 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Visual onoma-to-wave: environmental sound synthesis from visual onomatopoeias and sound-source images
Oct 17, 2022
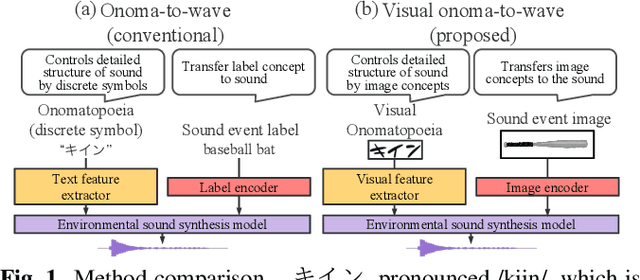
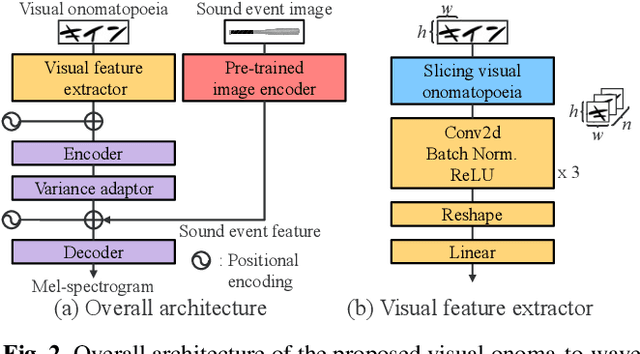

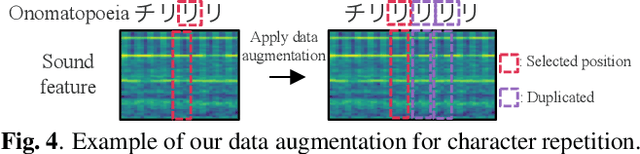
We propose a method for synthesizing environmental sounds from visually represented onomatopoeias and sound sources. An onomatopoeia is a word that imitates a sound structure, i.e., the text representation of sound. From this perspective, onoma-to-wave has been proposed to synthesize environmental sounds from the desired onomatopoeia texts. Onomatopoeias have another representation: visual-text representations of sounds in comics, advertisements, and virtual reality. A visual onomatopoeia (visual text of onomatopoeia) contains rich information that is not present in the text, such as a long-short duration of the image, so the use of this representation is expected to synthesize diverse sounds. Therefore, we propose visual onoma-to-wave for environmental sound synthesis from visual onomatopoeia. The method can transfer visual concepts of the visual text and sound-source image to the synthesized sound. We also propose a data augmentation method focusing on the repetition of onomatopoeias to enhance the performance of our method. An experimental evaluation shows that the methods can synthesize diverse environmental sounds from visual text and sound-source images.
tegdet: An extensible Python Library for Anomaly Detection using Time-Evolving Graphs
Oct 17, 2022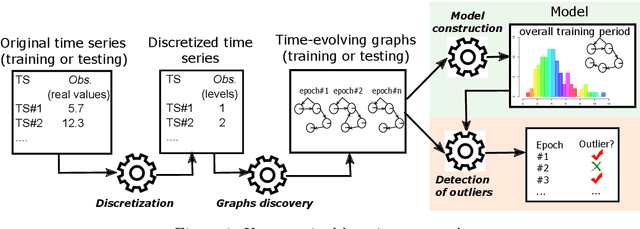

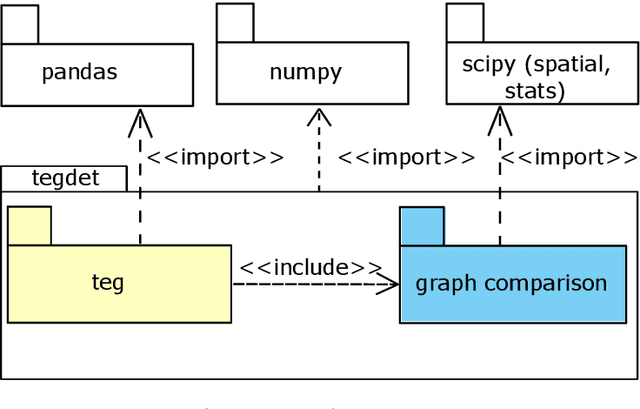

This paper presents a new Python library for anomaly detection in unsupervised learning approaches. The input for the library is a univariate time series representing observations of a given phenomenon. Then, it can identify anomalous epochs, i.e., time intervals where the observations are above a given percentile of a baseline distribution, defined by a dissimilarity metric. Using time-evolving graphs for the anomaly detection, the library leverages valuable information given by the inter-dependencies among data. Currently, the library implements 28 different dissimilarity metrics, and it has been designed to be easily extended with new ones. Through an API, the library exposes a complete functionality to carry out the anomaly detection. Summarizing, to the best of our knowledge, this library is the only one publicly available, that based on dynamic graphs, can be extended with other state-of-the-art anomaly detection techniques. Our experimentation shows promising results regarding the execution times of the algorithms and the accuracy of the implemented techniques. Additionally, the paper provides guidelines for setting the parameters of the detectors to improve their performance and prediction accuracy.
Towards Relation Extraction From Speech
Oct 17, 2022



Relation extraction typically aims to extract semantic relationships between entities from the unstructured text. One of the most essential data sources for relation extraction is the spoken language, such as interviews and dialogues. However, the error propagation introduced in automatic speech recognition (ASR) has been ignored in relation extraction, and the end-to-end speech-based relation extraction method has been rarely explored. In this paper, we propose a new listening information extraction task, i.e., speech relation extraction. We construct the training dataset for speech relation extraction via text-to-speech systems, and we construct the testing dataset via crowd-sourcing with native English speakers. We explore speech relation extraction via two approaches: the pipeline approach conducting text-based extraction with a pretrained ASR module, and the end2end approach via a new proposed encoder-decoder model, or what we called SpeechRE. We conduct comprehensive experiments to distinguish the challenges in speech relation extraction, which may shed light on future explorations. We share the code and data on https://github.com/wutong8023/SpeechRE.
Using Bottleneck Adapters to Identify Cancer in Clinical Notes under Low-Resource Constraints
Oct 17, 2022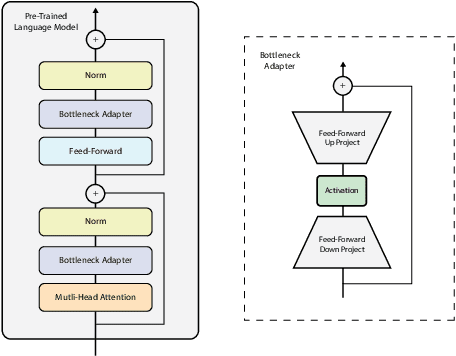
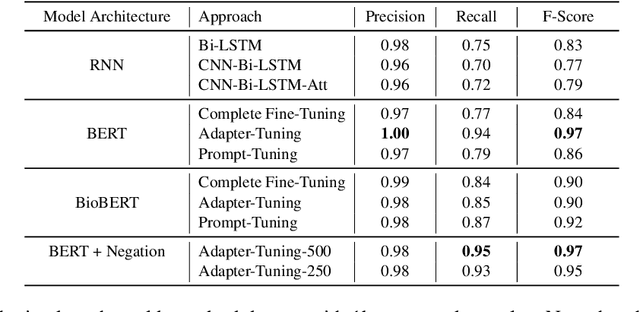
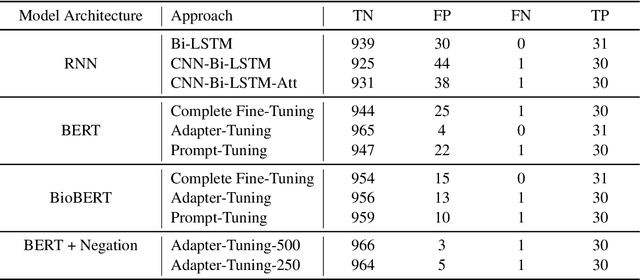
Processing information locked within clinical health records is a challenging task that remains an active area of research in biomedical NLP. In this work, we evaluate a broad set of machine learning techniques ranging from simple RNNs to specialised transformers such as BioBERT on a dataset containing clinical notes along with a set of annotations indicating whether a sample is cancer-related or not. Furthermore, we specifically employ efficient fine-tuning methods from NLP, namely, bottleneck adapters and prompt tuning, to adapt the models to our specialised task. Our evaluations suggest that fine-tuning a frozen BERT model pre-trained on natural language and with bottleneck adapters outperforms all other strategies, including full fine-tuning of the specialised BioBERT model. Based on our findings, we suggest that using bottleneck adapters in low-resource situations with limited access to labelled data or processing capacity could be a viable strategy in biomedical text mining. The code used in the experiments are going to be made available at https://github.com/omidrohanian/bottleneck-adapters.
Performance Analysis of Cell-Free Massive MIMO Systems with Asynchronous Reception
Oct 17, 2022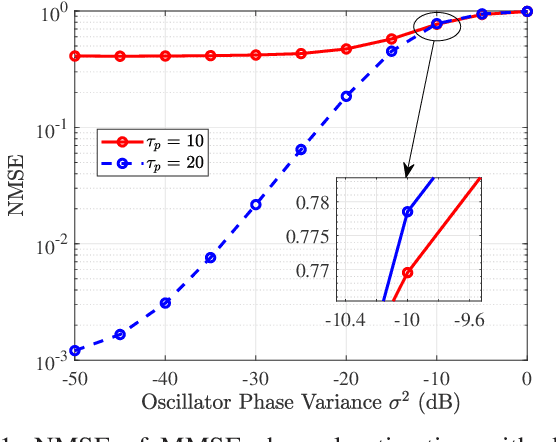
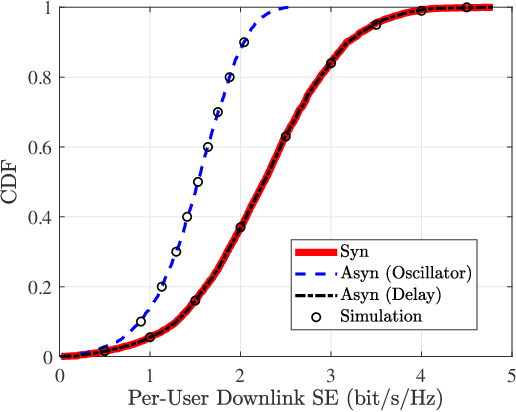
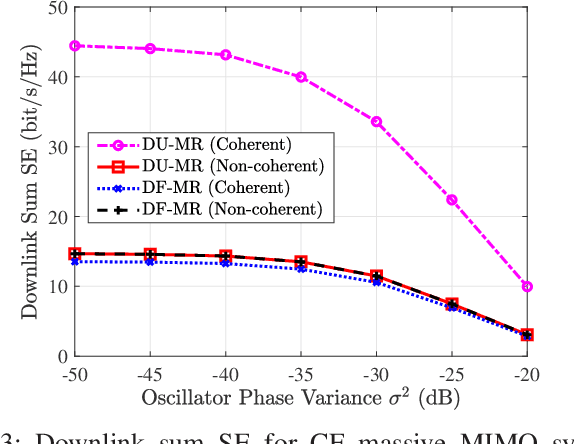
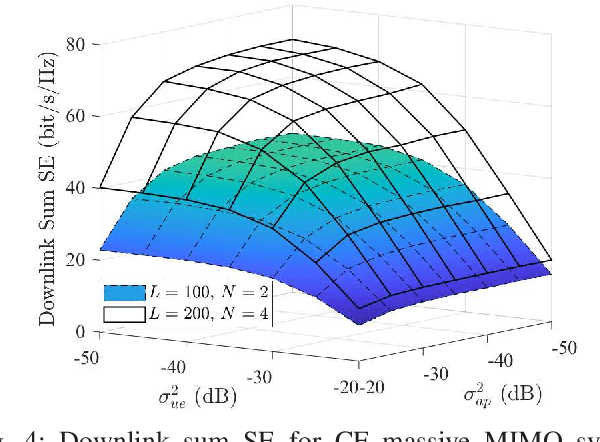
Cell-free (CF) massive multiple-input multiple-output (MIMO) is considered as a promising technology for achieving the ultimate performance limit. However, due to its distributed architecture and low-cost access points (APs), the signals received at user equipments (UEs) are most likely asynchronous. In this paper, we investigate the performance of CF massive MIMO systems with asynchronous reception, including both effects of delay and oscillator phases. Taking into account the imperfect channel state information caused by phase asynchronization and pilot contamination, we obtain novel and closed-form downlink spectral efficiency (SE) expressions with coherent and non-coherent data transmission schemes, respectively. Simulation results show that asynchronous reception destroys the orthogonality of pilots and coherent transmission of data, and thus results in poor system performance. In addition, getting a highly accurate delay phase is substantial for CF massive MIMO systems to achieve coherent transmission gain. Moreover, the oscillator phase of UEs has a larger effect on SE than that of the APs, because the latter can be significantly reduced by increasing the number of antennas.
Finger Multimodal Feature Fusion and Recognition Based on Channel Spatial Attention
Sep 06, 2022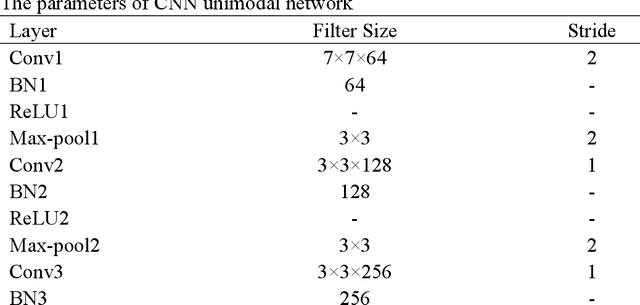
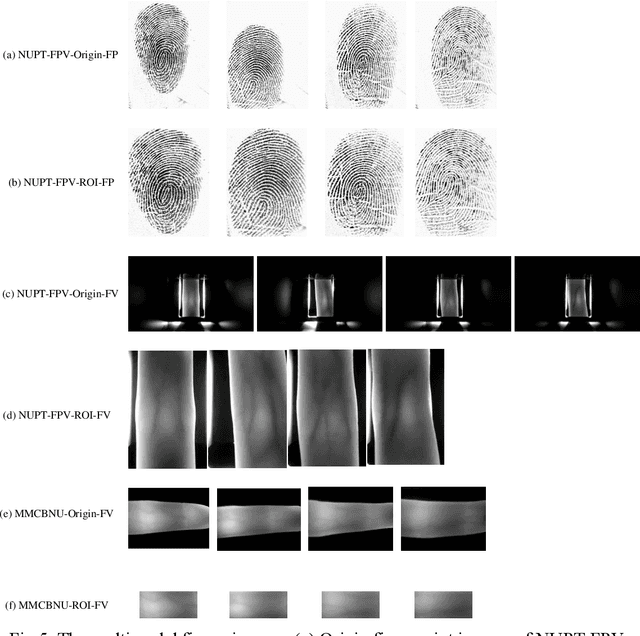
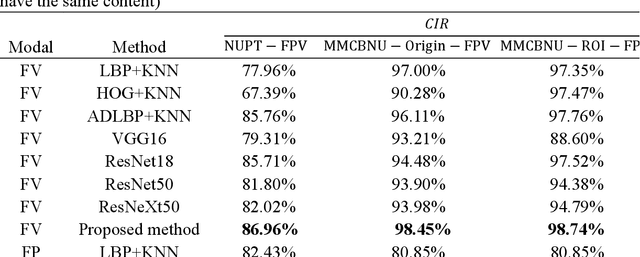
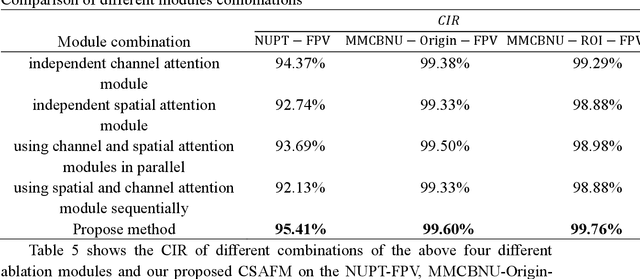
Due to the instability and limitations of unimodal biometric systems, multimodal systems have attracted more and more attention from researchers. However, how to exploit the independent and complementary information between different modalities remains a key and challenging problem. In this paper, we propose a multimodal biometric fusion recognition algorithm based on fingerprints and finger veins (Fingerprint Finger Veins-Channel Spatial Attention Fusion Module, FPV-CSAFM). Specifically, for each pair of fingerprint and finger vein images, we first propose a simple and effective Convolutional Neural Network (CNN) to extract features. Then, we build a multimodal feature fusion module (Channel Spatial Attention Fusion Module, CSAFM) to fully fuse the complementary information between fingerprints and finger veins. Different from existing fusion strategies, our fusion method can dynamically adjust the fusion weights according to the importance of different modalities in channel and spatial dimensions, so as to better combine the information between different modalities and improve the overall recognition performance. To evaluate the performance of our method, we conduct a series of experiments on multiple public datasets. Experimental results show that the proposed FPV-CSAFM achieves excellent recognition performance on three multimodal datasets based on fingerprints and finger veins.
KSG: Knowledge and Skill Graph
Sep 13, 2022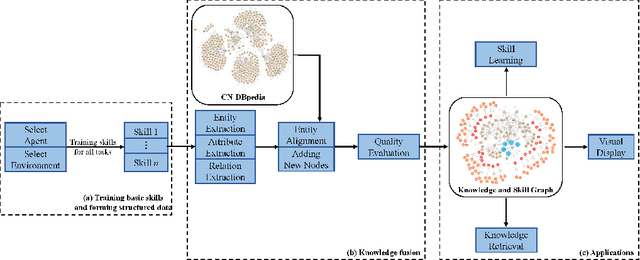
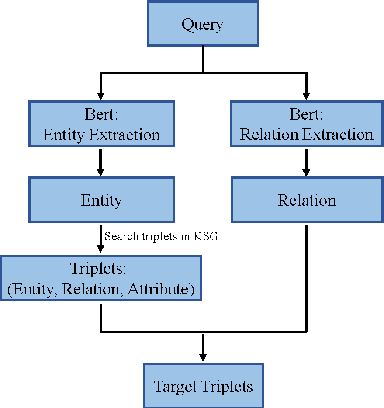
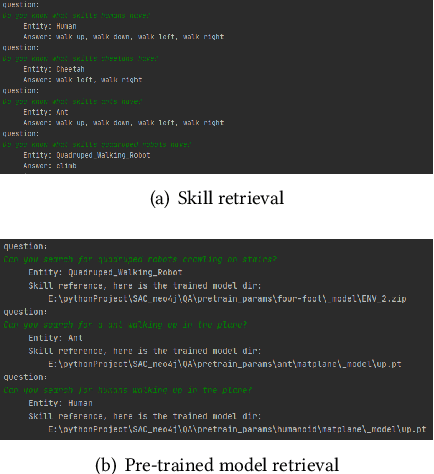
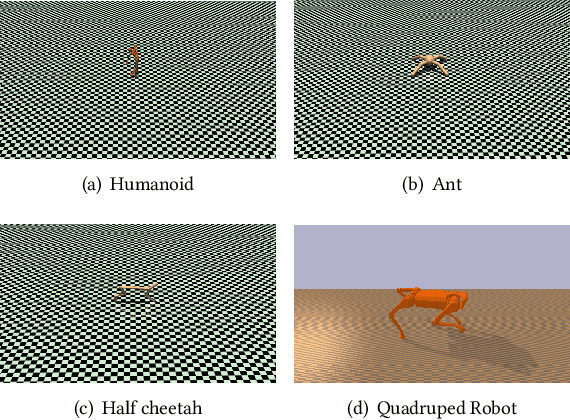
The knowledge graph (KG) is an essential form of knowledge representation that has grown in prominence in recent years. Because it concentrates on nominal entities and their relationships, traditional knowledge graphs are static and encyclopedic in nature. On this basis, event knowledge graph (Event KG) models the temporal and spatial dynamics by text processing to facilitate downstream applications, such as question-answering, recommendation and intelligent search. Existing KG research, on the other hand, mostly focuses on text processing and static facts, ignoring the vast quantity of dynamic behavioral information included in photos, movies, and pre-trained neural networks. In addition, no effort has been done to include behavioral intelligence information into the knowledge graph for deep reinforcement learning (DRL) and robot learning. In this paper, we propose a novel dynamic knowledge and skill graph (KSG), and then we develop a basic and specific KSG based on CN-DBpedia. The nodes are divided into entity and attribute nodes, with entity nodes containing the agent, environment, and skill (DRL policy or policy representation), and attribute nodes containing the entity description, pre-train network, and offline dataset. KSG can search for different agents' skills in various environments and provide transferable information for acquiring new skills. This is the first study that we are aware of that looks into dynamic KSG for skill retrieval and learning. Extensive experimental results on new skill learning show that KSG boosts new skill learning efficiency.
Q-TOD: A Query-driven Task-oriented Dialogue System
Oct 14, 2022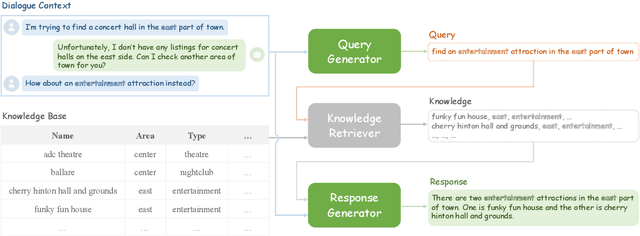
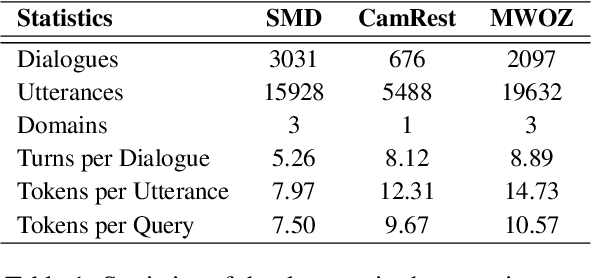
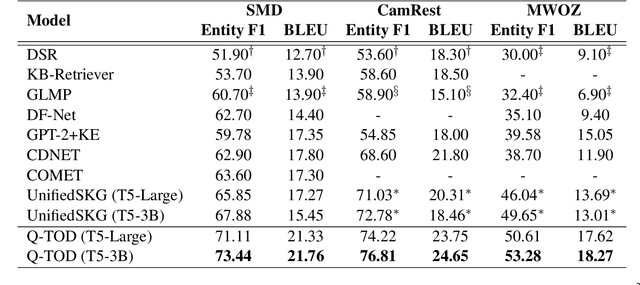
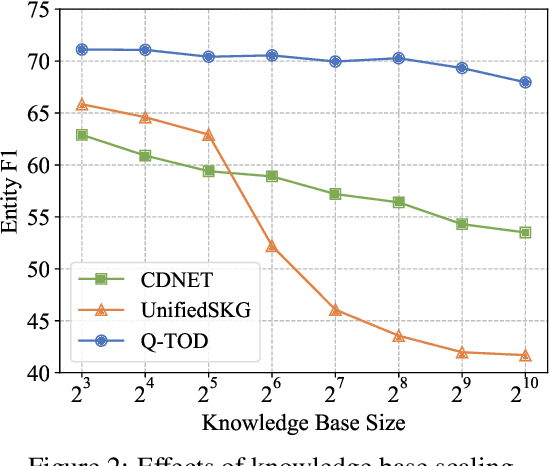
Existing pipelined task-oriented dialogue systems usually have difficulties adapting to unseen domains, whereas end-to-end systems are plagued by large-scale knowledge bases in practice. In this paper, we introduce a novel query-driven task-oriented dialogue system, namely Q-TOD. The essential information from the dialogue context is extracted into a query, which is further employed to retrieve relevant knowledge records for response generation. Firstly, as the query is in the form of natural language and not confined to the schema of the knowledge base, the issue of domain adaption is alleviated remarkably in Q-TOD. Secondly, as the query enables the decoupling of knowledge retrieval from the generation, Q-TOD gets rid of the issue of knowledge base scalability. To evaluate the effectiveness of the proposed Q-TOD, we collect query annotations for three publicly available task-oriented dialogue datasets. Comprehensive experiments verify that Q-TOD outperforms strong baselines and establishes a new state-of-the-art performance on these datasets.
Digital Image Forensics using Deep Learning
Oct 14, 2022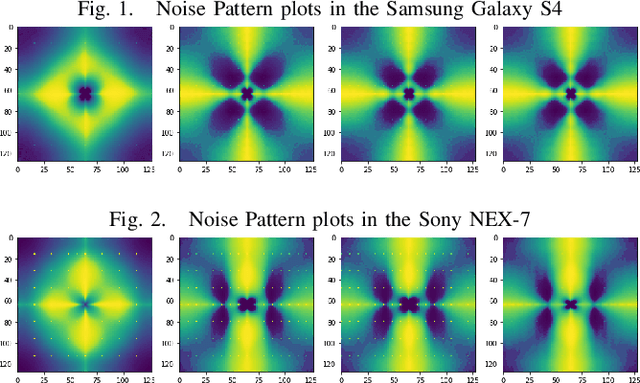
During the investigation of criminal activity when evidence is available, the issue at hand is determining the credibility of the video and ascertaining that the video is real. Today, one way to authenticate the footage is to identify the camera that was used to capture the image or video in question. While a very common way to do this is by using image meta-data, this data can easily be falsified by changing the video content or even splicing together content from two different cameras. Given the multitude of solutions proposed to this problem, it is yet to be sufficiently solved. The aim of our project is to build an algorithm that identifies which camera was used to capture an image using traces of information left intrinsically in the image, using filters, followed by a deep neural network on these filters. Solving this problem would have a big impact on the verification of evidence used in criminal and civil trials and even news reporting.
Towards Transformer-based Homogenization of Satellite Imagery for Landsat-8 and Sentinel-2
Oct 14, 2022
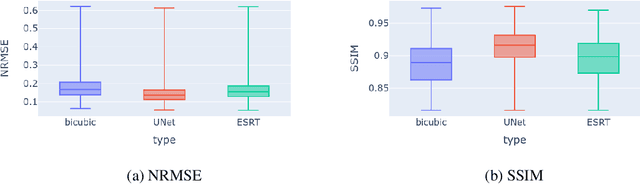

Landsat-8 (NASA) and Sentinel-2 (ESA) are two prominent multi-spectral imaging satellite projects that provide publicly available data. The multi-spectral imaging sensors of the satellites capture images of the earth's surface in the visible and infrared region of the electromagnetic spectrum. Since the majority of the earth's surface is constantly covered with clouds, which are not transparent at these wavelengths, many images do not provide much information. To increase the temporal availability of cloud-free images of a certain area, one can combine the observations from multiple sources. However, the sensors of satellites might differ in their properties, making the images incompatible. This work provides a first glance at the possibility of using a transformer-based model to reduce the spectral and spatial differences between observations from both satellite projects. We compare the results to a model based on a fully convolutional UNet architecture. Somewhat surprisingly, we find that, while deep models outperform classical approaches, the UNet significantly outperforms the transformer in our experiments.