 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Embedded Multi-label Feature Selection via Orthogonal Regression
Mar 01, 2024

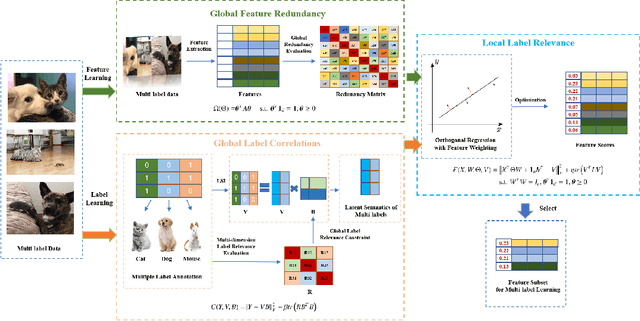


In the last decade, embedded multi-label feature selection methods, incorporating the search for feature subsets into model optimization, have attracted considerable attention in accurately evaluating the importance of features in multi-label classification tasks. Nevertheless, the state-of-the-art embedded multi-label feature selection algorithms based on least square regression usually cannot preserve sufficient discriminative information in multi-label data. To tackle the aforementioned challenge, a novel embedded multi-label feature selection method, termed global redundancy and relevance optimization in orthogonal regression (GRROOR), is proposed to facilitate the multi-label feature selection. The method employs orthogonal regression with feature weighting to retain sufficient statistical and structural information related to local label correlations of the multi-label data in the feature learning process. Additionally, both global feature redundancy and global label relevancy information have been considered in the orthogonal regression model, which could contribute to the search for discriminative and non-redundant feature subsets in the multi-label data. The cost function of GRROOR is an unbalanced orthogonal Procrustes problem on the Stiefel manifold. A simple yet effective scheme is utilized to obtain an optimal solution. Extensive experimental results on ten multi-label data sets demonstrate the effectiveness of GRROOR.
Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models
Mar 05, 2024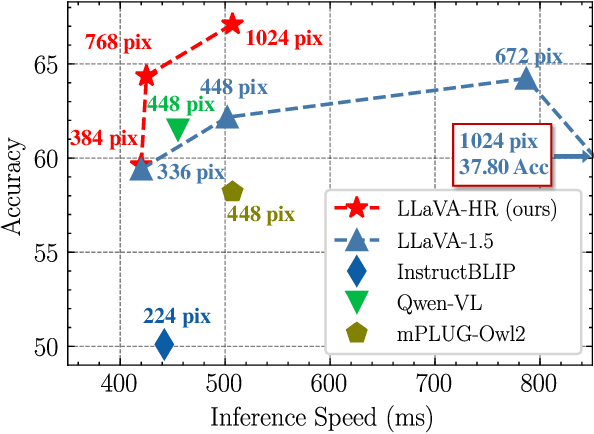
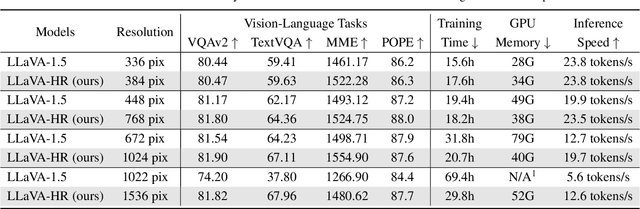
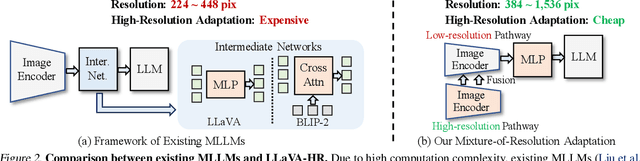
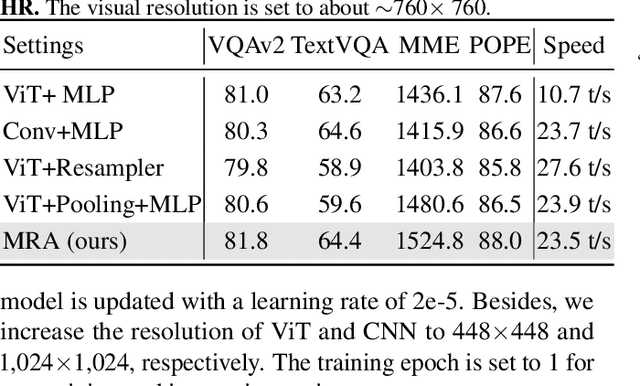
Despite remarkable progress, existing multimodal large language models (MLLMs) are still inferior in granular visual recognition. Contrary to previous works, we study this problem from the perspective of image resolution, and reveal that a combination of low- and high-resolution visual features can effectively mitigate this shortcoming. Based on this observation, we propose a novel and efficient method for MLLMs, termed Mixture-of-Resolution Adaptation (MRA). In particular, MRA adopts two visual pathways for images with different resolutions, where high-resolution visual information is embedded into the low-resolution pathway via the novel mixture-of-resolution adapters (MR-Adapters). This design also greatly reduces the input sequence length of MLLMs. To validate MRA, we apply it to a recent MLLM called LLaVA, and term the new model LLaVA-HR. We conduct extensive experiments on 11 vision-language (VL) tasks, which show that LLaVA-HR outperforms existing MLLMs on 8 VL tasks, e.g., +9.4% on TextVQA. More importantly, both training and inference of LLaVA-HR remain efficient with MRA, e.g., 20 training hours and 3$\times$ inference speed than LLaVA-1.5. Source codes are released at: https://github.com/luogen1996/LLaVA-HR.
Behavior Generation with Latent Actions
Mar 05, 2024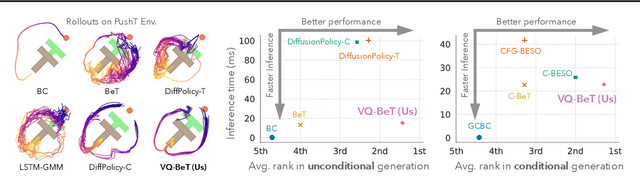
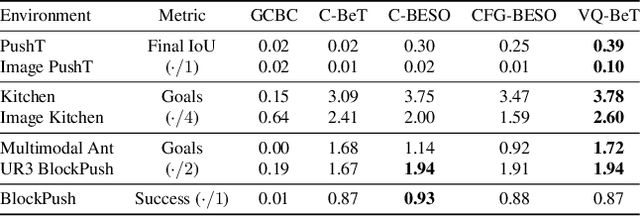
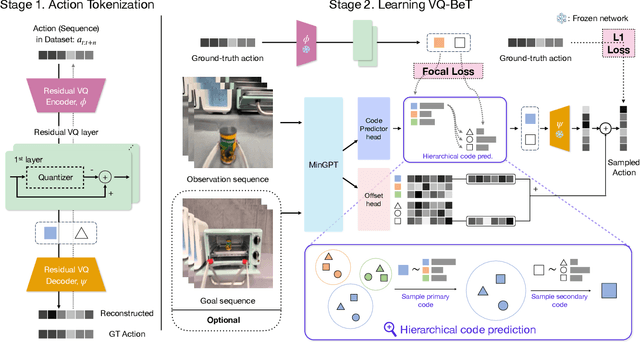
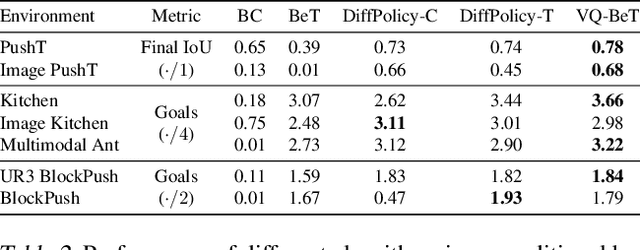
Generative modeling of complex behaviors from labeled datasets has been a longstanding problem in decision making. Unlike language or image generation, decision making requires modeling actions - continuous-valued vectors that are multimodal in their distribution, potentially drawn from uncurated sources, where generation errors can compound in sequential prediction. A recent class of models called Behavior Transformers (BeT) addresses this by discretizing actions using k-means clustering to capture different modes. However, k-means struggles to scale for high-dimensional action spaces or long sequences, and lacks gradient information, and thus BeT suffers in modeling long-range actions. In this work, we present Vector-Quantized Behavior Transformer (VQ-BeT), a versatile model for behavior generation that handles multimodal action prediction, conditional generation, and partial observations. VQ-BeT augments BeT by tokenizing continuous actions with a hierarchical vector quantization module. Across seven environments including simulated manipulation, autonomous driving, and robotics, VQ-BeT improves on state-of-the-art models such as BeT and Diffusion Policies. Importantly, we demonstrate VQ-BeT's improved ability to capture behavior modes while accelerating inference speed 5x over Diffusion Policies. Videos and code can be found https://sjlee.cc/vq-bet
Interactive Continual Learning: Fast and Slow Thinking
Mar 05, 2024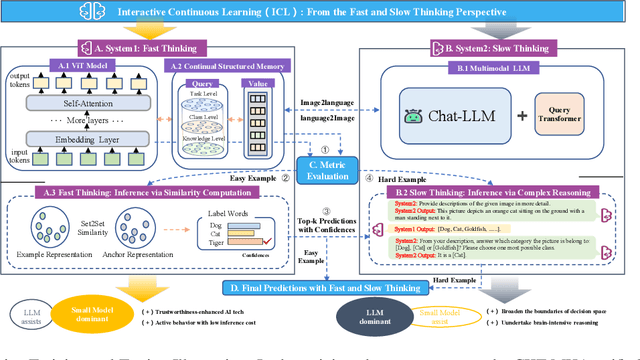
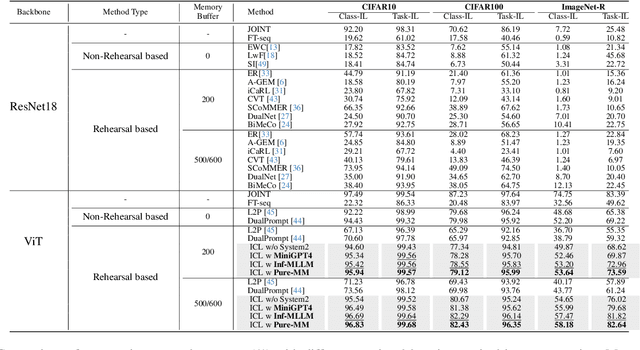
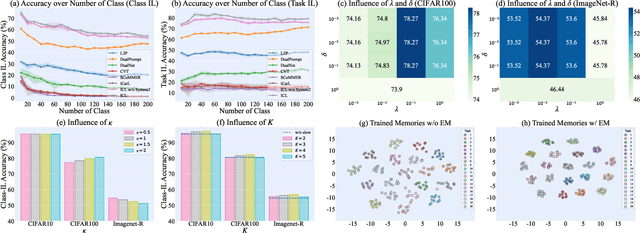
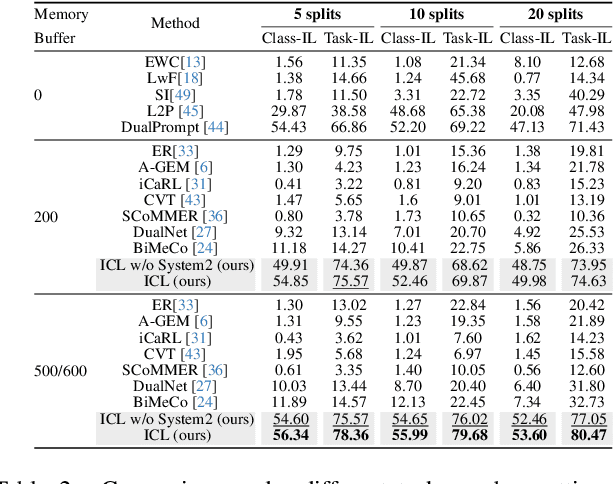
Advanced life forms, sustained by the synergistic interaction of neural cognitive mechanisms, continually acquire and transfer knowledge throughout their lifespan. In contrast, contemporary machine learning paradigms exhibit limitations in emulating the facets of continual learning (CL). Nonetheless, the emergence of large language models (LLMs) presents promising avenues for realizing CL via interactions with these models. Drawing on Complementary Learning System theory, this paper presents a novel Interactive Continual Learning (ICL) framework, enabled by collaborative interactions among models of various sizes. Specifically, we assign the ViT model as System1 and multimodal LLM as System2. To enable the memory module to deduce tasks from class information and enhance Set2Set retrieval, we propose the Class-Knowledge-Task Multi-Head Attention (CKT-MHA). Additionally, to improve memory retrieval in System1 through enhanced geometric representation, we introduce the CL-vMF mechanism, based on the von Mises-Fisher (vMF) distribution. Meanwhile, we introduce the von Mises-Fisher Outlier Detection and Interaction (vMF-ODI) strategy to identify hard examples, thus enhancing collaboration between System1 and System2 for complex reasoning realization. Comprehensive evaluation of our proposed ICL demonstrates significant resistance to forgetting and superior performance relative to existing methods.
Domain-Agnostic Mutual Prompting for Unsupervised Domain Adaptation
Mar 05, 2024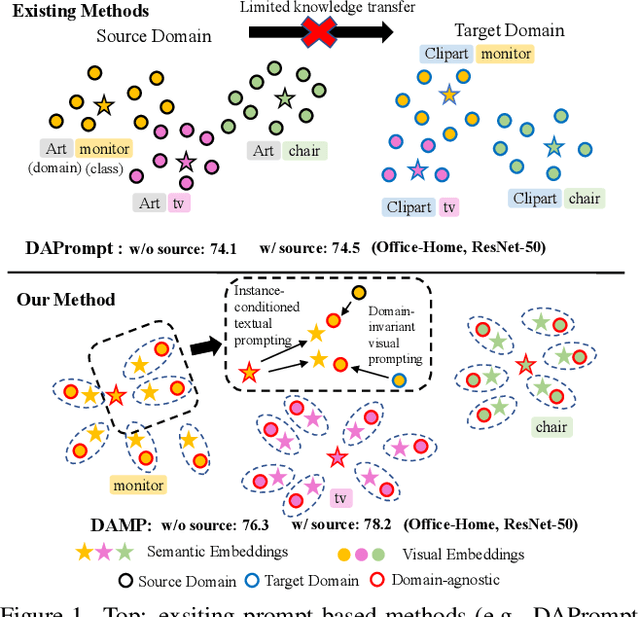
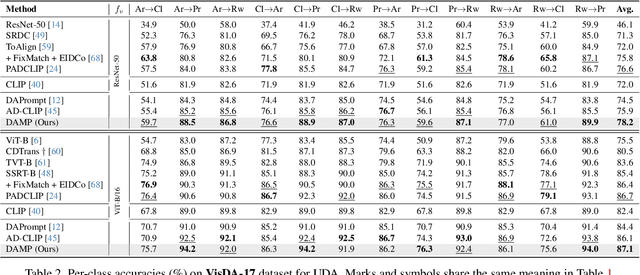
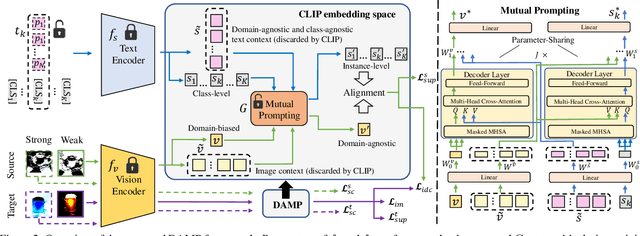
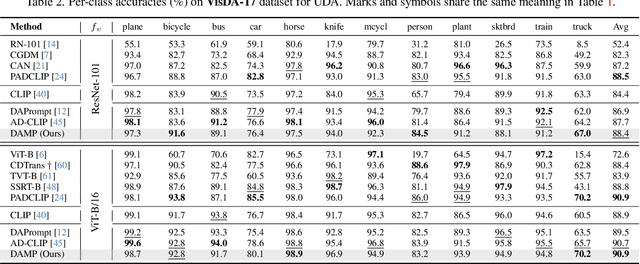
Conventional Unsupervised Domain Adaptation (UDA) strives to minimize distribution discrepancy between domains, which neglects to harness rich semantics from data and struggles to handle complex domain shifts. A promising technique is to leverage the knowledge of large-scale pre-trained vision-language models for more guided adaptation. Despite some endeavors, current methods often learn textual prompts to embed domain semantics for source and target domains separately and perform classification within each domain, limiting cross-domain knowledge transfer. Moreover, prompting only the language branch lacks flexibility to adapt both modalities dynamically. To bridge this gap, we propose Domain-Agnostic Mutual Prompting (DAMP) to exploit domain-invariant semantics by mutually aligning visual and textual embeddings. Specifically, the image contextual information is utilized to prompt the language branch in a domain-agnostic and instance-conditioned way. Meanwhile, visual prompts are imposed based on the domain-agnostic textual prompt to elicit domain-invariant visual embeddings. These two branches of prompts are learned mutually with a cross-attention module and regularized with a semantic-consistency loss and an instance-discrimination contrastive loss. Experiments on three UDA benchmarks demonstrate the superiority of DAMP over state-of-the-art approaches.
Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation
Mar 05, 2024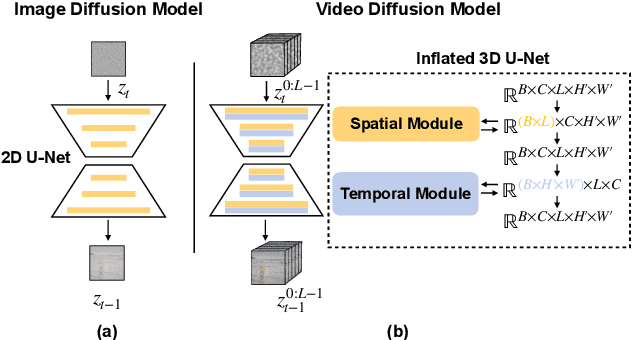
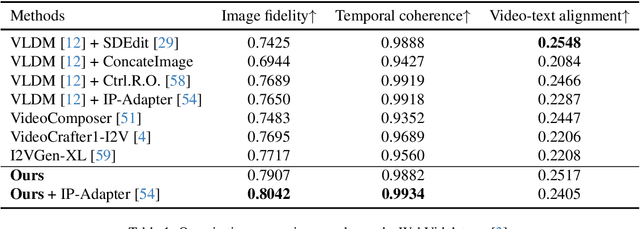
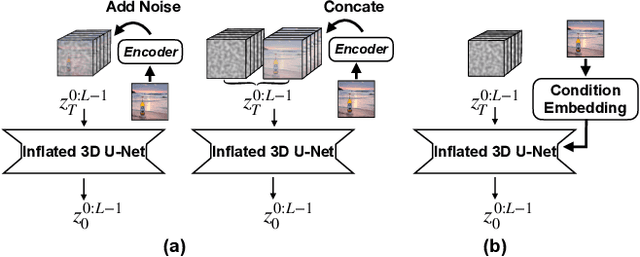
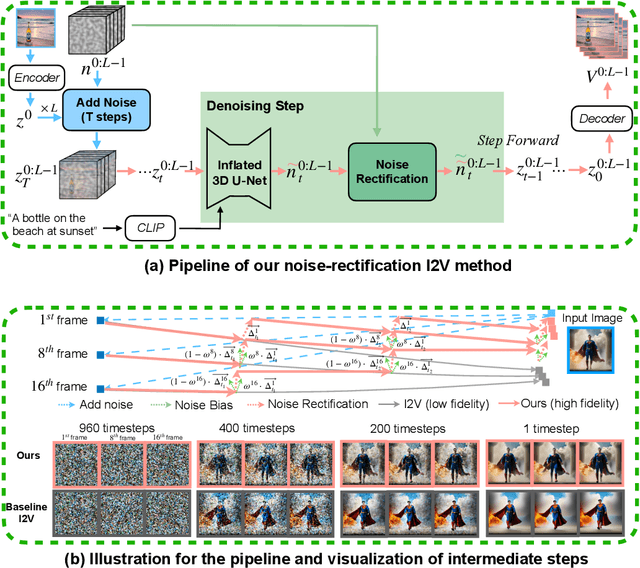
Image-to-video (I2V) generation tasks always suffer from keeping high fidelity in the open domains. Traditional image animation techniques primarily focus on specific domains such as faces or human poses, making them difficult to generalize to open domains. Several recent I2V frameworks based on diffusion models can generate dynamic content for open domain images but fail to maintain fidelity. We found that two main factors of low fidelity are the loss of image details and the noise prediction biases during the denoising process. To this end, we propose an effective method that can be applied to mainstream video diffusion models. This method achieves high fidelity based on supplementing more precise image information and noise rectification. Specifically, given a specified image, our method first adds noise to the input image latent to keep more details, then denoises the noisy latent with proper rectification to alleviate the noise prediction biases. Our method is tuning-free and plug-and-play. The experimental results demonstrate the effectiveness of our approach in improving the fidelity of generated videos. For more image-to-video generated results, please refer to the project website: https://noise-rectification.github.io.
CoGenesis: A Framework Collaborating Large and Small Language Models for Secure Context-Aware Instruction Following
Mar 05, 2024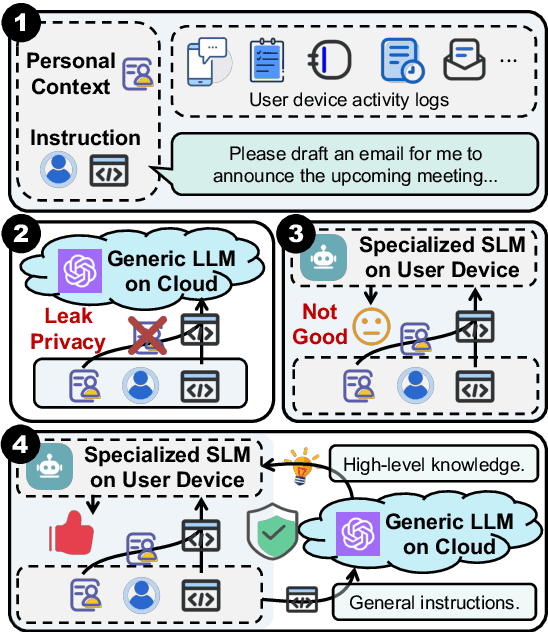
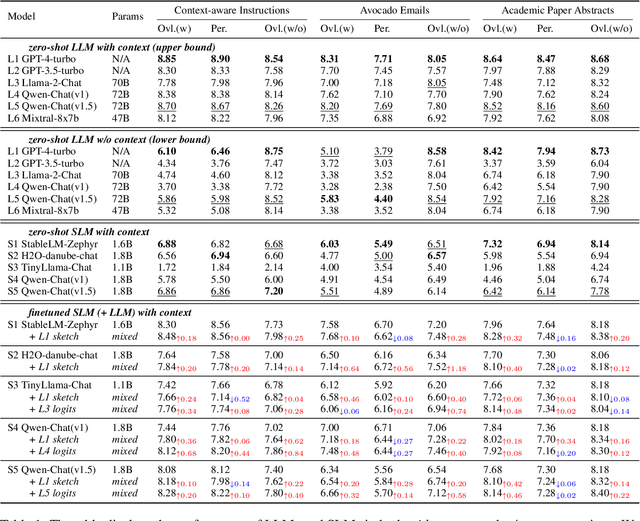
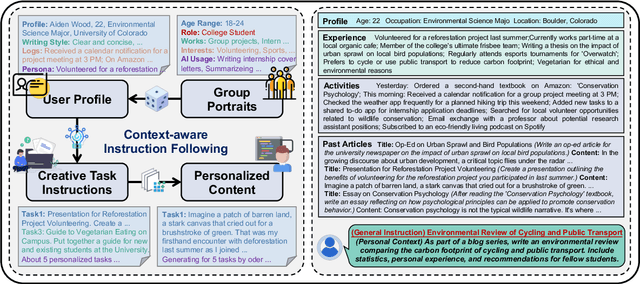
With the advancement of language models (LMs), their exposure to private data is increasingly inevitable, and their deployment (especially for smaller ones) on personal devices, such as PCs and smartphones, has become a prevailing trend. In contexts laden with user information, enabling models to both safeguard user privacy and execute commands efficiently emerges as an essential research imperative. In this paper, we propose CoGenesis, a collaborative generation framework integrating large (hosted on cloud infrastructure) and small models (deployed on local devices) to address privacy concerns logically. Initially, we design a pipeline to create personalized writing instruction datasets enriched with extensive context details as the testbed of this research issue. Subsequently, we introduce two variants of CoGenesis based on sketch and logits respectively. Our experimental findings, based on our synthesized dataset and two additional open-source datasets, indicate that: 1) Large-scale models perform well when provided with user context but struggle in the absence of such context. 2) While specialized smaller models fine-tuned on the synthetic dataset show promise, they still lag behind their larger counterparts. 3) Our CoGenesis framework, utilizing mixed-scale models, showcases competitive performance, providing a feasible solution to privacy issues.
GraphPub: Generation of Differential Privacy Graph with High Availability
Mar 05, 2024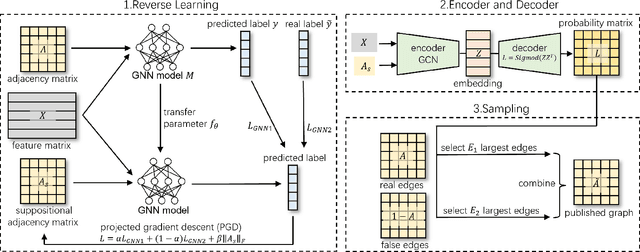
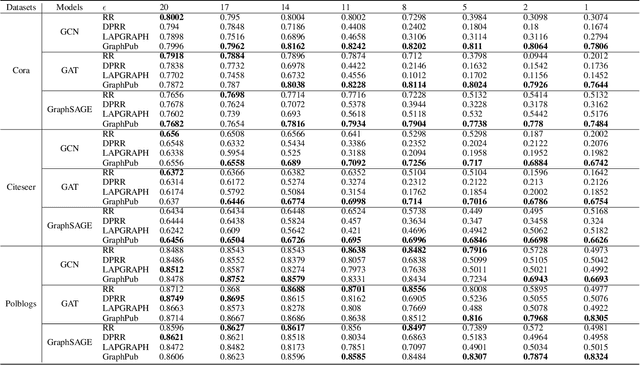
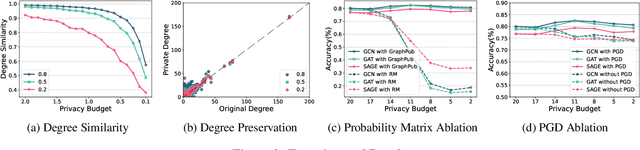
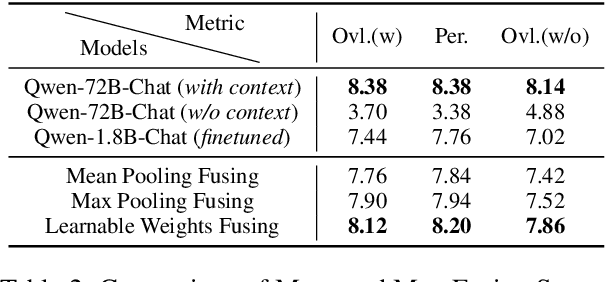
In recent years, with the rapid development of graph neural networks (GNN), more and more graph datasets have been published for GNN tasks. However, when an upstream data owner publishes graph data, there are often many privacy concerns, because many real-world graph data contain sensitive information like person's friend list. Differential privacy (DP) is a common method to protect privacy, but due to the complex topological structure of graph data, applying DP on graphs often affects the message passing and aggregation of GNN models, leading to a decrease in model accuracy. In this paper, we propose a novel graph edge protection framework, graph publisher (GraphPub), which can protect graph topology while ensuring that the availability of data is basically unchanged. Through reverse learning and the encoder-decoder mechanism, we search for some false edges that do not have a large negative impact on the aggregation of node features, and use them to replace some real edges. The modified graph will be published, which is difficult to distinguish between real and false data. Sufficient experiments prove that our framework achieves model accuracy close to the original graph with an extremely low privacy budget.
Privacy-Preserving Autoencoder for Collaborative Object Detection
Feb 29, 2024Privacy is a crucial concern in collaborative machine vision where a part of a Deep Neural Network (DNN) model runs on the edge, and the rest is executed on the cloud. In such applications, the machine vision model does not need the exact visual content to perform its task. Taking advantage of this potential, private information could be removed from the data insofar as it does not significantly impair the accuracy of the machine vision system. In this paper, we present an autoencoder-style network integrated within an object detection pipeline, which generates a latent representation of the input image that preserves task-relevant information while removing private information. Our approach employs an adversarial training strategy that not only removes private information from the bottleneck of the autoencoder but also promotes improved compression efficiency for feature channels coded by conventional codecs like VVC-Intra. We assess the proposed system using a realistic evaluation framework for privacy, directly measuring face and license plate recognition accuracy. Experimental results show that our proposed method is able to reduce the bitrate significantly at the same object detection accuracy compared to coding the input images directly, while keeping the face and license plate recognition accuracy on the images recovered from the bottleneck features low, implying strong privacy protection.
Non-orthogonal Age-Optimal Information Dissemination in Vehicular Networks: A Meta Multi-Objective Reinforcement Learning Approach
Feb 15, 2024This paper considers minimizing the age-of-information (AoI) and transmit power consumption in a vehicular network, where a roadside unit (RSU) provides timely updates about a set of physical processes to vehicles. We consider non-orthogonal multi-modal information dissemination, which is based on superposed message transmission from RSU and successive interference cancellation (SIC) at vehicles. The formulated problem is a multi-objective mixed-integer nonlinear programming problem; thus, a Pareto-optimal front is very challenging to obtain. First, we leverage the weighted-sum approach to decompose the multi-objective problem into a set of multiple single-objective sub-problems corresponding to each predefined objective preference weight. Then, we develop a hybrid deep Q-network (DQN)-deep deterministic policy gradient (DDPG) model to solve each optimization sub-problem respective to predefined objective-preference weight. The DQN optimizes the decoding order, while the DDPG solves the continuous power allocation. The model needs to be retrained for each sub-problem. We then present a two-stage meta-multi-objective reinforcement learning solution to estimate the Pareto front with a few fine-tuning update steps without retraining the model for each sub-problem. Simulation results illustrate the efficacy of the proposed solutions compared to the existing benchmarks and that the meta-multi-objective reinforcement learning model estimates a high-quality Pareto frontier with reduced training time.