 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Eval Judge: Towards a General Agentic Framework for Task Completion Evaluation
Aug 07, 2025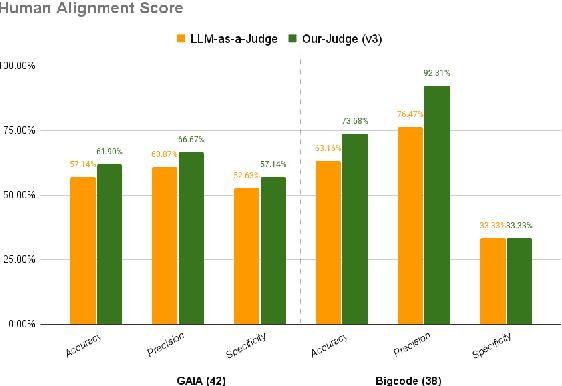
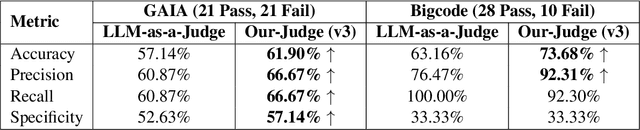
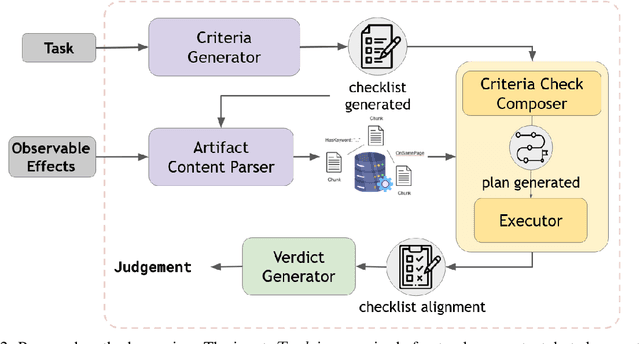
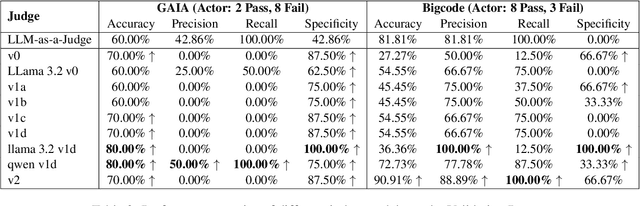
The increasing adoption of foundation models as agents across diverse domains necessitates a robust evaluation framework. Current methods, such as LLM-as-a-Judge, focus only on final outputs, overlooking the step-by-step reasoning that drives agentic decision-making. Meanwhile, existing Agent-as-a-Judge systems, where one agent evaluates another's task completion, are typically designed for narrow, domain-specific settings. To address this gap, we propose a generalizable, modular framework for evaluating agent task completion independent of the task domain. The framework emulates human-like evaluation by decomposing tasks into sub-tasks and validating each step using available information, such as the agent's output and reasoning. Each module contributes to a specific aspect of the evaluation process, and their outputs are aggregated to produce a final verdict on task completion. We validate our framework by evaluating the Magentic-One Actor Agent on two benchmarks, GAIA and BigCodeBench. Our Judge Agent predicts task success with closer agreement to human evaluations, achieving 4.76% and 10.52% higher alignment accuracy, respectively, compared to the GPT-4o based LLM-as-a-Judge baseline. This demonstrates the potential of our proposed general-purpose evaluation framework.
Does Prompt Formatting Have Any Impact on LLM Performance?
Nov 15, 2024



In the realm of Large Language Models (LLMs), prompt optimization is crucial for model performance. Although previous research has explored aspects like rephrasing prompt contexts, using various prompting techniques (like in-context learning and chain-of-thought), and ordering few-shot examples, our understanding of LLM sensitivity to prompt templates remains limited. Therefore, this paper examines the impact of different prompt templates on LLM performance. We formatted the same contexts into various human-readable templates, including plain text, Markdown, JSON, and YAML, and evaluated their impact across tasks like natural language reasoning, code generation, and translation using OpenAI's GPT models. Experiments show that GPT-3.5-turbo's performance varies by up to 40\% in a code translation task depending on the prompt template, while larger models like GPT-4 are more robust to these variations. Our analysis highlights the need to reconsider the use of fixed prompt templates, as different formats can significantly affect model performance.
HiGen: Hierarchy-Aware Sequence Generation for Hierarchical Text Classification
Jan 24, 2024



Hierarchical text classification (HTC) is a complex subtask under multi-label text classification, characterized by a hierarchical label taxonomy and data imbalance. The best-performing models aim to learn a static representation by combining document and hierarchical label information. However, the relevance of document sections can vary based on the hierarchy level, necessitating a dynamic document representation. To address this, we propose HiGen, a text-generation-based framework utilizing language models to encode dynamic text representations. We introduce a level-guided loss function to capture the relationship between text and label name semantics. Our approach incorporates a task-specific pretraining strategy, adapting the language model to in-domain knowledge and significantly enhancing performance for classes with limited examples. Furthermore, we present a new and valuable dataset called ENZYME, designed for HTC, which comprises articles from PubMed with the goal of predicting Enzyme Commission (EC) numbers. Through extensive experiments on the ENZYME dataset and the widely recognized WOS and NYT datasets, our methodology demonstrates superior performance, surpassing existing approaches while efficiently handling data and mitigating class imbalance. The data and code will be released publicly.
Forgotten Knowledge: Examining the Citational Amnesia in NLP
May 29, 2023



Citing papers is the primary method through which modern scientific writing discusses and builds on past work. Collectively, citing a diverse set of papers (in time and area of study) is an indicator of how widely the community is reading. Yet, there is little work looking at broad temporal patterns of citation. This work systematically and empirically examines: How far back in time do we tend to go to cite papers? How has that changed over time, and what factors correlate with this citational attention/amnesia? We chose NLP as our domain of interest and analyzed approximately 71.5K papers to show and quantify several key trends in citation. Notably, around 62% of cited papers are from the immediate five years prior to publication, whereas only about 17% are more than ten years old. Furthermore, we show that the median age and age diversity of cited papers were steadily increasing from 1990 to 2014, but since then, the trend has reversed, and current NLP papers have an all-time low temporal citation diversity. Finally, we show that unlike the 1990s, the highly cited papers in the last decade were also papers with the least citation diversity, likely contributing to the intense (and arguably harmful) recency focus. Code, data, and a demo are available on the project homepage.
Geographic Citation Gaps in NLP Research
Oct 26, 2022



In a fair world, people have equitable opportunities to education, to conduct scientific research, to publish, and to get credit for their work, regardless of where they live. However, it is common knowledge among researchers that a vast number of papers accepted at top NLP venues come from a handful of western countries and (lately) China; whereas, very few papers from Africa and South America get published. Similar disparities are also believed to exist for paper citation counts. In the spirit of "what we do not measure, we cannot improve", this work asks a series of questions on the relationship between geographical location and publication success (acceptance in top NLP venues and citation impact). We first created a dataset of 70,000 papers from the ACL Anthology, extracted their meta-information, and generated their citation network. We then show that not only are there substantial geographical disparities in paper acceptance and citation but also that these disparities persist even when controlling for a number of variables such as venue of publication and sub-field of NLP. Further, despite some steps taken by the NLP community to improve geographical diversity, we show that the disparity in publication metrics across locations is still on an increasing trend since the early 2000s. We release our code and dataset here: https://github.com/iamjanvijay/acl-cite-net