 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDU-level Extractive Summarization with Varying Summary Lengths
Paper and Code

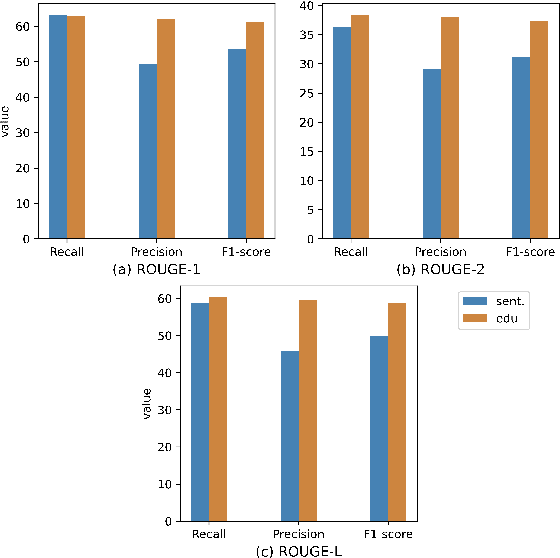
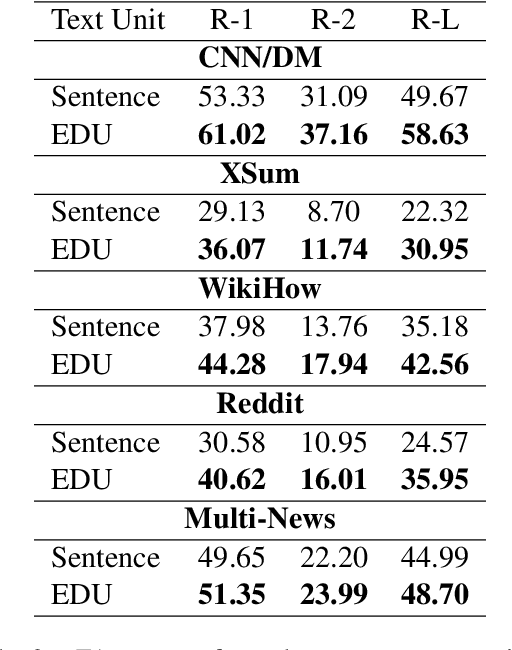
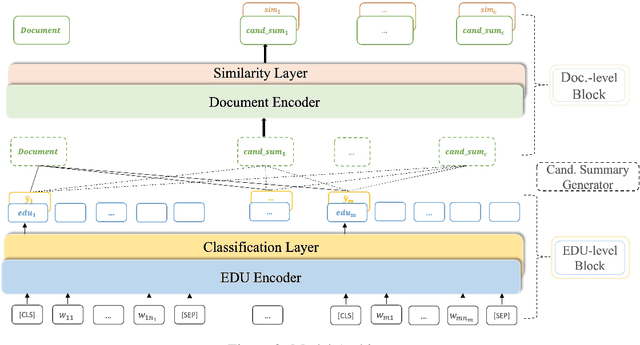
Extractive models usually formulate text summarization as extracting top-k important sentences from document as summary. Few work exploited extracting finer-grained Elementary Discourse Unit (EDU) and there is little analysis and justification for the extractive unit selection. To fill such a gap, this paper firstly conducts oracle analysis to compare the upper bound of performance for models based on EDUs and sentences. The analysis provides evidences from both theoretical and experimental perspectives to justify that EDUs make more concise and precise summary than sentences without losing salient information. Then, considering this merit of EDUs, this paper further proposes EDU-level extractive model with Varying summary Lengths (EDU-VL) and develops the corresponding learning algorithm. EDU-VL learns to encode and predict probabilities of EDUs in document, and encode EDU-level candidate summaries with different lengths based on various $k$ values and select the best candidate summary in an end-to-end training manner. Finally, the proposed and developed approach is experimented on single and multi-document benchmark datasets and shows the improved performances in comparison with the state-of-the-art models.