granularity with effectiveness.
A Library for Representing Python Programs as Graphs for Machine Learning
Aug 15, 2022



Graph representations of programs are commonly a central element of machine learning for code research. We introduce an open source Python library python_graphs that applies static analysis to construct graph representations of Python programs suitable for training machine learning models. Our library admits the construction of control-flow graphs, data-flow graphs, and composite ``program graphs'' that combine control-flow, data-flow, syntactic, and lexical information about a program. We present the capabilities and limitations of the library, perform a case study applying the library to millions of competitive programming submissions, and showcase the library's utility for machine learning research.
Attention Mechanism Based Intelligent Channel Feedback for mmWave Massive MIMO Systems
Aug 13, 2022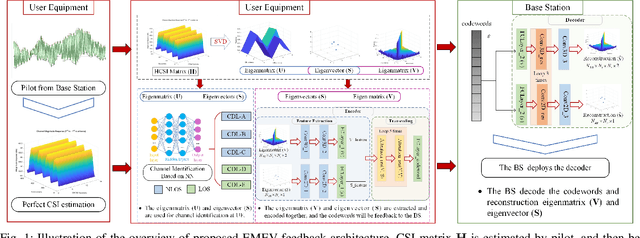
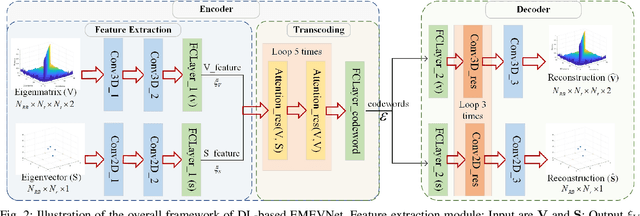
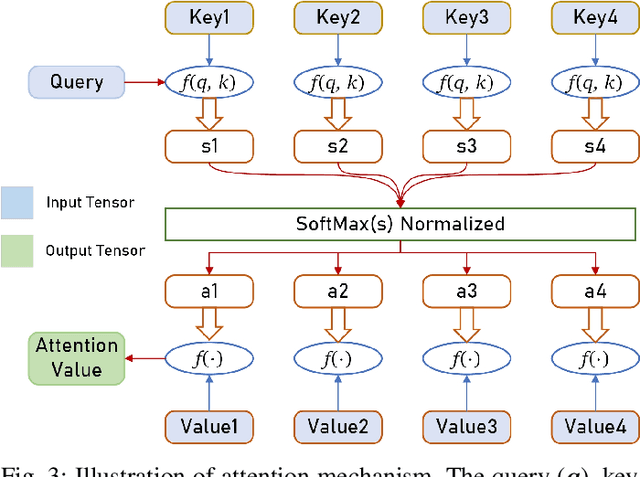
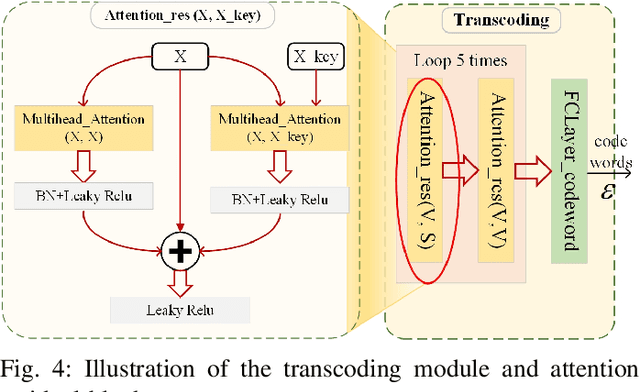
The potential advantages of intelligent wireless communications with millimeter wave (mmWave) and massive multiple-input multiple-output (MIMO) are all based on the availability of instantaneous channel state information (CSI) at the base station (BS). However, in frequency division duplex (FDD) systems, no existence of channel reciprocity leads to the difficult acquisition of accurate CSI at the BS. In recent years, many researchers explored effective architectures based on deep learning (DL) to solve this problem and proved the success of DL-based solutions. However, existing schemes focused on the acquisition of complete CSI while ignoring the beamforming and precoding operations. In this paper, we propose an intelligent channel feedback architecture designed for beamforming based on attention mechanism and eigen features. That is, we design an eigenmatrix and eigenvector feedback neural network, called EMEVNet. The key idea of EMEVNet is to extract and feedback effective information meeting the requirements of beamforming and precoding operations at the BS. With the help of the attention mechanism, the proposed EMEVNet can be considered as a dual channel auto-encoder, which is able to jointly encode the eigenmatrix and eigenvector into codewords. Hence, the EMEVNet consists of an encoder deployed at the user and the decoder at the BS. Each user first utilizes singular value decomposition (SVD) transformation to extract the eigen features from CSI, and then selects an appropriate encoder for a specific channel to generate feedback codewords.
Cross-Skeleton Interaction Graph Aggregation Network for Representation Learning of Mouse Social Behaviour
Aug 07, 2022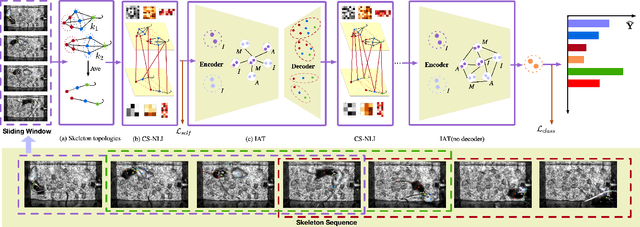
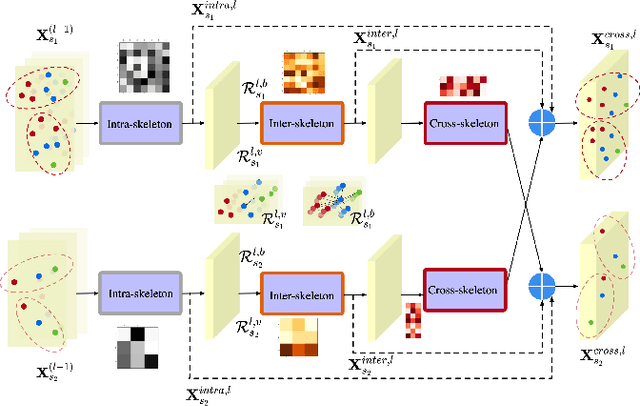
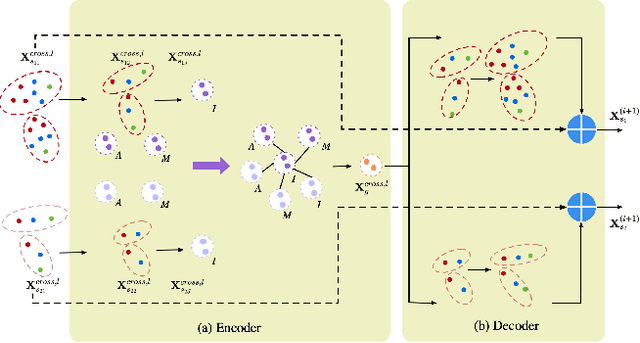
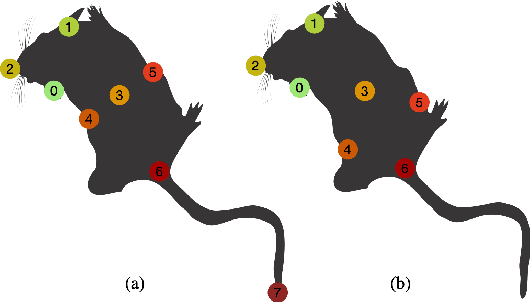
Automated social behaviour analysis of mice has become an increasingly popular research area in behavioural neuroscience. Recently, pose information (i.e., locations of keypoints or skeleton) has been used to interpret social behaviours of mice. Nevertheless, effective encoding and decoding of social interaction information underlying the keypoints of mice has been rarely investigated in the existing methods. In particular, it is challenging to model complex social interactions between mice due to highly deformable body shapes and ambiguous movement patterns. To deal with the interaction modelling problem, we here propose a Cross-Skeleton Interaction Graph Aggregation Network (CS-IGANet) to learn abundant dynamics of freely interacting mice, where a Cross-Skeleton Node-level Interaction module (CS-NLI) is used to model multi-level interactions (i.e., intra-, inter- and cross-skeleton interactions). Furthermore, we design a novel Interaction-Aware Transformer (IAT) to dynamically learn the graph-level representation of social behaviours and update the node-level representation, guided by our proposed interaction-aware self-attention mechanism. Finally, to enhance the representation ability of our model, an auxiliary self-supervised learning task is proposed for measuring the similarity between cross-skeleton nodes. Experimental results on the standard CRMI13-Skeleton and our PDMB-Skeleton datasets show that our proposed model outperforms several other state-of-the-art approaches.
Intrusion Detection Systems Using Support Vector Machines on the KDDCUP'99 and NSL-KDD Datasets: A Comprehensive Survey
Sep 12, 2022With the growing rates of cyber-attacks and cyber espionage, the need for better and more powerful intrusion detection systems (IDS) is even more warranted nowadays. The basic task of an IDS is to act as the first line of defense, in detecting attacks on the internet. As intrusion tactics from intruders become more sophisticated and difficult to detect, researchers have started to apply novel Machine Learning (ML) techniques to effectively detect intruders and hence preserve internet users' information and overall trust in the entire internet network security. Over the last decade, there has been an explosion of research on intrusion detection techniques based on ML and Deep Learning (DL) architectures on various cyber security-based datasets such as the DARPA, KDDCUP'99, NSL-KDD, CAIDA, CTU-13, UNSW-NB15. In this research, we review contemporary literature and provide a comprehensive survey of different types of intrusion detection technique that applies Support Vector Machines (SVMs) algorithms as a classifier. We focus only on studies that have been evaluated on the two most widely used datasets in cybersecurity namely: the KDDCUP'99 and the NSL-KDD datasets. We provide a summary of each method, identifying the role of the SVMs classifier, and all other algorithms involved in the studies. Furthermore, we present a critical review of each method, in tabular form, highlighting the performance measures, strengths, and limitations of each of the methods surveyed.
Deep Music Information Dynamics
Feb 01, 2021
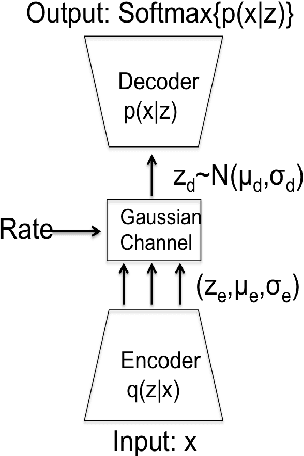
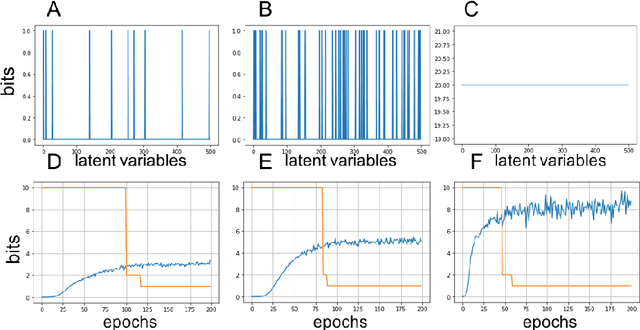
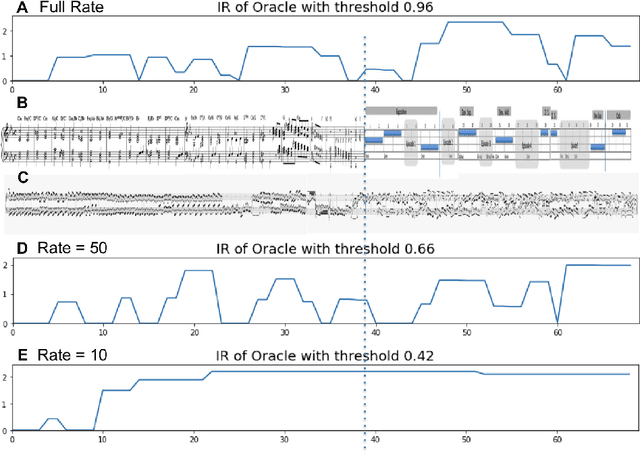
Music comprises of a set of complex simultaneous events organized in time. In this paper we introduce a novel framework that we call Deep Musical Information Dynamics, which combines two parallel streams - a low rate latent representation stream that is assumed to capture the dynamics of a thought process contrasted with a higher rate information dynamics derived from the musical data itself. Motivated by rate-distortion theories of human cognition we propose a framework for exploring possible relations between imaginary anticipations existing in the listener's mind and information dynamics of the musical surface itself. This model is demonstrated for the case of symbolic (MIDI) data, as accounting for acoustic surface would require many more layers to capture instrument properties and performance expressive inflections. The mathematical framework is based on variational encoding that first establishes a high rate representation of the musical observations, which is then reduced using a bit-allocation method into a parallel low rate data stream. The combined loss considered here includes both the information rate in terms of time evolution for each stream, and the fidelity of encoding measured in terms of mutual information between the high and low rate representations. In the simulations presented in the paper we are able to juxtapose aspects of latent/imaginary surprisal versus surprisal of the music surface in a manner that is quantifiable and computationally tractable. The set of computational tools is discussed in the paper, suggesting that a trade off between compression and prediction are an important factor in the analysis and design of time-based music generative models.
Motion-aware Memory Network for Fast Video Salient Object Detection
Aug 01, 2022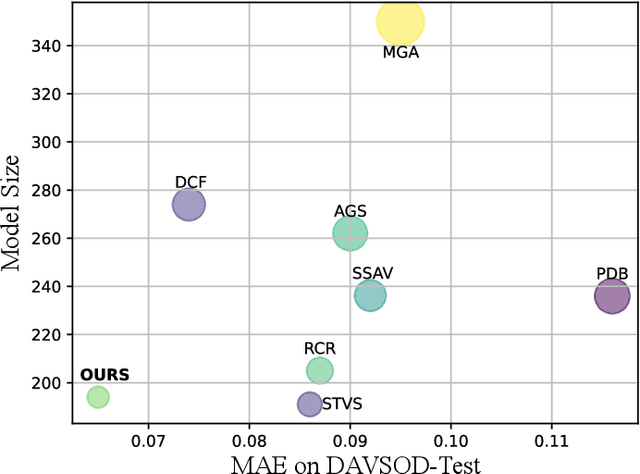

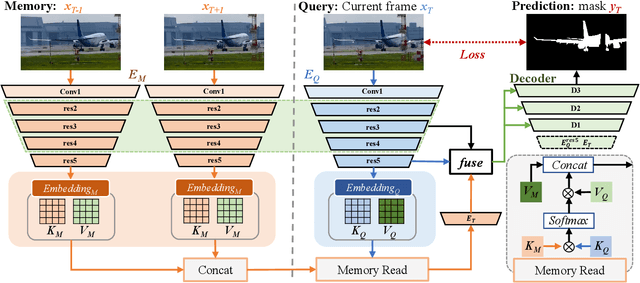
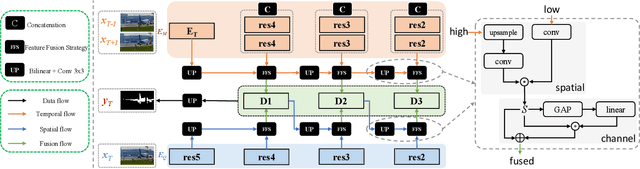
Previous methods based on 3DCNN, convLSTM, or optical flow have achieved great success in video salient object detection (VSOD). However, they still suffer from high computational costs or poor quality of the generated saliency maps. To solve these problems, we design a space-time memory (STM)-based network, which extracts useful temporal information of the current frame from adjacent frames as the temporal branch of VSOD. Furthermore, previous methods only considered single-frame prediction without temporal association. As a result, the model may not focus on the temporal information sufficiently. Thus, we initially introduce object motion prediction between inter-frame into VSOD. Our model follows standard encoder--decoder architecture. In the encoding stage, we generate high-level temporal features by using high-level features from the current and its adjacent frames. This approach is more efficient than the optical flow-based methods. In the decoding stage, we propose an effective fusion strategy for spatial and temporal branches. The semantic information of the high-level features is used to fuse the object details in the low-level features, and then the spatiotemporal features are obtained step by step to reconstruct the saliency maps. Moreover, inspired by the boundary supervision commonly used in image salient object detection (ISOD), we design a motion-aware loss for predicting object boundary motion and simultaneously perform multitask learning for VSOD and object motion prediction, which can further facilitate the model to extract spatiotemporal features accurately and maintain the object integrity. Extensive experiments on several datasets demonstrated the effectiveness of our method and can achieve state-of-the-art metrics on some datasets. The proposed model does not require optical flow or other preprocessing, and can reach a speed of nearly 100 FPS during inference.
Denoised MDPs: Learning World Models Better Than the World Itself
Jul 01, 2022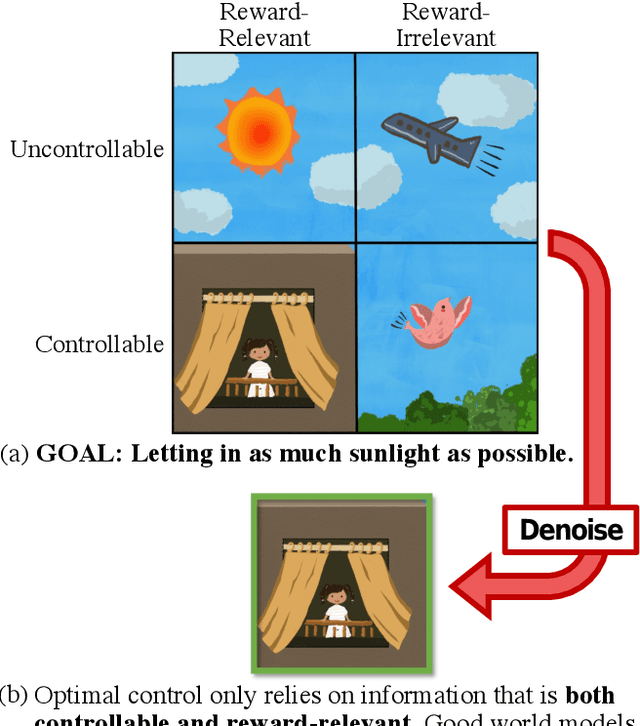
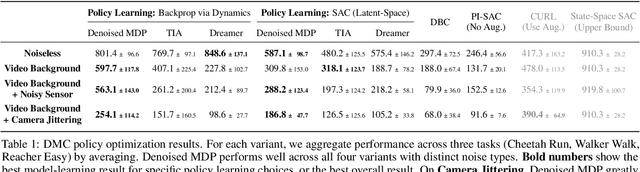
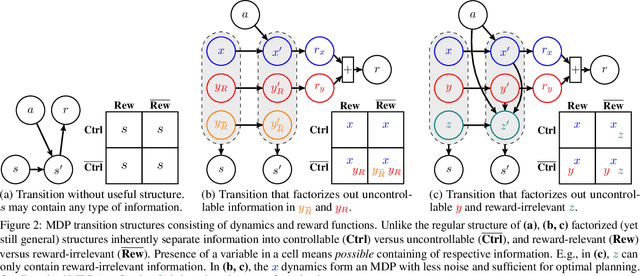
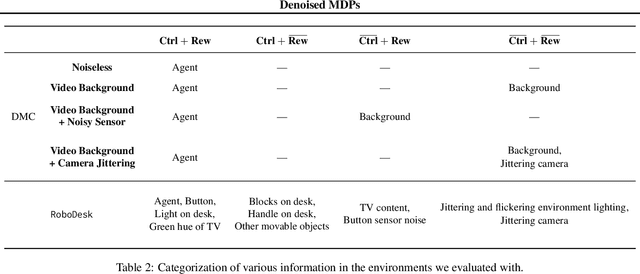
The ability to separate signal from noise, and reason with clean abstractions, is critical to intelligence. With this ability, humans can efficiently perform real world tasks without considering all possible nuisance factors.How can artificial agents do the same? What kind of information can agents safely discard as noises? In this work, we categorize information out in the wild into four types based on controllability and relation with reward, and formulate useful information as that which is both controllable and reward-relevant. This framework clarifies the kinds information removed by various prior work on representation learning in reinforcement learning (RL), and leads to our proposed approach of learning a Denoised MDP that explicitly factors out certain noise distractors. Extensive experiments on variants of DeepMind Control Suite and RoboDesk demonstrate superior performance of our denoised world model over using raw observations alone, and over prior works, across policy optimization control tasks as well as the non-control task of joint position regression.
An Adjoint-Free Algorithm for CNOP via Sampling
Aug 01, 2022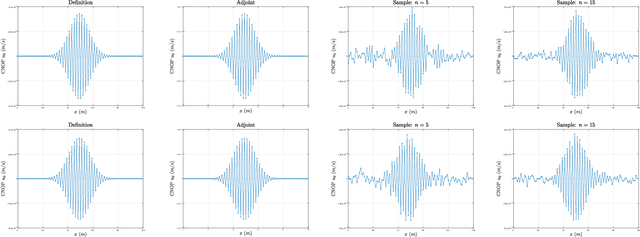

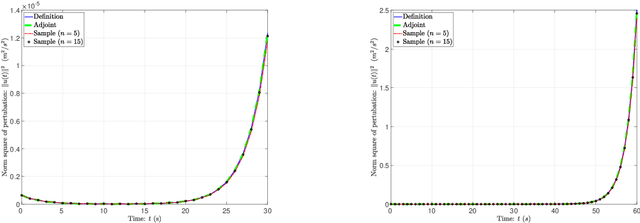
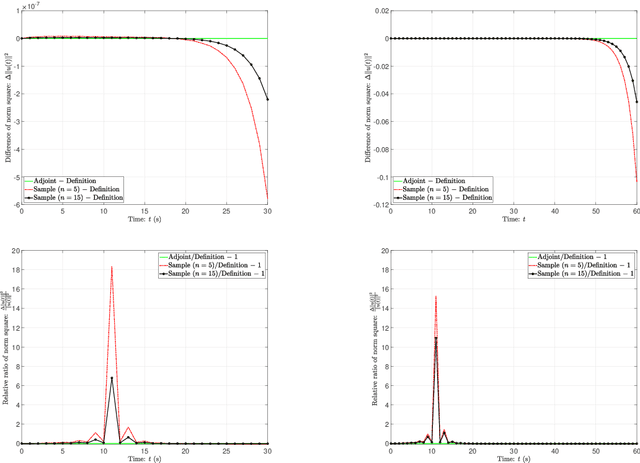
In this paper, we propose a sampling algorithm based on statistical machine learning to obtain conditional nonlinear optimal perturbation (CNOP), which is essentially different from the traditional deterministic optimization methods. The new approach does not only reduce the extremely expensive gradient (first-order) information directly by the objective value (zeroth-order) information, but also avoid the use of adjoint technique that gives rise to the huge storage problem and the instability from linearization. Meanwhile, an intuitive anlysis and a rigorous concentration inequality for the approximate gradient by sampling are shown. The numerical experiments to obtain the CNOPs by the performance of standard spatial sturctures for a theoretical model, Burgers equation with small viscosity, demonstrate that at the cost of losing accuracy, fewer samples spend time relatively shorter than the adjoint-based method and directly from definition. Finally, we reveal that the nonlinear time evolution of the CNOPs obtained by all the algorithms are almost consistent with the quantity of norm square of perturbations, their difference and relative difference on the basis of the definition method.