 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Average Mutual Information of MIMO Keyhole Channels with Finite Inputs
Dec 08, 2021
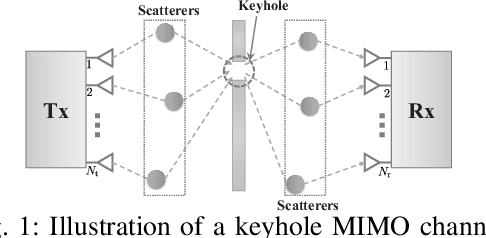
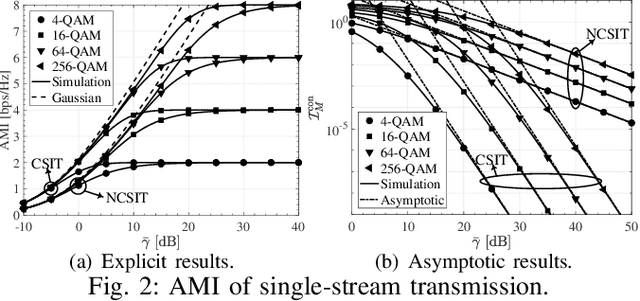
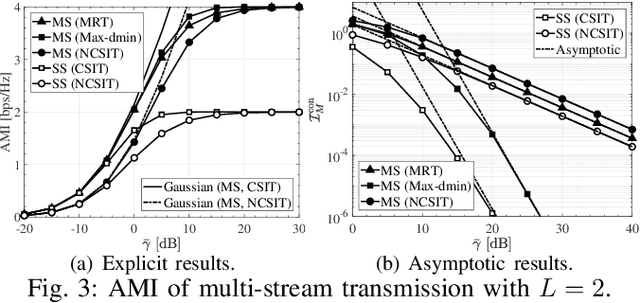
This letter studies the average mutual information (AMI) of keyhole multiple-input multiple-output (MIMO) systems having finite input signals. At first, the AMI of single-stream transmission is investigated under two cases where the state information at the transmitter (CSIT) is available or not. Then, the derived results are further extended to the case of multi-stream transmission. For the sake of providing more system insights, asymptotic analyses are performed in the regime of high signal-to-noise ratio (SNR), which suggests that the high-SNR AMI converges to some constant with its rate of convergence determined by the diversity order. All the results are validated by numerical simulations and are in excellent agreement.
Convolutional Neural Network-Based Image Watermarking using Discrete Wavelet Transform
Oct 08, 2022
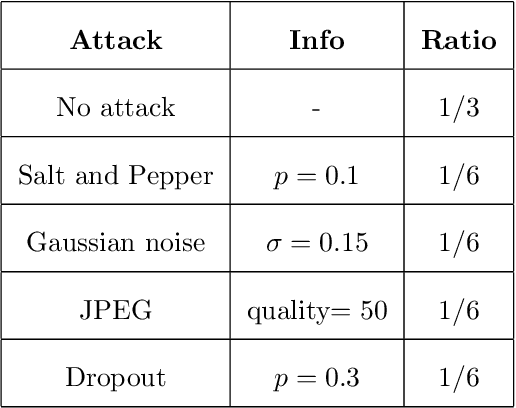
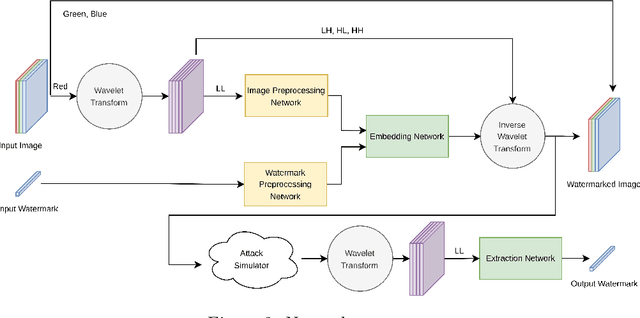
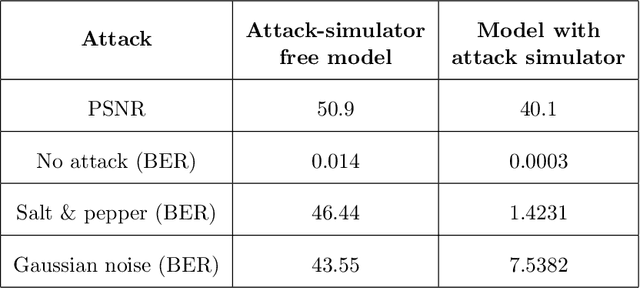
As the Internet becomes more popular, digital images are used and transferred more frequently. Although this phenomenon facilitates easy access to information, it also creates security concerns and violates intellectual property rights by allowing illegal use, copying, and digital content theft. Using watermarks (WMs) in digital images is one of the most common ways to maintain security. Watermarking is proving and declaring ownership of an image by adding a digital watermark to the original image. Watermarks can be either text or an image placed overtly or covertly in an image and are expected to be challenging to remove. This paper proposes a combination of convolutional neural networks (CNNs) and wavelet transforms to obtain a watermarking network for embedding and extracting watermarks. The network is independent of the host image resolution, can accept all kinds of watermarks, and has only 11 CNN layers while keeping performance. Two terms measure performance; the similarity between the extracted watermark and the original one and the similarity between the host image and the watermarked one.
(Fusionformer):Exploiting the Joint Motion Synergy with Fusion Network Based On Transformer for 3D Human Pose Estimation
Oct 08, 2022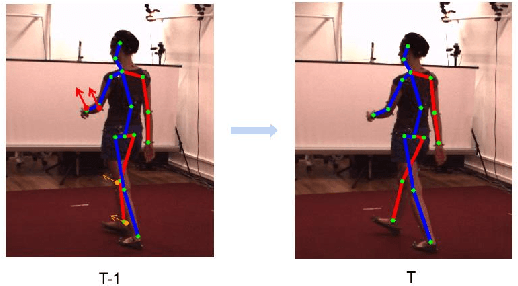
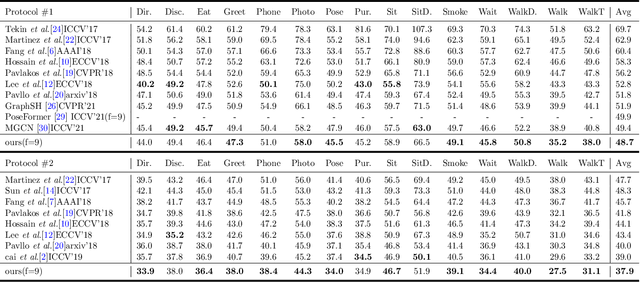

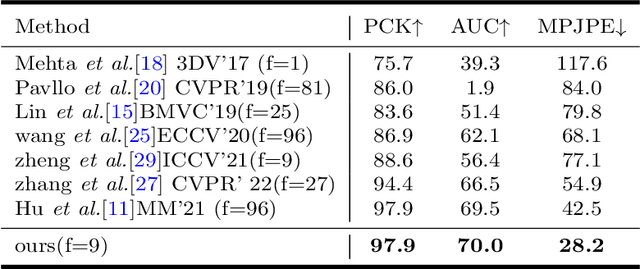
For the current 3D human pose estimation task, in order to improve the efficiency of pose sequence output, we try to further improve the prediction stability in low input video frame scenarios.Many previous methods lack the understanding of local joint information.\cite{9878888}considers the temporal relationship of a single joint in this work.However, we found that there is a certain predictive correlation between the trajectories of different joints in time.Therefore, our proposed \textbf{Fusionformer} method introduces a self-trajectory module and a cross-trajectory module based on the spatio-temporal module.After that, the global spatio-temporal features and local joint trajectory features are fused through a linear network in a parallel manner.To eliminate the influence of bad 2D poses on 3D projections, finally we also introduce a pose refinement network to balance the consistency of 3D projections.In addition, we evaluate the proposed method on two benchmark datasets (Human3.6M, MPI-INF-3DHP). Comparing our method with the baseline method poseformer, the results show an improvement of 2.4\% MPJPE and 4.3\% P-MPJPE on the Human3.6M dataset, respectively.
EDU-level Extractive Summarization with Varying Summary Lengths
Oct 08, 2022
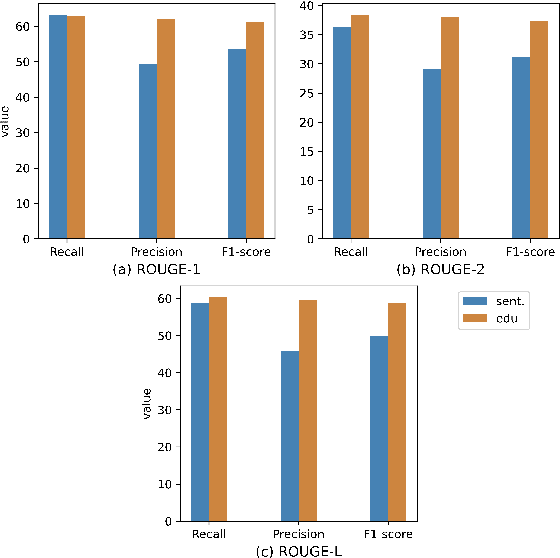
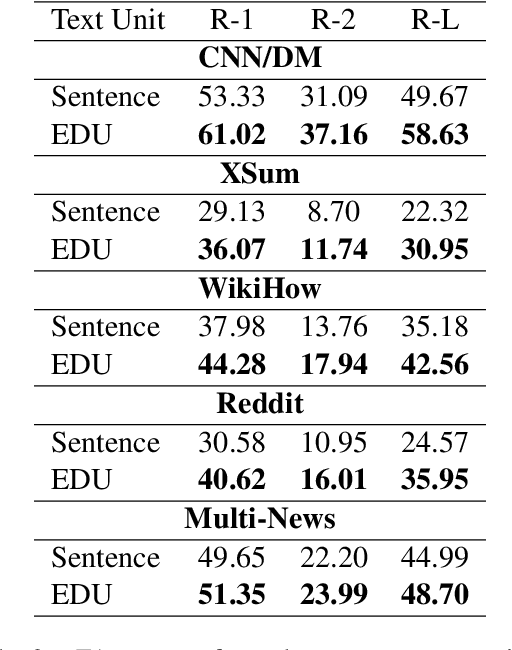
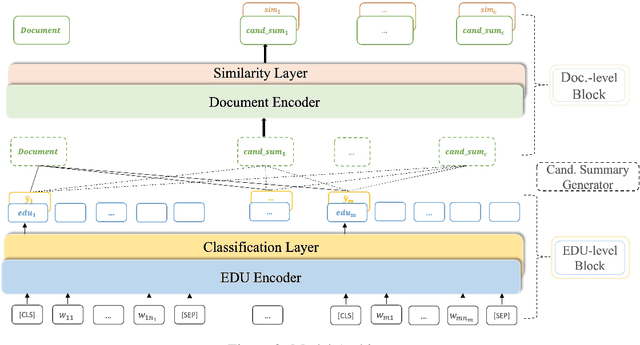
Extractive models usually formulate text summarization as extracting top-k important sentences from document as summary. Few work exploited extracting finer-grained Elementary Discourse Unit (EDU) and there is little analysis and justification for the extractive unit selection. To fill such a gap, this paper firstly conducts oracle analysis to compare the upper bound of performance for models based on EDUs and sentences. The analysis provides evidences from both theoretical and experimental perspectives to justify that EDUs make more concise and precise summary than sentences without losing salient information. Then, considering this merit of EDUs, this paper further proposes EDU-level extractive model with Varying summary Lengths (EDU-VL) and develops the corresponding learning algorithm. EDU-VL learns to encode and predict probabilities of EDUs in document, and encode EDU-level candidate summaries with different lengths based on various $k$ values and select the best candidate summary in an end-to-end training manner. Finally, the proposed and developed approach is experimented on single and multi-document benchmark datasets and shows the improved performances in comparison with the state-of-the-art models.
An Ordinal Latent Variable Model of Conflict Intensity
Oct 08, 2022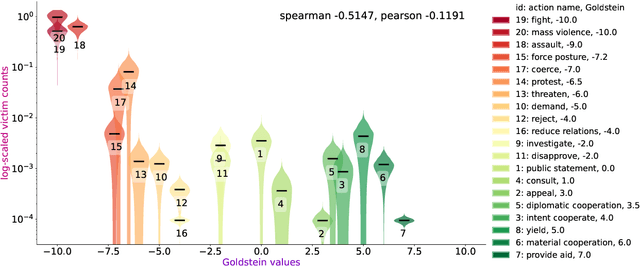
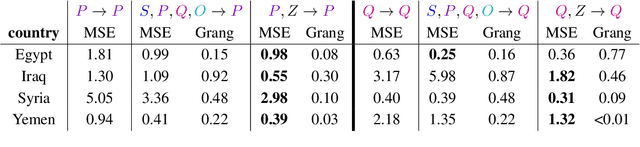
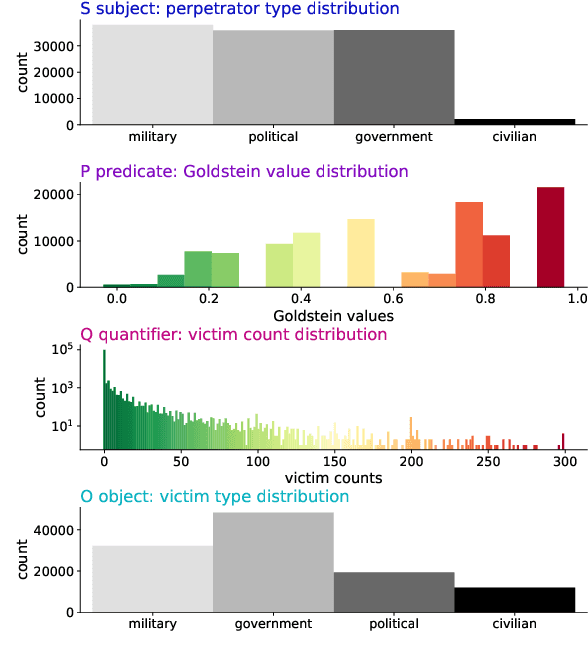

For the quantitative monitoring of international relations, political events are extracted from the news and parsed into "who-did-what-to-whom" patterns. This has resulted in large data collections which require aggregate statistics for analysis. The Goldstein Scale is an expert-based measure that ranks individual events on a one-dimensional scale from conflictual to cooperative. However, the scale disregards fatality counts as well as perpetrator and victim types involved in an event. This information is typically considered in qualitative conflict assessment. To address this limitation, we propose a probabilistic generative model over the full subject-predicate-quantifier-object tuples associated with an event. We treat conflict intensity as an interpretable, ordinal latent variable that correlates conflictual event types with high fatality counts. Taking a Bayesian approach, we learn a conflict intensity scale from data and find the optimal number of intensity classes. We evaluate the model by imputing missing data. Our scale proves to be more informative than the original Goldstein Scale in autoregressive forecasting and when compared with global online attention towards armed conflicts.
Hierarchical Adversarial Inverse Reinforcement Learning
Oct 05, 2022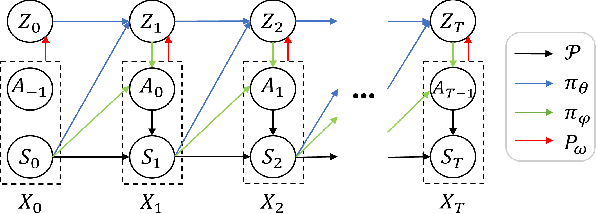
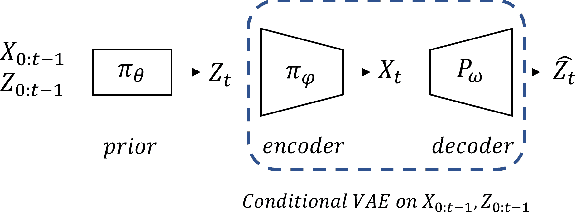
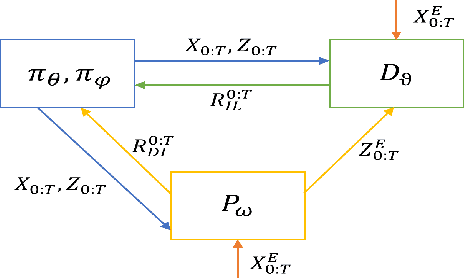
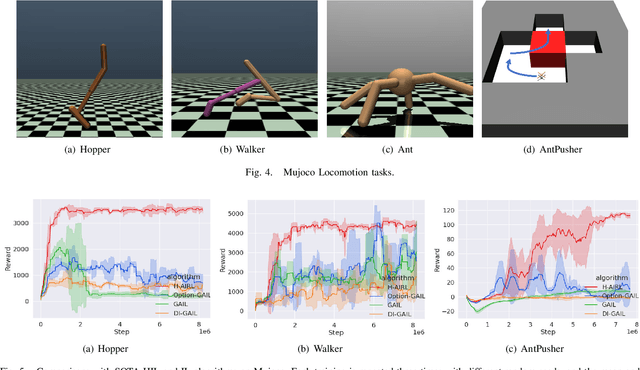
Hierarchical Imitation Learning (HIL) has been proposed to recover highly-complex behaviors in long-horizontal tasks from expert demonstrations by modeling the task hierarchy with the option framework. Existing methods either overlook the causal relationship between the subtask and its corresponding policy or fail to learn the policy in an end-to-end fashion, which leads to suboptimality. In this work, we develop a novel HIL algorithm based on Adversarial Inverse Reinforcement Learning and adapt it with the Expectation-Maximization algorithm in order to directly recover a hierarchical policy from the unannotated demonstrations. Further, we introduce a directed information term to the objective function to enhance the causality and propose a Variational Autoencoder framework for learning with our objectives in an end-to-end fashion. Theoretical justifications and evaluations on challenging robotic control tasks are provided to show the superiority of our algorithm. The codes are available at https://github.com/LucasCJYSDL/HierAIRL.
Exploration of A Self-Supervised Speech Model: A Study on Emotional Corpora
Oct 05, 2022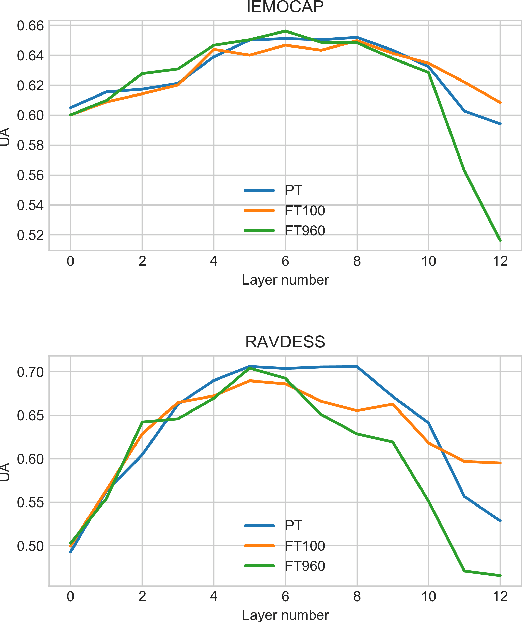
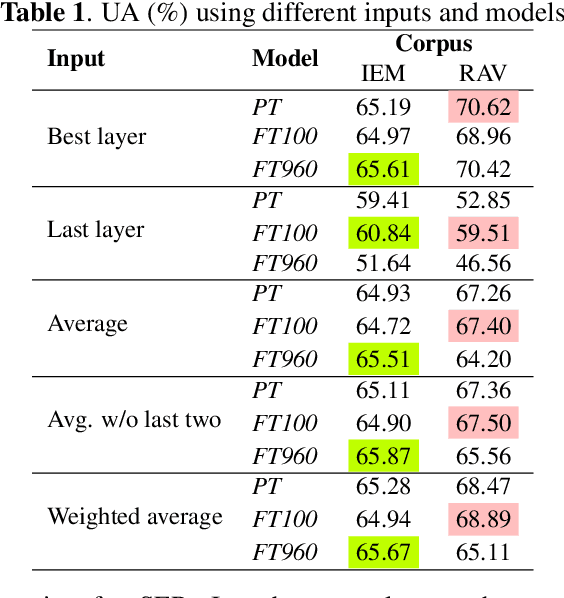
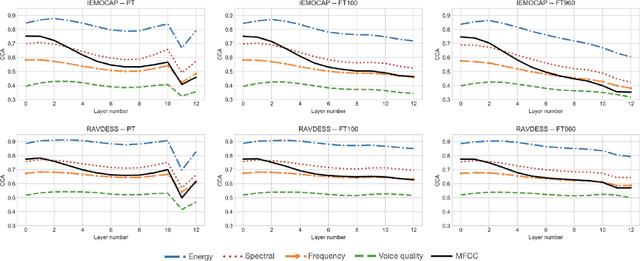

Self-supervised speech models have grown fast during the past few years and have proven feasible for use in various downstream tasks. Some recent work has started to look at the characteristics of these models, yet many concerns have not been fully addressed. In this work, we conduct a study on emotional corpora to explore a popular self-supervised model -- wav2vec 2.0. Via a set of quantitative analysis, we mainly demonstrate that: 1) wav2vec 2.0 appears to discard paralinguistic information that is less useful for word recognition purposes; 2) for emotion recognition, representations from the middle layer alone perform as well as those derived from layer averaging, while the final layer results in the worst performance in some cases; 3) current self-supervised models may not be the optimal solution for downstream tasks that make use of non-lexical features. Our work provides novel findings that will aid future research in this area and theoretical basis for the use of existing models.
Visuo-Tactile Transformers for Manipulation
Sep 30, 2022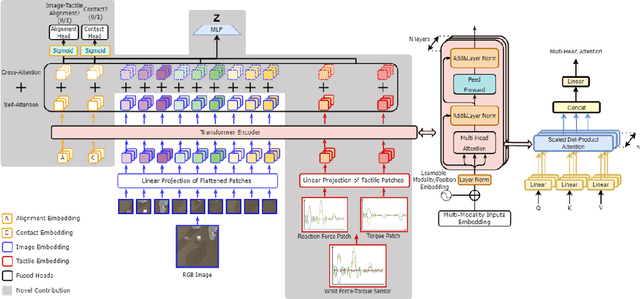
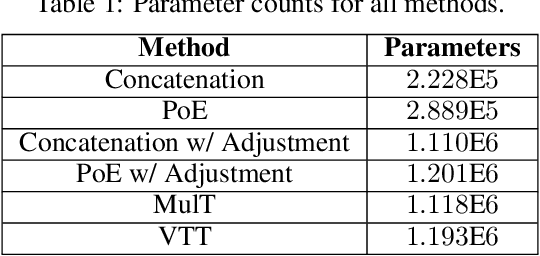
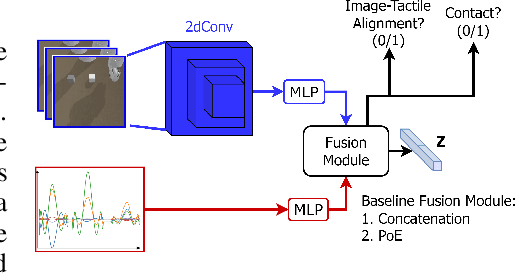
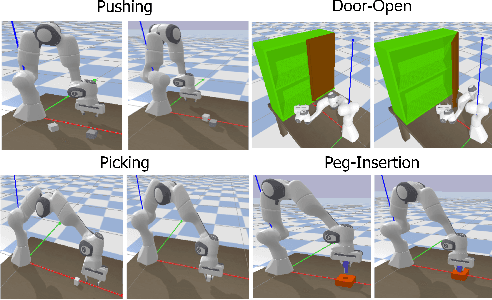
Learning representations in the joint domain of vision and touch can improve manipulation dexterity, robustness, and sample-complexity by exploiting mutual information and complementary cues. Here, we present Visuo-Tactile Transformers (VTTs), a novel multimodal representation learning approach suited for model-based reinforcement learning and planning. Our approach extends the Visual Transformer \cite{dosovitskiy2021image} to handle visuo-tactile feedback. Specifically, VTT uses tactile feedback together with self and cross-modal attention to build latent heatmap representations that focus attention on important task features in the visual domain. We demonstrate the efficacy of VTT for representation learning with a comparative evaluation against baselines on four simulated robot tasks and one real world block pushing task. We conduct an ablation study over the components of VTT to highlight the importance of cross-modality in representation learning.
E-Branchformer: Branchformer with Enhanced merging for speech recognition
Sep 30, 2022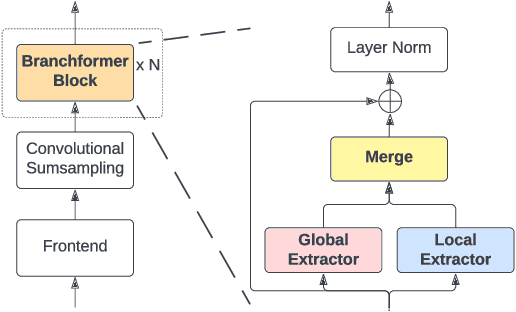
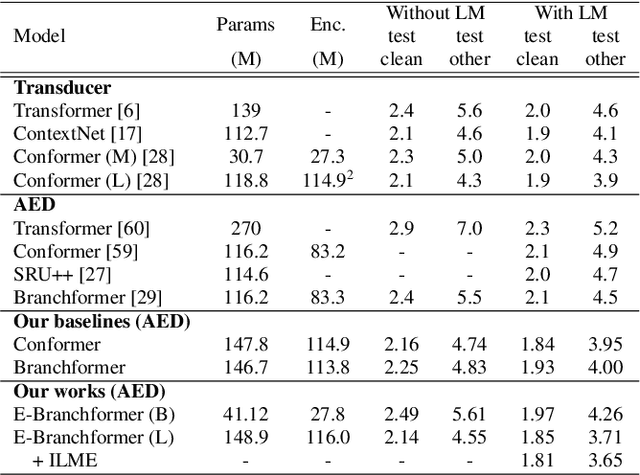
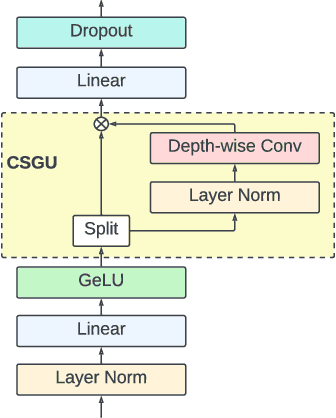
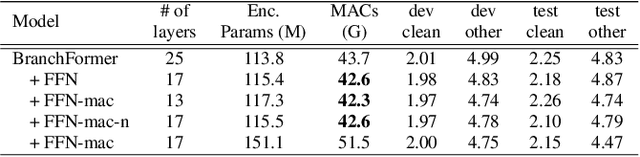
Conformer, combining convolution and self-attention sequentially to capture both local and global information, has shown remarkable performance and is currently regarded as the state-of-the-art for automatic speech recognition (ASR). Several other studies have explored integrating convolution and self-attention but they have not managed to match Conformer's performance. The recently introduced Branchformer achieves comparable performance to Conformer by using dedicated branches of convolution and self-attention and merging local and global context from each branch. In this paper, we propose E-Branchformer, which enhances Branchformer by applying an effective merging method and stacking additional point-wise modules. E-Branchformer sets new state-of-the-art word error rates (WERs) 1.81% and 3.65% on LibriSpeech test-clean and test-other sets without using any external training data.
Shuffled linear regression through graduated convex relaxation
Sep 30, 2022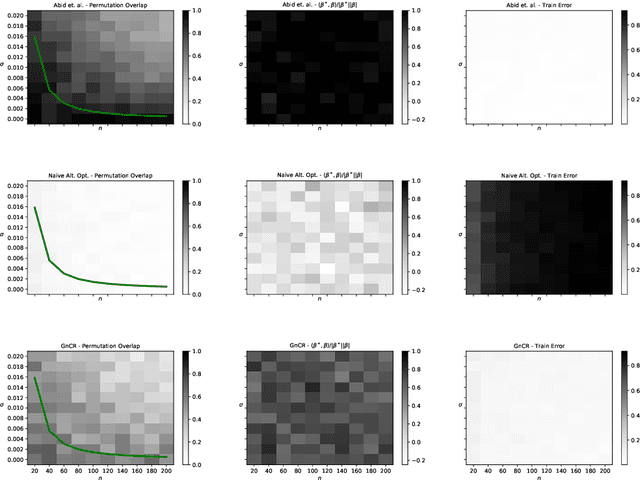
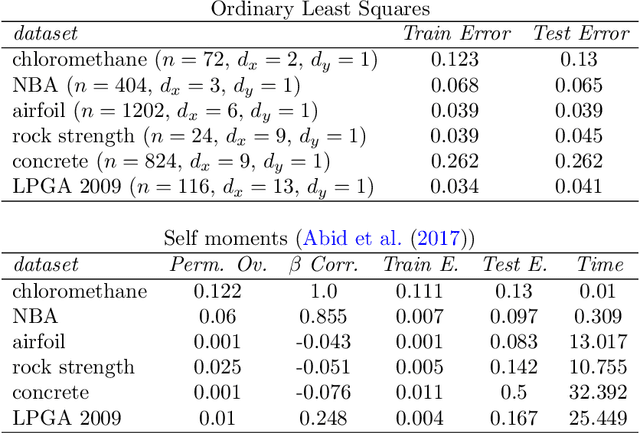
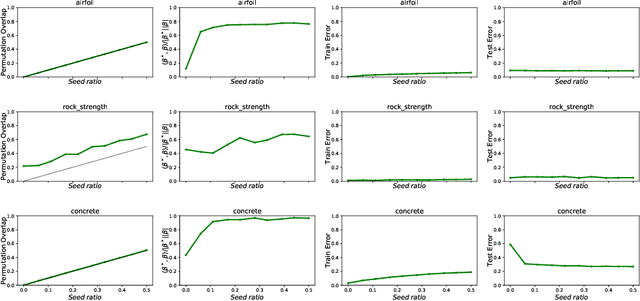
The shuffled linear regression problem aims to recover linear relationships in datasets where the correspondence between input and output is unknown. This problem arises in a wide range of applications including survey data, in which one needs to decide whether the anonymity of the responses can be preserved while uncovering significant statistical connections. In this work, we propose a novel optimization algorithm for shuffled linear regression based on a posterior-maximizing objective function assuming Gaussian noise prior. We compare and contrast our approach with existing methods on synthetic and real data. We show that our approach performs competitively while achieving empirical running-time improvements. Furthermore, we demonstrate that our algorithm is able to utilize the side information in the form of seeds, which recently came to prominence in related problems.