 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Evaluation of Autonomous Systems under Adversarial Attacks
May 05, 2026Most evaluations of autonomous driving policies under adversarial conditions are conducted in simulation, due to cost efficiency and the absence of physical risk. However, purely virtual testing fails to capture structural inconsistencies, supervision constraints, and state-representation effects that arise in real-world data and fundamentally shape policy robustness. This work presents an offline trajectory-learning and adversarial robustness evaluation framework grounded in real-world intersection driving data. Within a controlled data contract, we train and compare three trajectory-learning paradigms: Multi-Layer Perceptron (MLP)-based Behavior Cloning (BC), Transformer-based object-tokenized BC, and inverse reinforcement learning (IRL) formulated within a Generative Adversarial Imitation Learning (GAIL) framework. Models are evaluated using Average Displacement Error (ADE) and Final Displacement Error (FDE). Inference-time robustness is assessed by subjecting trained policies to gradient-based adversarial perturbations across multiple intersection scenarios, yielding a structured robustness evaluation matrix. Results show that state-structure design and architectural inductive biases critically influence adversarial stability, leading to markedly different robustness profiles despite comparable nominal prediction accuracy (ADE < 0.08). Inference-time Projected Gradient Descent (PGD) attacks induce final displacement errors of up to approximately 8 meters. The proposed framework establishes a scalable benchmark for studying offline trajectory learning and adversarial robustness in real-world autonomous driving settings.
Embedding Arithmetic: A Lightweight, Tuning-Free Framework for Post-hoc Bias Mitigation in Text-to-Image Models
Apr 20, 2026Modern text-to-image (T2I) models amplify harmful societal biases, challenging their ethical deployment. We introduce an inference-time method that reliably mitigates social bias while keeping prompt semantics and visual context (background, layout, and style) intact. This ensures context persistency and provides a controllable parameter to adjust mitigation strength, giving practitioners fine-grained control over fairness-coherence trade-offs. Using Embedding Arithmetic, we analyze how bias is structured in the embedding space and correct it without altering model weights, prompts, or datasets. Experiments on FLUX 1.0-Dev and Stable Diffusion 3.5-Large show that the conditional embedding space forms a complex, entangled manifold rather than a grid of disentangled concepts. To rigorously assess semantic preservation beyond the circularity and bias limitations of of CLIP scores, we propose the Concept Coherence Score (CCS). Evaluated against this robust metric, our lightweight, tuning-free method significantly outperforms existing baselines in improving diversity while maintaining high concept coherence, effectively resolving the critical fairness-coherence trade-off. By characterizing how models represent social concepts, we establish geometric understanding of latent space as a principled path toward more transparent, controllable, and fair image generation.
DrivIng: A Large-Scale Multimodal Driving Dataset with Full Digital Twin Integration
Jan 21, 2026Perception is a cornerstone of autonomous driving, enabling vehicles to understand their surroundings and make safe, reliable decisions. Developing robust perception algorithms requires large-scale, high-quality datasets that cover diverse driving conditions and support thorough evaluation. Existing datasets often lack a high-fidelity digital twin, limiting systematic testing, edge-case simulation, sensor modification, and sim-to-real evaluations. To address this gap, we present DrivIng, a large-scale multimodal dataset with a complete geo-referenced digital twin of a ~18 km route spanning urban, suburban, and highway segments. Our dataset provides continuous recordings from six RGB cameras, one LiDAR, and high-precision ADMA-based localization, captured across day, dusk, and night. All sequences are annotated at 10 Hz with 3D bounding boxes and track IDs across 12 classes, yielding ~1.2 million annotated instances. Alongside the benefits of a digital twin, DrivIng enables a 1-to-1 transfer of real traffic into simulation, preserving agent interactions while enabling realistic and flexible scenario testing. To support reproducible research and robust validation, we benchmark DrivIng with state-of-the-art perception models and publicly release the dataset, digital twin, HD map, and codebase.
Towards Transformer-based Homogenization of Satellite Imagery for Landsat-8 and Sentinel-2
Oct 14, 2022
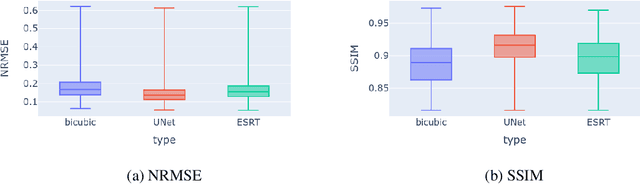

Landsat-8 (NASA) and Sentinel-2 (ESA) are two prominent multi-spectral imaging satellite projects that provide publicly available data. The multi-spectral imaging sensors of the satellites capture images of the earth's surface in the visible and infrared region of the electromagnetic spectrum. Since the majority of the earth's surface is constantly covered with clouds, which are not transparent at these wavelengths, many images do not provide much information. To increase the temporal availability of cloud-free images of a certain area, one can combine the observations from multiple sources. However, the sensors of satellites might differ in their properties, making the images incompatible. This work provides a first glance at the possibility of using a transformer-based model to reduce the spectral and spatial differences between observations from both satellite projects. We compare the results to a model based on a fully convolutional UNet architecture. Somewhat surprisingly, we find that, while deep models outperform classical approaches, the UNet significantly outperforms the transformer in our experiments.