 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrick-DICL: Dynamic In-Context Learning for Automated Brick Schema Classification
Jun 16, 2026Building Management Systems (BMS) are essential for optimizing energy efficiency and operational performance in modern buildings. However, the lack of standardization across BMS points from different manufacturers creates significant barriers to integration and data utilization. While the Brick schema offers a standardized ontology for building systems, mapping BMS points to appropriate Brick classes presents three critical challenges: (i) the extensive number of Brick classes (936 in the latest version), (ii) limited domain-specific knowledge in large language models (LLMs), and (iii) substantial manual effort required for verification. To address these challenges, we propose Brick-DICL, a two-stage dynamic in-context learning framework for automated Brick schema classification. Brick-DICL consists of two primary components: metadata-RAG, which retrieves relevant examples to enhance LLMs' domain knowledge, and class-RAG, which narrows down potential Brick classes to address the large classification space. Additionally, we implement a multi-LLM filtering mechanism that compares predictions across multiple models, flagging low-confidence classifications for human review. As a result: (i) General: Brick-DICL is applicable to any building management system regardless of manufacturer or metadata format; (ii) Novel and Powerful: as the first dynamic in-context learning approach for Brick schema classification, Brick-DICL achieves significant classification accuracy improvements on building datasets, outperforming existing methods; (iii) Efficient: our multi-LLM filtering strategy reduces manual verification effort, enabling rapid digital building onboarding. Extensive experiments demonstrate Brick-DICL's effectiveness across diverse building datasets, accelerating the path toward standardized, interoperable building management systems.
CollabEval: Enhancing LLM-as-a-Judge via Multi-Agent Collaboration
Mar 01, 2026Large Language Models (LLMs) have revolutionized AI-generated content evaluation, with the LLM-as-a-Judge paradigm becoming increasingly popular. However, current single-LLM evaluation approaches face significant challenges, including inconsistent judgments and inherent biases from pre-training data. To address these limitations, we propose CollabEval, a novel multi-agent evaluation framework that implements a three-phase Collaborative Evaluation process: initial evaluation, multi-round discussion, and final judgment. Unlike existing approaches that rely on competitive debate or single-model evaluation, CollabEval emphasizes collaboration among multiple agents with strategic consensus checking for efficiency. Our extensive experiments demonstrate that CollabEval consistently outperforms single-LLM approaches across multiple dimensions while maintaining robust performance even when individual models struggle. The framework provides comprehensive support for various evaluation criteria while ensuring efficiency through its collaborative design.
BHyGNN+: Unsupervised Representation Learning for Heterophilic Hypergraphs
Feb 16, 2026Hypergraph Neural Networks (HyGNNs) have demonstrated remarkable success in modeling higher-order relationships among entities. However, their performance often degrades on heterophilic hypergraphs, where nodes connected by the same hyperedge tend to have dissimilar semantic representations or belong to different classes. While several HyGNNs, including our prior work BHyGNN, have been proposed to address heterophily, their reliance on labeled data significantly limits their applicability in real-world scenarios where annotations are scarce or costly. To overcome this limitation, we introduce BHyGNN+, a self-supervised learning framework that extends BHyGNN for representation learning on heterophilic hypergraphs without requiring ground-truth labels. The core idea of BHyGNN+ is hypergraph duality, a structural transformation where the roles of nodes and hyperedges are interchanged. By contrasting augmented views of a hypergraph against its dual using cosine similarity, our framework captures essential structural patterns in a fully unsupervised manner. Notably, this duality-based formulation eliminates the need for negative samples, a common requirement in existing hypergraph contrastive learning methods that is often difficult to satisfy in practice. Extensive experiments on eleven benchmark datasets demonstrate that BHyGNN+ consistently outperforms state-of-the-art supervised and self-supervised baselines on both heterophilic and homophilic hypergraphs. Our results validate the effectiveness of leveraging hypergraph duality for self-supervised learning and establish a new paradigm for representation learning on challenging, unlabeled hypergraphs.
OPBench: A Graph Benchmark to Combat the Opioid Crisis
Feb 16, 2026The opioid epidemic continues to ravage communities worldwide, straining healthcare systems, disrupting families, and demanding urgent computational solutions. To combat this lethal opioid crisis, graph learning methods have emerged as a promising paradigm for modeling complex drug-related phenomena. However, a significant gap remains: there is no comprehensive benchmark for systematically evaluating these methods across real-world opioid crisis scenarios. To bridge this gap, we introduce OPBench, the first comprehensive opioid benchmark comprising five datasets across three critical application domains: opioid overdose detection from healthcare claims, illicit drug trafficking detection from digital platforms, and drug misuse prediction from dietary patterns. Specifically, OPBench incorporates diverse graph structures, including heterogeneous graphs and hypergraphs, to preserve the rich and complex relational information among drug-related data. To address data scarcity, we collaborate with domain experts and authoritative institutions to curate and annotate datasets while adhering to privacy and ethical guidelines. Furthermore, we establish a unified evaluation framework with standardized protocols, predefined data splits, and reproducible baselines to facilitate fair and systematic comparison among graph learning methods. Through extensive experiments, we analyze the strengths and limitations of existing graph learning methods, thereby providing actionable insights for future research in combating the opioid crisis. Our source code and datasets are available at https://github.com/Tianyi-Billy-Ma/OPBench.
Verification-Guided Context Optimization for Tool Calling via Hierarchical LLMs-as-Editors
Dec 15, 2025



Tool calling enables large language models (LLMs) to interact with external environments through tool invocation, providing a practical way to overcome the limitations of pretraining. However, the effectiveness of tool use depends heavily on the quality of the associated documentation and knowledge base context. These materials are usually written for human users and are often misaligned with how LLMs interpret information. This problem is even more pronounced in industrial settings, where hundreds of tools with overlapping functionality create challenges in scalability, variability, and ambiguity. We propose Verification-Guided Context Optimization (VGCO), a framework that uses LLMs as editors to automatically refine tool-related documentation and knowledge base context. VGCO works in two stages. First, Evaluation collects real-world failure cases and identifies mismatches between tools and their context. Second, Optimization performs hierarchical editing through offline learning with structure-aware, in-context optimization. The novelty of our LLM editors has three main aspects. First, they use a hierarchical structure that naturally integrates into the tool-calling workflow. Second, they are state-aware, action-specific, and verification-guided, which constrains the search space and enables efficient, targeted improvements. Third, they enable cost-efficient sub-task specialization, either by prompt engineering large editor models or by post-training smaller editor models. Unlike prior work that emphasizes multi-turn reasoning, VGCO focuses on the single-turn, large-scale tool-calling problem and achieves significant improvements in accuracy, robustness, and generalization across LLMs.
AutoData: A Multi-Agent System for Open Web Data Collection
May 21, 2025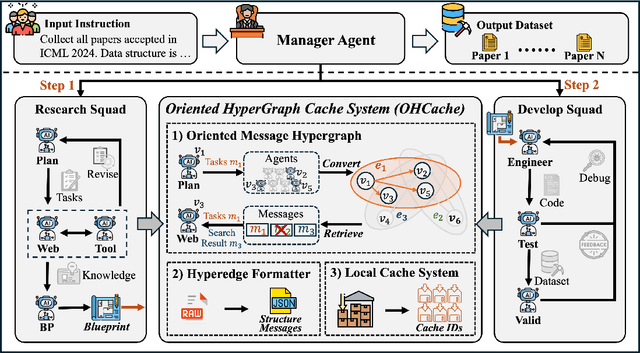
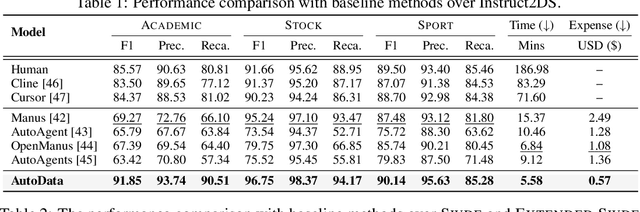
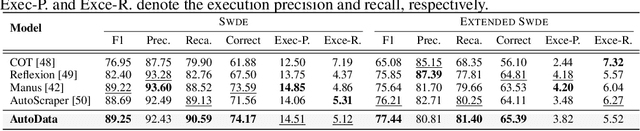

The exponential growth of data-driven systems and AI technologies has intensified the demand for high-quality web-sourced datasets. While existing datasets have proven valuable, conventional web data collection approaches face significant limitations in terms of human effort and scalability. Current data-collecting solutions fall into two categories: wrapper-based methods that struggle with adaptability and reproducibility, and large language model (LLM)-based approaches that incur substantial computational and financial costs. To address these challenges, we propose AutoData, a novel multi-agent system for Automated web Data collection, that requires minimal human intervention, i.e., only necessitating a natural language instruction specifying the desired dataset. In addition, AutoData is designed with a robust multi-agent architecture, featuring a novel oriented message hypergraph coordinated by a central task manager, to efficiently organize agents across research and development squads. Besides, we introduce a novel hypergraph cache system to advance the multi-agent collaboration process that enables efficient automated data collection and mitigates the token cost issues prevalent in existing LLM-based systems. Moreover, we introduce Instruct2DS, a new benchmark dataset supporting live data collection from web sources across three domains: academic, finance, and sports. Comprehensive evaluations over Instruct2DS and three existing benchmark datasets demonstrate AutoData's superior performance compared to baseline methods. Case studies on challenging tasks such as picture book collection and paper extraction from surveys further validate its applicability. Our source code and dataset are available at https://github.com/GraphResearcher/AutoData.
Adversarial Cross-View Disentangled Graph Contrastive Learning
Sep 16, 2022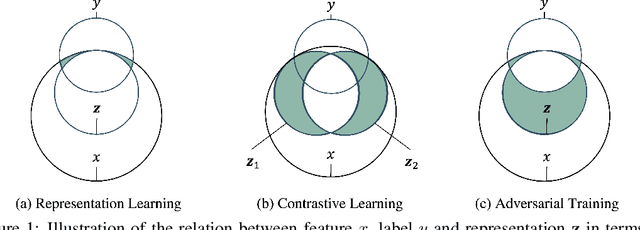
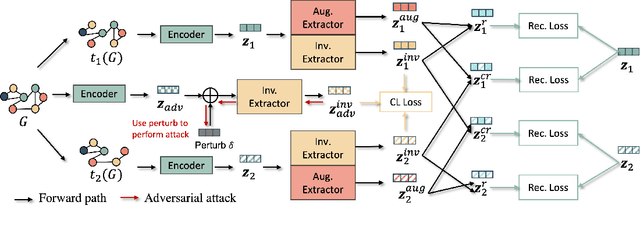

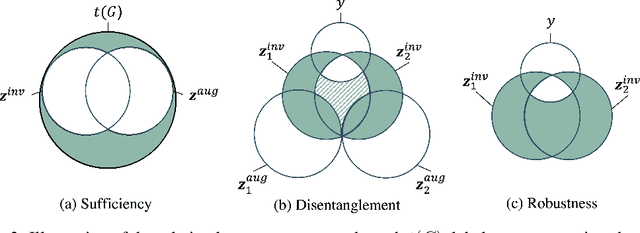
Graph contrastive learning (GCL) is prevalent to tackle the supervision shortage issue in graph learning tasks. Many recent GCL methods have been proposed with various manually designed augmentation techniques, aiming to implement challenging augmentations on the original graph to yield robust representation. Although many of them achieve remarkable performances, existing GCL methods still struggle to improve model robustness without risking losing task-relevant information because they ignore the fact the augmentation-induced latent factors could be highly entangled with the original graph, thus it is more difficult to discriminate the task-relevant information from irrelevant information. Consequently, the learned representation is either brittle or unilluminating. In light of this, we introduce the Adversarial Cross-View Disentangled Graph Contrastive Learning (ACDGCL), which follows the information bottleneck principle to learn minimal yet sufficient representations from graph data. To be specific, our proposed model elicits the augmentation-invariant and augmentation-dependent factors separately. Except for the conventional contrastive loss which guarantees the consistency and sufficiency of the representations across different contrastive views, we introduce a cross-view reconstruction mechanism to pursue the representation disentanglement. Besides, an adversarial view is added as the third view of contrastive loss to enhance model robustness. We empirically demonstrate that our proposed model outperforms the state-of-the-arts on graph classification task over multiple benchmark datasets.