 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping-to-Parameter Nonlinear Functional Regression with Novel B-spline Free Knot Placement Algorithm
Jan 26, 2024



We propose a novel approach to nonlinear functional regression, called the Mapping-to-Parameter function model, which addresses complex and nonlinear functional regression problems in parameter space by employing any supervised learning technique. Central to this model is the mapping of function data from an infinite-dimensional function space to a finite-dimensional parameter space. This is accomplished by concurrently approximating multiple functions with a common set of B-spline basis functions by any chosen order, with their knot distribution determined by the Iterative Local Placement Algorithm, a newly proposed free knot placement algorithm. In contrast to the conventional equidistant knot placement strategy that uniformly distributes knot locations based on a predefined number of knots, our proposed algorithms determine knot location according to the local complexity of the input or output functions. The performance of our knot placement algorithms is shown to be robust in both single-function approximation and multiple-function approximation contexts. Furthermore, the effectiveness and advantage of the proposed prediction model in handling both function-on-scalar regression and function-on-function regression problems are demonstrated through several real data applications, in comparison with four groups of state-of-the-art methods.
Knowledge From the Dark Side: Entropy-Reweighted Knowledge Distillation for Balanced Knowledge Transfer
Nov 22, 2023



Knowledge Distillation (KD) transfers knowledge from a larger "teacher" model to a compact "student" model, guiding the student with the "dark knowledge" $\unicode{x2014}$ the implicit insights present in the teacher's soft predictions. Although existing KDs have shown the potential of transferring knowledge, the gap between the two parties still exists. With a series of investigations, we argue the gap is the result of the student's overconfidence in prediction, signaling an imbalanced focus on pronounced features while overlooking the subtle yet crucial dark knowledge. To overcome this, we introduce the Entropy-Reweighted Knowledge Distillation (ER-KD), a novel approach that leverages the entropy in the teacher's predictions to reweight the KD loss on a sample-wise basis. ER-KD precisely refocuses the student on challenging instances rich in the teacher's nuanced insights while reducing the emphasis on simpler cases, enabling a more balanced knowledge transfer. Consequently, ER-KD not only demonstrates compatibility with various state-of-the-art KD methods but also further enhances their performance at negligible cost. This approach offers a streamlined and effective strategy to refine the knowledge transfer process in KD, setting a new paradigm in the meticulous handling of dark knowledge. Our code is available at https://github.com/cpsu00/ER-KD.
A Novel Method of Fuzzy Topic Modeling based on Transformer Processing
Sep 18, 2023



Topic modeling is admittedly a convenient way to monitor markets trend. Conventionally, Latent Dirichlet Allocation, LDA, is considered a must-do model to gain this type of information. By given the merit of deducing keyword with token conditional probability in LDA, we can know the most possible or essential topic. However, the results are not intuitive because the given topics cannot wholly fit human knowledge. LDA offers the first possible relevant keywords, which also brings out another problem of whether the connection is reliable based on the statistic possibility. It is also hard to decide the topic number manually in advance. As the booming trend of using fuzzy membership to cluster and using transformers to embed words, this work presents the fuzzy topic modeling based on soft clustering and document embedding from state-of-the-art transformer-based model. In our practical application in a press release monitoring, the fuzzy topic modeling gives a more natural result than the traditional output from LDA.
Real-time Automatic M-mode Echocardiography Measurement with Panel Attention from Local-to-Global Pixels
Aug 15, 2023



Motion mode (M-mode) recording is an essential part of echocardiography to measure cardiac dimension and function. However, the current diagnosis cannot build an automatic scheme, as there are three fundamental obstructs: Firstly, there is no open dataset available to build the automation for ensuring constant results and bridging M-mode echocardiography with real-time instance segmentation (RIS); Secondly, the examination is involving the time-consuming manual labelling upon M-mode echocardiograms; Thirdly, as objects in echocardiograms occupy a significant portion of pixels, the limited receptive field in existing backbones (e.g., ResNet) composed from multiple convolution layers are inefficient to cover the period of a valve movement. Existing non-local attentions (NL) compromise being unable real-time with a high computation overhead or losing information from a simplified version of the non-local block. Therefore, we proposed RAMEM, a real-time automatic M-mode echocardiography measurement scheme, contributes three aspects to answer the problems: 1) provide MEIS, a dataset of M-mode echocardiograms for instance segmentation, to enable consistent results and support the development of an automatic scheme; 2) propose panel attention, local-to-global efficient attention by pixel-unshuffling, embedding with updated UPANets V2 in a RIS scheme toward big object detection with global receptive field; 3) develop and implement AMEM, an efficient algorithm of automatic M-mode echocardiography measurement enabling fast and accurate automatic labelling among diagnosis. The experimental results show that RAMEM surpasses existing RIS backbones (with non-local attention) in PASCAL 2012 SBD and human performances in real-time MEIS tested. The code of MEIS and dataset are available at https://github.com/hanktseng131415go/RAME.
EDU-level Extractive Summarization with Varying Summary Lengths
Oct 08, 2022
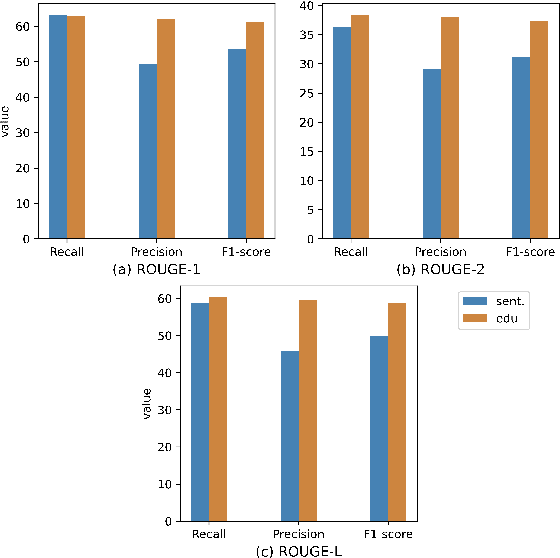
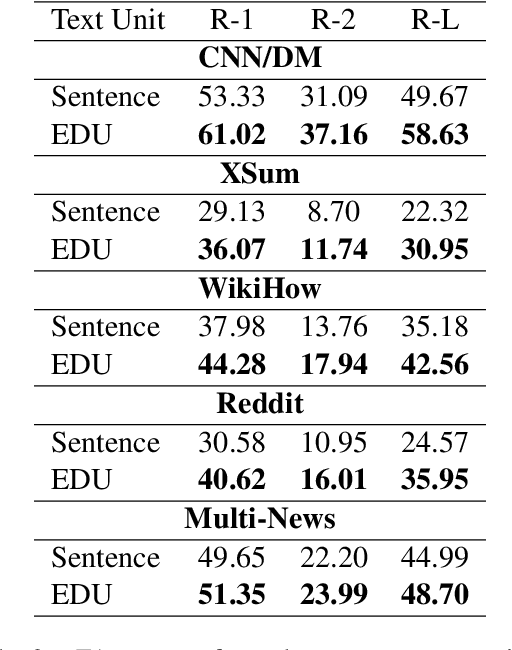
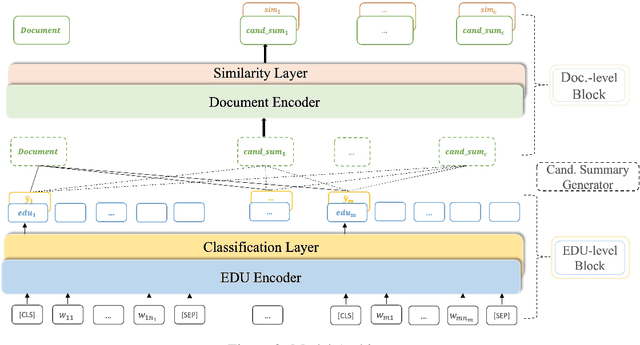
Extractive models usually formulate text summarization as extracting top-k important sentences from document as summary. Few work exploited extracting finer-grained Elementary Discourse Unit (EDU) and there is little analysis and justification for the extractive unit selection. To fill such a gap, this paper firstly conducts oracle analysis to compare the upper bound of performance for models based on EDUs and sentences. The analysis provides evidences from both theoretical and experimental perspectives to justify that EDUs make more concise and precise summary than sentences without losing salient information. Then, considering this merit of EDUs, this paper further proposes EDU-level extractive model with Varying summary Lengths (EDU-VL) and develops the corresponding learning algorithm. EDU-VL learns to encode and predict probabilities of EDUs in document, and encode EDU-level candidate summaries with different lengths based on various $k$ values and select the best candidate summary in an end-to-end training manner. Finally, the proposed and developed approach is experimented on single and multi-document benchmark datasets and shows the improved performances in comparison with the state-of-the-art models.
UPANets: Learning from the Universal Pixel Attention Networks
Mar 22, 2021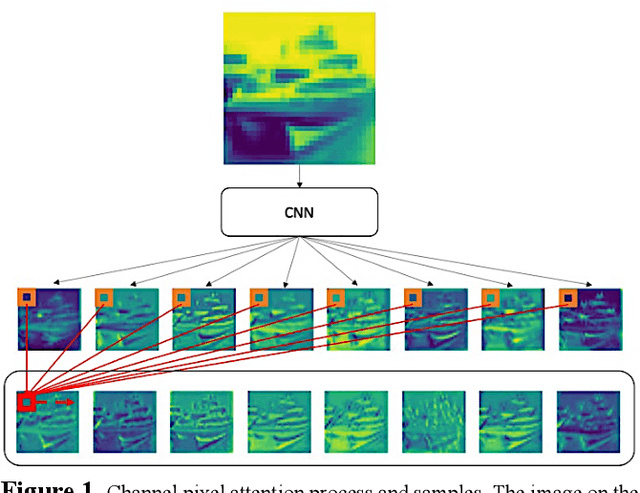
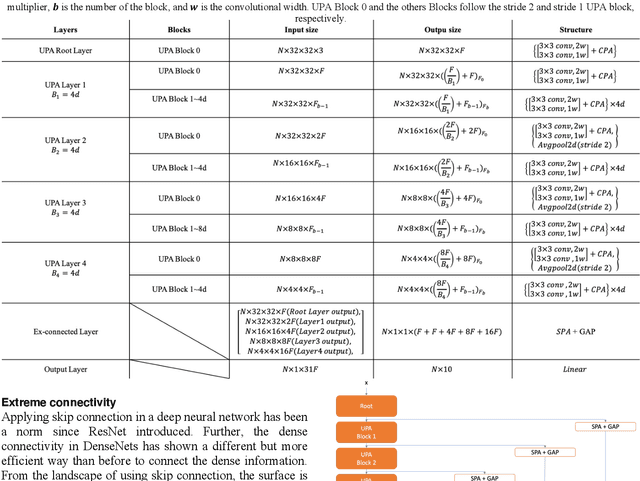
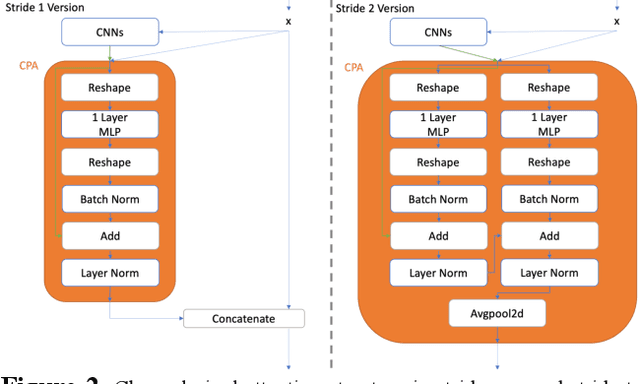
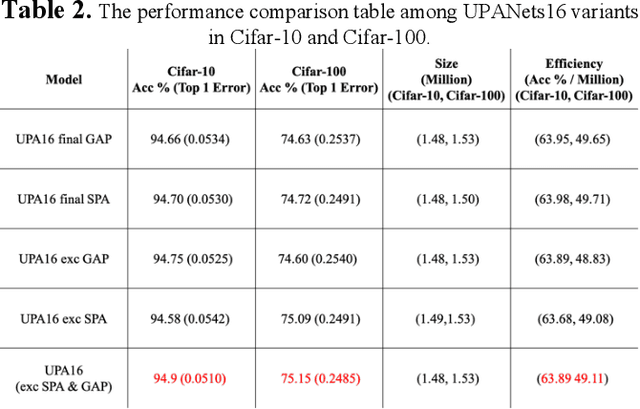
Among image classification, skip and densely-connection-based networks have dominated most leaderboards. Recently, from the successful development of multi-head attention in natural language processing, it is sure that now is a time of either using a Transformer-like model or hybrid CNNs with attention. However, the former need a tremendous resource to train, and the latter is in the perfect balance in this direction. In this work, to make CNNs handle global and local information, we proposed UPANets, which equips channel-wise attention with a hybrid skip-densely-connection structure. Also, the extreme-connection structure makes UPANets robust with a smoother loss landscape. In experiments, UPANets surpassed most well-known and widely-used SOTAs with an accuracy of 96.47% in Cifar-10, 80.29% in Cifar-100, and 67.67% in Tiny Imagenet. Most importantly, these performances have high parameters efficiency and only trained in one customer-based GPU. We share implementing code of UPANets in https://github.com/hanktseng131415go/UPANets.