 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMDG-Bench: A Benchmark for Multimodal Domain Generalization
May 30, 2026Multi-modal Domain Generalization (MMDG) seeks to leverage complementary modalities to enhance model robustness on unseen domains. Despite extensive progress in Multi-modal Learning (MML) and Domain Generalization (DG) as individual fields, their systematic integration remains under-explored. Current MMDG research is largely confined to action recognition and lacks standardized evaluation protocols. To address this, we introduce MMDG-Bench, a comprehensive benchmark featuring two foundational frameworks: DG then MML (D2M) and MML then DG (M2D). We provide unified experimental protocols across diverse tasks, including video-audio-flow action recognition and RGB-Depth-IR face anti-spoofing. By instantiating ten MMDG baselines through pairing a unified MML configuration with five DG techniques under both D2M and M2D orderings, we demonstrate that these structured combinations frequently outperform existing state-of-the-art methods, underscoring the necessity of a unified benchmarking effort. Our analysis yields three key insights: (1) Integrating DG techniques provides consistent generalization gains across various backbones, whereas non-DG methods are highly sensitive to backbone shifts; (2) The optimal framework choice depends on inter-modal stability: D2M excels when modal relations are stable across domains, while M2D is more robust to cross-domain relational variance; (3) Stronger backbones yield amplified performance dividends when integrated into our structured frameworks. MMDG-Bench provides a principled foundation and actionable design guidelines for future research in multi-modal robustness. Code is released at https://github.com/qszhan/MMDG-Bench.
Group-Agent Reinforcement Learning with Heterogeneous Agents
Jan 21, 2025



Group-agent reinforcement learning (GARL) is a newly arising learning scenario, where multiple reinforcement learning agents study together in a group, sharing knowledge in an asynchronous fashion. The goal is to improve the learning performance of each individual agent. Under a more general heterogeneous setting where different agents learn using different algorithms, we advance GARL by designing novel and effective group-learning mechanisms. They guide the agents on whether and how to learn from action choices from the others, and allow the agents to adopt available policy and value function models sent by another agent if they perform better. We have conducted extensive experiments on a total of 43 different Atari 2600 games to demonstrate the superior performance of the proposed method. After the group learning, among the 129 agents examined, 96% are able to achieve a learning speed-up, and 72% are able to learn over 100 times faster. Also, around 41% of those agents have achieved a higher accumulated reward score by learning in less than 5% of the time steps required by a single agent when learning on its own.
Extract-and-Abstract: Unifying Extractive and Abstractive Summarization within Single Encoder-Decoder Framework
Sep 18, 2024



Extract-then-Abstract is a naturally coherent paradigm to conduct abstractive summarization with the help of salient information identified by the extractive model. Previous works that adopt this paradigm train the extractor and abstractor separately and introduce extra parameters to highlight the extracted salients to the abstractor, which results in error accumulation and additional training costs. In this paper, we first introduce a parameter-free highlight method into the encoder-decoder framework: replacing the encoder attention mask with a saliency mask in the cross-attention module to force the decoder to focus only on salient parts of the input. A preliminary analysis compares different highlight methods, demonstrating the effectiveness of our saliency mask. We further propose the novel extract-and-abstract paradigm, ExtAbs, which jointly and seamlessly performs Extractive and Abstractive summarization tasks within single encoder-decoder model to reduce error accumulation. In ExtAbs, the vanilla encoder is augmented to extract salients, and the vanilla decoder is modified with the proposed saliency mask to generate summaries. Built upon BART and PEGASUS, experiments on three datasets show that ExtAbs can achieve superior performance than baselines on the extractive task and performs comparable, or even better than the vanilla models on the abstractive task.
Time Series Analysis for Education: Methods, Applications, and Future Directions
Aug 27, 2024



Recent advancements in the collection and analysis of sequential educational data have brought time series analysis to a pivotal position in educational research, highlighting its essential role in facilitating data-driven decision-making. However, there is a lack of comprehensive summaries that consolidate these advancements. To the best of our knowledge, this paper is the first to provide a comprehensive review of time series analysis techniques specifically within the educational context. We begin by exploring the landscape of educational data analytics, categorizing various data sources and types relevant to education. We then review four prominent time series methods-forecasting, classification, clustering, and anomaly detection-illustrating their specific application points in educational settings. Subsequently, we present a range of educational scenarios and applications, focusing on how these methods are employed to address diverse educational tasks, which highlights the practical integration of multiple time series methods to solve complex educational problems. Finally, we conclude with a discussion on future directions, including personalized learning analytics, multimodal data fusion, and the role of large language models (LLMs) in educational time series. The contributions of this paper include a detailed taxonomy of educational data, a synthesis of time series techniques with specific educational applications, and a forward-looking perspective on emerging trends and future research opportunities in educational analysis. The related papers and resources are available and regularly updated at the project page.
Enhancing Cooperation through Selective Interaction and Long-term Experiences in Multi-Agent Reinforcement Learning
May 04, 2024



The significance of network structures in promoting group cooperation within social dilemmas has been widely recognized. Prior studies attribute this facilitation to the assortment of strategies driven by spatial interactions. Although reinforcement learning has been employed to investigate the impact of dynamic interaction on the evolution of cooperation, there remains a lack of understanding about how agents develop neighbour selection behaviours and the formation of strategic assortment within an explicit interaction structure. To address this, our study introduces a computational framework based on multi-agent reinforcement learning in the spatial Prisoner's Dilemma game. This framework allows agents to select dilemma strategies and interacting neighbours based on their long-term experiences, differing from existing research that relies on preset social norms or external incentives. By modelling each agent using two distinct Q-networks, we disentangle the coevolutionary dynamics between cooperation and interaction. The results indicate that long-term experience enables agents to develop the ability to identify non-cooperative neighbours and exhibit a preference for interaction with cooperative ones. This emergent self-organizing behaviour leads to the clustering of agents with similar strategies, thereby increasing network reciprocity and enhancing group cooperation.
Mapping-to-Parameter Nonlinear Functional Regression with Novel B-spline Free Knot Placement Algorithm
Jan 26, 2024



We propose a novel approach to nonlinear functional regression, called the Mapping-to-Parameter function model, which addresses complex and nonlinear functional regression problems in parameter space by employing any supervised learning technique. Central to this model is the mapping of function data from an infinite-dimensional function space to a finite-dimensional parameter space. This is accomplished by concurrently approximating multiple functions with a common set of B-spline basis functions by any chosen order, with their knot distribution determined by the Iterative Local Placement Algorithm, a newly proposed free knot placement algorithm. In contrast to the conventional equidistant knot placement strategy that uniformly distributes knot locations based on a predefined number of knots, our proposed algorithms determine knot location according to the local complexity of the input or output functions. The performance of our knot placement algorithms is shown to be robust in both single-function approximation and multiple-function approximation contexts. Furthermore, the effectiveness and advantage of the proposed prediction model in handling both function-on-scalar regression and function-on-function regression problems are demonstrated through several real data applications, in comparison with four groups of state-of-the-art methods.
To transfer or not transfer: Unified transferability metric and analysis
May 12, 2023



In transfer learning, transferability is one of the most fundamental problems, which aims to evaluate the effectiveness of arbitrary transfer tasks. Existing research focuses on classification tasks and neglects domain or task differences. More importantly, there is a lack of research to determine whether to transfer or not. To address these, we propose a new analytical approach and metric, Wasserstein Distance based Joint Estimation (WDJE), for transferability estimation and determination in a unified setting: classification and regression problems with domain and task differences. The WDJE facilitates decision-making on whether to transfer or not by comparing the target risk with and without transfer. To enable the comparison, we approximate the target transfer risk by proposing a non-symmetric, easy-to-understand and easy-to-calculate target risk bound that is workable even with limited target labels. The proposed bound relates the target risk to source model performance, domain and task differences based on Wasserstein distance. We also extend our bound into unsupervised settings and establish the generalization bound from finite empirical samples. Our experiments in image classification and remaining useful life regression prediction illustrate the effectiveness of the WDJE in determining whether to transfer or not, and the proposed bound in approximating the target transfer risk.
EDU-level Extractive Summarization with Varying Summary Lengths
Oct 08, 2022
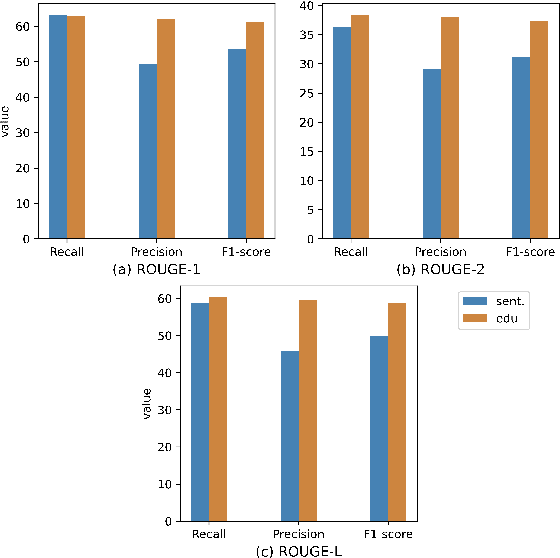
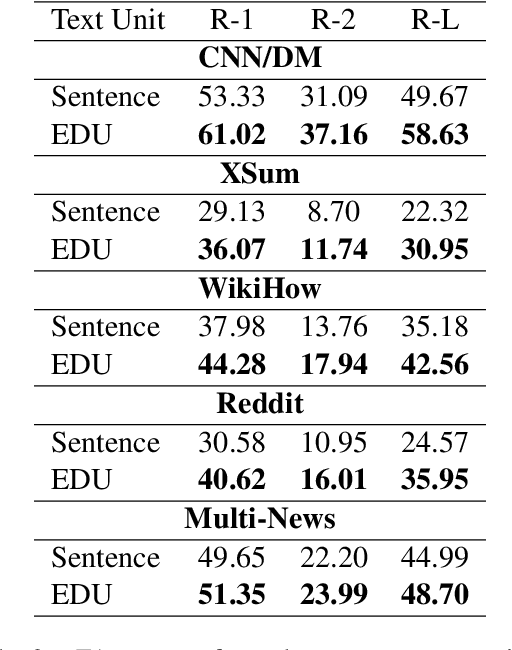
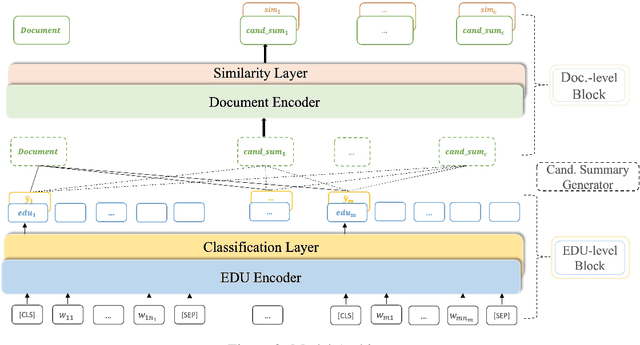
Extractive models usually formulate text summarization as extracting top-k important sentences from document as summary. Few work exploited extracting finer-grained Elementary Discourse Unit (EDU) and there is little analysis and justification for the extractive unit selection. To fill such a gap, this paper firstly conducts oracle analysis to compare the upper bound of performance for models based on EDUs and sentences. The analysis provides evidences from both theoretical and experimental perspectives to justify that EDUs make more concise and precise summary than sentences without losing salient information. Then, considering this merit of EDUs, this paper further proposes EDU-level extractive model with Varying summary Lengths (EDU-VL) and develops the corresponding learning algorithm. EDU-VL learns to encode and predict probabilities of EDUs in document, and encode EDU-level candidate summaries with different lengths based on various $k$ values and select the best candidate summary in an end-to-end training manner. Finally, the proposed and developed approach is experimented on single and multi-document benchmark datasets and shows the improved performances in comparison with the state-of-the-art models.
Towards Better Dermoscopic Image Feature Representation Learning for Melanoma Classification
Jul 15, 2022Deep learning-based melanoma classification with dermoscopic images has recently shown great potential in automatic early-stage melanoma diagnosis. However, limited by the significant data imbalance and obvious extraneous artifacts, i.e., the hair and ruler markings, discriminative feature extraction from dermoscopic images is very challenging. In this study, we seek to resolve these problems respectively towards better representation learning for lesion features. Specifically, a GAN-based data augmentation (GDA) strategy is adapted to generate synthetic melanoma-positive images, in conjunction with the proposed implicit hair denoising (IHD) strategy. Wherein the hair-related representations are implicitly disentangled via an auxiliary classifier network and reversely sent to the melanoma-feature extraction backbone for better melanoma-specific representation learning. Furthermore, to train the IHD module, the hair noises are additionally labeled on the ISIC2020 dataset, making it the first large-scale dermoscopic dataset with annotation of hair-like artifacts. Extensive experiments demonstrate the superiority of the proposed framework as well as the effectiveness of each component. The improved dataset publicly avaliable at https://github.com/kirtsy/DermoscopicDataset.
Group-Agent Reinforcement Learning with A Distributed Deep Solution
Mar 07, 2022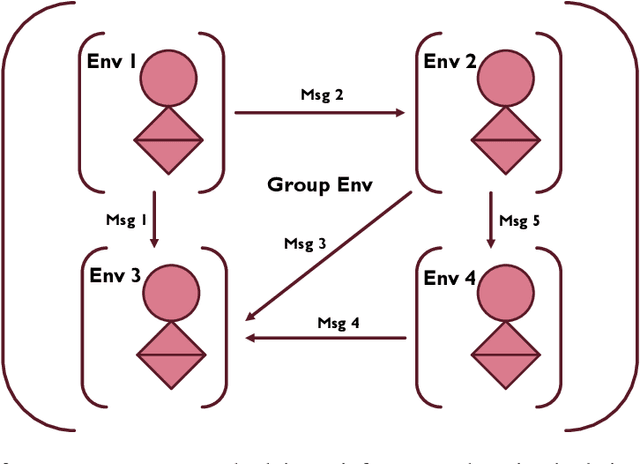
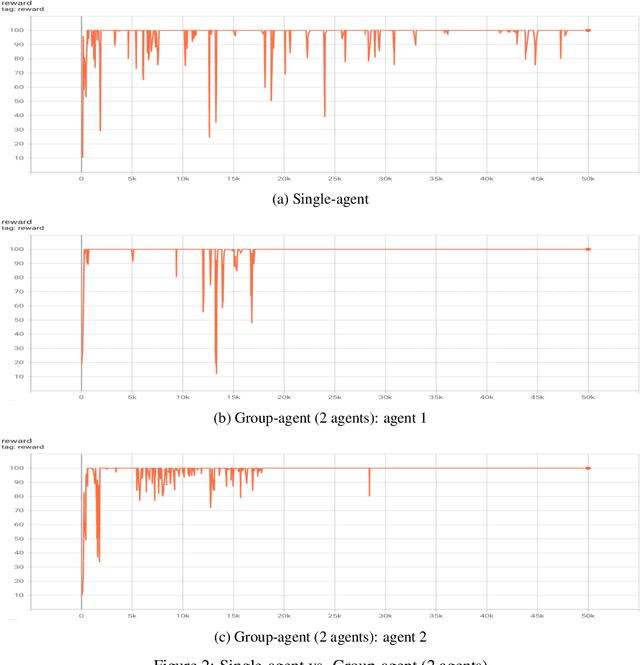
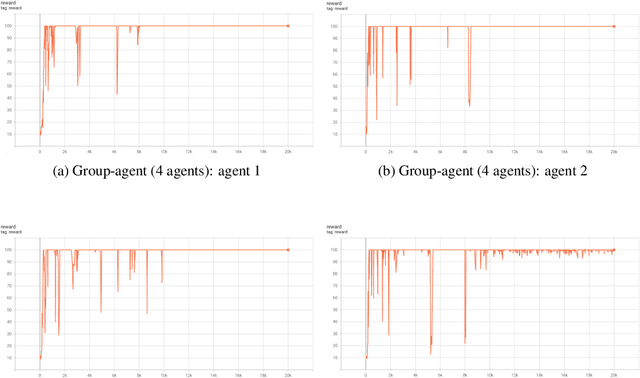
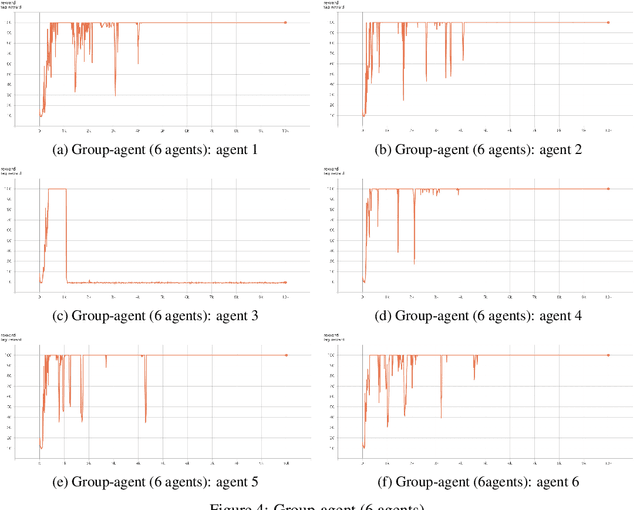
It can largely benefit the reinforcement learning process of each agent if multiple agents perform their separate reinforcement learning tasks cooperatively. These tasks can be not exactly the same but still benefit from the communication behaviour between agents due to task similarities. In fact, this learning scenario is not well understood yet and not well formulated. As the first effort, we provide a detailed discussion of this scenario, and propose group-agent reinforcement learning as a formulation of the reinforcement learning problem under this scenario and a third type of reinforcement learning problem with respect to single-agent and multi-agent reinforcement learning. We propose that it can be solved with the help of modern deep reinforcement learning techniques and provide a distributed deep reinforcement learning algorithm called DDA3C (Decentralised Distributed Asynchronous Advantage Actor-Critic) that is the first framework designed for group-agent reinforcement learning. We show through experiments in the CartPole-v0 game environment that DDA3C achieved desirable performance with very stable training and has good scalability.