 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWave-Trainer-Fit: Neural Vocoder with Trainable Prior and Fixed-Point Iteration towards High-Quality Speech Generation from SSL features
Feb 05, 2026We propose WaveTrainerFit, a neural vocoder that performs high-quality waveform generation from data-driven features such as SSL features. WaveTrainerFit builds upon the WaveFit vocoder, which integrates diffusion model and generative adversarial network. Furthermore, the proposed method incorporates the following key improvements: 1. By introducing trainable priors, the inference process starts from noise close to the target speech instead of Gaussian noise. 2. Reference-aware gain adjustment is performed by imposing constraints on the trainable prior to matching the speech energy. These improvements are expected to reduce the complexity of waveform modeling from data-driven features, enabling high-quality waveform generation with fewer inference steps. Through experiments, we showed that WaveTrainerFit can generate highly natural waveforms with improved speaker similarity from data-driven features, while requiring fewer iterations than WaveFit. Moreover, we showed that the proposed method works robustly with respect to the depth at which SSL features are extracted. Code and pre-trained models are available from https://github.com/line/WaveTrainerFit.
Grapheme-Coherent Phonemic and Prosodic Annotation of Speech by Implicit and Explicit Grapheme Conditioning
Jun 05, 2025We propose a model to obtain phonemic and prosodic labels of speech that are coherent with graphemes. Unlike previous methods that simply fine-tune a pre-trained ASR model with the labels, the proposed model conditions the label generation on corresponding graphemes by two methods: 1) Add implicit grapheme conditioning through prompt encoder using pre-trained BERT features. 2) Explicitly prune the label hypotheses inconsistent with the grapheme during inference. These methods enable obtaining parallel data of speech, the labels, and graphemes, which is applicable to various downstream tasks such as text-to-speech and accent estimation from text. Experiments showed that the proposed method significantly improved the consistency between graphemes and the predicted labels. Further, experiments on accent estimation task confirmed that the created parallel data by the proposed method effectively improve the estimation accuracy.
Unsupervised speech enhancement with spectral kurtosis and double deep priors
Jul 04, 2024This paper proposes an unsupervised DNN-based speech enhancement approach founded on deep priors (DPs). Here, DP signifies that DNNs are more inclined to produce clean speech signals than noises. Conventional methods based on DP typically involve training on a noisy speech signal using a random noise feature as input, stopping training only a clean speech signal is generated. However, such conventional approaches encounter challenges in determining the optimal stop timing, experience performance degradation due to environmental background noise, and suffer a trade-off between distortion of the clean speech signal and noise reduction performance. To address these challenges, we utilize two DNNs: one to generate a clean speech signal and the other to generate noise. The combined output of these networks closely approximates the noisy speech signal, with a loss term based on spectral kurtosis utilized to separate the noisy speech signal into a clean speech signal and noise. The key advantage of this method lies in its ability to circumvent trade-offs and early stopping problems, as the signal is decomposed by enough steps. Through evaluation experiments, we demonstrate that the proposed method outperforms conventional methods in the case of white Gaussian and environmental noise while effectively mitigating early stopping problems.
Visual onoma-to-wave: environmental sound synthesis from visual onomatopoeias and sound-source images
Oct 17, 2022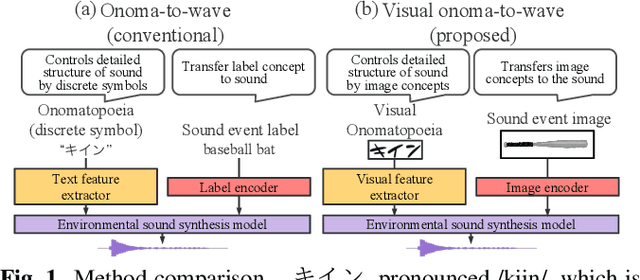
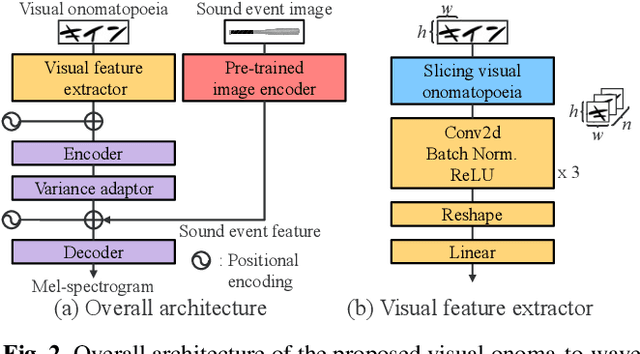

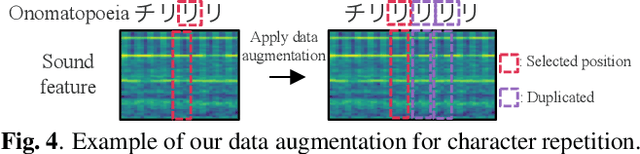
We propose a method for synthesizing environmental sounds from visually represented onomatopoeias and sound sources. An onomatopoeia is a word that imitates a sound structure, i.e., the text representation of sound. From this perspective, onoma-to-wave has been proposed to synthesize environmental sounds from the desired onomatopoeia texts. Onomatopoeias have another representation: visual-text representations of sounds in comics, advertisements, and virtual reality. A visual onomatopoeia (visual text of onomatopoeia) contains rich information that is not present in the text, such as a long-short duration of the image, so the use of this representation is expected to synthesize diverse sounds. Therefore, we propose visual onoma-to-wave for environmental sound synthesis from visual onomatopoeia. The method can transfer visual concepts of the visual text and sound-source image to the synthesized sound. We also propose a data augmentation method focusing on the repetition of onomatopoeias to enhance the performance of our method. An experimental evaluation shows that the methods can synthesize diverse environmental sounds from visual text and sound-source images.