 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-objective and multi-fidelity Bayesian optimization of laser-plasma acceleration
Oct 07, 2022
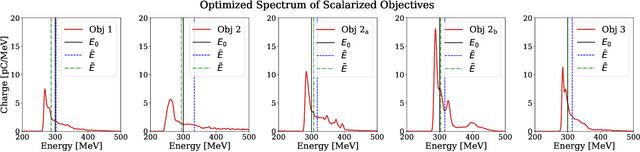
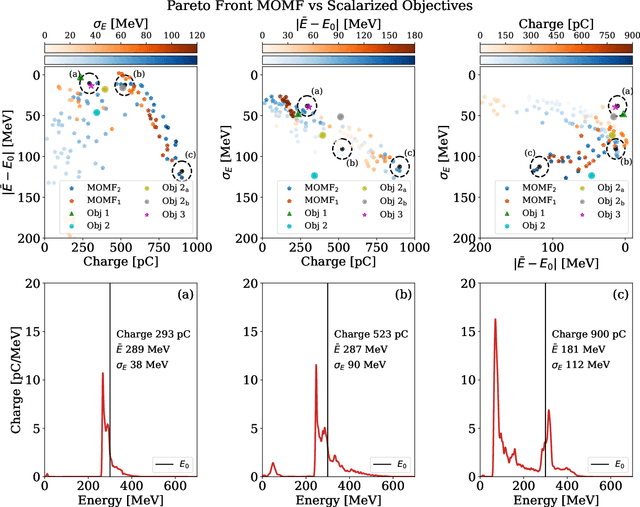
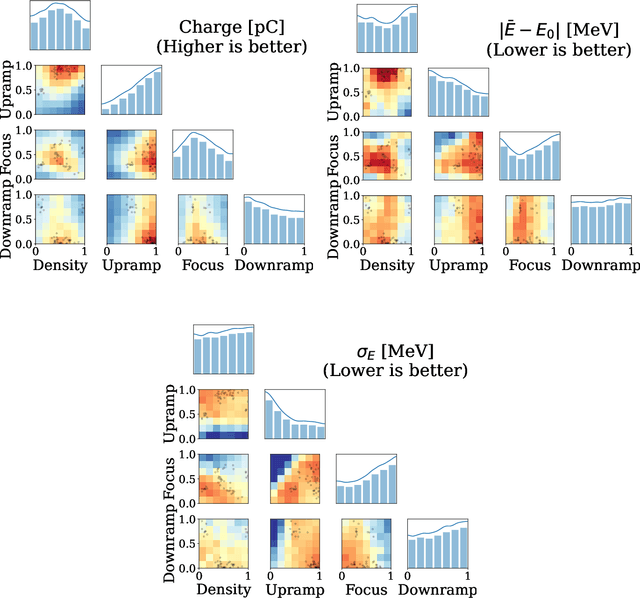
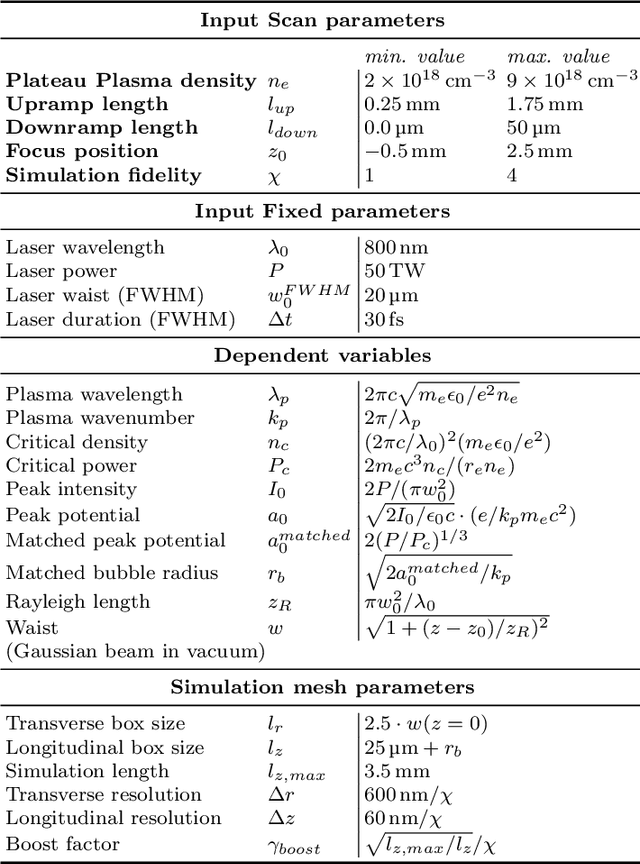
Beam parameter optimization in accelerators involves multiple, sometimes competing objectives. Condensing these multiple objectives into a single objective unavoidably results in bias towards particular outcomes that do not necessarily represent the best possible outcome for the operator in terms of parameter optimization. A more versatile approach is multi-objective optimization, which establishes the trade-off curve or Pareto front between objectives. Here we present first results on multi-objective Bayesian optimization of a simulated laser-plasma accelerator. We find that multi-objective optimization is equal or even superior in performance to its single-objective counterparts, and that it is more resilient to different statistical descriptions of objectives. As a second major result of our paper, we significantly reduce the computational costs of the optimization by choosing the resolution and box size of the simulations dynamically. This is relevant since even with the use of Bayesian statistics, performing such optimizations on a multi-dimensional search space may require hundreds or thousands of simulations. Our algorithm translates information gained from fast, low-resolution runs with lower fidelity to high-resolution data, thus requiring fewer actual simulations at highest computational cost. The techniques demonstrated in this paper can be translated to many different use cases, both computational and experimental.
Pose Guided Human Image Synthesis with Partially Decoupled GAN
Oct 07, 2022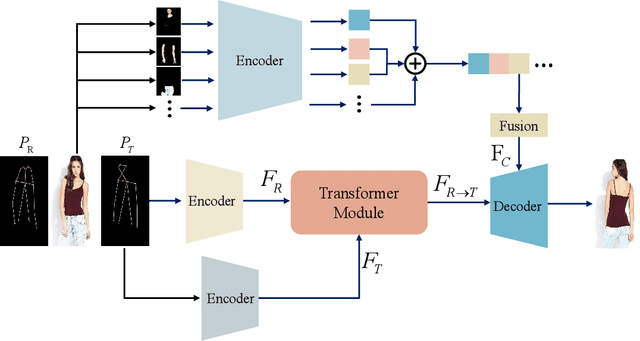
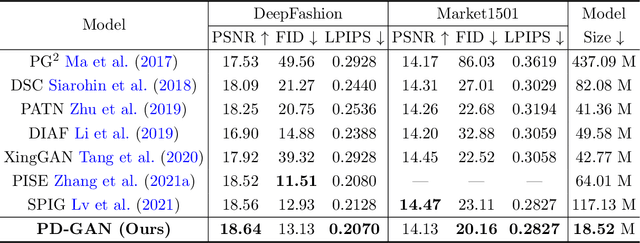
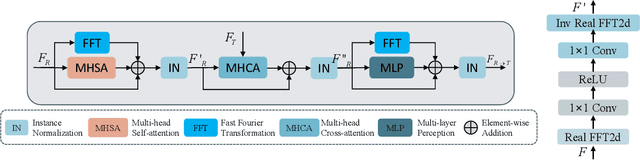

Pose Guided Human Image Synthesis (PGHIS) is a challenging task of transforming a human image from the reference pose to a target pose while preserving its style. Most existing methods encode the texture of the whole reference human image into a latent space, and then utilize a decoder to synthesize the image texture of the target pose. However, it is difficult to recover the detailed texture of the whole human image. To alleviate this problem, we propose a method by decoupling the human body into several parts (\eg, hair, face, hands, feet, \etc) and then using each of these parts to guide the synthesis of a realistic image of the person, which preserves the detailed information of the generated images. In addition, we design a multi-head attention-based module for PGHIS. Because most convolutional neural network-based methods have difficulty in modeling long-range dependency due to the convolutional operation, the long-range modeling capability of attention mechanism is more suitable than convolutional neural networks for pose transfer task, especially for sharp pose deformation. Extensive experiments on Market-1501 and DeepFashion datasets reveal that our method almost outperforms other existing state-of-the-art methods in terms of both qualitative and quantitative metrics.
Few-Shot Anaphora Resolution in Scientific Protocols via Mixtures of In-Context Experts
Oct 07, 2022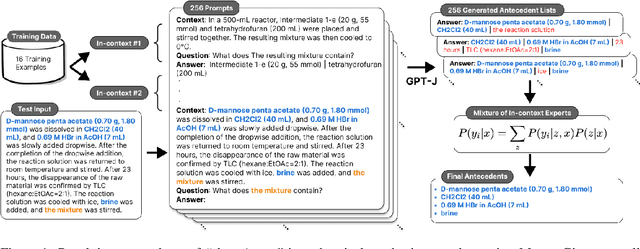
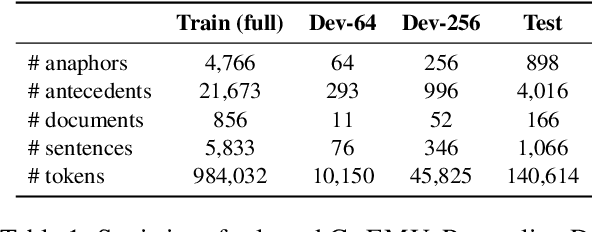
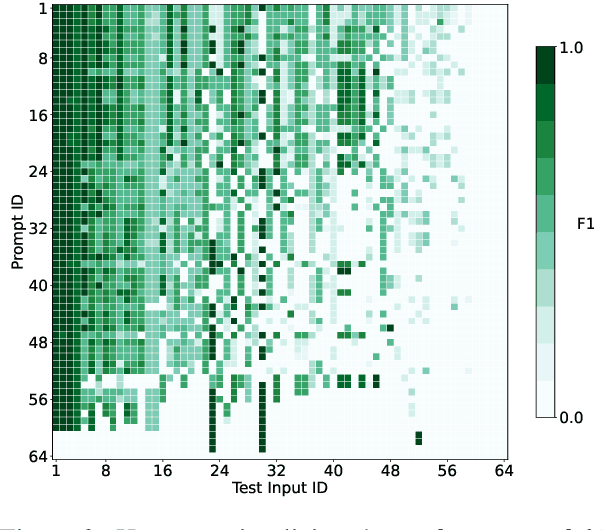
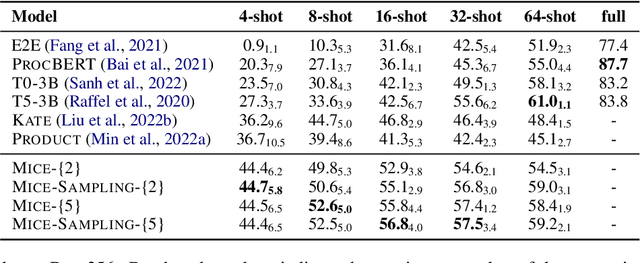
Anaphora resolution is an important task for information extraction across a range of languages, text genres, and domains, motivating the need for methods that do not require large annotated datasets. In-context learning has emerged as a promising approach, yet there are a number of challenges in applying in-context learning to resolve anaphora. For example, encoding a single in-context demonstration that consists of: an anaphor, a paragraph-length context, and a list of corresponding antecedents, requires conditioning a language model on a long sequence of tokens, limiting the number of demonstrations per prompt. In this paper, we present MICE (Mixtures of In-Context Experts), which we demonstrate is effective for few-shot anaphora resolution in scientific protocols (Tamari et al., 2021). Given only a handful of training examples, MICE combines the predictions of hundreds of in-context experts, yielding a 30% increase in F1 score over a competitive prompt retrieval baseline. Furthermore, we show MICE can be used to train compact student models without sacrificing performance. As far as we are aware, this is the first work to present experimental results demonstrating the effectiveness of in-context learning on the task of few-shot anaphora resolution in scientific protocols.
Self-Supervised Pyramid Representation Learning for Multi-Label Visual Analysis and Beyond
Aug 30, 2022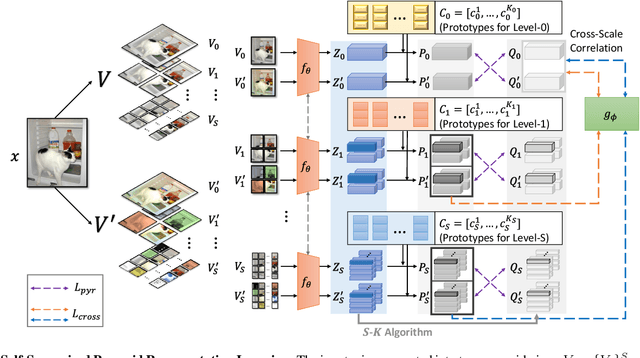
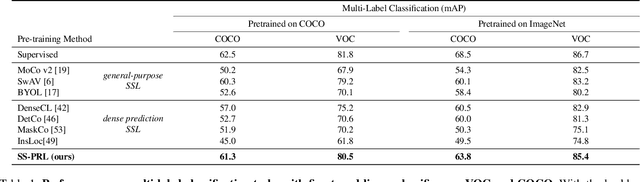
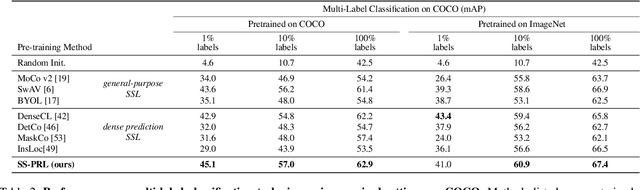
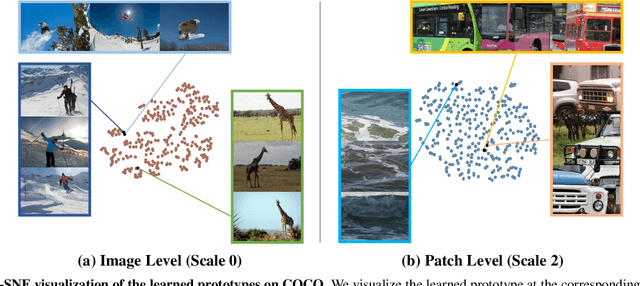
While self-supervised learning has been shown to benefit a number of vision tasks, existing techniques mainly focus on image-level manipulation, which may not generalize well to downstream tasks at patch or pixel levels. Moreover, existing SSL methods might not sufficiently describe and associate the above representations within and across image scales. In this paper, we propose a Self-Supervised Pyramid Representation Learning (SS-PRL) framework. The proposed SS-PRL is designed to derive pyramid representations at patch levels via learning proper prototypes, with additional learners to observe and relate inherent semantic information within an image. In particular, we present a cross-scale patch-level correlation learning in SS-PRL, which allows the model to aggregate and associate information learned across patch scales. We show that, with our proposed SS-PRL for model pre-training, one can easily adapt and fine-tune the models for a variety of applications including multi-label classification, object detection, and instance segmentation.
Zero-Shot Retargeting of Learned Quadruped Locomotion Policies Using Hybrid Kinodynamic Model Predictive Control
Sep 28, 2022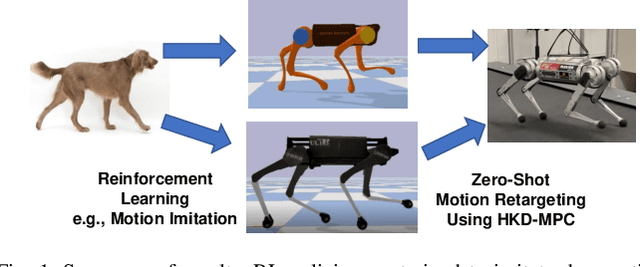
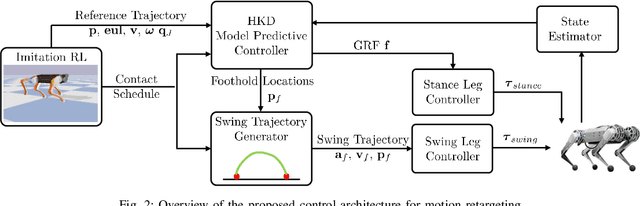


Reinforcement Learning (RL) has witnessed great strides for quadruped locomotion, with continued progress in the reliable sim-to-real transfer of policies. However, it remains a challenge to reuse a policy on another robot, which could save time for retraining. In this work, we present a framework for zero-shot policy retargeting wherein diverse motor skills can be transferred between robots of different shapes and sizes. The new framework centers on a planning-and-control pipeline that systematically integrates RL and Model Predictive Control (MPC). The planning stage employs RL to generate a dynamically plausible trajectory as well as the contact schedule, avoiding the combinatorial complexity of contact sequence optimization. This information is then used to seed the MPC to stabilize and robustify the policy roll-out via a new Hybrid Kinodynamic (HKD) model that implicitly optimizes the foothold locations. Hardware results show an ability to transfer policies from both the A1 and Laikago robots to the MIT Mini Cheetah robot without requiring any policy re-tuning.
Weighted Contrastive Hashing
Sep 28, 2022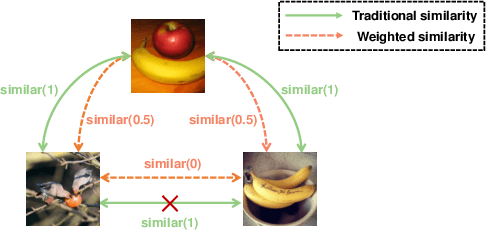
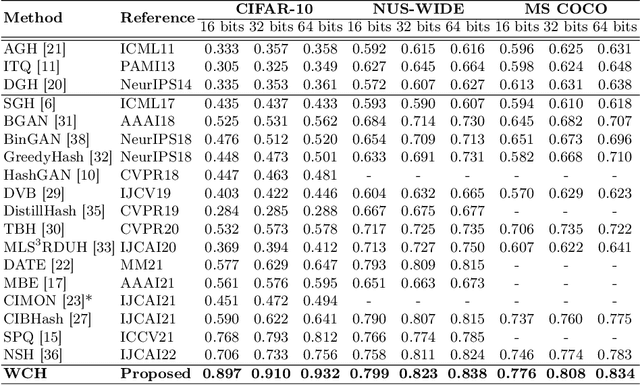
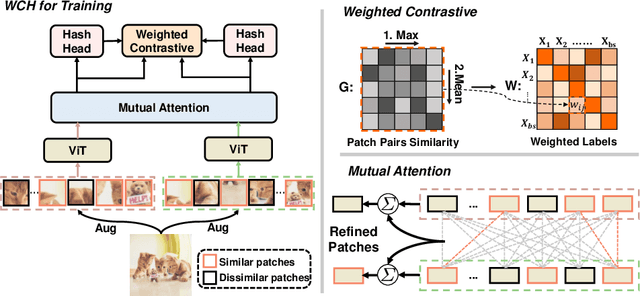
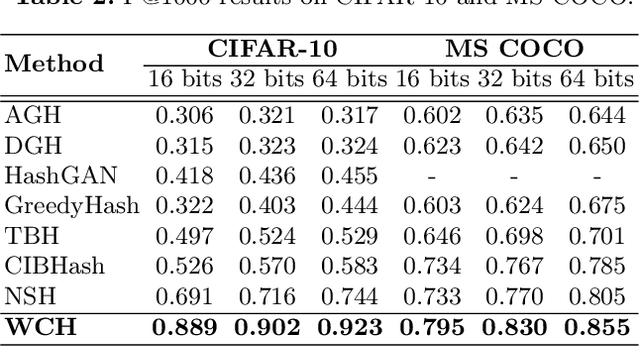
The development of unsupervised hashing is advanced by the recent popular contrastive learning paradigm. However, previous contrastive learning-based works have been hampered by (1) insufficient data similarity mining based on global-only image representations, and (2) the hash code semantic loss caused by the data augmentation. In this paper, we propose a novel method, namely Weighted Contrative Hashing (WCH), to take a step towards solving these two problems. We introduce a novel mutual attention module to alleviate the problem of information asymmetry in network features caused by the missing image structure during contrative augmentation. Furthermore, we explore the fine-grained semantic relations between images, i.e., we divide the images into multiple patches and calculate similarities between patches. The aggregated weighted similarities, which reflect the deep image relations, are distilled to facilitate the hash codes learning with a distillation loss, so as to obtain better retrieval performance. Extensive experiments show that the proposed WCH significantly outperforms existing unsupervised hashing methods on three benchmark datasets.
RGB-D Saliency Detection via Cascaded Mutual Information Minimization
Sep 15, 2021

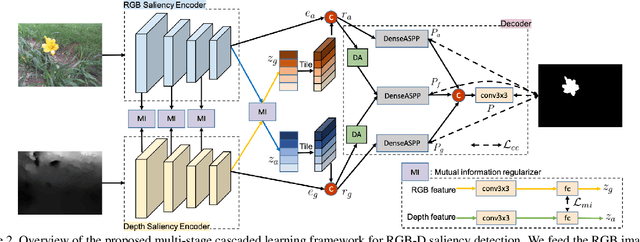
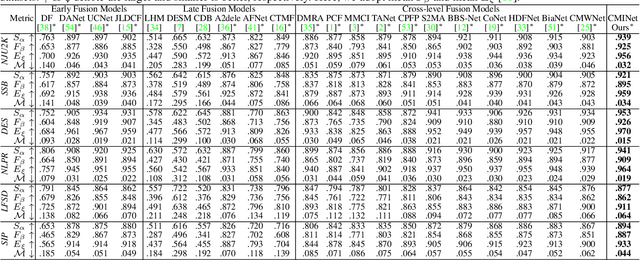
Existing RGB-D saliency detection models do not explicitly encourage RGB and depth to achieve effective multi-modal learning. In this paper, we introduce a novel multi-stage cascaded learning framework via mutual information minimization to "explicitly" model the multi-modal information between RGB image and depth data. Specifically, we first map the feature of each mode to a lower dimensional feature vector, and adopt mutual information minimization as a regularizer to reduce the redundancy between appearance features from RGB and geometric features from depth. We then perform multi-stage cascaded learning to impose the mutual information minimization constraint at every stage of the network. Extensive experiments on benchmark RGB-D saliency datasets illustrate the effectiveness of our framework. Further, to prosper the development of this field, we contribute the largest (7x larger than NJU2K) dataset, which contains 15,625 image pairs with high quality polygon-/scribble-/object-/instance-/rank-level annotations. Based on these rich labels, we additionally construct four new benchmarks with strong baselines and observe some interesting phenomena, which can motivate future model design. Source code and dataset are available at "https://github.com/JingZhang617/cascaded_rgbd_sod".
Dual Representation Learning for One-Step Clustering of Multi-View Data
Aug 30, 2022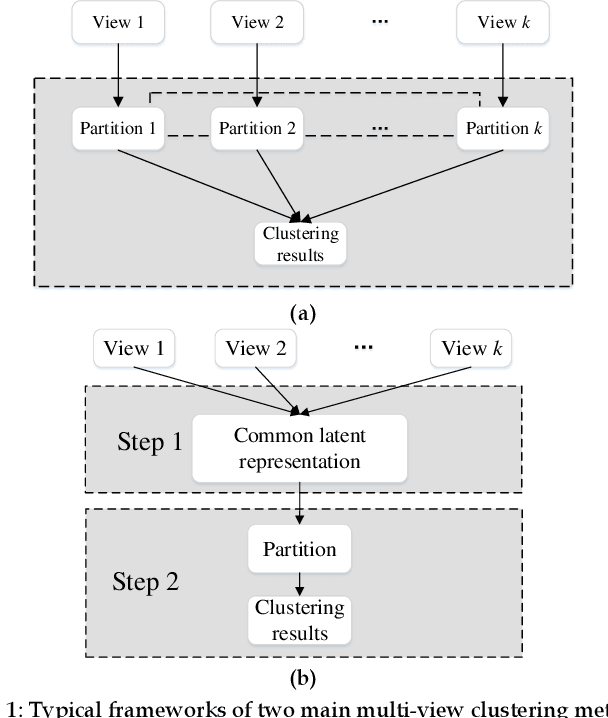
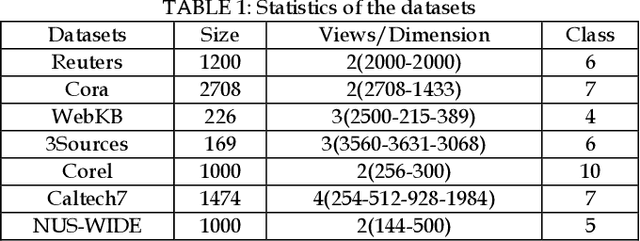
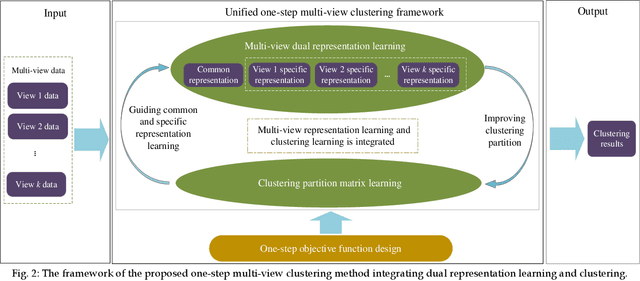
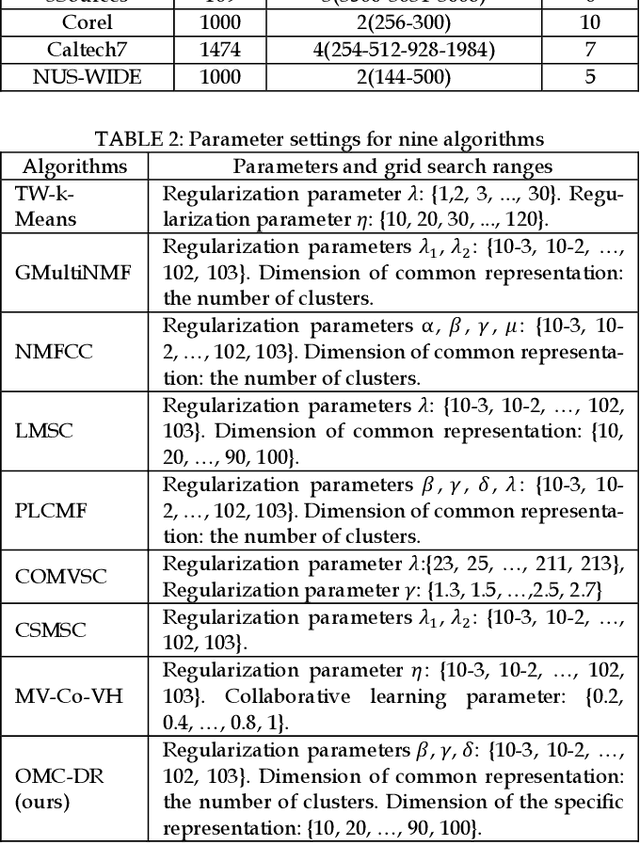
Multi-view data are commonly encountered in data mining applications. Effective extraction of information from multi-view data requires specific design of clustering methods to cater for data with multiple views, which is non-trivial and challenging. In this paper, we propose a novel one-step multi-view clustering method by exploiting the dual representation of both the common and specific information of different views. The motivation originates from the rationale that multi-view data contain not only the consistent knowledge between views but also the unique knowledge of each view. Meanwhile, to make the representation learning more specific to the clustering task, a one-step learning framework is proposed to integrate representation learning and clustering partition as a whole. With this framework, the representation learning and clustering partition mutually benefit each other, which effectively improve the clustering performance. Results from extensive experiments conducted on benchmark multi-view datasets clearly demonstrate the superiority of the proposed method.
Optimal Power Allocation for Integrated Visible Light Positioning and Communication System with a Single LED-Lamp
Aug 30, 2022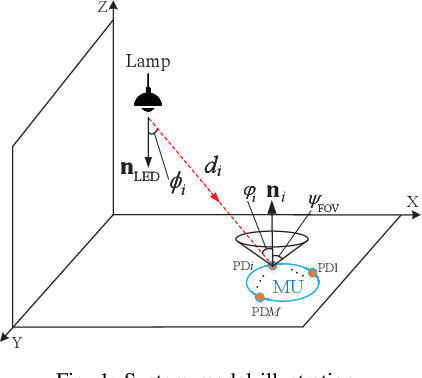
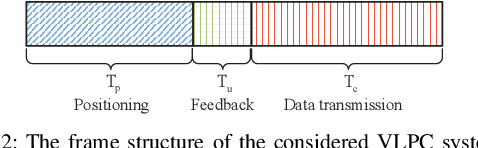
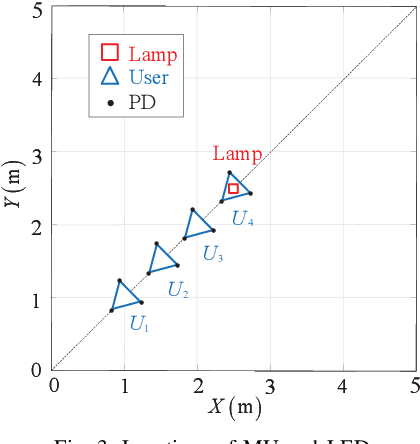
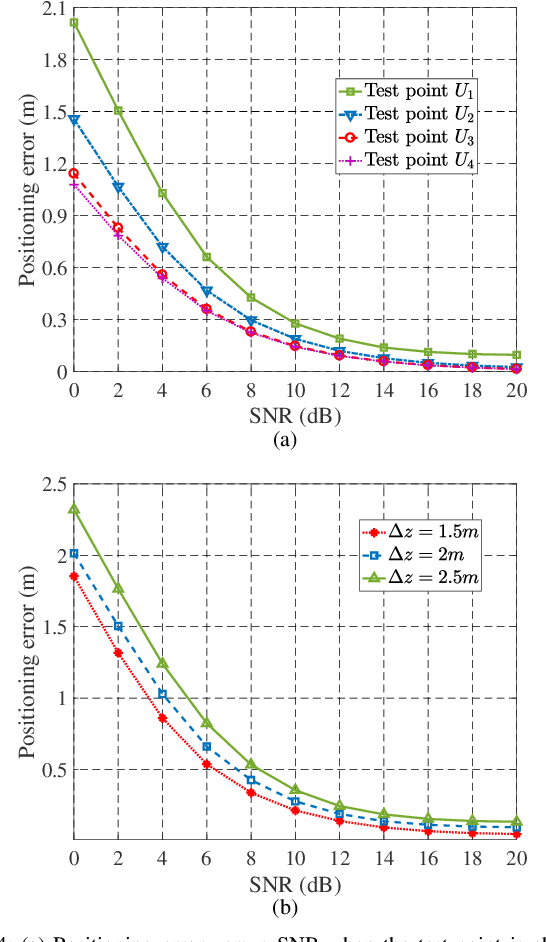
In this paper, we investigate an integrated visible light positioning and communication (VLPC) system with a single LED-lamp. First, by leveraging the fact that the VLC channel model is a function of the receiver's location, we propose a system model that estimates the channel state information (CSI) based on the positioning information without transmitting pilot sequences. Second, we derive the Cramer-Rao lower bound (CRLB) on the positioning error variance and a lower bound on the achievable rate with on-off keying modulation. Third, based on the derived performance metrics, we optimize the power allocation to minimize the CRLB, while satisfying the rate outage probability constraint. To tackle this non-convex optimization problem, we apply the worst-case distribution of the Conditional Value-at-Risk (CVaR) and the block coordinate descent (BCD) methods to obtain the feasible solutions. Finally, the effects of critical system parameters, such as outage probability, rate threshold, total power threshold, are revealed by numerical results.
Gated Information Bottleneck for Generalization in Sequential Environments
Oct 12, 2021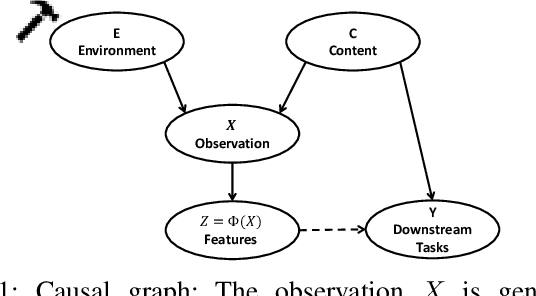
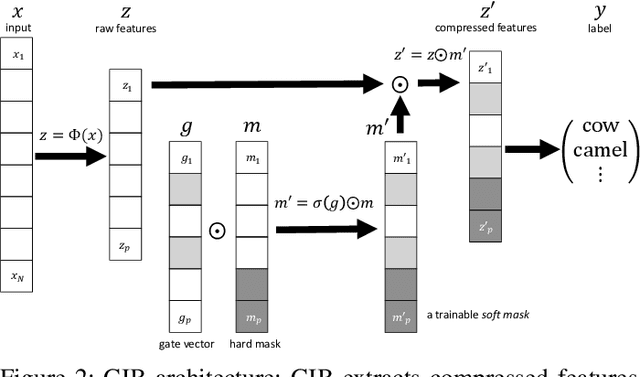
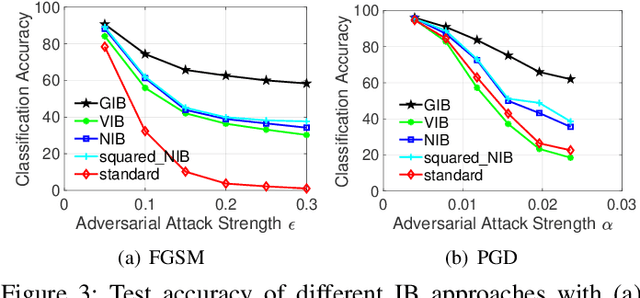
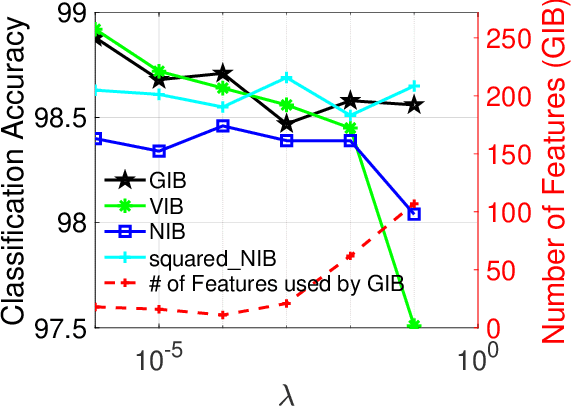
Deep neural networks suffer from poor generalization to unseen environments when the underlying data distribution is different from that in the training set. By learning minimum sufficient representations from training data, the information bottleneck (IB) approach has demonstrated its effectiveness to improve generalization in different AI applications. In this work, we propose a new neural network-based IB approach, termed gated information bottleneck (GIB), that dynamically drops spurious correlations and progressively selects the most task-relevant features across different environments by a trainable soft mask (on raw features). GIB enjoys a simple and tractable objective, without any variational approximation or distributional assumption. We empirically demonstrate the superiority of GIB over other popular neural network-based IB approaches in adversarial robustness and out-of-distribution (OOD) detection. Meanwhile, we also establish the connection between IB theory and invariant causal representation learning, and observed that GIB demonstrates appealing performance when different environments arrive sequentially, a more practical scenario where invariant risk minimization (IRM) fails. Code of GIB is available at https://github.com/falesiani/GIB