 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A study linking patient EHR data to external death data at Stanford Medicine
Nov 02, 2022
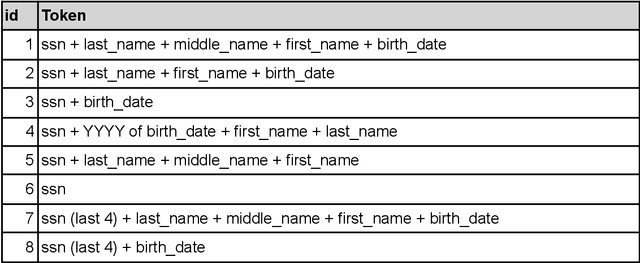
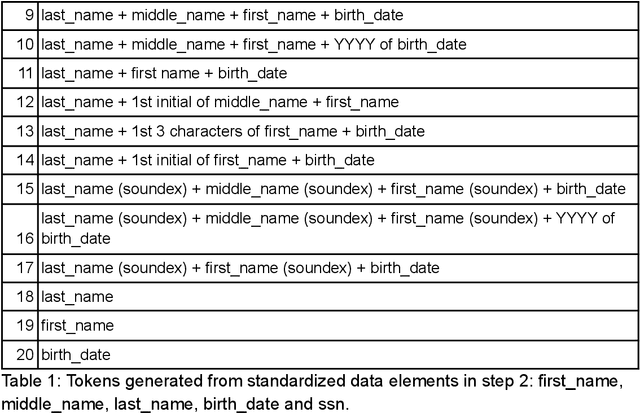
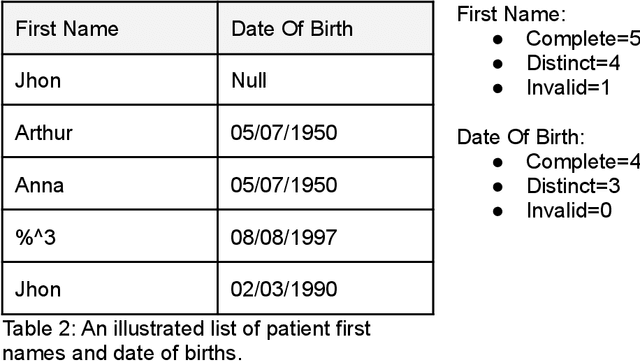
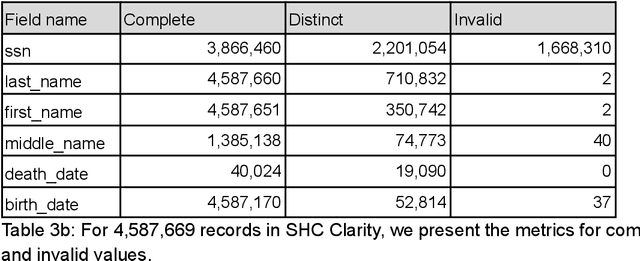
This manuscript explores linking real-world patient data with external death data in the context of research Clinical Data Warehouses (r-CDWs). We specifically present the linking of Electronic Health Records (EHR) data for Stanford Health Care (SHC) patients and data from the Social Security Administration (SSA) Limited Access Death Master File (LADMF) made available by the US Department of Commerce's National Technical Information Service (NTIS). The data analysis framework presented in this manuscript extends prior approaches and is generalizable to linking any two cross-organizational real-world patient data sources. Electronic Health Record (EHR) data and NTIS LADMF are heavily used resources at other medical centers and we expect that the methods and learnings presented here will be valuable to others. Our findings suggest that strong linkages are incomplete and weak linkages are noisy i.e., there is no good linkage rule that provides coverage and accuracy. Furthermore, the best linkage rule for any two datasets is different from the best linkage rule for two other datasets i.e., there is no generalization of linkage rules. Finally, LADMF, a commonly used external death data resource for r-CDWs, has a significant gap in death data making it necessary for r-CDWs to seek out more than one external death data source. We anticipate that presentation of multiple linkages will make it hard to present the linkage outcome to the end user. This manuscript is a resource in support of Stanford Medicine STARR (STAnford medicine Research data Repository) r-CDWs. The data are stored and analyzed as PHI in our HIPAA-compliant data center and are used under research and development (R&D) activities of STARR IRB.
Coordinated Transmit Beamforming for Multi-antenna Network Integrated Sensing and Communication
Nov 02, 2022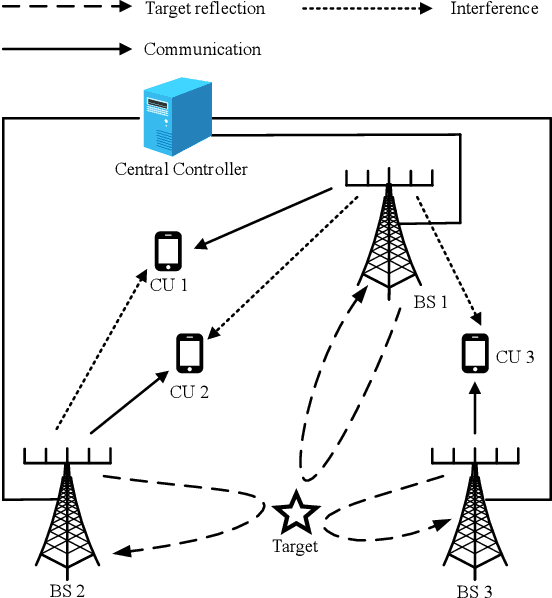
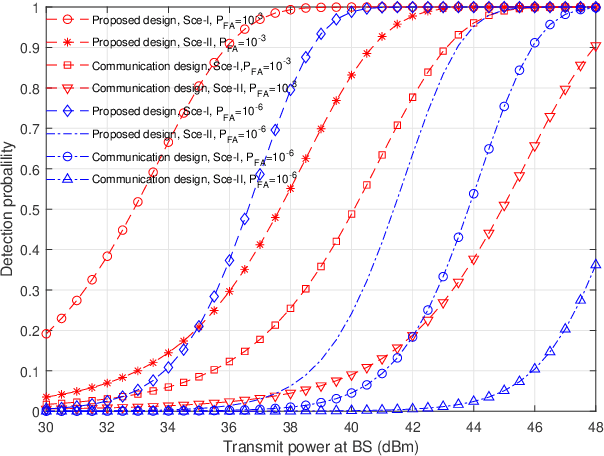
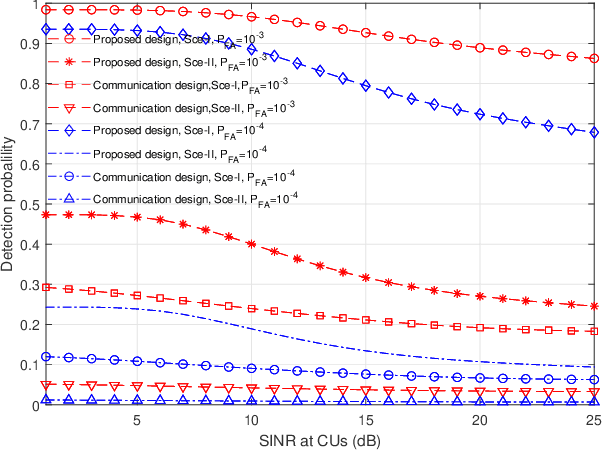
This paper studies a multi-antenna network integrated sensing and communication (ISAC) system, in which a set of multi-antenna base stations (BSs) employ the coordinated transmit beamforming to serve their respectively associated single-antenna communication users (CUs), and at the same time reuse the reflected information signals to perform joint target detection. In particular, we consider two target detection scenarios depending on the time synchronization among BSs. In Scenario \uppercase\expandafter{\romannumeral1}, these BSs are synchronized and can exploit the target-reflected signals over both the direct links (from each BS to target to itself) and the cross links (from each BS to target to other BSs) for joint detection. In Scenario \uppercase\expandafter{\romannumeral2}, these BSs are not synchronized and can only utilize target-reflected signals over the direct links for joint detection. For each scenario, we derive the detection probability under a specific false alarm probability at any given target location. Based on the derivation, we optimize the coordinated transmit beamforming at the BSs to maximize the minimum detection probability over a particular target area, while ensuring the minimum signal-to-interference-plus-noise ratio (SINR) constraints at the CUs, subject to the maximum transmit power constraints at the BSs. We use the semi-definite relaxation (SDR) technique to obtain highly-quality solutions to the formulated problems. Numerical results show that for each scenario, the proposed design achieves higher detection probability than the benchmark scheme based on communication design. It is also shown that the time synchronization among BSs is beneficial in enhancing the detection performance as more reflected signal paths are exploited.
Image Understands Point Cloud: Weakly Supervised 3D Semantic Segmentation via Association Learning
Sep 16, 2022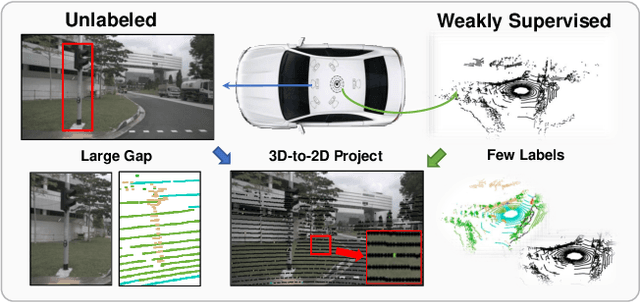
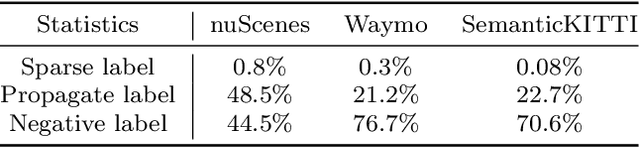

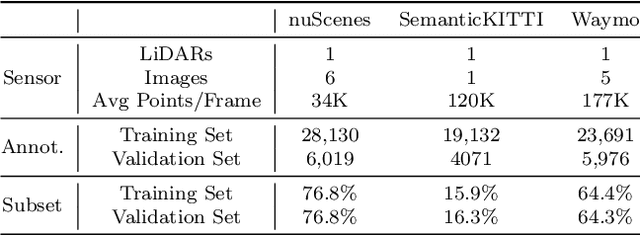
Weakly supervised point cloud semantic segmentation methods that require 1\% or fewer labels, hoping to realize almost the same performance as fully supervised approaches, which recently, have attracted extensive research attention. A typical solution in this framework is to use self-training or pseudo labeling to mine the supervision from the point cloud itself, but ignore the critical information from images. In fact, cameras widely exist in LiDAR scenarios and this complementary information seems to be greatly important for 3D applications. In this paper, we propose a novel cross-modality weakly supervised method for 3D segmentation, incorporating complementary information from unlabeled images. Basically, we design a dual-branch network equipped with an active labeling strategy, to maximize the power of tiny parts of labels and directly realize 2D-to-3D knowledge transfer. Afterwards, we establish a cross-modal self-training framework in an Expectation-Maximum (EM) perspective, which iterates between pseudo labels estimation and parameters updating. In the M-Step, we propose a cross-modal association learning to mine complementary supervision from images by reinforcing the cycle-consistency between 3D points and 2D superpixels. In the E-step, a pseudo label self-rectification mechanism is derived to filter noise labels thus providing more accurate labels for the networks to get fully trained. The extensive experimental results demonstrate that our method even outperforms the state-of-the-art fully supervised competitors with less than 1\% actively selected annotations.
Identity-Aware Hand Mesh Estimation and Personalization from RGB Images
Sep 22, 2022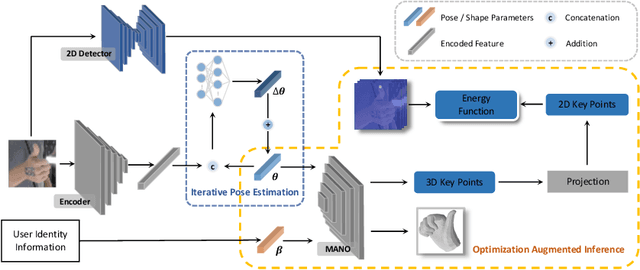
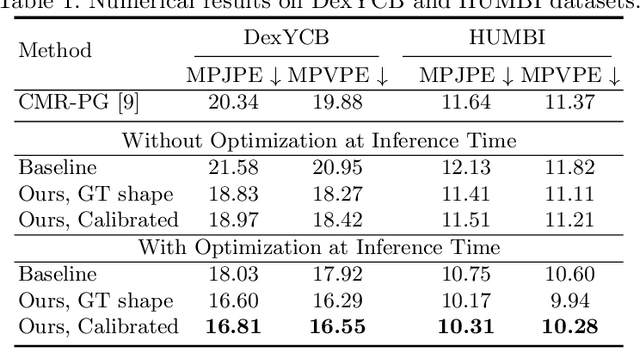
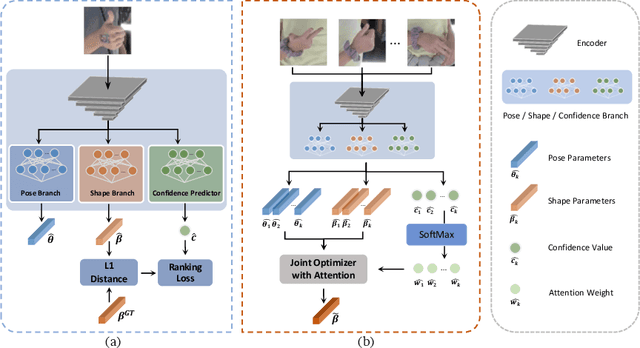
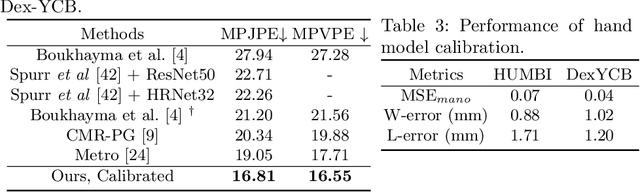
Reconstructing 3D hand meshes from monocular RGB images has attracted increasing amount of attention due to its enormous potential applications in the field of AR/VR. Most state-of-the-art methods attempt to tackle this task in an anonymous manner. Specifically, the identity of the subject is ignored even though it is practically available in real applications where the user is unchanged in a continuous recording session. In this paper, we propose an identity-aware hand mesh estimation model, which can incorporate the identity information represented by the intrinsic shape parameters of the subject. We demonstrate the importance of the identity information by comparing the proposed identity-aware model to a baseline which treats subject anonymously. Furthermore, to handle the use case where the test subject is unseen, we propose a novel personalization pipeline to calibrate the intrinsic shape parameters using only a few unlabeled RGB images of the subject. Experiments on two large scale public datasets validate the state-of-the-art performance of our proposed method.
GRAPHYP: A Scientific Knowledge Graph with Manifold Subnetworks of Communities. Detection of Scholarly Disputes in Adversarial Information Routes
May 03, 2022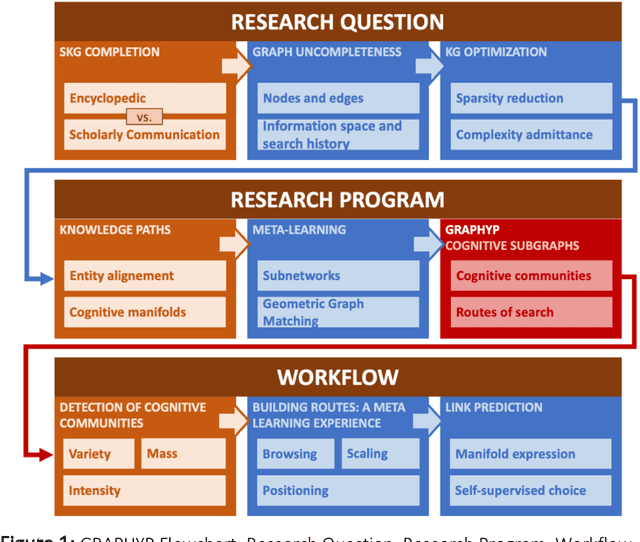

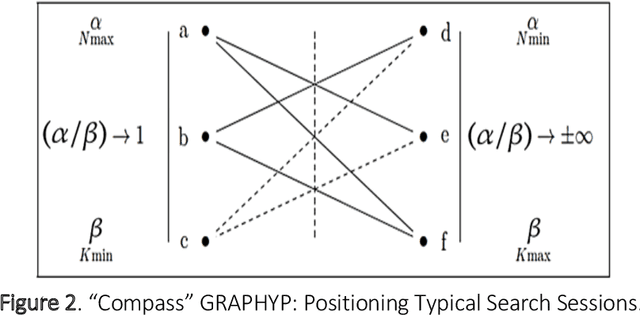
The cognitive manifold of published content is currently expanding in all areas of science. However, Scientific Knowledge Graphs (SKGs) only provide poor pictures of the adversarial directions and scientific controversies that feed the production of knowledge. In this Article, we tackle the understanding of the design of the information space of a cognitive representation of research activities, and of related bottlenecks that affect search interfaces, in the mapping of structured objects into graphs. We propose, with SKG GRAPHYP, a novel graph designed geometric architecture which optimizes both the detection of the knowledge manifold of "cognitive communities", and the representation of alternative paths to adversarial answers to a research question, for instance in the context of academic disputes. With a methodology for designing "Manifold Subnetworks of Cognitive Communities", GRAPHYP provides a classification of distinct search paths in a research field. Users are detected from the variety of their search practices and classified in "Cognitive communities" from the analysis of the search history of their logs of scientific documentation. The manifold of practices is expressed from metrics of differentiated uses by triplets of nodes shaped into symmetrical graph subnetworks, with the following three parameters: Mass, Intensity, and Variety.
Performance Optimization for Semantic Communications: An Attention-based Reinforcement Learning Approach
Aug 17, 2022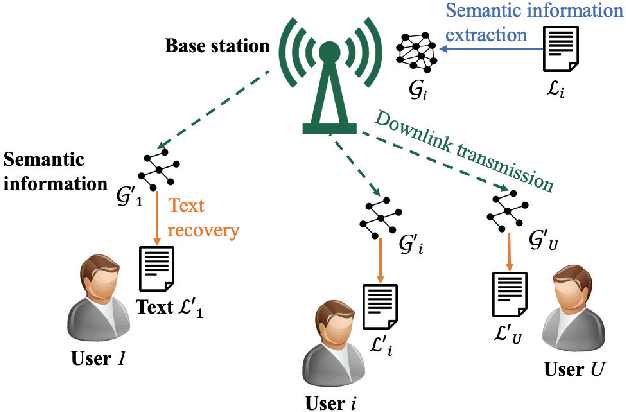
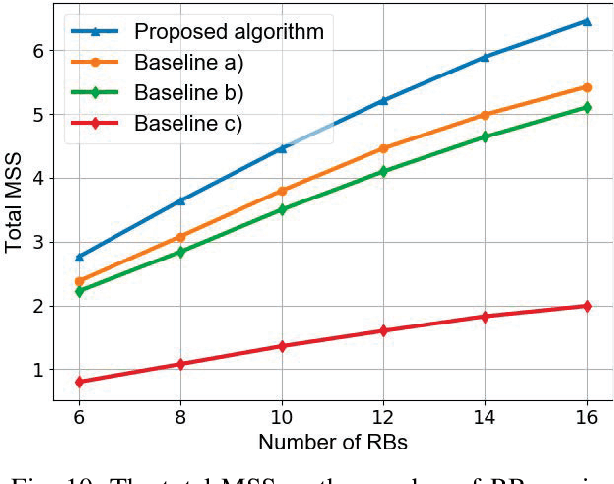
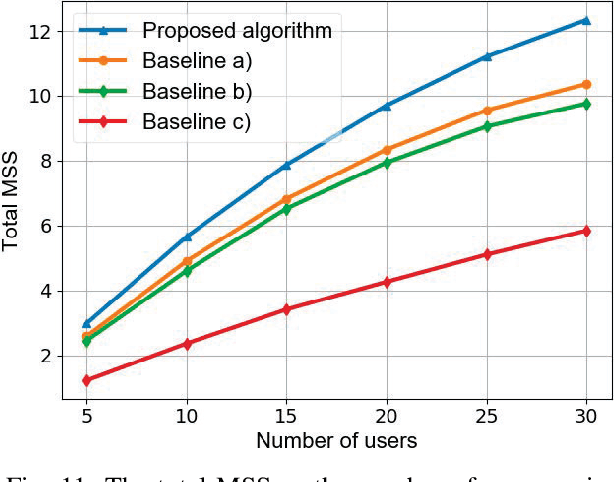
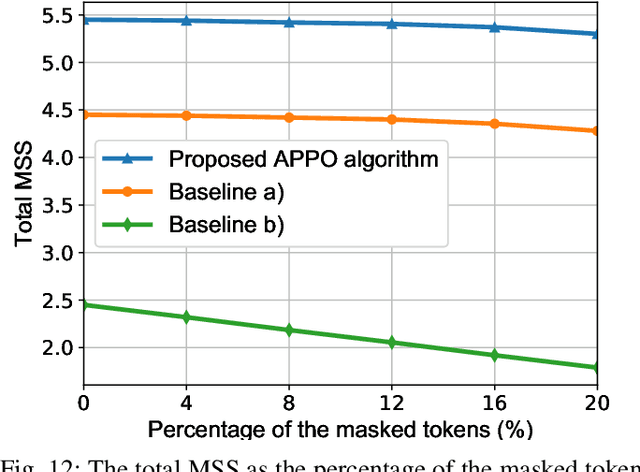
In this paper, a semantic communication framework is proposed for textual data transmission. In the studied model, a base station (BS) extracts the semantic information from textual data, and transmits it to each user. The semantic information is modeled by a knowledge graph (KG) that consists of a set of semantic triples. After receiving the semantic information, each user recovers the original text using a graph-to-text generation model. To measure the performance of the considered semantic communication framework, a metric of semantic similarity (MSS) that jointly captures the semantic accuracy and completeness of the recovered text is proposed. Due to wireless resource limitations, the BS may not be able to transmit the entire semantic information to each user and satisfy the transmission delay constraint. Hence, the BS must select an appropriate resource block for each user as well as determine and transmit part of the semantic information to the users. As such, we formulate an optimization problem whose goal is to maximize the total MSS by jointly optimizing the resource allocation policy and determining the partial semantic information to be transmitted. To solve this problem, a proximal-policy-optimization-based reinforcement learning (RL) algorithm integrated with an attention network is proposed. The proposed algorithm can evaluate the importance of each triple in the semantic information using an attention network and then, build a relationship between the importance distribution of the triples in the semantic information and the total MSS. Compared to traditional RL algorithms, the proposed algorithm can dynamically adjust its learning rate thus ensuring convergence to a locally optimal solution.
Dial2vec: Self-Guided Contrastive Learning of Unsupervised Dialogue Embeddings
Oct 27, 2022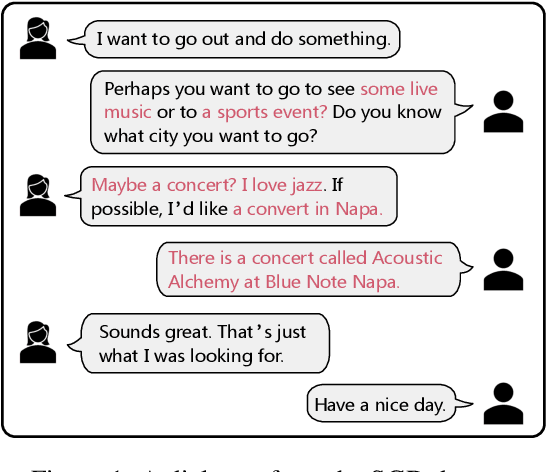
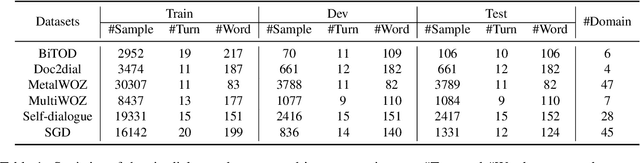
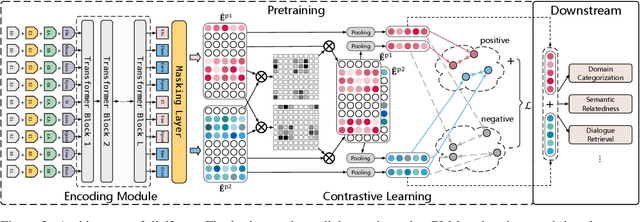
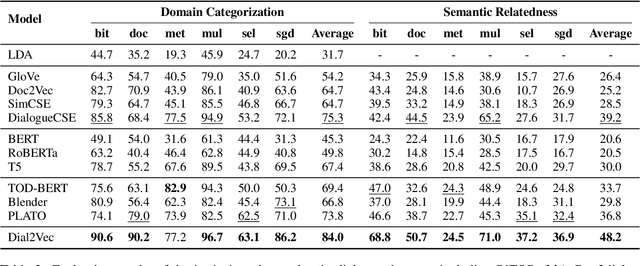
In this paper, we introduce the task of learning unsupervised dialogue embeddings. Trivial approaches such as combining pre-trained word or sentence embeddings and encoding through pre-trained language models (PLMs) have been shown to be feasible for this task. However, these approaches typically ignore the conversational interactions between interlocutors, resulting in poor performance. To address this issue, we proposed a self-guided contrastive learning approach named dial2vec. Dial2vec considers a dialogue as an information exchange process. It captures the conversational interaction patterns between interlocutors and leverages them to guide the learning of the embeddings corresponding to each interlocutor. The dialogue embedding is obtained by an aggregation of the embeddings from all interlocutors. To verify our approach, we establish a comprehensive benchmark consisting of six widely-used dialogue datasets. We consider three evaluation tasks: domain categorization, semantic relatedness, and dialogue retrieval. Dial2vec achieves on average 8.7, 9.0, and 13.8 points absolute improvements in terms of purity, Spearman's correlation, and mean average precision (MAP) over the strongest baseline on the three tasks respectively. Further analysis shows that dial2vec obtains informative and discriminative embeddings for both interlocutors under the guidance of the conversational interactions and achieves the best performance when aggregating them through the interlocutor-level pooling strategy. All codes and data are publicly available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/dial2vec.
Towards Better Text-Image Consistency in Text-to-Image Generation
Oct 27, 2022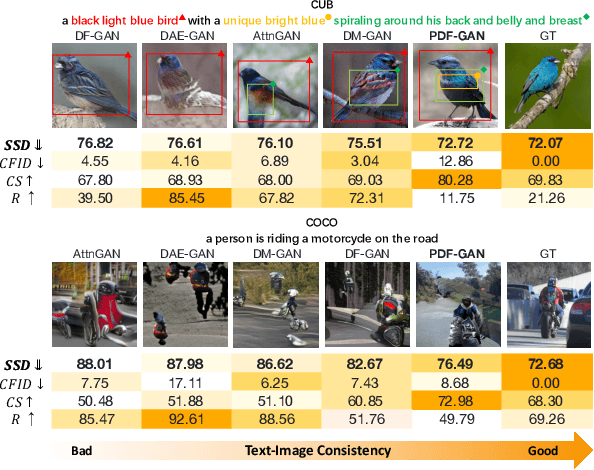
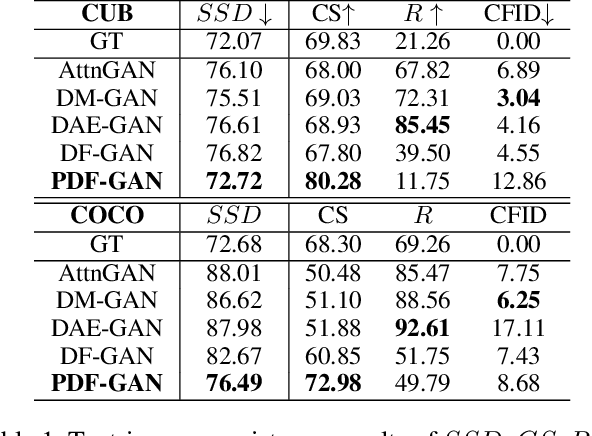
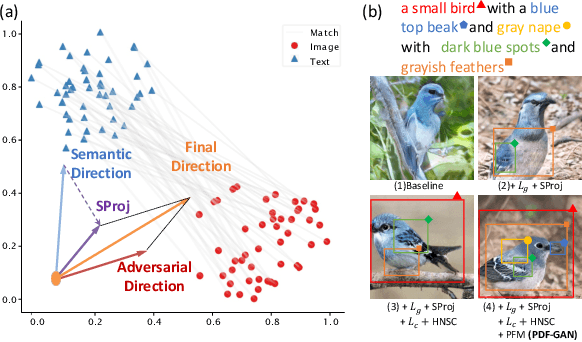
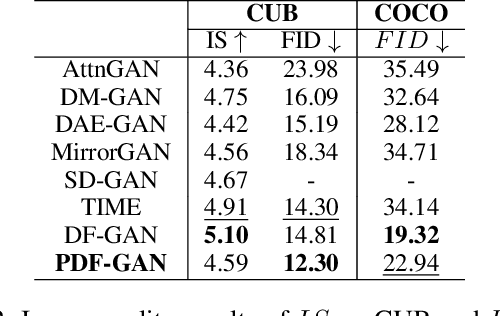
Generating consistent and high-quality images from given texts is essential for visual-language understanding. Although impressive results have been achieved in generating high-quality images, text-image consistency is still a major concern in existing GAN-based methods. Particularly, the most popular metric $R$-precision may not accurately reflect the text-image consistency, often resulting in very misleading semantics in the generated images. Albeit its significance, how to design a better text-image consistency metric surprisingly remains under-explored in the community. In this paper, we make a further step forward to develop a novel CLIP-based metric termed as Semantic Similarity Distance (SSD), which is both theoretically founded from a distributional viewpoint and empirically verified on benchmark datasets. Benefiting from the proposed metric, we further design the Parallel Deep Fusion Generative Adversarial Networks (PDF-GAN), which can fuse semantic information at different granularities and capture accurate semantics. Equipped with two novel plug-and-play components: Hard-Negative Sentence Constructor and Semantic Projection, the proposed PDF-GAN can mitigate inconsistent semantics and bridge the text-image semantic gap. A series of experiments show that, as opposed to current state-of-the-art methods, our PDF-GAN can lead to significantly better text-image consistency while maintaining decent image quality on the CUB and COCO datasets.
Few-shot Image Generation via Masked Discrimination
Oct 27, 2022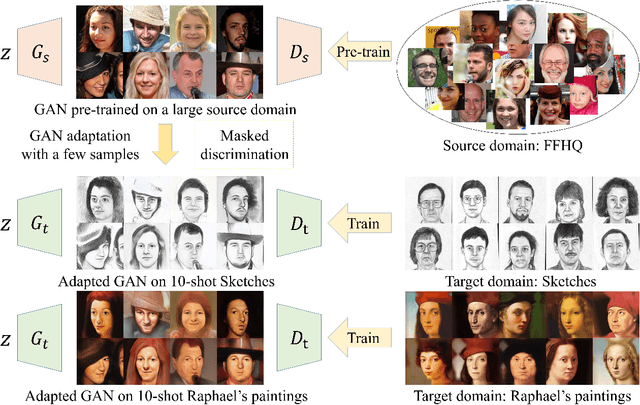
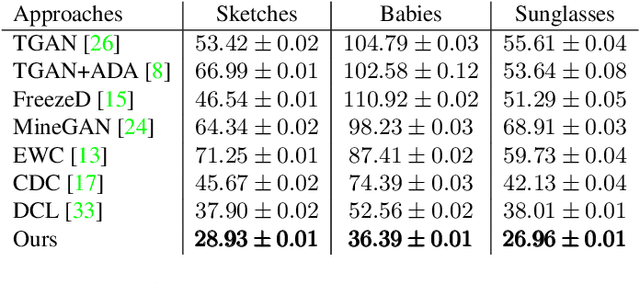
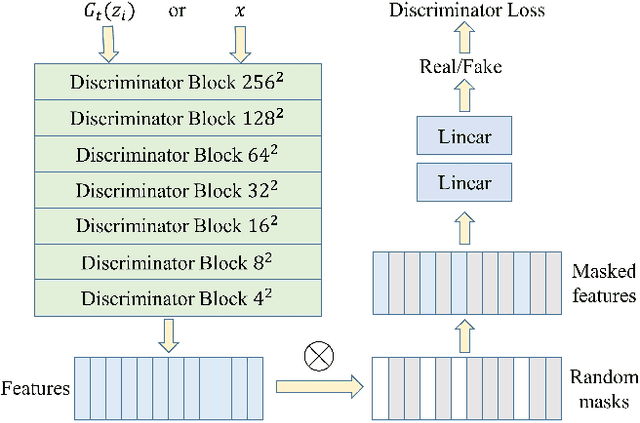

Few-shot image generation aims to generate images of high quality and great diversity with limited data. However, it is difficult for modern GANs to avoid overfitting when trained on only a few images. The discriminator can easily remember all the training samples and guide the generator to replicate them, leading to severe diversity degradation. Several methods have been proposed to relieve overfitting by adapting GANs pre-trained on large source domains to target domains with limited real samples. In this work, we present a novel approach to realize few-shot GAN adaptation via masked discrimination. Random masks are applied to features extracted by the discriminator from input images. We aim to encourage the discriminator to judge more diverse images which share partially common features with training samples as realistic images. Correspondingly, the generator is guided to generate more diverse images instead of replicating training samples. In addition, we employ cross-domain consistency loss for the discriminator to keep relative distances between samples in its feature space. The discriminator cross-domain consistency loss serves as another optimization target in addition to adversarial loss and guides adapted GANs to preserve more information learned from source domains for higher image quality. The effectiveness of our approach is demonstrated both qualitatively and quantitatively with higher quality and greater diversity on a series of few-shot image generation tasks than prior methods.
Finite time analysis of temporal difference learning with linear function approximation: Tail averaging and regularisation
Oct 12, 2022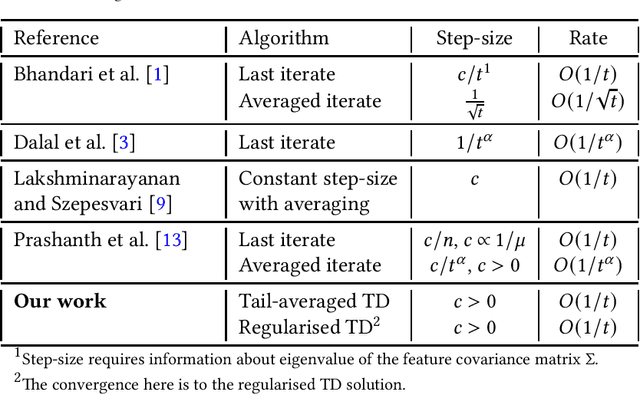
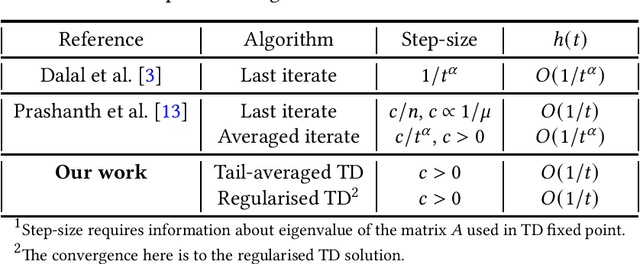
We study the finite-time behaviour of the popular temporal difference (TD) learning algorithm when combined with tail-averaging. We derive finite time bounds on the parameter error of the tail-averaged TD iterate under a step-size choice that does not require information about the eigenvalues of the matrix underlying the projected TD fixed point. Our analysis shows that tail-averaged TD converges at the optimal $O\left(1/t\right)$ rate, both in expectation and with high probability. In addition, our bounds exhibit a sharper rate of decay for the initial error (bias), which is an improvement over averaging all iterates. We also propose and analyse a variant of TD that incorporates regularisation. From analysis, we conclude that the regularised version of TD is useful for problems with ill-conditioned features.