 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Object Segmentation of Cluttered Airborne LiDAR Point Clouds
Oct 28, 2022
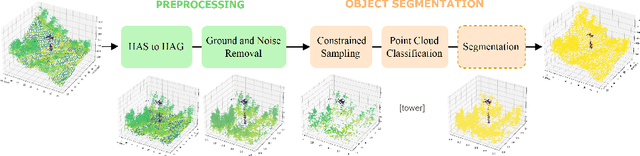
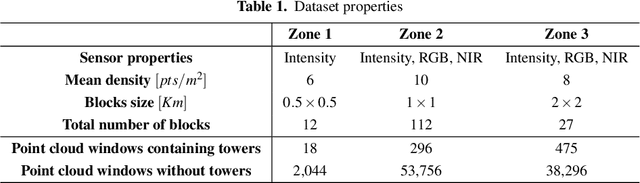

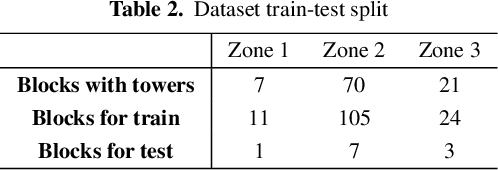
Airborne topographic LiDAR is an active remote sensing technology that emits near-infrared light to map objects on the Earth's surface. Derived products of LiDAR are suitable to service a wide range of applications because of their rich three-dimensional spatial information and their capacity to obtain multiple returns. However, processing point cloud data still requires a significant effort in manual editing. Certain human-made objects are difficult to detect because of their variety of shapes, irregularly-distributed point clouds, and low number of class samples. In this work, we propose an end-to-end deep learning framework to automatize the detection and segmentation of objects defined by an arbitrary number of LiDAR points surrounded by clutter. Our method is based on a light version of PointNet that achieves good performance on both object recognition and segmentation tasks. The results are tested against manually delineated power transmission towers and show promising accuracy.
* proceedings of the 24th International Conference of the Catalan Association for Artificial Intelligence (CCIA 2022)
Comparison of Stereo Matching Algorithms for the Development of Disparity Map
Oct 28, 2022
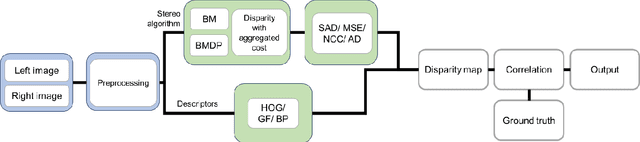
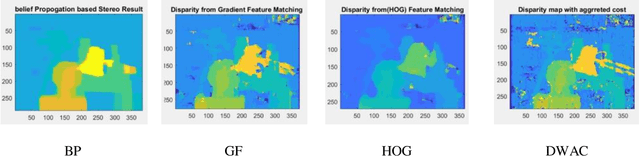
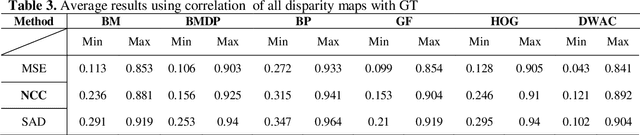
Stereo Matching is one of the classical problems in computer vision for the extraction of 3D information but still controversial for accuracy and processing costs. The use of matching techniques and cost functions is crucial in the development of the disparity map. This paper presents a comparative study of six different stereo matching algorithms including Block Matching (BM), Block Matching with Dynamic Programming (BMDP), Belief Propagation (BP), Gradient Feature Matching (GF), Histogram of Oriented Gradient (HOG), and the proposed method. Also three cost functions namely Mean Squared Error (MSE), Sum of Absolute Differences (SAD), Normalized Cross-Correlation (NCC) were used and compared. The stereo images used in this study were from the Middlebury Stereo Datasets provided with perfect and imperfect calibrations. Results show that the selection of matching function is quite important and also depends on the images properties. Results showed that the BP algorithm in most cases provided better results getting accuracies over 95%.
GeoGCN: Geometric Dual-domain Graph Convolution Network for Point Cloud Denoising
Oct 28, 2022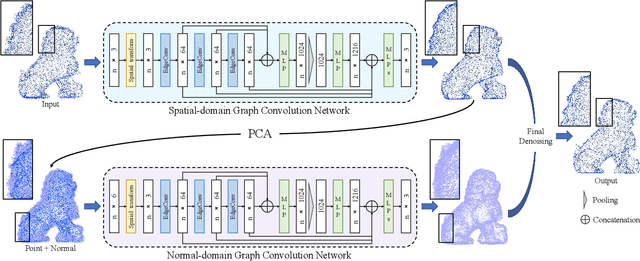
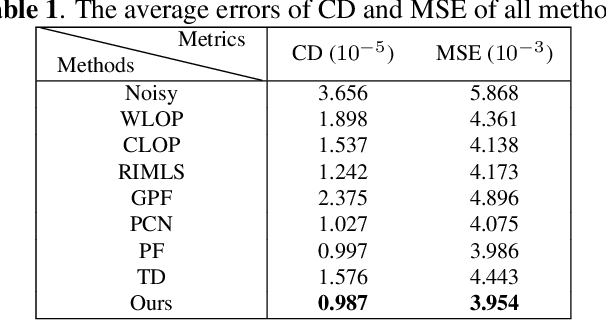


We propose GeoGCN, a novel geometric dual-domain graph convolution network for point cloud denoising (PCD). Beyond the traditional wisdom of PCD, to fully exploit the geometric information of point clouds, we define two kinds of surface normals, one is called Real Normal (RN), and the other is Virtual Normal (VN). RN preserves the local details of noisy point clouds while VN avoids the global shape shrinkage during denoising. GeoGCN is a new PCD paradigm that, 1) first regresses point positions by spatialbased GCN with the help of VNs, 2) then estimates initial RNs by performing Principal Component Analysis on the regressed points, and 3) finally regresses fine RNs by normalbased GCN. Unlike existing PCD methods, GeoGCN not only exploits two kinds of geometry expertise (i.e., RN and VN) but also benefits from training data. Experiments validate that GeoGCN outperforms SOTAs in terms of both noise-robustness and local-and-global feature preservation.
SEMPAI: a Self-Enhancing Multi-Photon Artificial Intelligence for prior-informed assessment of muscle function and pathology
Oct 28, 2022Deep learning (DL) shows notable success in biomedical studies. However, most DL algorithms work as a black box, exclude biomedical experts, and need extensive data. We introduce the Self-Enhancing Multi-Photon Artificial Intelligence (SEMPAI), that integrates hypothesis-driven priors in a data-driven DL approach for research on multiphoton microscopy (MPM) of muscle fibers. SEMPAI utilizes meta-learning to optimize prior integration, data representation, and neural network architecture simultaneously. This allows hypothesis testing and provides interpretable feedback about the origin of biological information in MPM images. SEMPAI performs joint learning of several tasks to enable prediction for small datasets. The method is applied on an extensive multi-study dataset resulting in the largest joint analysis of pathologies and function for single muscle fibers. SEMPAI outperforms state-of-the-art biomarkers in six of seven predictive tasks, including those with scarce data. SEMPAI's DL models with integrated priors are superior to those without priors and to prior-only machine learning approaches.
Towards zero-shot Text-based voice editing using acoustic context conditioning, utterance embeddings, and reference encoders
Oct 28, 2022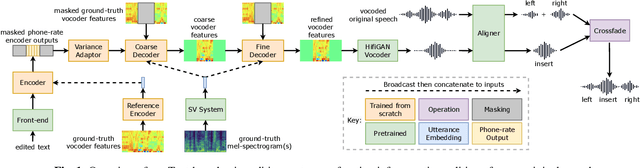
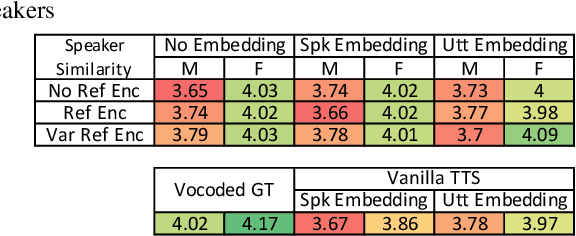
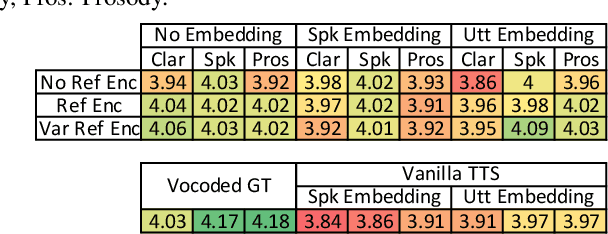
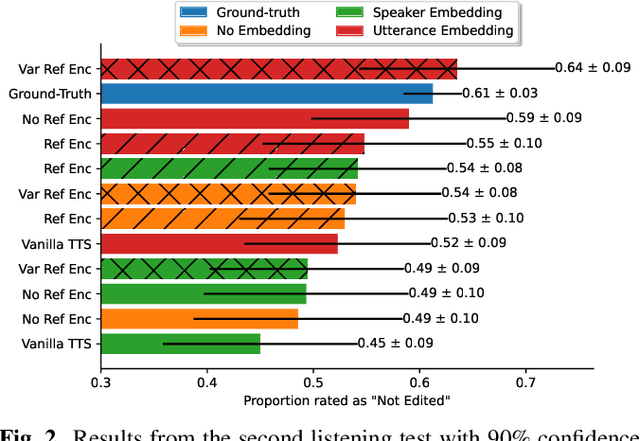
Text-based voice editing (TBVE) uses synthetic output from text-to-speech (TTS) systems to replace words in an original recording. Recent work has used neural models to produce edited speech that is similar to the original speech in terms of clarity, speaker identity, and prosody. However, one limitation of prior work is the usage of finetuning to optimise performance: this requires further model training on data from the target speaker, which is a costly process that may incorporate potentially sensitive data into server-side models. In contrast, this work focuses on the zero-shot approach which avoids finetuning altogether, and instead uses pretrained speaker verification embeddings together with a jointly trained reference encoder to encode utterance-level information that helps capture aspects such as speaker identity and prosody. Subjective listening tests find that both utterance embeddings and a reference encoder improve the continuity of speaker identity and prosody between the edited synthetic speech and unedited original recording in the zero-shot setting.
Toward Unifying Text Segmentation and Long Document Summarization
Oct 28, 2022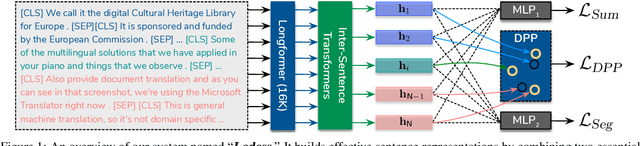
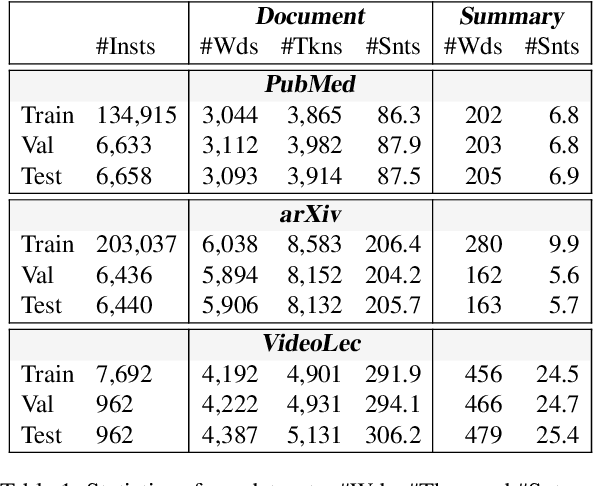
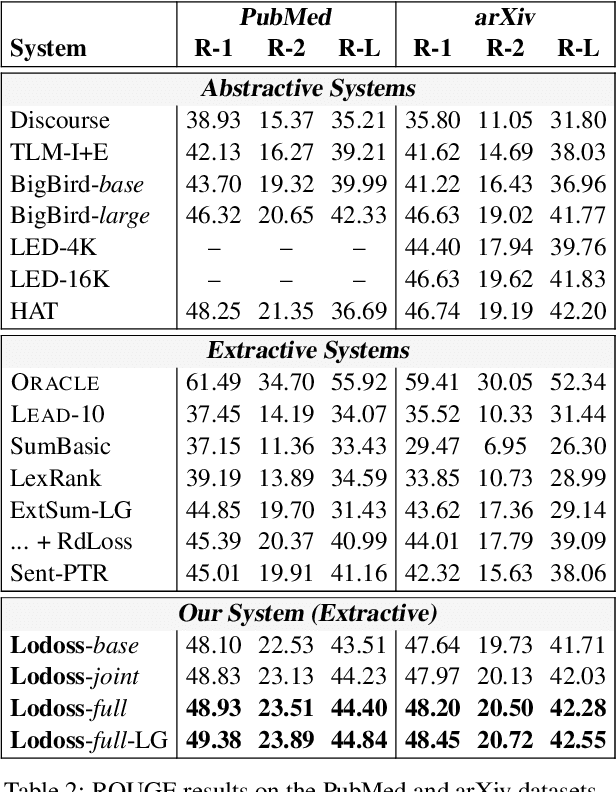
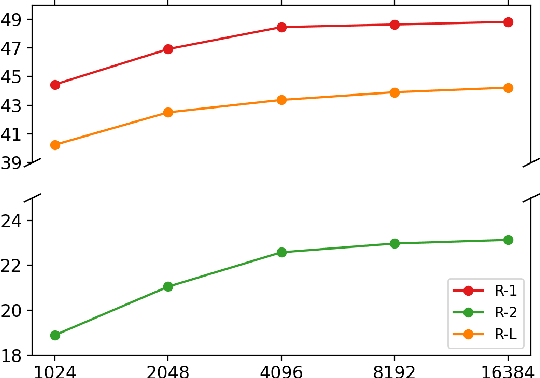
Text segmentation is important for signaling a document's structure. Without segmenting a long document into topically coherent sections, it is difficult for readers to comprehend the text, let alone find important information. The problem is only exacerbated by a lack of segmentation in transcripts of audio/video recordings. In this paper, we explore the role that section segmentation plays in extractive summarization of written and spoken documents. Our approach learns robust sentence representations by performing summarization and segmentation simultaneously, which is further enhanced by an optimization-based regularizer to promote selection of diverse summary sentences. We conduct experiments on multiple datasets ranging from scientific articles to spoken transcripts to evaluate the model's performance. Our findings suggest that the model can not only achieve state-of-the-art performance on publicly available benchmarks, but demonstrate better cross-genre transferability when equipped with text segmentation. We perform a series of analyses to quantify the impact of section segmentation on summarizing written and spoken documents of substantial length and complexity.
Just-DREAM-about-it: Figurative Language Understanding with DREAM-FLUTE
Oct 28, 2022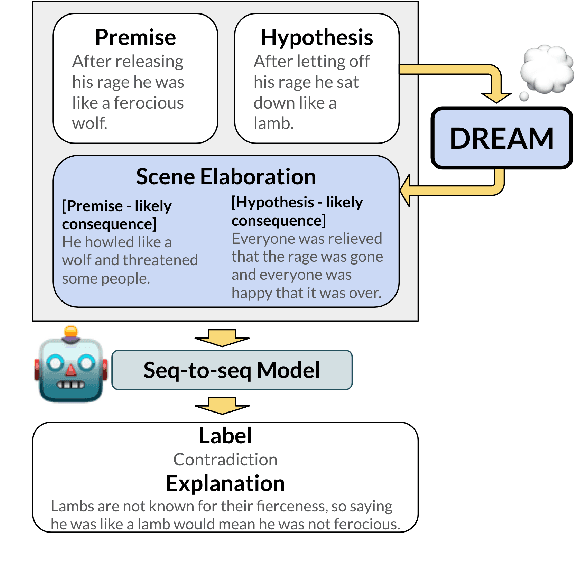
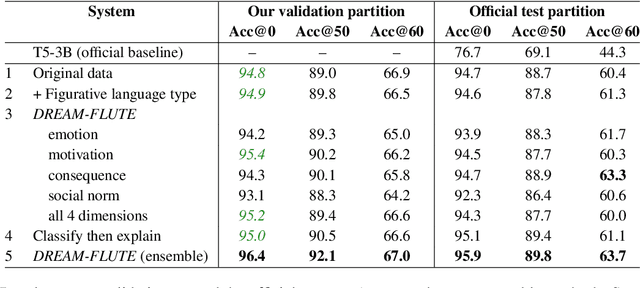

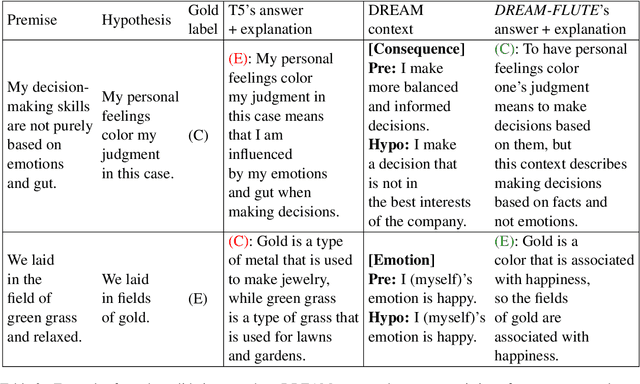
Figurative language (e.g., "he flew like the wind") is challenging to understand, as it is hard to tell what implicit information is being conveyed from the surface form alone. We hypothesize that to perform this task well, the reader needs to mentally elaborate the scene being described to identify a sensible meaning of the language. We present DREAM-FLUTE, a figurative language understanding system that does this, first forming a "mental model" of situations described in a premise and hypothesis before making an entailment/contradiction decision and generating an explanation. DREAM-FLUTE uses an existing scene elaboration model, DREAM, for constructing its "mental model." In the FigLang2022 Shared Task evaluation, DREAM-FLUTE achieved (joint) first place (Acc@60=63.3%), and can perform even better with ensemble techniques, demonstrating the effectiveness of this approach. More generally, this work suggests that adding a reflective component to pretrained language models can improve their performance beyond standard fine-tuning (3.3% improvement in Acc@60).
Adversarial Cross-View Disentangled Graph Contrastive Learning
Sep 16, 2022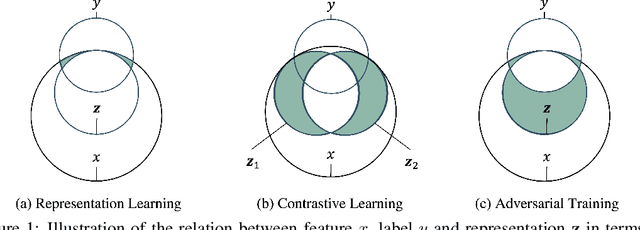
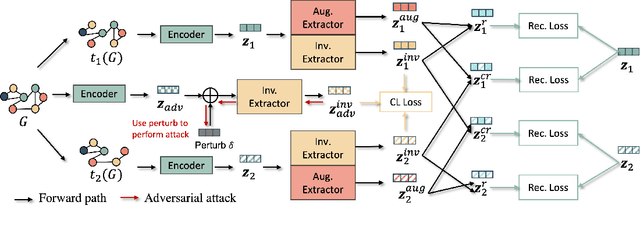

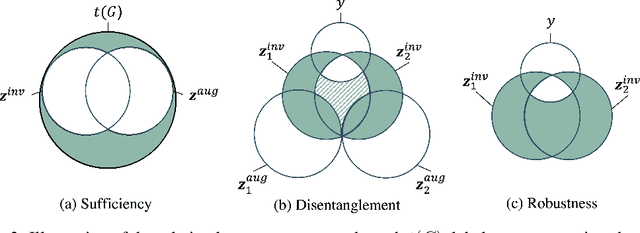
Graph contrastive learning (GCL) is prevalent to tackle the supervision shortage issue in graph learning tasks. Many recent GCL methods have been proposed with various manually designed augmentation techniques, aiming to implement challenging augmentations on the original graph to yield robust representation. Although many of them achieve remarkable performances, existing GCL methods still struggle to improve model robustness without risking losing task-relevant information because they ignore the fact the augmentation-induced latent factors could be highly entangled with the original graph, thus it is more difficult to discriminate the task-relevant information from irrelevant information. Consequently, the learned representation is either brittle or unilluminating. In light of this, we introduce the Adversarial Cross-View Disentangled Graph Contrastive Learning (ACDGCL), which follows the information bottleneck principle to learn minimal yet sufficient representations from graph data. To be specific, our proposed model elicits the augmentation-invariant and augmentation-dependent factors separately. Except for the conventional contrastive loss which guarantees the consistency and sufficiency of the representations across different contrastive views, we introduce a cross-view reconstruction mechanism to pursue the representation disentanglement. Besides, an adversarial view is added as the third view of contrastive loss to enhance model robustness. We empirically demonstrate that our proposed model outperforms the state-of-the-arts on graph classification task over multiple benchmark datasets.
A Complete Set of Connectivity-aware Local Topology Manipulation Operations for Robot Swarms
Oct 04, 2022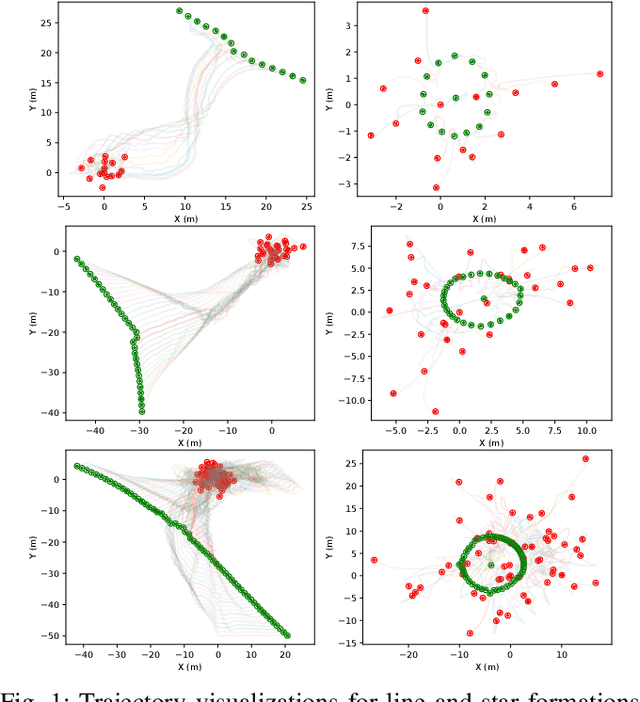
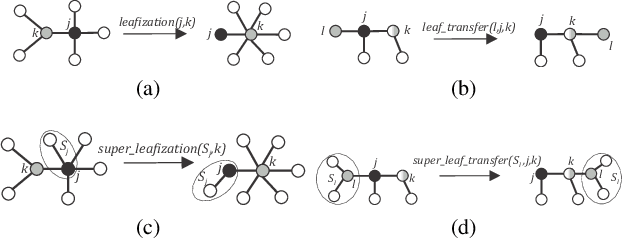
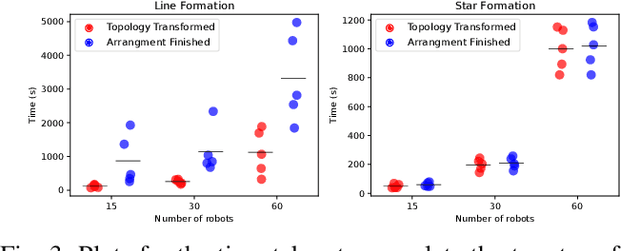
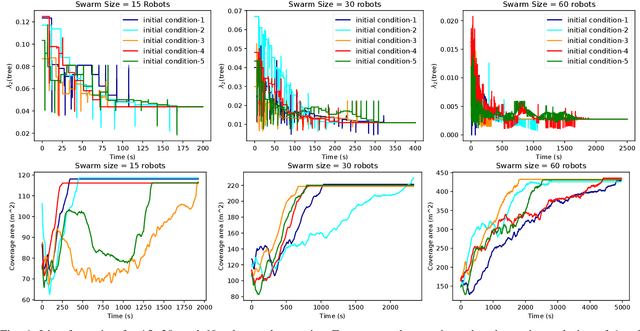
The topology of a robotic swarm affects the convergence speed of consensus and the mobility of the robots. In this paper, we prove the existence of a complete set of local topology manipulation operations that allow the transformation of a swarm topology. The set is complete in the sense that any other possible set of manipulation operations can be performed by a sequence of operations from our set. The operations are local as they depend only on the first and second hop neighbors' information to transform any initial spanning tree of the network's graph to any other connected tree with the same number of nodes. The flexibility provided by our method is similar to global methods that require full knowledge of the swarm network. We prove the existence of a sequence of transformations for any tree-to-tree transformation, and derive sequences of operations to form a line or star from any initial spanning tree. Our work provides a theoretical and practical framework for topological control of a swarm, establishing global properties using only local information.
ASAP: Accurate semantic segmentation for real time performance
Oct 04, 2022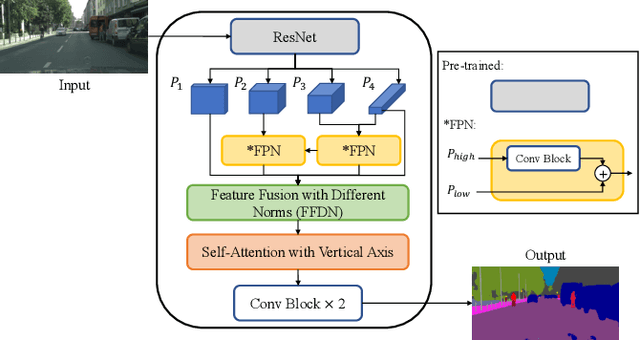
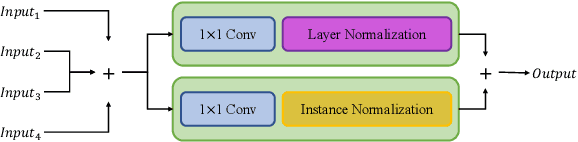
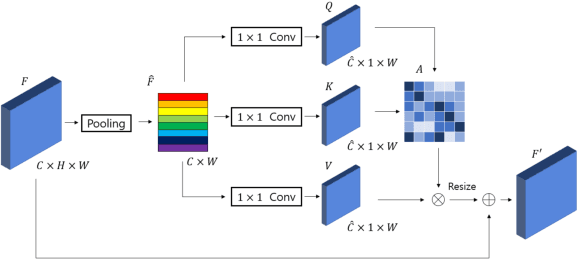

Feature fusion modules from encoder and self-attention module have been adopted in semantic segmentation. However, the computation of these modules is costly and has operational limitations in real-time environments. In addition, segmentation performance is limited in autonomous driving environments with a lot of contextual information perpendicular to the road surface, such as people, buildings, and general objects. In this paper, we propose an efficient feature fusion method, Feature Fusion with Different Norms (FFDN) that utilizes rich global context of multi-level scale and vertical pooling module before self-attention that preserves most contextual information while reducing the complexity of global context encoding in the vertical direction. By doing this, we could handle the properties of representation in global space and reduce additional computational cost. In addition, we analyze low performance in challenging cases including small and vertically featured objects. We achieve the mean Interaction of-union(mIoU) of 73.1 and the Frame Per Second(FPS) of 191, which are comparable results with state-of-the-arts on Cityscapes test datasets.