 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Gaussian Process for Building Terrain-Incorporating Wind Power Curves
Jun 30, 2026Accurate modeling of wind turbine power curves is crucial for optimal wind farm operation. Nearly all existing power curve models focus on temporal variables such as wind speed and temperature while overlooking the influence of terrain covariates, which governs inflow wind conditions and thus also affects wind power production. This paper proposes a nonparametric spatio-temporal Gaussian process model that integrates temporal environmental covariates with spatial terrain features. The model falls in the category of spatial-temporal Gaussian process models with data on a grid. The challenge to be addressed is that the spatio-temporal modeling require certain temporal alignment among the data, a property that the wind farm data does not have. Our solution strategy is to construct a shared representative temporal covariate set which not only aligns the temporal inputs but also has a size an order of magnitude smaller than the original data size. With this transformation, our resulting model is able to employ a separable kernel structure that captures both spatial and temporal dependencies. Empirical analysis on a real wind farm dataset shows that our method improves predictive accuracy over existing baselines and can be used to quantify the various impact of the terrain characteristics on turbine performance.
StarOR: Synergizing Tree Search and Test-Time Reinforcement Learning for Optimization Modeling
Jun 18, 2026Optimization modeling is inherently hierarchical, requiring a precise sequence of symbolic commitments. Traditional learning-based automated optimization modeling methods improve modeling policies through large-scale annotated or curated training data, but are costly to adapt to new problem distributions. Meanwhile, one-shot generation remains brittle in hierarchical modeling, where early symbolic errors can propagate into invalid formulations. Test-time scaling offers a promising alternative by enabling structural exploration with additional instance-level computation; however, existing search-based methods typically rely on a fixed policy, causing repeated rollouts to inherit similar modeling biases and providing limited credit assignment for intermediate decisions. To address these limitations, we propose StarOR, a synergistic search-and-adaptation framework that couples MCTS with Test-Time Reinforcement Learning for optimization modeling. StarOR decomposes the modeling process into four stages and updates a transient LoRA adapter via GRPO at each non-terminal node. By using MCTS-generated siblings as local comparison sets, StarOR transforms search-time exploration into instance-specific policy refinement. Moreover, an unsupervised multi-faceted reward system provides fine-grained feedback for intermediate formulation decisions without ground-truth labels. Experiments across five optimization benchmarks show that StarOR achieves state-of-the-art performance even with a 4B backbone, outperforming existing methods and the frontier LLMs.
ORAgentBench: Can LLM Agents Solve Challenging Operations Research Tasks End to End?
Jun 18, 2026Large language models are increasingly deployed as autonomous agents for multi-step tasks in executable environments, yet their ability to perform realistic operations research (OR) work remains unclear. Existing OR evaluations often decouple modeling from solving, rely on pre-formalized or text-only instances, and rarely test the full workflow from operational artifacts to validated decisions. In this work, we introduce ORAgentBench, an execution-grounded benchmark for evaluating autonomous agents on challenging end-to-end operations research tasks. It contains 107 human-reviewed tasks across diverse operational scenarios, each packaged in an isolated environment with a natural-language brief, multi-file data, configuration artifacts, and a required submission schema. Agents must write and run solution code, and their submissions are evaluated by hidden validators for schema validity, hard-constraint feasibility, and normalized objective quality. Experiments with fourteen frontier agent-model configurations show that current agents remain far from reliable OR practice. The best agent passes only 35.51% of all tasks and 20.59% of hard tasks, and many feasible submissions still fall below the required quality threshold. Failure analysis further shows that errors are dominated by strategic weaknesses, including missed operational rules, brittle formulations, weak feasible-solution construction, and insufficient solution improvement. OR-specific procedural skills increase hard-task feasibility, but do not reliably improve solution quality or pass rate. These results suggest that progress in OR agents requires moving beyond plausible optimization code toward dependable, high-quality operational decision-making.
Traceable Knowledge Graph Reasoning Enables LLM-Assisted Decision Support for Industrial VOCs in the Steel Industry
May 26, 2026Key knowledge for steel-industry volatile organic compounds (VOCs) governance is scattered across unstructured scientific literature, making it difficult to integrate process, pollutant, and control-technology evidence and increasing the risk of hallucination when general large language models (LLMs) answer low-frequency industrial questions. Here we developed Chat-ISV, a knowledge graph (KG) enhanced multi-agent Q&A system that parses a curated steel-industry VOCs literature corpus, constructs a Neo4j KG with 27180 nodes and 81779 semantic edges, and combines prompt-constrained extraction, chunk-centered topology optimization, multi-agent routing, source-backtracking retrieval, local literature retrieval, open-domain knowledge access, and interactive subgraph visualization. Benchmark tests and 400 expert blind evaluations showed that topology optimization reduced isolated nodes from 57% to 4.08% and that Chat-ISV achieved high factual reliability, with 96.93% precision, 72.63% recall, an F1-score of 0.830, and a mean score of 1.69/2.00. By converting fragmented environmental-engineering literature into traceable, queryable, and decision-support-oriented knowledge, Chat-ISV establishes a scalable environmental-informatics paradigm for reliable LLM deployment and intelligent pollution-control decision support in specialized industrial domains.
MUSIC: Learning Muscle-Driven Dexterous Hand Control
Apr 26, 2026We present a data-driven approach for physics-based, muscle-driven dexterous control that enables musculoskeletal hands to perform precise piano playing for novel pieces of music outside the reference dataset. Our approach combines high-frequency muscle-level control with low-frequency latent-space coordination in a hierarchical architecture. At the low level, general single-hand policies are trained via reinforcement learning to generate dynamic muscle-tendon activations while tracking trajectories from a large reference motion dataset. The resulting tracking policies are then distilled into variational autoencoder (VAE) models, yielding smooth and structured latent spaces that abstract away low-level muscle dynamics. For the high level, we train piece-specific policies to operate in this latent space, coordinating bimanual motions based on specific goals, denoted by note events extracted from given musical scores, to synthesize performances beyond the reference data. In addition, we present an enhanced musculoskeletal hand model that supports fine control of fingers for accurate low-level motion tracking and diverse high-level motion synthesis. We evaluate the control pipeline of our approach on a diverse piano repertoire spanning multiple musical styles and technical demands. Results demonstrate that our approach can synthesize coordinated bimanual motions with accurate key presses, and achieve the state-of-the-art performance of piano playing in physics-based dexterous control. We also show that our musculoskeletal hand model demonstrates superior biomechanical stability and tracking precision compared to the existing model, and validate that our musculoskeletal hand model and muscle-driven controller can generate physiologically plausible activation patterns that align with human electromyography (EMG) recordings.
Opal: Private Memory for Personal AI
Apr 02, 2026Personal AI systems increasingly retain long-term memory of user activity, including documents, emails, messages, meetings, and ambient recordings. Trusted hardware can keep this data private, but struggles to scale with a growing datastore. This pushes the data to external storage, which exposes retrieval access patterns that leak private information to the application provider. Oblivious RAM (ORAM) is a cryptographic primitive that can hide these patterns, but it requires a fixed access budget, precluding the query-dependent traversals that agentic memory systems rely on for accuracy. We present Opal, a private memory system for personal AI. Our key insight is to decouple all data-dependent reasoning from the bulk of personal data, confining it to the trusted enclave. Untrusted disk then sees only fixed, oblivious memory accesses. This enclave-resident component uses a lightweight knowledge graph to capture personal context that semantic search alone misses and handles continuous ingestion by piggybacking reindexing and capacity management on every ORAM access. Evaluated on a comprehensive synthetic personal-data pipeline driven by stochastic communication models, Opal improves retrieval accuracy by 13 percentage points over semantic search and achieves 29x higher throughput with 15x lower infrastructure cost than a secure baseline. Opal is under consideration for deployment to millions of users at a major AI provider.
Deep Variable-Length Feedback Codes
Feb 08, 2026Deep learning has enabled significant advances in feedback-based channel coding, yet existing learned schemes remain fundamentally limited: they employ fixed block lengths, suffer degraded performance at high rates, and cannot fully exploit the adaptive potential of feedback. This paper introduces Deep Variable-Length Feedback (DeepVLF) coding, a flexible coding framework that dynamically adjusts transmission length via learned feedback. We propose two complementary architectures: DeepVLF-R, where termination is receiver-driven, and DeepVLF-T, where the transmitter controls termination. Both architectures leverage bit-group partitioning and transformer-based encoder-decoder networks to enable fine-grained rate adaptation in response to feedback. Evaluations over AWGN and 5G-NR fading channels demonstrate that DeepVLF substantially outperforms state-of-the-art learned feedback codes. It achieves the same block error rate with 20%-55% fewer channel uses and lowers error floors by orders of magnitude, particularly in high-rate regimes. Encoding dynamics analysis further reveals that the models autonomously learn a two-phase strategy analogous to classical Schalkwijk-Kailath coding: an initial information-carrying phase followed by a noise-cancellation refinement phase. This emergent behavior underscores the interpretability and information-theoretic alignment of the learned codes.
Constraint Matters: Multi-Modal Representation for Reducing Mixed-Integer Linear programming
Aug 26, 2025Model reduction, which aims to learn a simpler model of the original mixed integer linear programming (MILP), can solve large-scale MILP problems much faster. Most existing model reduction methods are based on variable reduction, which predicts a solution value for a subset of variables. From a dual perspective, constraint reduction that transforms a subset of inequality constraints into equalities can also reduce the complexity of MILP, but has been largely ignored. Therefore, this paper proposes a novel constraint-based model reduction approach for the MILP. Constraint-based MILP reduction has two challenges: 1) which inequality constraints are critical such that reducing them can accelerate MILP solving while preserving feasibility, and 2) how to predict these critical constraints efficiently. To identify critical constraints, we first label these tight-constraints at the optimal solution as potential critical constraints and design a heuristic rule to select a subset of critical tight-constraints. To learn the critical tight-constraints, we propose a multi-modal representation technique that leverages information from both instance-level and abstract-level MILP formulations. The experimental results show that, compared to the state-of-the-art methods, our method improves the quality of the solution by over 50\% and reduces the computation time by 17.47\%.
Mutual Information Surprise: Rethinking Unexpectedness in Autonomous Systems
Aug 24, 2025Recent breakthroughs in autonomous experimentation have demonstrated remarkable physical capabilities, yet their cognitive control remains limited--often relying on static heuristics or classical optimization. A core limitation is the absence of a principled mechanism to detect and adapt to the unexpectedness. While traditional surprise measures--such as Shannon or Bayesian Surprise--offer momentary detection of deviation, they fail to capture whether a system is truly learning and adapting. In this work, we introduce Mutual Information Surprise (MIS), a new framework that redefines surprise not as anomaly detection, but as a signal of epistemic growth. MIS quantifies the impact of new observations on mutual information, enabling autonomous systems to reflect on their learning progression. We develop a statistical test sequence to detect meaningful shifts in estimated mutual information and propose a mutual information surprise reaction policy (MISRP) that dynamically governs system behavior through sampling adjustment and process forking. Empirical evaluations--on both synthetic domains and a dynamic pollution map estimation task--show that MISRP-governed strategies significantly outperform classical surprise-based approaches in stability, responsiveness, and predictive accuracy. By shifting surprise from reactive to reflective, MIS offers a path toward more self-aware and adaptive autonomous systems.
MienCap: Realtime Performance-Based Facial Animation with Live Mood Dynamics
Aug 06, 2025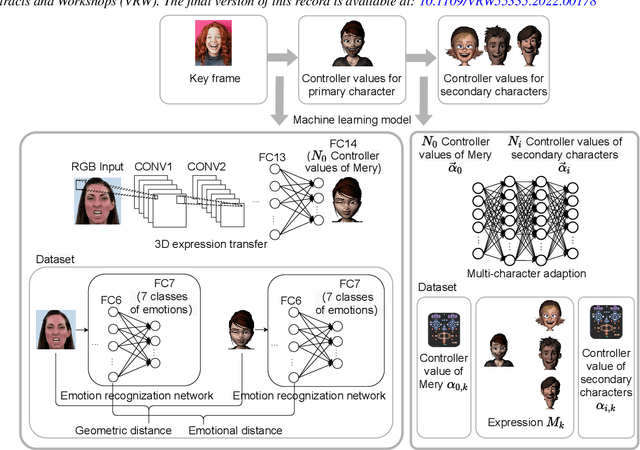
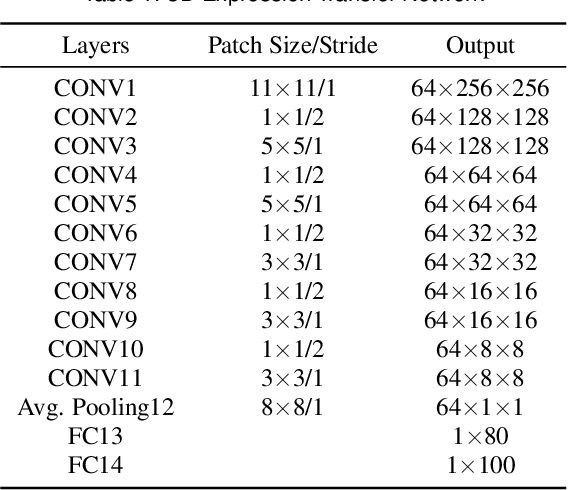
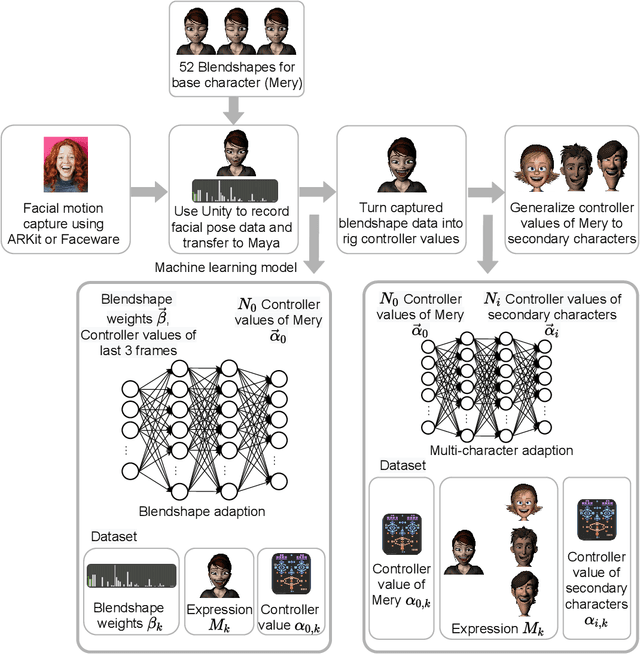

Our purpose is to improve performance-based animation which can drive believable 3D stylized characters that are truly perceptual. By combining traditional blendshape animation techniques with multiple machine learning models, we present both non-real time and real time solutions which drive character expressions in a geometrically consistent and perceptually valid way. For the non-real time system, we propose a 3D emotion transfer network makes use of a 2D human image to generate a stylized 3D rig parameters. For the real time system, we propose a blendshape adaption network which generates the character rig parameter motions with geometric consistency and temporally stability. We demonstrate the effectiveness of our system by comparing to a commercial product Faceware. Results reveal that ratings of the recognition, intensity, and attractiveness of expressions depicted for animated characters via our systems are statistically higher than Faceware. Our results may be implemented into the animation pipeline, and provide animators with a system for creating the expressions they wish to use more quickly and accurately.