 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHey ASR System! Why Aren't You More Inclusive? Automatic Speech Recognition Systems' Bias and Proposed Bias Mitigation Techniques. A Literature Review
Nov 17, 2022Speech is the fundamental means of communication between humans. The advent of AI and sophisticated speech technologies have led to the rapid proliferation of human-to-computer-based interactions, fueled primarily by Automatic Speech Recognition (ASR) systems. ASR systems normally take human speech in the form of audio and convert it into words, but for some users, it cannot decode the speech, and any output text is filled with errors that are incomprehensible to the human reader. These systems do not work equally for everyone and actually hinder the productivity of some users. In this paper, we present research that addresses ASR biases against gender, race, and the sick and disabled, while exploring studies that propose ASR debiasing techniques for mitigating these discriminations. We also discuss techniques for designing a more accessible and inclusive ASR technology. For each approach surveyed, we also provide a summary of the investigation and methods applied, the ASR systems and corpora used, and the research findings, and highlight their strengths and/or weaknesses. Finally, we propose future opportunities for Natural Language Processing researchers to explore in the next level creation of ASR technologies.
Evaluating Novel Mask-RCNN Architectures for Ear Mask Segmentation
Nov 05, 2022The human ear is generally universal, collectible, distinct, and permanent. Ear-based biometric recognition is a niche and recent approach that is being explored. For any ear-based biometric algorithm to perform well, ear detection and segmentation need to be accurately performed. While significant work has been done in existing literature for bounding boxes, a lack of approaches output a segmentation mask for ears. This paper trains and compares three newer models to the state-of-the-art MaskRCNN (ResNet 101 +FPN) model across four different datasets. The Average Precision (AP) scores reported show that the newer models outperform the state-of-the-art but no one model performs the best over multiple datasets.
Sentiment Classification of Code-Switched Text using Pre-trained Multilingual Embeddings and Segmentation
Oct 29, 2022


With increasing globalization and immigration, various studies have estimated that about half of the world population is bilingual. Consequently, individuals concurrently use two or more languages or dialects in casual conversational settings. However, most research is natural language processing is focused on monolingual text. To further the work in code-switched sentiment analysis, we propose a multi-step natural language processing algorithm utilizing points of code-switching in mixed text and conduct sentiment analysis around those identified points. The proposed sentiment analysis algorithm uses semantic similarity derived from large pre-trained multilingual models with a handcrafted set of positive and negative words to determine the polarity of code-switched text. The proposed approach outperforms a comparable baseline model by 11.2% for accuracy and 11.64% for F1-score on a Spanish-English dataset. Theoretically, the proposed algorithm can be expanded for sentiment analysis of multiple languages with limited human expertise.
Intrusion Detection Systems Using Support Vector Machines on the KDDCUP'99 and NSL-KDD Datasets: A Comprehensive Survey
Sep 12, 2022With the growing rates of cyber-attacks and cyber espionage, the need for better and more powerful intrusion detection systems (IDS) is even more warranted nowadays. The basic task of an IDS is to act as the first line of defense, in detecting attacks on the internet. As intrusion tactics from intruders become more sophisticated and difficult to detect, researchers have started to apply novel Machine Learning (ML) techniques to effectively detect intruders and hence preserve internet users' information and overall trust in the entire internet network security. Over the last decade, there has been an explosion of research on intrusion detection techniques based on ML and Deep Learning (DL) architectures on various cyber security-based datasets such as the DARPA, KDDCUP'99, NSL-KDD, CAIDA, CTU-13, UNSW-NB15. In this research, we review contemporary literature and provide a comprehensive survey of different types of intrusion detection technique that applies Support Vector Machines (SVMs) algorithms as a classifier. We focus only on studies that have been evaluated on the two most widely used datasets in cybersecurity namely: the KDDCUP'99 and the NSL-KDD datasets. We provide a summary of each method, identifying the role of the SVMs classifier, and all other algorithms involved in the studies. Furthermore, we present a critical review of each method, in tabular form, highlighting the performance measures, strengths, and limitations of each of the methods surveyed.
Towards Understanding and Modeling Empathy for Use in Motivational Design Thinking
Jul 28, 2019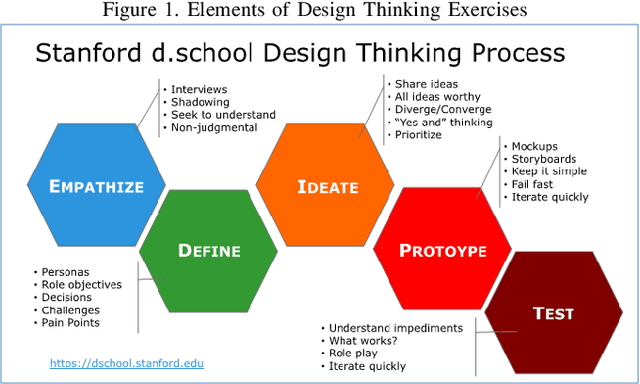
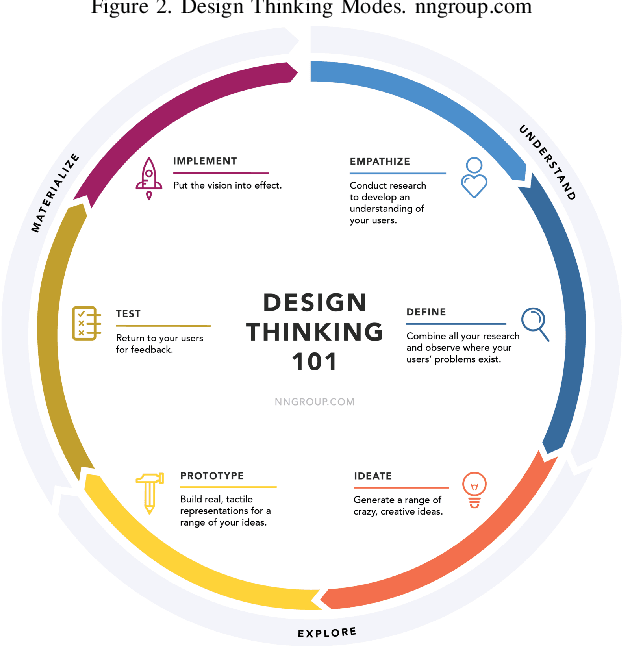
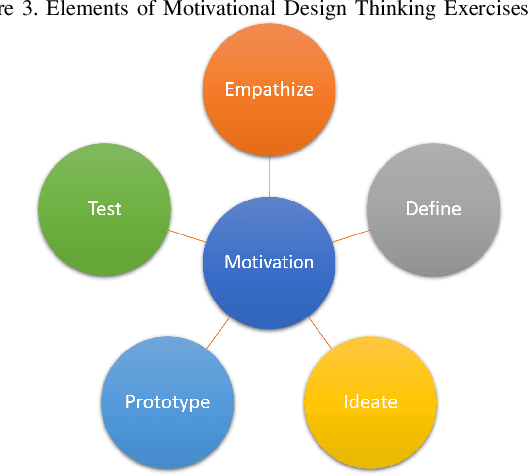
Design Thinking workshops are used by companies to help generate new ideas for technologies and products by engaging subjects in exercises to understand their users' wants and become more empathetic towards their needs. The "aha moment" experienced during these thought-provoking, step outside the yourself activities occurs when a group of persons iterate over several problems and converge upon a solution that will fit seamlessly everyday life. With the increasing use and cost of Design workshops being offered, it is important that technology be developed that can help identify empathy and its onset in humans. This position paper presents an approach to modeling empathy using Gaussian mixture models and heart rate and skin conductance. This paper also presents an updated approach to Design Thinking that helps to ensure participants are thinking outside of their own race's, culture's, or other affiliations' motives.