 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of Keratitis from Eye Corneal Photographs using Deep Learning
Nov 13, 2024



Keratitis is an inflammatory corneal condition responsible for 10% of visual impairment in low- and middle-income countries (LMICs), with bacteria, fungi, or amoeba as the most common infection etiologies. While an accurate and timely diagnosis is crucial for the selected treatment and the patients' sight outcomes, due to the high cost and limited availability of laboratory diagnostics in LMICs, diagnosis is often made by clinical observation alone, despite its lower accuracy. In this study, we investigate and compare different deep learning approaches to diagnose the source of infection: 1) three separate binary models for infection type predictions; 2) a multitask model with a shared backbone and three parallel classification layers (Multitask V1); and, 3) a multitask model with a shared backbone and a multi-head classification layer (Multitask V2). We used a private Brazilian cornea dataset to conduct the empirical evaluation. We achieved the best results with Multitask V2, with an area under the receiver operating characteristic curve (AUROC) confidence intervals of 0.7413-0.7740 (bacteria), 0.8395-0.8725 (fungi), and 0.9448-0.9616 (amoeba). A statistical analysis of the impact of patient features on models' performance revealed that sex significantly affects amoeba infection prediction, and age seems to affect fungi and bacteria predictions.
Evaluating the Impact of Pulse Oximetry Bias in Machine Learning under Counterfactual Thinking
Aug 08, 2024



Algorithmic bias in healthcare mirrors existing data biases. However, the factors driving unfairness are not always known. Medical devices capture significant amounts of data but are prone to errors; for instance, pulse oximeters overestimate the arterial oxygen saturation of darker-skinned individuals, leading to worse outcomes. The impact of this bias in machine learning (ML) models remains unclear. This study addresses the technical challenges of quantifying the impact of medical device bias in downstream ML. Our experiments compare a "perfect world", without pulse oximetry bias, using SaO2 (blood-gas), to the "actual world", with biased measurements, using SpO2 (pulse oximetry). Under this counterfactual design, two models are trained with identical data, features, and settings, except for the method of measuring oxygen saturation: models using SaO2 are a "control" and models using SpO2 a "treatment". The blood-gas oximetry linked dataset was a suitable test-bed, containing 163,396 nearly-simultaneous SpO2 - SaO2 paired measurements, aligned with a wide array of clinical features and outcomes. We studied three classification tasks: in-hospital mortality, respiratory SOFA score in the next 24 hours, and SOFA score increase by two points. Models using SaO2 instead of SpO2 generally showed better performance. Patients with overestimation of O2 by pulse oximetry of > 3% had significant decreases in mortality prediction recall, from 0.63 to 0.59, P < 0.001. This mirrors clinical processes where biased pulse oximetry readings provide clinicians with false reassurance of patients' oxygen levels. A similar degradation happened in ML models, with pulse oximetry biases leading to more false negatives in predicting adverse outcomes.
Deep Learning-based Prediction of Breast Cancer Tumor and Immune Phenotypes from Histopathology
Apr 25, 2024



The interactions between tumor cells and the tumor microenvironment (TME) dictate therapeutic efficacy of radiation and many systemic therapies in breast cancer. However, to date, there is not a widely available method to reproducibly measure tumor and immune phenotypes for each patient's tumor. Given this unmet clinical need, we applied multiple instance learning (MIL) algorithms to assess activity of ten biologically relevant pathways from the hematoxylin and eosin (H&E) slide of primary breast tumors. We employed different feature extraction approaches and state-of-the-art model architectures. Using binary classification, our models attained area under the receiver operating characteristic (AUROC) scores above 0.70 for nearly all gene expression pathways and on some cases, exceeded 0.80. Attention maps suggest that our trained models recognize biologically relevant spatial patterns of cell sub-populations from H&E. These efforts represent a first step towards developing computational H&E biomarkers that reflect facets of the TME and hold promise for augmenting precision oncology.
Massively Annotated Datasets for Assessment of Synthetic and Real Data in Face Recognition
Apr 23, 2024



Face recognition applications have grown in parallel with the size of datasets, complexity of deep learning models and computational power. However, while deep learning models evolve to become more capable and computational power keeps increasing, the datasets available are being retracted and removed from public access. Privacy and ethical concerns are relevant topics within these domains. Through generative artificial intelligence, researchers have put efforts into the development of completely synthetic datasets that can be used to train face recognition systems. Nonetheless, the recent advances have not been sufficient to achieve performance comparable to the state-of-the-art models trained on real data. To study the drift between the performance of models trained on real and synthetic datasets, we leverage a massive attribute classifier (MAC) to create annotations for four datasets: two real and two synthetic. From these annotations, we conduct studies on the distribution of each attribute within all four datasets. Additionally, we further inspect the differences between real and synthetic datasets on the attribute set. When comparing through the Kullback-Leibler divergence we have found differences between real and synthetic samples. Interestingly enough, we have verified that while real samples suffice to explain the synthetic distribution, the opposite could not be further from being true.
Unveiling the Two-Faced Truth: Disentangling Morphed Identities for Face Morphing Detection
Jun 05, 2023

Morphing attacks keep threatening biometric systems, especially face recognition systems. Over time they have become simpler to perform and more realistic, as such, the usage of deep learning systems to detect these attacks has grown. At the same time, there is a constant concern regarding the lack of interpretability of deep learning models. Balancing performance and interpretability has been a difficult task for scientists. However, by leveraging domain information and proving some constraints, we have been able to develop IDistill, an interpretable method with state-of-the-art performance that provides information on both the identity separation on morph samples and their contribution to the final prediction. The domain information is learnt by an autoencoder and distilled to a classifier system in order to teach it to separate identity information. When compared to other methods in the literature it outperforms them in three out of five databases and is competitive in the remaining.
OrthoMAD: Morphing Attack Detection Through Orthogonal Identity Disentanglement
Aug 23, 2022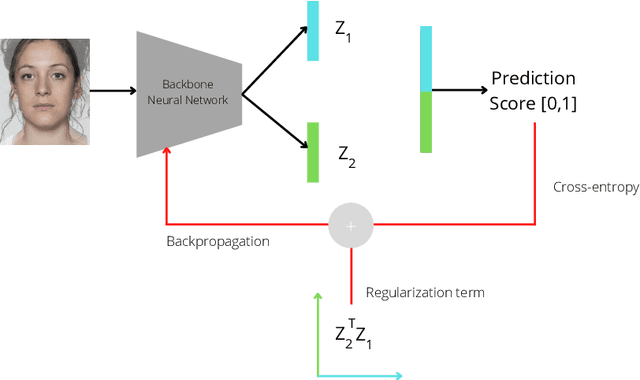
Morphing attacks are one of the many threats that are constantly affecting deep face recognition systems. It consists of selecting two faces from different individuals and fusing them into a final image that contains the identity information of both. In this work, we propose a novel regularisation term that takes into account the existent identity information in both and promotes the creation of two orthogonal latent vectors. We evaluate our proposed method (OrthoMAD) in five different types of morphing in the FRLL dataset and evaluate the performance of our model when trained on five distinct datasets. With a small ResNet-18 as the backbone, we achieve state-of-the-art results in the majority of the experiments, and competitive results in the others. The code of this paper will be publicly available.
Explainable Biometrics in the Age of Deep Learning
Aug 19, 2022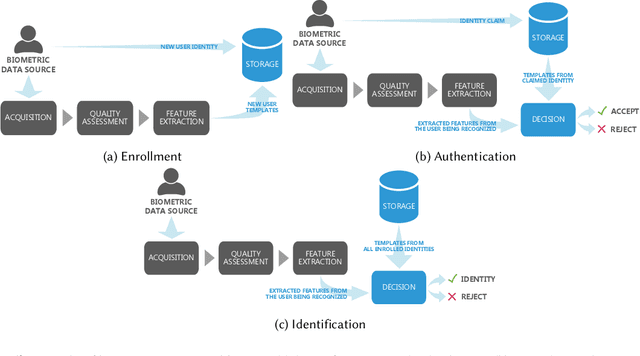
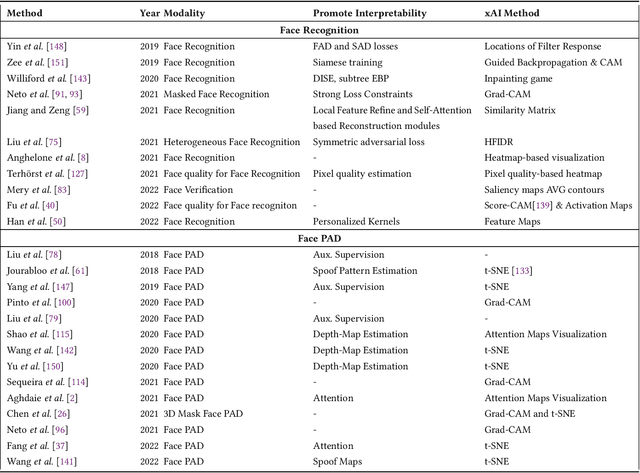
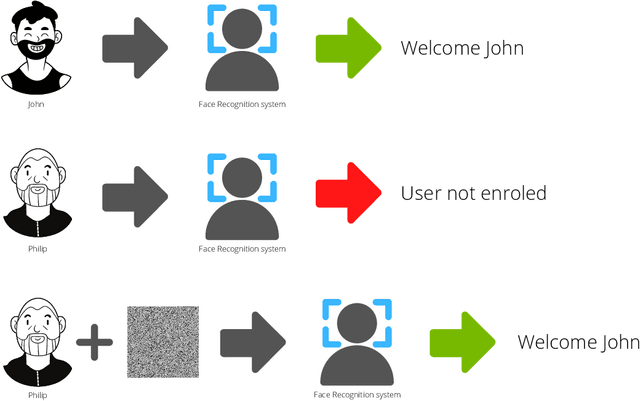
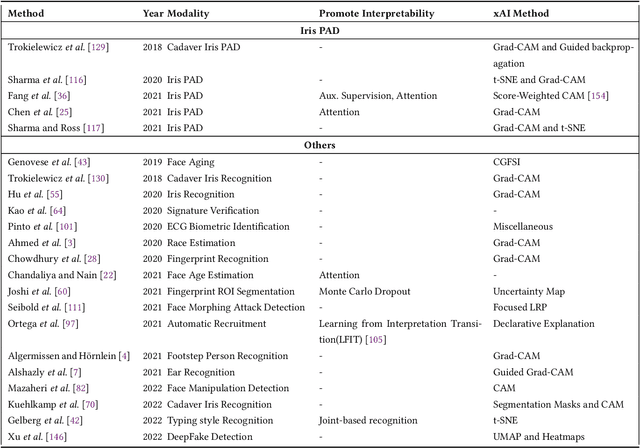
Systems capable of analyzing and quantifying human physical or behavioral traits, known as biometrics systems, are growing in use and application variability. Since its evolution from handcrafted features and traditional machine learning to deep learning and automatic feature extraction, the performance of biometric systems increased to outstanding values. Nonetheless, the cost of this fast progression is still not understood. Due to its opacity, deep neural networks are difficult to understand and analyze, hence, hidden capacities or decisions motivated by the wrong motives are a potential risk. Researchers have started to pivot their focus towards the understanding of deep neural networks and the explanation of their predictions. In this paper, we provide a review of the current state of explainable biometrics based on the study of 47 papers and discuss comprehensively the direction in which this field should be developed.
SYN-MAD 2022: Competition on Face Morphing Attack Detection Based on Privacy-aware Synthetic Training Data
Aug 15, 2022
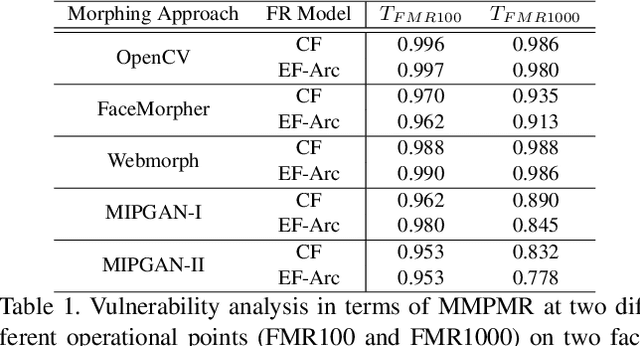
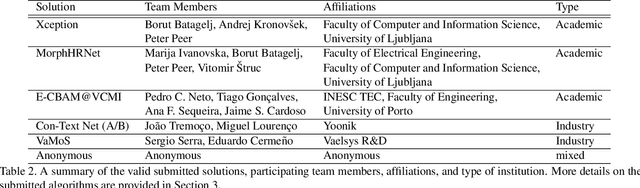
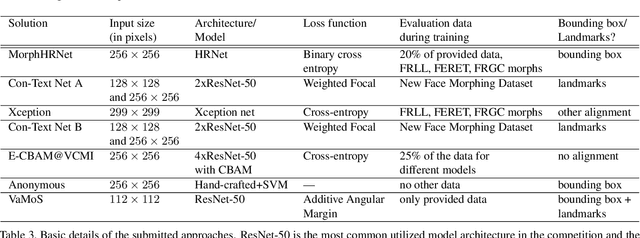
This paper presents a summary of the Competition on Face Morphing Attack Detection Based on Privacy-aware Synthetic Training Data (SYN-MAD) held at the 2022 International Joint Conference on Biometrics (IJCB 2022). The competition attracted a total of 12 participating teams, both from academia and industry and present in 11 different countries. In the end, seven valid submissions were submitted by the participating teams and evaluated by the organizers. The competition was held to present and attract solutions that deal with detecting face morphing attacks while protecting people's privacy for ethical and legal reasons. To ensure this, the training data was limited to synthetic data provided by the organizers. The submitted solutions presented innovations that led to outperforming the considered baseline in many experimental settings. The evaluation benchmark is now available at: https://github.com/marcohuber/SYN-MAD-2022.
A survey on attention mechanisms for medical applications: are we moving towards better algorithms?
Apr 26, 2022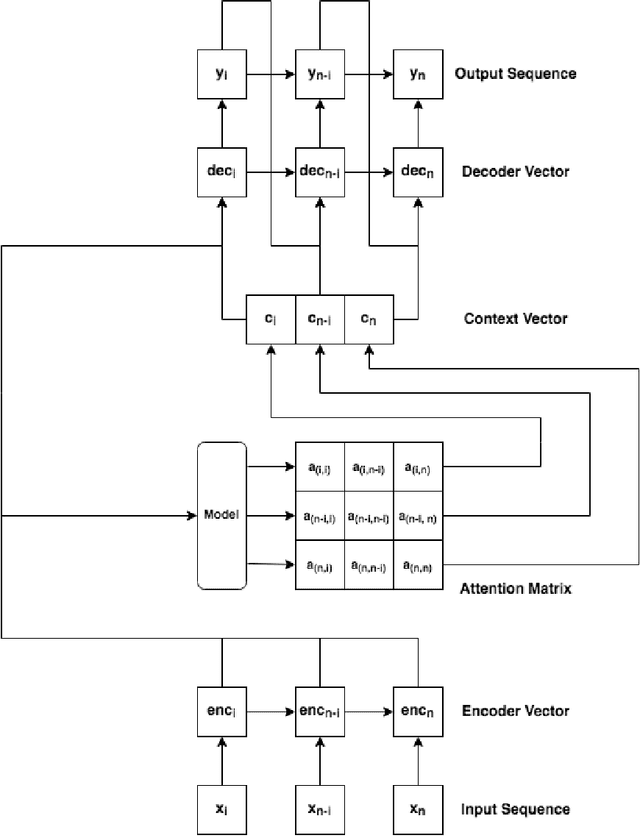

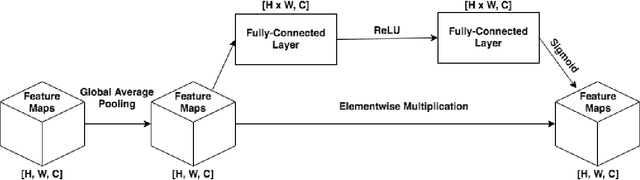
The increasing popularity of attention mechanisms in deep learning algorithms for computer vision and natural language processing made these models attractive to other research domains. In healthcare, there is a strong need for tools that may improve the routines of the clinicians and the patients. Naturally, the use of attention-based algorithms for medical applications occurred smoothly. However, being healthcare a domain that depends on high-stake decisions, the scientific community must ponder if these high-performing algorithms fit the needs of medical applications. With this motto, this paper extensively reviews the use of attention mechanisms in machine learning (including Transformers) for several medical applications. This work distinguishes itself from its predecessors by proposing a critical analysis of the claims and potentialities of attention mechanisms presented in the literature through an experimental case study on medical image classification with three different use cases. These experiments focus on the integrating process of attention mechanisms into established deep learning architectures, the analysis of their predictive power, and a visual assessment of their saliency maps generated by post-hoc explanation methods. This paper concludes with a critical analysis of the claims and potentialities presented in the literature about attention mechanisms and proposes future research lines in medical applications that may benefit from these frameworks.