 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Composite Layers for Deep Anomaly Detection on 3D Point Clouds
Sep 23, 2022
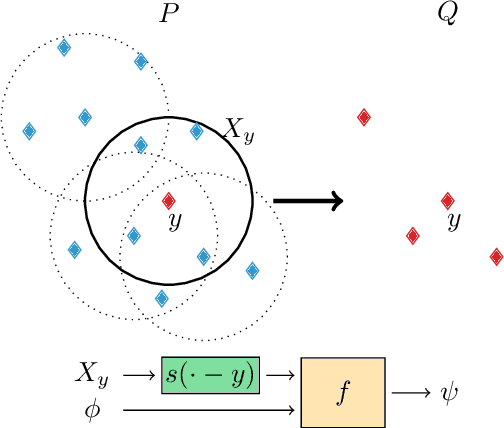
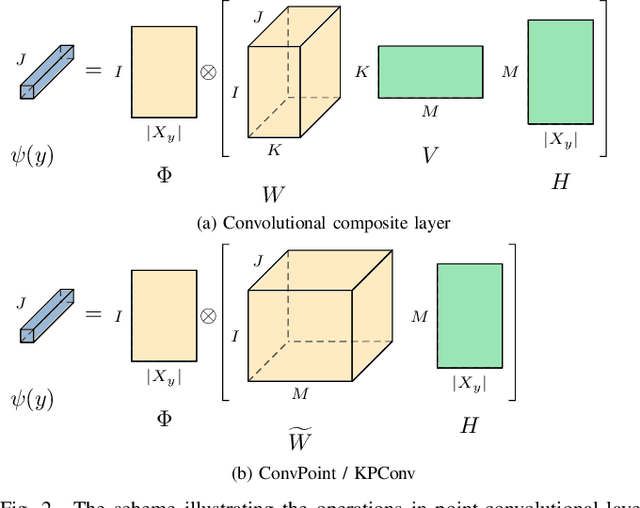
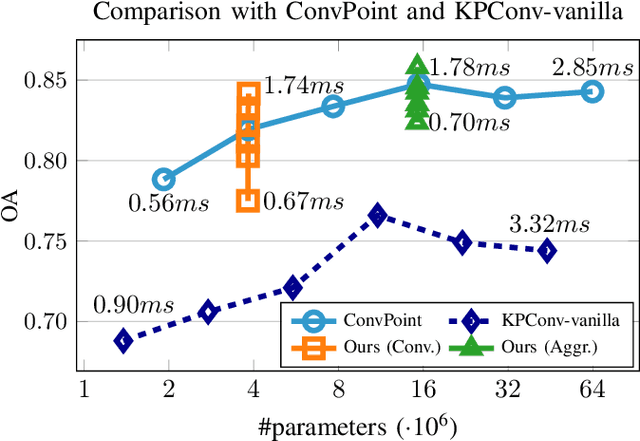
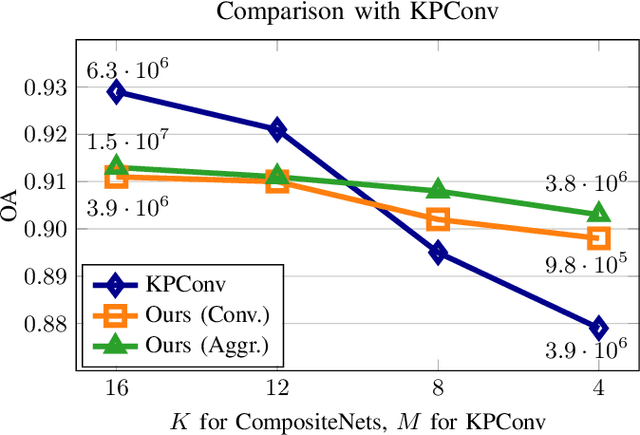
Deep neural networks require specific layers to process point clouds, as the scattered and irregular location of points prevents us from using convolutional filters. Here we introduce the composite layer, a new convolutional operator for point clouds. The peculiarity of our composite layer is that it extracts and compresses the spatial information from the position of points before combining it with their feature vectors. Compared to well-known point-convolutional layers such as those of ConvPoint and KPConv, our composite layer provides additional regularization and guarantees greater flexibility in terms of design and number of parameters. To demonstrate the design flexibility, we also define an aggregate composite layer that combines spatial information and features in a nonlinear manner, and we use these layers to implement a convolutional and an aggregate CompositeNet. We train our CompositeNets to perform classification and, most remarkably, unsupervised anomaly detection. Our experiments on synthetic and real-world datasets show that, in both tasks, our CompositeNets outperform ConvPoint and achieve similar results as KPConv despite having a much simpler architecture. Moreover, our CompositeNets substantially outperform existing solutions for anomaly detection on point clouds.
Degree-of-Freedom of Modulating Information in the Phases of Reconfigurable Intelligent Surface
Dec 27, 2021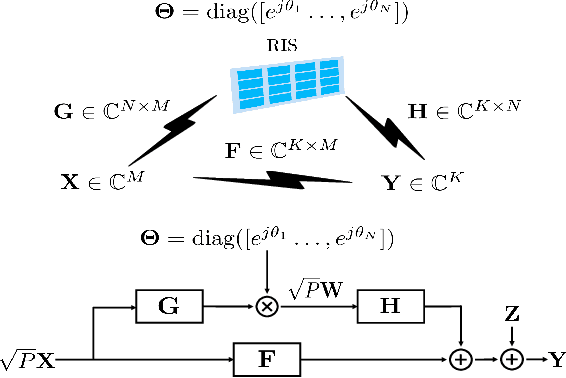
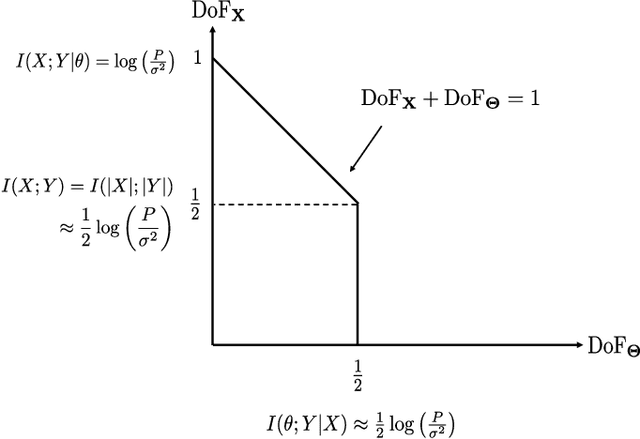
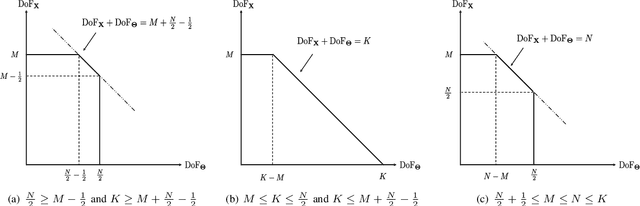
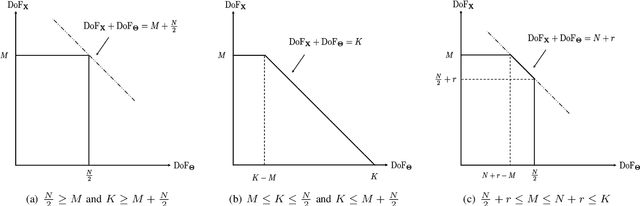
This paper investigates the information theoretical limit of a reconfigurable intelligent surface (RIS) aided communication scenario in which the RIS and the transmitter either jointly or independently send information to the receiver. The RIS is an emerging technology that uses a large number of passive reflective elements with adjustable phases to intelligently reflect the transmit signal to the intended receiver. While most previous studies of the RIS focus on its ability to beamform and to boost the received signal-to-noise ratio (SNR), this paper shows that if the information data stream is also available at the RIS and can be modulated through the adjustable phases at the RIS, significant improvement in the {degree-of-freedom} (DoF) of the overall channel is possible. For example, for an RIS system in which the signals are reflected from a transmitter with $M$ antennas to a receiver with $K$ antennas through an RIS with $N$ reflective elements, assuming no direct path between the transmitter and the receiver, joint transmission of the transmitter and the RIS can achieve a DoF of $\min(M+\frac{N}{2}-\frac{1}{2},N,K)$ as compared to the DoF of $\min(M,K)$ for the conventional multiple-input multiple-output (MIMO) channel. This result is obtained by establishing a connection between the RIS system and the MIMO channel with phase noises and by using results for characterizing the information dimension under projection. The result is further extended to the case with a direct path between the transmitter and the receiver, and also to the multiple access scenario, in which the transmitter and the RIS send independent information. Finally, this paper proposes a symbol-level precoding approach for modulating data through the phases of the RIS, and provides numerical simulation results to verify the theoretical DoF results.
Leveraging Artificial Intelligence on Binary Code Comprehension
Oct 11, 2022Understanding binary code is an essential but complex software engineering task for reverse engineering, malware analysis, and compiler optimization. Unlike source code, binary code has limited semantic information, which makes it challenging for human comprehension. At the same time, compiling source to binary code, or transpiling among different programming languages (PLs) can provide a way to introduce external knowledge into binary comprehension. We propose to develop Artificial Intelligence (AI) models that aid human comprehension of binary code. Specifically, we propose to incorporate domain knowledge from large corpora of source code (e.g., variable names, comments) to build AI models that capture a generalizable representation of binary code. Lastly, we will investigate metrics to assess the performance of models that apply to binary code by using human studies of comprehension.
Active Metric-Semantic Mapping by Multiple Aerial Robots
Sep 18, 2022
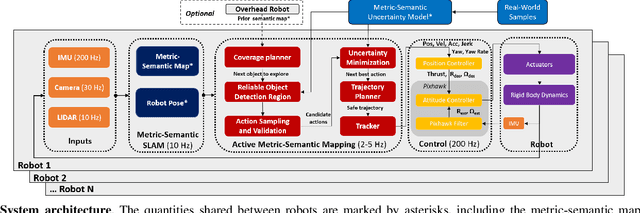
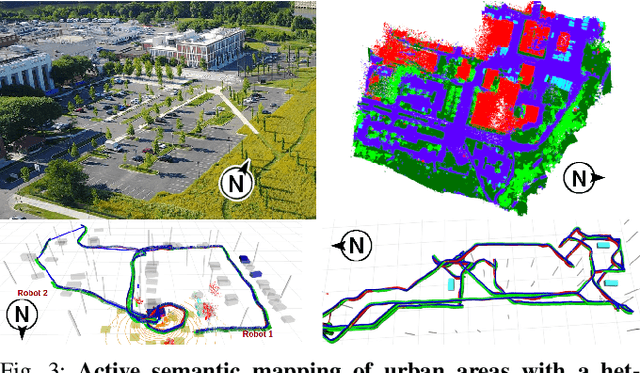
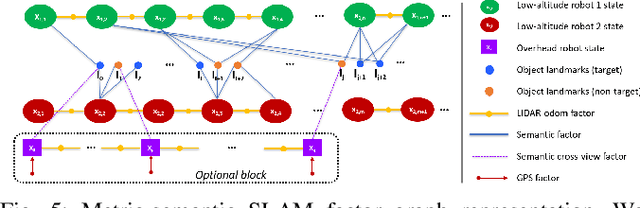
Traditional approaches for active mapping focus on building geometric maps. For most real-world applications, however, actionable information is related to semantically meaningful objects in the environment. We propose an approach to the active metric-semantic mapping problem that enables multiple heterogeneous robots to collaboratively build a map of the environment. The robots actively explore to minimize the uncertainties in both semantic (object classification) and geometric (object modeling) information. We represent the environment using informative but sparse object models, each consisting of a basic shape and a semantic class label, and characterize uncertainties empirically using a large amount of real-world data. Given a prior map, we use this model to select actions for each robot to minimize uncertainties. The performance of our algorithm is demonstrated through multi-robot experiments in diverse real-world environments. The proposed framework is applicable to a wide range of real-world problems, such as precision agriculture, infrastructure inspection, and asset mapping in factories.
Differentially Private Language Models for Secure Data Sharing
Oct 26, 2022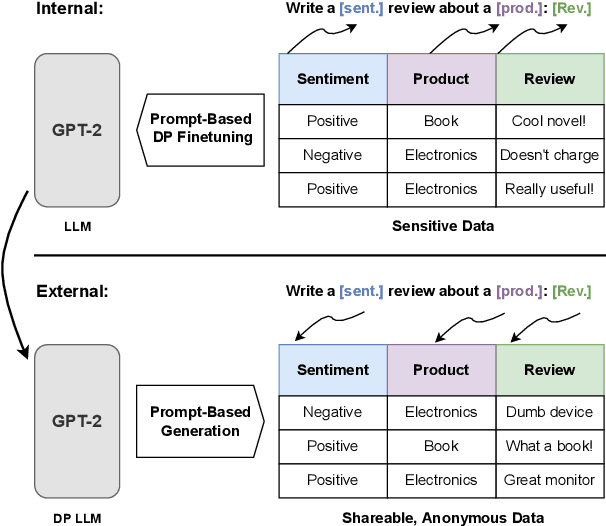
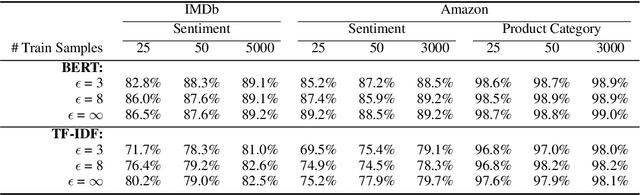

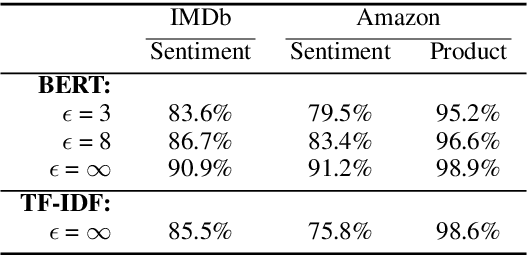
To protect the privacy of individuals whose data is being shared, it is of high importance to develop methods allowing researchers and companies to release textual data while providing formal privacy guarantees to its originators. In the field of NLP, substantial efforts have been directed at building mechanisms following the framework of local differential privacy, thereby anonymizing individual text samples before releasing them. In practice, these approaches are often dissatisfying in terms of the quality of their output language due to the strong noise required for local differential privacy. In this paper, we approach the problem at hand using global differential privacy, particularly by training a generative language model in a differentially private manner and consequently sampling data from it. Using natural language prompts and a new prompt-mismatch loss, we are able to create highly accurate and fluent textual datasets taking on specific desired attributes such as sentiment or topic and resembling statistical properties of the training data. We perform thorough experiments indicating that our synthetic datasets do not leak information from our original data and are of high language quality and highly suitable for training models for further analysis on real-world data. Notably, we also demonstrate that training classifiers on private synthetic data outperforms directly training classifiers on real data with DP-SGD.
Geographic Citation Gaps in NLP Research
Oct 26, 2022
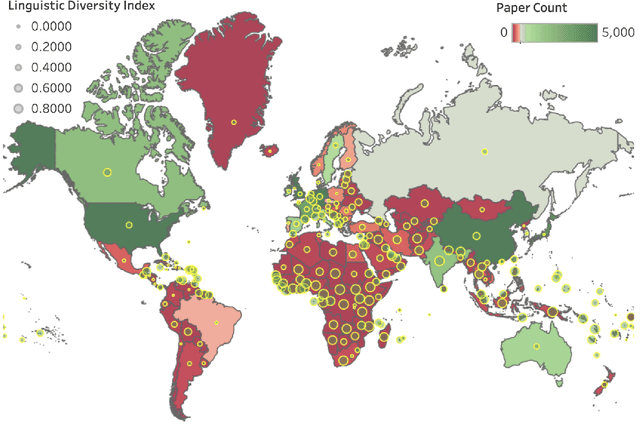
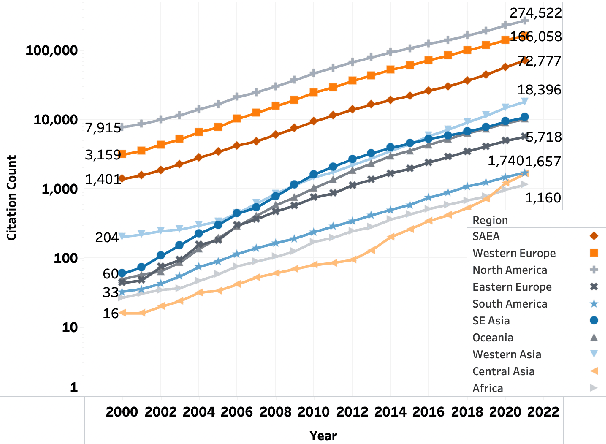
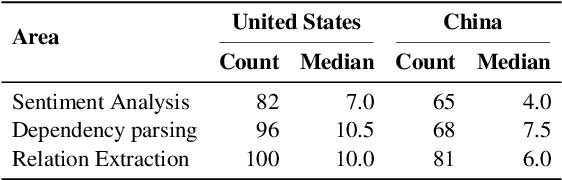
In a fair world, people have equitable opportunities to education, to conduct scientific research, to publish, and to get credit for their work, regardless of where they live. However, it is common knowledge among researchers that a vast number of papers accepted at top NLP venues come from a handful of western countries and (lately) China; whereas, very few papers from Africa and South America get published. Similar disparities are also believed to exist for paper citation counts. In the spirit of "what we do not measure, we cannot improve", this work asks a series of questions on the relationship between geographical location and publication success (acceptance in top NLP venues and citation impact). We first created a dataset of 70,000 papers from the ACL Anthology, extracted their meta-information, and generated their citation network. We then show that not only are there substantial geographical disparities in paper acceptance and citation but also that these disparities persist even when controlling for a number of variables such as venue of publication and sub-field of NLP. Further, despite some steps taken by the NLP community to improve geographical diversity, we show that the disparity in publication metrics across locations is still on an increasing trend since the early 2000s. We release our code and dataset here: https://github.com/iamjanvijay/acl-cite-net
On the Ergodic Mutual Information of Keyhole MIMO Channels with Finite Inputs
Dec 29, 2021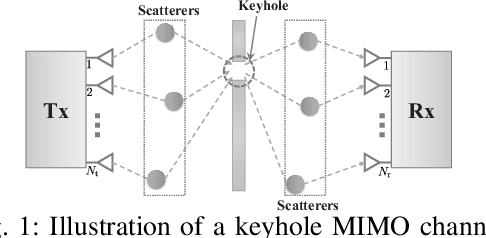
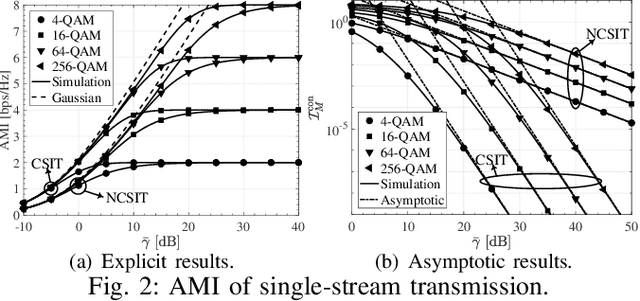
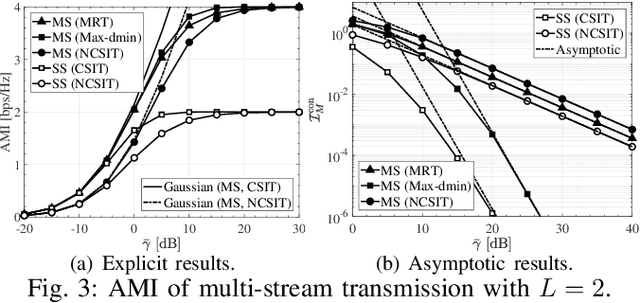
This letter studies the ergodic mutual information (EMI) of keyhole multiple-input multiple-output (MIMO) channels having finite input signals. At first, the EMI of single-stream transmission is investigated depending on whether the channel state information at the transmitter (CSIT) is available or not. Then, the derived results are extended to the case of multi-stream transmission. For the sake of providing more system insights, asymptotic analyses are performed in the regime of high signal-to-noise ratio (SNR), which suggests that the high-SNR EMI converges to some constant with its rate of convergence (ROC) determined by the diversity order. All the results are validated by numerical simulations and are in excellent agreement.
In the realm of hybrid Brain: Human Brain and AI
Oct 07, 2022
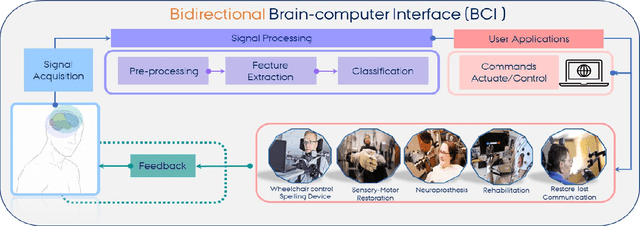
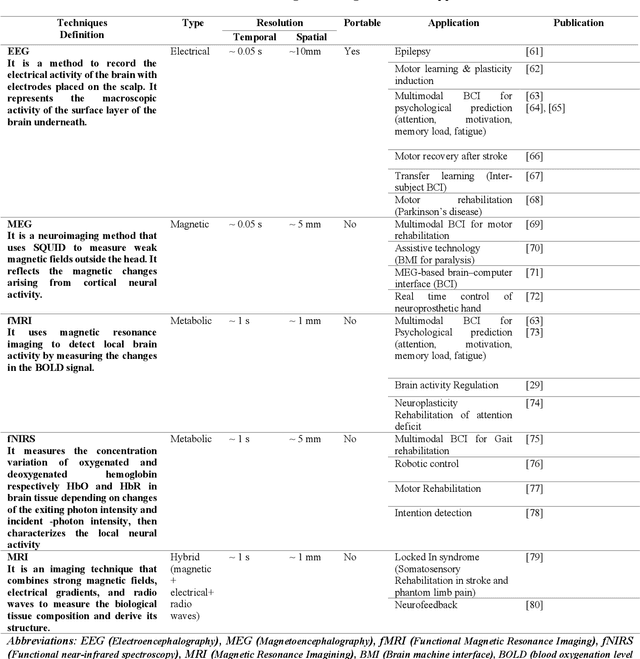
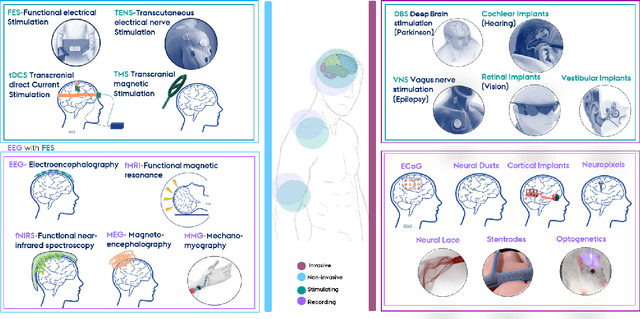
With the recent developments in neuroscience and engineering, it is now possible to record brain signals and decode them. Also, a growing number of stimulation methods have emerged to modulate and influence brain activity. Current brain-computer interface (BCI) technology is mainly on therapeutic outcomes, it already demonstrated its efficiency as assistive and rehabilitative technology for patients with severe motor impairments. Recently, artificial intelligence (AI) and machine learning (ML) technologies have been used to decode brain signals. Beyond this progress, combining AI with advanced BCIs in the form of implantable neurotechnologies grants new possibilities for the diagnosis, prediction, and treatment of neurological and psychiatric disorders. In this context, we envision the development of closed loop, intelligent, low-power, and miniaturized neural interfaces that will use brain inspired AI techniques with neuromorphic hardware to process the data from the brain. This will be referred to as Brain Inspired Brain Computer Interfaces (BI-BCIs). Such neural interfaces would offer access to deeper brain regions and better understanding for brain's functions and working mechanism, which improves BCIs operative stability and system's efficiency. On one hand, brain inspired AI algorithms represented by spiking neural networks (SNNs) would be used to interpret the multimodal neural signals in the BCI system. On the other hand, due to the ability of SNNs to capture rich dynamics of biological neurons and to represent and integrate different information dimensions such as time, frequency, and phase, it would be used to model and encode complex information processing in the brain and to provide feedback to the users. This paper provides an overview of the different methods to interface with the brain, presents future applications and discusses the merger of AI and BCIs.
Global-to-local Expression-aware Embeddings for Facial Action Unit Detection
Oct 28, 2022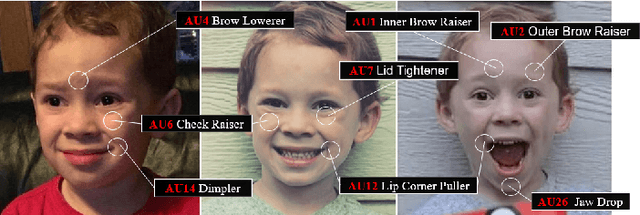
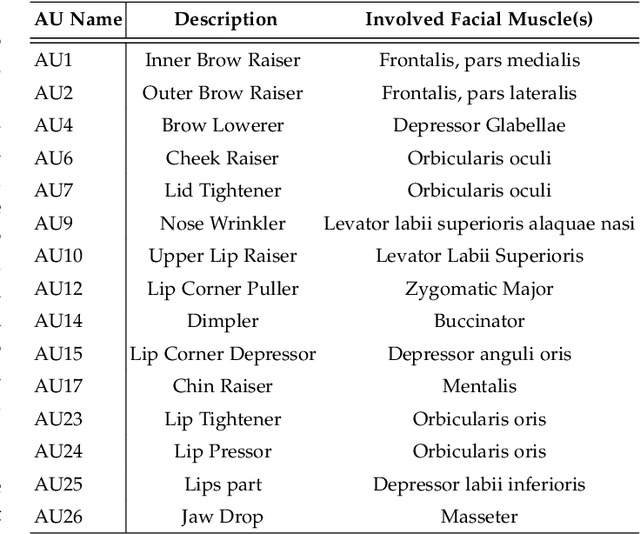
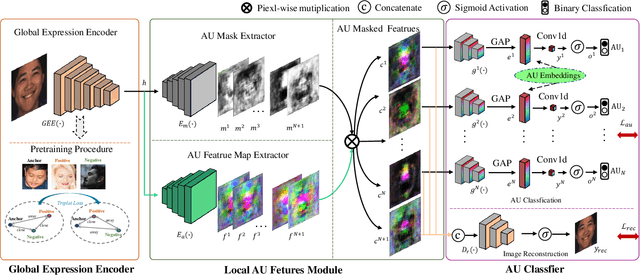
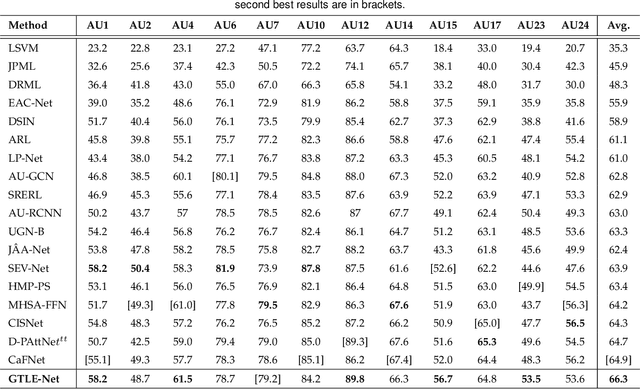
Expressions and facial action units (AUs) are two levels of facial behavior descriptors. Expression auxiliary information has been widely used to improve the AU detection performance. However, most existing expression representations can only describe pre-determined discrete categories (e.g., Angry, Disgust, Happy, Sad, etc.) and cannot capture subtle expression transformations like AUs. In this paper, we propose a novel fine-grained \textsl{Global Expression representation Encoder} to capture subtle and continuous facial movements, to promote AU detection. To obtain such a global expression representation, we propose to train an expression embedding model on a large-scale expression dataset according to global expression similarity. Moreover, considering the local definition of AUs, it is essential to extract local AU features. Therefore, we design a \textsl{Local AU Features Module} to generate local facial features for each AU. Specifically, it consists of an AU feature map extractor and a corresponding AU mask extractor. First, the two extractors transform the global expression representation into AU feature maps and masks, respectively. Then, AU feature maps and their corresponding AU masks are multiplied to generate AU masked features focusing on local facial region. Finally, the AU masked features are fed into an AU classifier for judging the AU occurrence. Extensive experiment results demonstrate the superiority of our proposed method. Our method validly outperforms previous works and achieves state-of-the-art performances on widely-used face datasets, including BP4D, DISFA, and BP4D+.
Doc-GCN: Heterogeneous Graph Convolutional Networks for Document Layout Analysis
Aug 22, 2022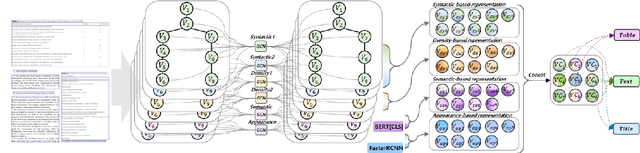


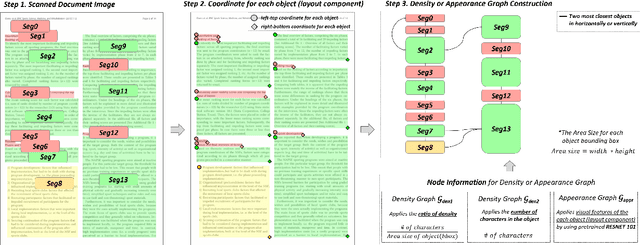
Recognizing the layout of unstructured digital documents is crucial when parsing the documents into the structured, machine-readable format for downstream applications. Recent studies in Document Layout Analysis usually rely on computer vision models to understand documents while ignoring other information, such as context information or relation of document components, which are vital to capture. Our Doc-GCN presents an effective way to harmonize and integrate heterogeneous aspects for Document Layout Analysis. We first construct graphs to explicitly describe four main aspects, including syntactic, semantic, density, and appearance/visual information. Then, we apply graph convolutional networks for representing each aspect of information and use pooling to integrate them. Finally, we aggregate each aspect and feed them into 2-layer MLPs for document layout component classification. Our Doc-GCN achieves new state-of-the-art results in three widely used DLA datasets.