 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePachinko: Patching Interpretable QA Models through Natural Language Feedback
Nov 16, 2023



Eliciting feedback from end users of NLP models can be beneficial for improving models. However, how should we present model responses to users so they are most amenable to be corrected from user feedback? Further, what properties do users value to understand and trust responses? We answer these questions by analyzing the effect of rationales generated by QA models to support their answers. We specifically consider decomposed question-answering models that first extract an intermediate rationale based on a context and a question and then use solely this rationale to answer the question. A rationale outlines the approach followed by the model to answer the question. Our work considers various formats of these rationales that vary according to well-defined properties of interest. We sample these rationales from large language models using few-shot prompting for two reading comprehension datasets, and then perform two user studies. In the first one, we present users with incorrect answers and corresponding rationales of various formats and ask them to provide natural language feedback to revise the rationale. We then measure the effectiveness of this feedback in patching these rationales through in-context learning. The second study evaluates how well different rationale formats enable users to understand and trust model answers, when they are correct. We find that rationale formats significantly affect how easy it is (1) for users to give feedback for rationales, and (2) for models to subsequently execute this feedback. In addition to influencing critiquablity, certain formats significantly enhance user reported understanding and trust of model outputs.
ExpertQA: Expert-Curated Questions and Attributed Answers
Sep 14, 2023



As language models are adapted by a more sophisticated and diverse set of users, the importance of guaranteeing that they provide factually correct information supported by verifiable sources is critical across fields of study & professions. This is especially the case for high-stakes fields, such as medicine and law, where the risk of propagating false information is high and can lead to undesirable societal consequences. Previous work studying factuality and attribution has not focused on analyzing these characteristics of language model outputs in domain-specific scenarios. In this work, we present an evaluation study analyzing various axes of factuality and attribution provided in responses from a few systems, by bringing domain experts in the loop. Specifically, we first collect expert-curated questions from 484 participants across 32 fields of study, and then ask the same experts to evaluate generated responses to their own questions. We also ask experts to revise answers produced by language models, which leads to ExpertQA, a high-quality long-form QA dataset with 2177 questions spanning 32 fields, along with verified answers and attributions for claims in the answers.
ASAP: Accurate semantic segmentation for real time performance
Oct 04, 2022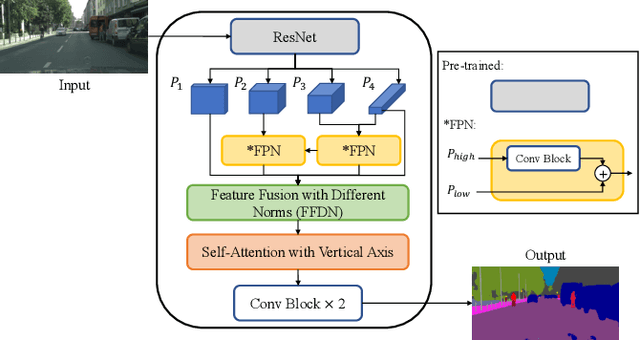
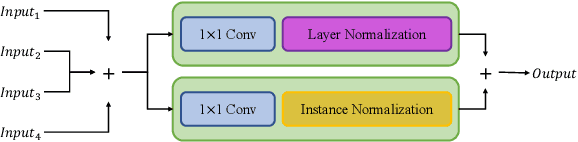
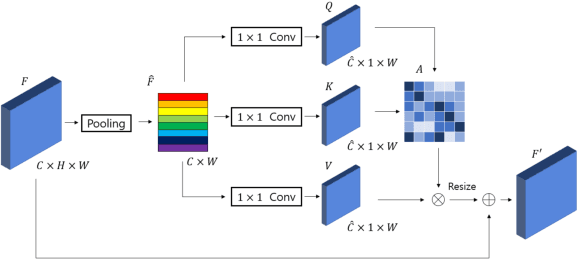

Feature fusion modules from encoder and self-attention module have been adopted in semantic segmentation. However, the computation of these modules is costly and has operational limitations in real-time environments. In addition, segmentation performance is limited in autonomous driving environments with a lot of contextual information perpendicular to the road surface, such as people, buildings, and general objects. In this paper, we propose an efficient feature fusion method, Feature Fusion with Different Norms (FFDN) that utilizes rich global context of multi-level scale and vertical pooling module before self-attention that preserves most contextual information while reducing the complexity of global context encoding in the vertical direction. By doing this, we could handle the properties of representation in global space and reduce additional computational cost. In addition, we analyze low performance in challenging cases including small and vertically featured objects. We achieve the mean Interaction of-union(mIoU) of 73.1 and the Frame Per Second(FPS) of 191, which are comparable results with state-of-the-arts on Cityscapes test datasets.