 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewriting Pre-Training Data Boosts LLM Performance in Math and Code
May 05, 2025The performance of large language models (LLMs) in program synthesis and mathematical reasoning is fundamentally limited by the quality of their pre-training corpora. We introduce two openly licensed datasets, released under the Llama 3.3 Community License, that significantly enhance LLM performance by systematically rewriting public data. SwallowCode (approximately 16.1 billion tokens) refines Python snippets from The-Stack-v2 through a novel four-stage pipeline: syntax validation, pylint-based style filtering, and a two-stage LLM rewriting process that enforces style conformity and transforms snippets into self-contained, algorithmically efficient examples. Unlike prior methods that rely on exclusionary filtering or limited transformations, our transform-and-retain approach upgrades low-quality code, maximizing data utility. SwallowMath (approximately 2.3 billion tokens) enhances Finemath-4+ by removing boilerplate, restoring context, and reformatting solutions into concise, step-by-step explanations. Within a fixed 50 billion token training budget, continual pre-training of Llama-3.1-8B with SwallowCode boosts pass@1 by +17.0 on HumanEval and +17.7 on HumanEval+ compared to Stack-Edu, surpassing the baseline model's code generation capabilities. Similarly, substituting SwallowMath yields +12.4 accuracy on GSM8K and +7.6 on MATH. Ablation studies confirm that each pipeline stage contributes incrementally, with rewriting delivering the largest gains. All datasets, prompts, and checkpoints are publicly available, enabling reproducible research and advancing LLM pre-training for specialized domains.
Building Instruction-Tuning Datasets from Human-Written Instructions with Open-Weight Large Language Models
Mar 31, 2025Instruction tuning is crucial for enabling Large Language Models (LLMs) to solve real-world tasks. Prior work has shown the effectiveness of instruction-tuning data synthesized solely from LLMs, raising a fundamental question: Do we still need human-originated signals for instruction tuning? This work answers the question affirmatively: we build state-of-the-art instruction-tuning datasets sourced from human-written instructions, by simply pairing them with LLM-generated responses. LLMs fine-tuned on our datasets consistently outperform those fine-tuned on existing ones. Our data construction approach can be easily adapted to other languages; we build datasets for Japanese and confirm that LLMs tuned with our data reach state-of-the-art performance. Analyses suggest that instruction-tuning in a new language allows LLMs to follow instructions, while the tuned models exhibit a notable lack of culture-specific knowledge in that language. The datasets and fine-tuned models will be publicly available. Our datasets, synthesized with open-weight LLMs, are openly distributed under permissive licenses, allowing for diverse use cases.
Drop-Upcycling: Training Sparse Mixture of Experts with Partial Re-initialization
Feb 26, 2025



The Mixture of Experts (MoE) architecture reduces the training and inference cost significantly compared to a dense model of equivalent capacity. Upcycling is an approach that initializes and trains an MoE model using a pre-trained dense model. While upcycling leads to initial performance gains, the training progresses slower than when trained from scratch, leading to suboptimal performance in the long term. We propose Drop-Upcycling - a method that effectively addresses this problem. Drop-Upcycling combines two seemingly contradictory approaches: utilizing the knowledge of pre-trained dense models while statistically re-initializing some parts of the weights. This approach strategically promotes expert specialization, significantly enhancing the MoE model's efficiency in knowledge acquisition. Extensive large-scale experiments demonstrate that Drop-Upcycling significantly outperforms previous MoE construction methods in the long term, specifically when training on hundreds of billions of tokens or more. As a result, our MoE model with 5.9B active parameters achieves comparable performance to a 13B dense model in the same model family, while requiring approximately 1/4 of the training FLOPs. All experimental resources, including source code, training data, model checkpoints and logs, are publicly available to promote reproducibility and future research on MoE.
Why We Build Local Large Language Models: An Observational Analysis from 35 Japanese and Multilingual LLMs
Dec 19, 2024



Why do we build local large language models (LLMs)? What should a local LLM learn from the target language? Which abilities can be transferred from other languages? Do language-specific scaling laws exist? To explore these research questions, we evaluated 35 Japanese, English, and multilingual LLMs on 19 evaluation benchmarks for Japanese and English, taking Japanese as a local language. Adopting an observational approach, we analyzed correlations of benchmark scores, and conducted principal component analysis (PCA) on the scores to derive \textit{ability factors} of local LLMs. We found that training on English text can improve the scores of academic subjects in Japanese (JMMLU). In addition, it is unnecessary to specifically train on Japanese text to enhance abilities for solving Japanese code generation, arithmetic reasoning, commonsense, and reading comprehension tasks. In contrast, training on Japanese text could improve question-answering tasks about Japanese knowledge and English-Japanese translation, which indicates that abilities for solving these two tasks can be regarded as \textit{Japanese abilities} for LLMs. Furthermore, we confirmed that the Japanese abilities scale with the computational budget for Japanese text.
Balancing Speed and Stability: The Trade-offs of FP8 vs. BF16 Training in LLMs
Nov 10, 2024



Large Language Models (LLMs) have attracted significant attention due to their human-like language understanding and generation capabilities, as well as their applicability across various domains. These models, characterized by their massive scale and extensive training data, continue to push the boundaries of what is possible in natural language processing. The Llama 3 series, for instance, exemplifies this trend with its flagship model boasting 405 billion parameters trained on 15.6 trillion tokens. The immense computational demands associated with training such models have spurred ongoing research into optimizing the efficiency of the training process, particularly through the use of lower-precision formats. NVIDIA's H100 GPU, which introduces support for FP8 in addition to the more conventional FP16 and BF16 formats, has emerged as a focal point in this optimization effort. Preliminary studies suggest that FP8 could offer substantial reductions in training time without sacrificing model performance when compared to BF16, making it a promising candidate for large-scale model training. However, the broader implications of adopting FP8, particularly in terms of training stability and downstream task performance, have yet to be fully understood. In this study, we delve into the practical trade-offs involved in adopting FP8 over BF16 for training LLMs.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities
Apr 27, 2024



Cross-lingual continual pre-training of large language models (LLMs) initially trained on English corpus allows us to leverage the vast amount of English language resources and reduce the pre-training cost. In this study, we constructed Swallow, an LLM with enhanced Japanese capability, by extending the vocabulary of Llama 2 to include Japanese characters and conducting continual pre-training on a large Japanese web corpus. Experimental results confirmed that the performance on Japanese tasks drastically improved through continual pre-training, and the performance monotonically increased with the amount of training data up to 100B tokens. Consequently, Swallow achieved superior performance compared to other LLMs that were trained from scratch in English and Japanese. An analysis of the effects of continual pre-training revealed that it was particularly effective for Japanese question answering tasks. Furthermore, to elucidate effective methodologies for cross-lingual continual pre-training from English to Japanese, we investigated the impact of vocabulary expansion and the effectiveness of incorporating parallel corpora. The results showed that the efficiency gained through vocabulary expansion had no negative impact on performance, except for the summarization task, and that the combined use of parallel corpora enhanced translation ability.
Building a Large Japanese Web Corpus for Large Language Models
Apr 27, 2024


Open Japanese large language models (LLMs) have been trained on the Japanese portions of corpora such as CC-100, mC4, and OSCAR. However, these corpora were not created for the quality of Japanese texts. This study builds a large Japanese web corpus by extracting and refining text from the Common Crawl archive (21 snapshots of approximately 63.4 billion pages crawled between 2020 and 2023). This corpus consists of approximately 312.1 billion characters (approximately 173 million pages), which is the largest of all available training corpora for Japanese LLMs, surpassing CC-100 (approximately 25.8 billion characters), mC4 (approximately 239.7 billion characters) and OSCAR 23.10 (approximately 74 billion characters). To confirm the quality of the corpus, we performed continual pre-training on Llama 2 7B, 13B, 70B, Mistral 7B v0.1, and Mixtral 8x7B Instruct as base LLMs and gained consistent (6.6-8.1 points) improvements on Japanese benchmark datasets. We also demonstrate that the improvement on Llama 2 13B brought from the presented corpus was the largest among those from other existing corpora.
Heron-Bench: A Benchmark for Evaluating Vision Language Models in Japanese
Apr 11, 2024



Vision Language Models (VLMs) have undergone a rapid evolution, giving rise to significant advancements in the realm of multimodal understanding tasks. However, the majority of these models are trained and evaluated on English-centric datasets, leaving a gap in the development and evaluation of VLMs for other languages, such as Japanese. This gap can be attributed to the lack of methodologies for constructing VLMs and the absence of benchmarks to accurately measure their performance. To address this issue, we introduce a novel benchmark, Japanese Heron-Bench, for evaluating Japanese capabilities of VLMs. The Japanese Heron-Bench consists of a variety of imagequestion answer pairs tailored to the Japanese context. Additionally, we present a baseline Japanese VLM that has been trained with Japanese visual instruction tuning datasets. Our Heron-Bench reveals the strengths and limitations of the proposed VLM across various ability dimensions. Furthermore, we clarify the capability gap between strong closed models like GPT-4V and the baseline model, providing valuable insights for future research in this domain. We release the benchmark dataset and training code to facilitate further developments in Japanese VLM research.
Visual onoma-to-wave: environmental sound synthesis from visual onomatopoeias and sound-source images
Oct 17, 2022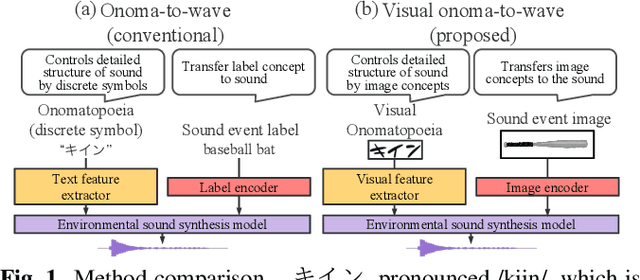
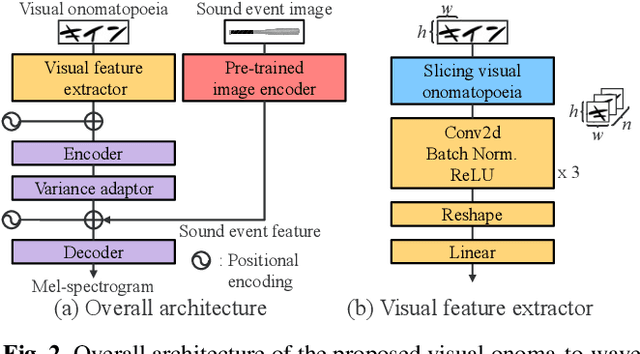

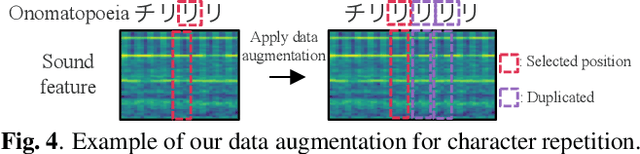
We propose a method for synthesizing environmental sounds from visually represented onomatopoeias and sound sources. An onomatopoeia is a word that imitates a sound structure, i.e., the text representation of sound. From this perspective, onoma-to-wave has been proposed to synthesize environmental sounds from the desired onomatopoeia texts. Onomatopoeias have another representation: visual-text representations of sounds in comics, advertisements, and virtual reality. A visual onomatopoeia (visual text of onomatopoeia) contains rich information that is not present in the text, such as a long-short duration of the image, so the use of this representation is expected to synthesize diverse sounds. Therefore, we propose visual onoma-to-wave for environmental sound synthesis from visual onomatopoeia. The method can transfer visual concepts of the visual text and sound-source image to the synthesized sound. We also propose a data augmentation method focusing on the repetition of onomatopoeias to enhance the performance of our method. An experimental evaluation shows that the methods can synthesize diverse environmental sounds from visual text and sound-source images.