 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSirens' Whisper: Inaudible Near-Ultrasonic Jailbreaks of Speech-Driven LLMs
Mar 14, 2026Speech-driven large language models (LLMs) are increasingly accessed through speech interfaces, introducing new security risks via open acoustic channels. We present Sirens' Whisper (SWhisper), the first practical framework for covert prompt-based attacks against speech-driven LLMs under realistic black-box conditions using commodity hardware. SWhisper enables robust, inaudible delivery of arbitrary target baseband audio-including long and structured prompts-on commodity devices by encoding it into near-ultrasound waveforms that demodulate faithfully after acoustic transmission and microphone nonlinearity. This is achieved through a simple yet effective approach to modeling nonlinear channel characteristics across devices and environments, combined with lightweight channel-inversion pre-compensation. Building on this high-fidelity covert channel, we design a voice-aware jailbreak generation method that ensures intelligibility, brevity, and transferability under speech-driven interfaces. Experiments across both commercial and open-source speech-driven LLMs demonstrate strong black-box effectiveness. On commercial models, SWhisper achieves up to 0.94 non-refusal (NR) and 0.925 specific-convincing (SC). A controlled user study further shows that the injected jailbreak audio is perceptually indistinguishable from background-only playback for human listeners. Although jailbreaks serve as a case study, the underlying covert acoustic channel enables a broader class of high-fidelity prompt-injection and commandexecution attacks.
M^4I: Multi-modal Models Membership Inference
Sep 15, 2022
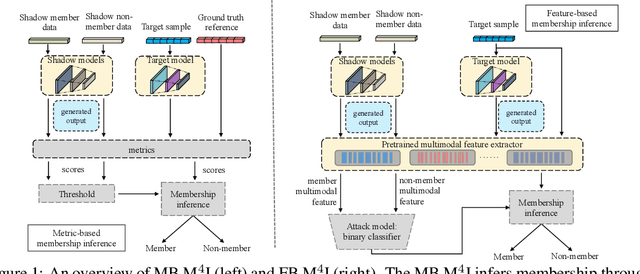
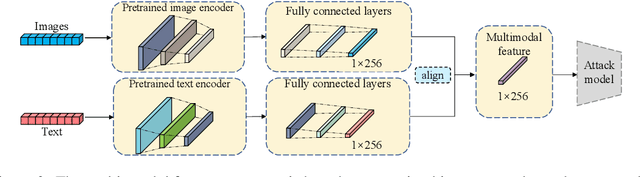
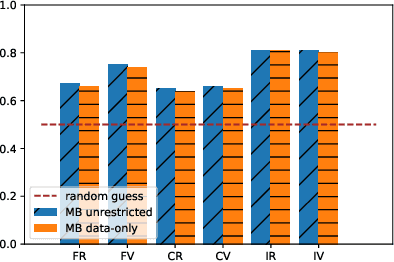
With the development of machine learning techniques, the attention of research has been moved from single-modal learning to multi-modal learning, as real-world data exist in the form of different modalities. However, multi-modal models often carry more information than single-modal models and they are usually applied in sensitive scenarios, such as medical report generation or disease identification. Compared with the existing membership inference against machine learning classifiers, we focus on the problem that the input and output of the multi-modal models are in different modalities, such as image captioning. This work studies the privacy leakage of multi-modal models through the lens of membership inference attack, a process of determining whether a data record involves in the model training process or not. To achieve this, we propose Multi-modal Models Membership Inference (M^4I) with two attack methods to infer the membership status, named metric-based (MB) M^4I and feature-based (FB) M^4I, respectively. More specifically, MB M^4I adopts similarity metrics while attacking to infer target data membership. FB M^4I uses a pre-trained shadow multi-modal feature extractor to achieve the purpose of data inference attack by comparing the similarities from extracted input and output features. Extensive experimental results show that both attack methods can achieve strong performances. Respectively, 72.5% and 94.83% of attack success rates on average can be obtained under unrestricted scenarios. Moreover, we evaluate multiple defense mechanisms against our attacks. The source code of M^4I attacks is publicly available at https://github.com/MultimodalMI/Multimodal-membership-inference.git.