 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mask-Guided Image Person Removal with Data Synthesis
Sep 29, 2022

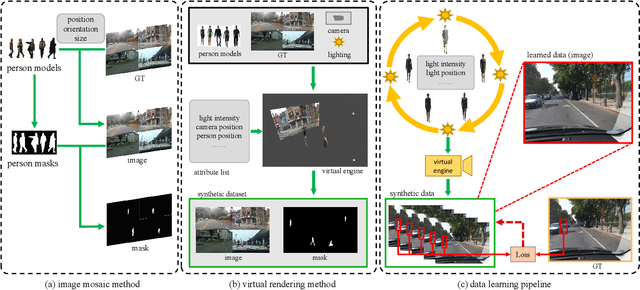
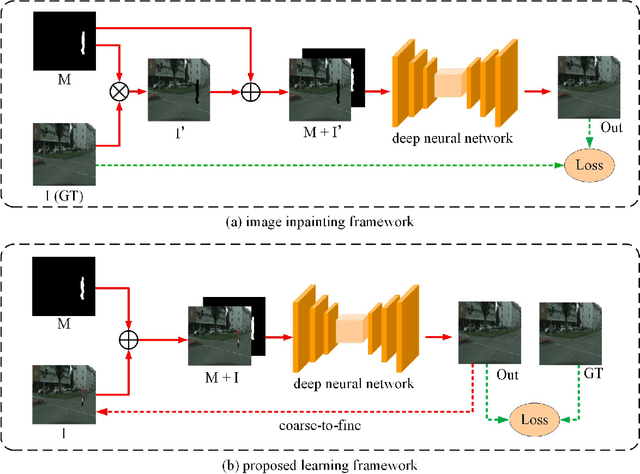

As a special case of common object removal, image person removal is playing an increasingly important role in social media and criminal investigation domains. Due to the integrity of person area and the complexity of human posture, person removal has its own dilemmas. In this paper, we propose a novel idea to tackle these problems from the perspective of data synthesis. Concerning the lack of dedicated dataset for image person removal, two dataset production methods are proposed to automatically generate images, masks and ground truths respectively. Then, a learning framework similar to local image degradation is proposed so that the masks can be used to guide the feature extraction process and more texture information can be gathered for final prediction. A coarse-to-fine training strategy is further applied to refine the details. The data synthesis and learning framework combine well with each other. Experimental results verify the effectiveness of our method quantitatively and qualitatively, and the trained network proves to have good generalization ability either on real or synthetic images.
Baking in the Feature: Accelerating Volumetric Segmentation by Rendering Feature Maps
Sep 26, 2022


Methods have recently been proposed that densely segment 3D volumes into classes using only color images and expert supervision in the form of sparse semantically annotated pixels. While impressive, these methods still require a relatively large amount of supervision and segmenting an object can take several minutes in practice. Such systems typically only optimize their representation on the particular scene they are fitting, without leveraging any prior information from previously seen images. In this paper, we propose to use features extracted with models trained on large existing datasets to improve segmentation performance. We bake this feature representation into a Neural Radiance Field (NeRF) by volumetrically rendering feature maps and supervising on features extracted from each input image. We show that by baking this representation into the NeRF, we make the subsequent classification task much easier. Our experiments show that our method achieves higher segmentation accuracy with fewer semantic annotations than existing methods over a wide range of scenes.
Generalization Bounds for Stochastic Gradient Langevin Dynamics: A Unified View via Information Leakage Analysis
Dec 14, 2021

Recently, generalization bounds of the non-convex empirical risk minimization paradigm using Stochastic Gradient Langevin Dynamics (SGLD) have been extensively studied. Several theoretical frameworks have been presented to study this problem from different perspectives, such as information theory and stability. In this paper, we present a unified view from privacy leakage analysis to investigate the generalization bounds of SGLD, along with a theoretical framework for re-deriving previous results in a succinct manner. Aside from theoretical findings, we conduct various numerical studies to empirically assess the information leakage issue of SGLD. Additionally, our theoretical and empirical results provide explanations for prior works that study the membership privacy of SGLD.
Incremental Semantic Localization using Hierarchical Clustering of Object Association Sets
Aug 28, 2022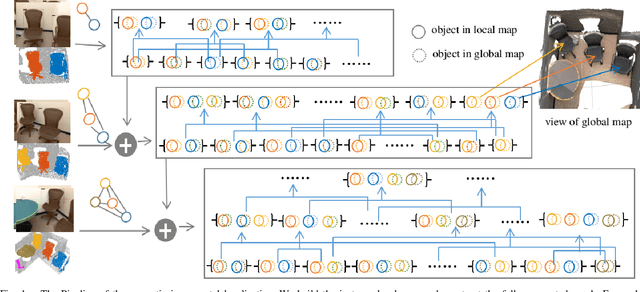
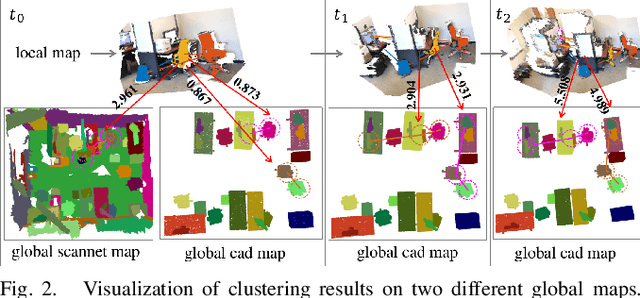
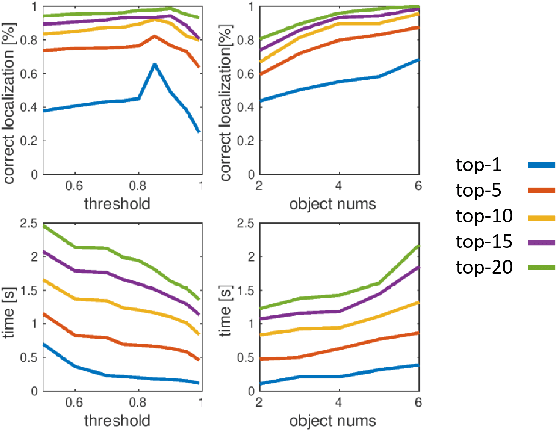
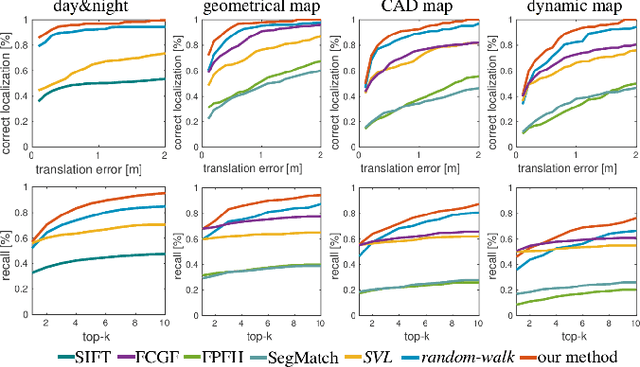
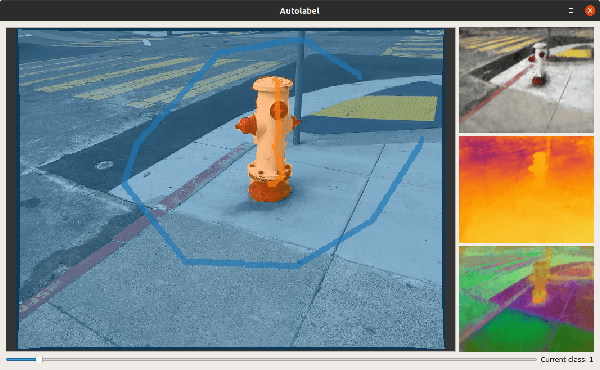
We present a novel approach for relocalization or place recognition, a fundamental problem to be solved in many robotics, automation, and AR applications. Rather than relying on often unstable appearance information, we consider a situation in which the reference map is given in the form of localized objects. Our localization framework relies on 3D semantic object detections, which are then associated to objects in the map. Possible pair-wise association sets are grown based on hierarchical clustering using a merge metric that evaluates spatial compatibility. The latter notably uses information about relative object configurations, which is invariant with respect to global transformations. Association sets are furthermore updated and expanded as the camera incrementally explores the environment and detects further objects. We test our algorithm in several challenging situations including dynamic scenes, large view-point changes, and scenes with repeated instances. Our experiments demonstrate that our approach outperforms prior art in terms of both robustness and accuracy.
Deep Manifold Hashing: A Divide-and-Conquer Approach for Semi-Paired Unsupervised Cross-Modal Retrieval
Sep 26, 2022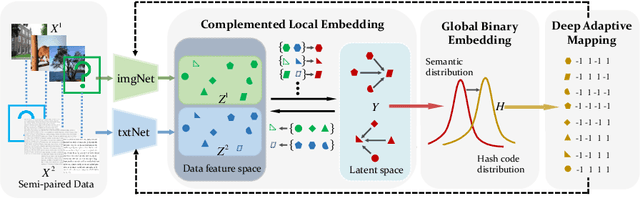
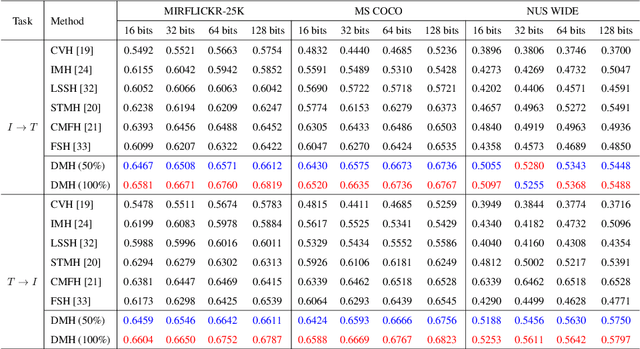
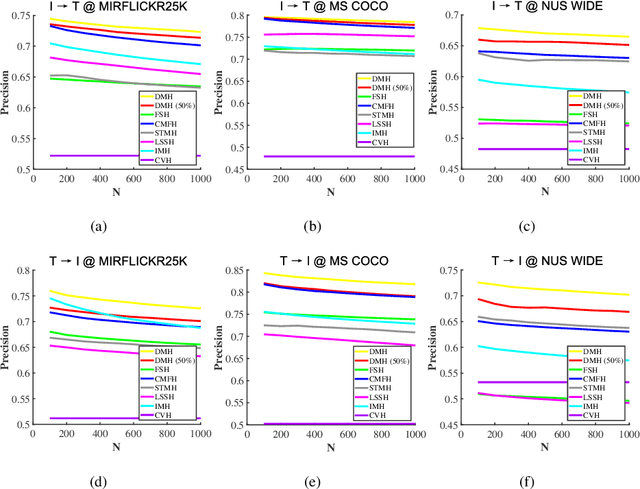
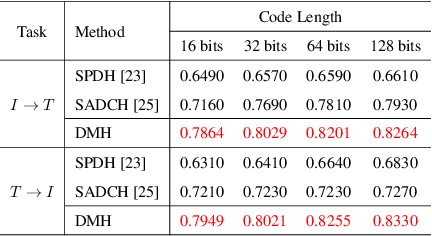
Hashing that projects data into binary codes has shown extraordinary talents in cross-modal retrieval due to its low storage usage and high query speed. Despite their empirical success on some scenarios, existing cross-modal hashing methods usually fail to cross modality gap when fully-paired data with plenty of labeled information is nonexistent. To circumvent this drawback, motivated by the Divide-and-Conquer strategy, we propose Deep Manifold Hashing (DMH), a novel method of dividing the problem of semi-paired unsupervised cross-modal retrieval into three sub-problems and building one simple yet efficiency model for each sub-problem. Specifically, the first model is constructed for obtaining modality-invariant features by complementing semi-paired data based on manifold learning, whereas the second model and the third model aim to learn hash codes and hash functions respectively. Extensive experiments on three benchmarks demonstrate the superiority of our DMH compared with the state-of-the-art fully-paired and semi-paired unsupervised cross-modal hashing methods.
Self-supervised Pre-training for Semantic Segmentation in an Indoor Scene
Oct 04, 2022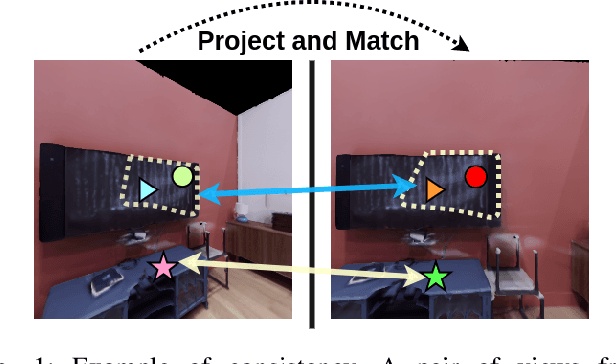
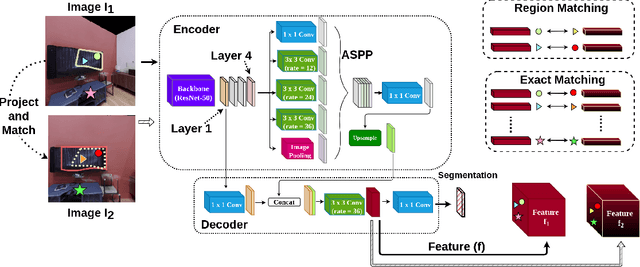

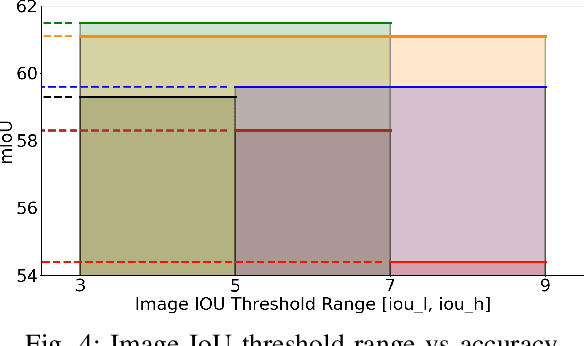
The ability to endow maps of indoor scenes with semantic information is an integral part of robotic agents which perform different tasks such as target driven navigation, object search or object rearrangement. The state-of-the-art methods use Deep Convolutional Neural Networks (DCNNs) for predicting semantic segmentation of an image as useful representation for these tasks. The accuracy of semantic segmentation depends on the availability and the amount of labeled data from the target environment or the ability to bridge the domain gap between test and training environment. We propose RegConsist, a method for self-supervised pre-training of a semantic segmentation model, exploiting the ability of the agent to move and register multiple views in the novel environment. Given the spatial and temporal consistency cues used for pixel level data association, we use a variant of contrastive learning to train a DCNN model for predicting semantic segmentation from RGB views in the target environment. The proposed method outperforms models pre-trained on ImageNet and achieves competitive performance when using models that are trained for exactly the same task but on a different dataset. We also perform various ablation studies to analyze and demonstrate the efficacy of our proposed method.
Improved Super Resolution of MR Images Using CNNs and Vision Transformers
Jul 24, 2022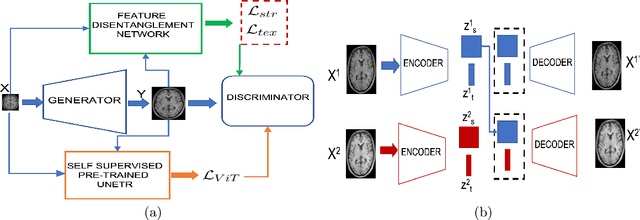
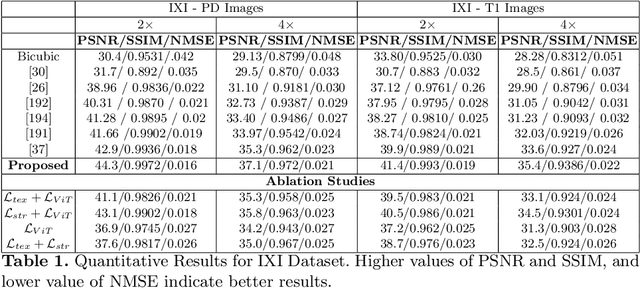
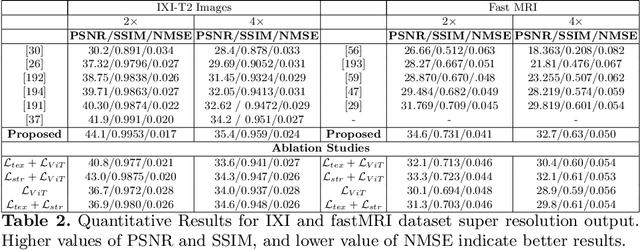
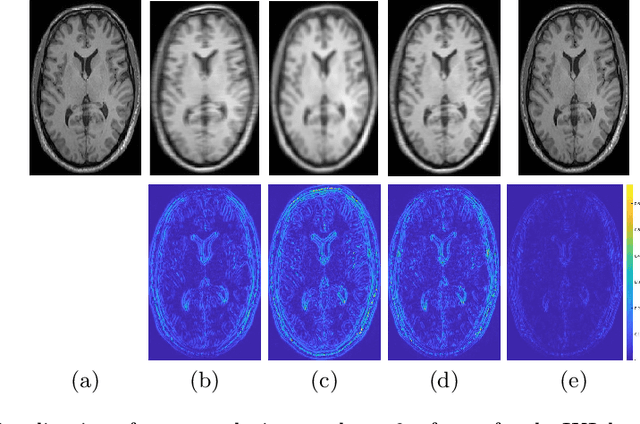
State of the art magnetic resonance (MR) image super-resolution methods (ISR) using convolutional neural networks (CNNs) leverage limited contextual information due to the limited spatial coverage of CNNs. Vision transformers (ViT) learn better global context that is helpful in generating superior quality HR images. We combine local information of CNNs and global information from ViTs for image super resolution and output super resolved images that have superior quality than those produced by state of the art methods. We include extra constraints through multiple novel loss functions that preserve structure and texture information from the low resolution to high resolution images.
Towards Improving Faithfulness in Abstractive Summarization
Oct 04, 2022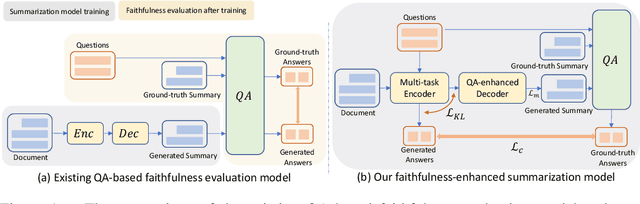
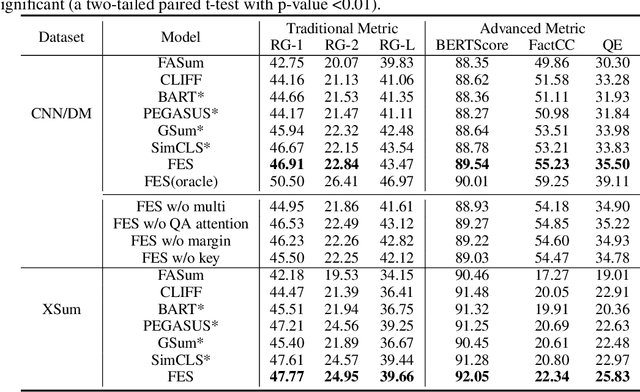
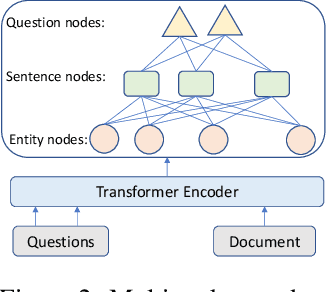

Despite the success achieved in neural abstractive summarization based on pre-trained language models, one unresolved issue is that the generated summaries are not always faithful to the input document. There are two possible causes of the unfaithfulness problem: (1) the summarization model fails to understand or capture the gist of the input text, and (2) the model over-relies on the language model to generate fluent but inadequate words. In this work, we propose a Faithfulness Enhanced Summarization model (FES), which is designed for addressing these two problems and improving faithfulness in abstractive summarization. For the first problem, we propose to use question-answering (QA) to examine whether the encoder fully grasps the input document and can answer the questions on the key information in the input. The QA attention on the proper input words can also be used to stipulate how the decoder should attend to the source. For the second problem, we introduce a max-margin loss defined on the difference between the language and the summarization model, aiming to prevent the overconfidence of the language model. Extensive experiments on two benchmark summarization datasets, CNN/DM and XSum, demonstrate that our model significantly outperforms strong baselines. The evaluation of factual consistency also shows that our model generates more faithful summaries than baselines.
Robust Causality and False Attribution in Data-Driven Earth Science Discoveries
Sep 26, 2022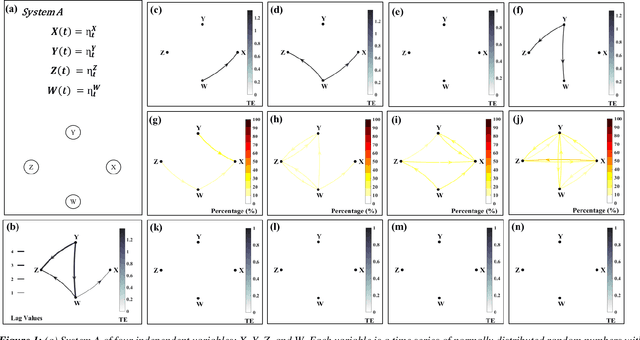
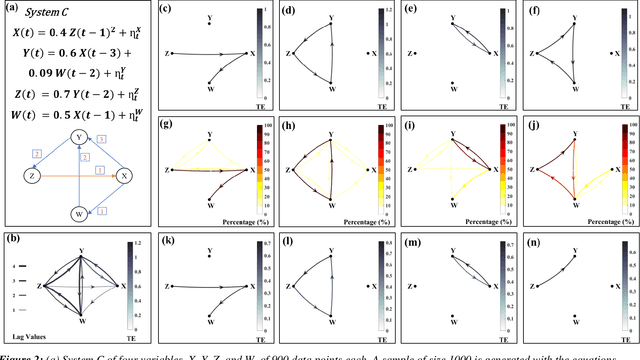
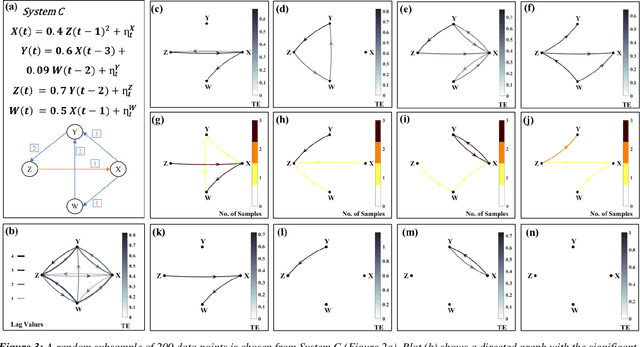
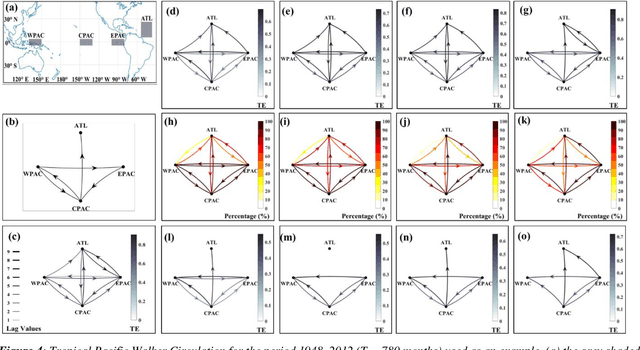
Causal and attribution studies are essential for earth scientific discoveries and critical for informing climate, ecology, and water policies. However, the current generation of methods needs to keep pace with the complexity of scientific and stakeholder challenges and data availability combined with the adequacy of data-driven methods. Unless carefully informed by physics, they run the risk of conflating correlation with causation or getting overwhelmed by estimation inaccuracies. Given that natural experiments, controlled trials, interventions, and counterfactual examinations are often impractical, information-theoretic methods have been developed and are being continually refined in the earth sciences. Here we show that transfer entropy-based causal graphs, which have recently become popular in the earth sciences with high-profile discoveries, can be spurious even when augmented with statistical significance. We develop a subsample-based ensemble approach for robust causality analysis. Simulated data, and observations in climate and ecohydrology, suggest the robustness and consistency of this approach.
OrthoMAD: Morphing Attack Detection Through Orthogonal Identity Disentanglement
Aug 23, 2022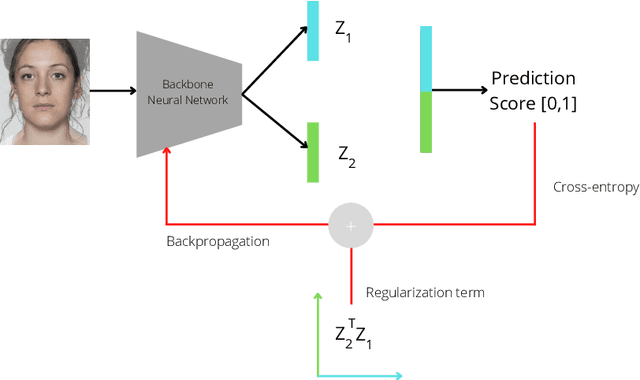
Morphing attacks are one of the many threats that are constantly affecting deep face recognition systems. It consists of selecting two faces from different individuals and fusing them into a final image that contains the identity information of both. In this work, we propose a novel regularisation term that takes into account the existent identity information in both and promotes the creation of two orthogonal latent vectors. We evaluate our proposed method (OrthoMAD) in five different types of morphing in the FRLL dataset and evaluate the performance of our model when trained on five distinct datasets. With a small ResNet-18 as the backbone, we achieve state-of-the-art results in the majority of the experiments, and competitive results in the others. The code of this paper will be publicly available.