 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust Online Video Instance Segmentation with Track Queries
Nov 16, 2022
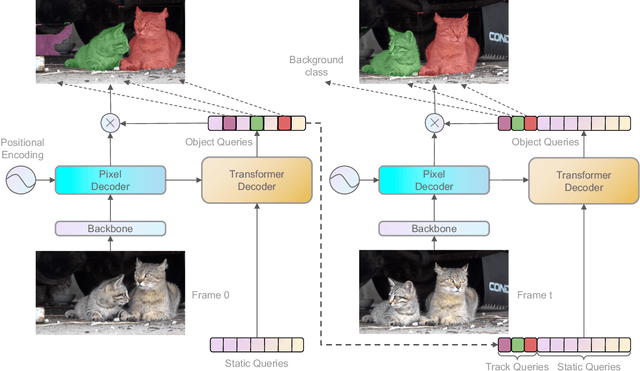
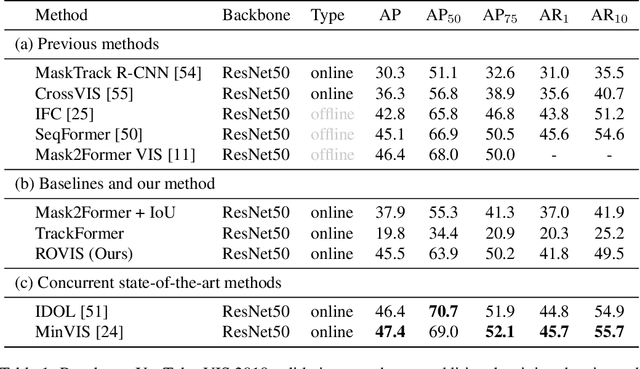

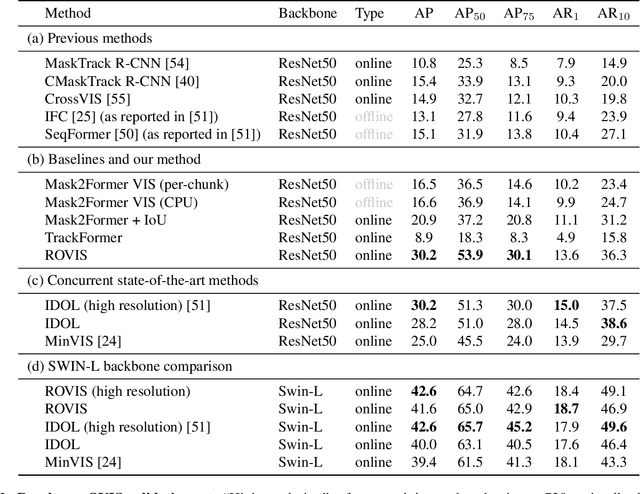
Recently, transformer-based methods have achieved impressive results on Video Instance Segmentation (VIS). However, most of these top-performing methods run in an offline manner by processing the entire video clip at once to predict instance mask volumes. This makes them incapable of handling the long videos that appear in challenging new video instance segmentation datasets like UVO and OVIS. We propose a fully online transformer-based video instance segmentation model that performs comparably to top offline methods on the YouTube-VIS 2019 benchmark and considerably outperforms them on UVO and OVIS. This method, called Robust Online Video Segmentation (ROVIS), augments the Mask2Former image instance segmentation model with track queries, a lightweight mechanism for carrying track information from frame to frame, originally introduced by the TrackFormer method for multi-object tracking. We show that, when combined with a strong enough image segmentation architecture, track queries can exhibit impressive accuracy while not being constrained to short videos.
Multilingual Speech Emotion Recognition With Multi-Gating Mechanism and Neural Architecture Search
Nov 16, 2022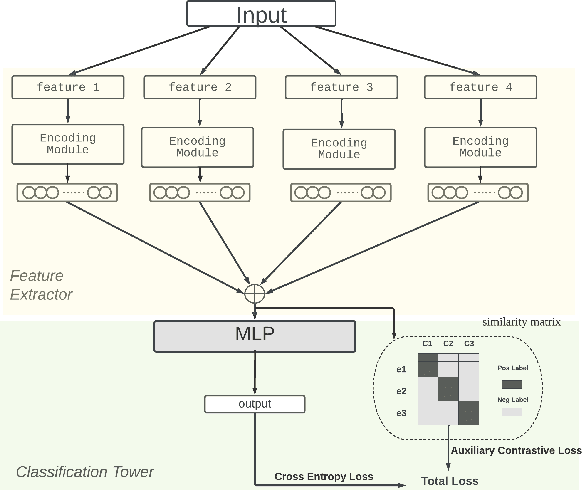

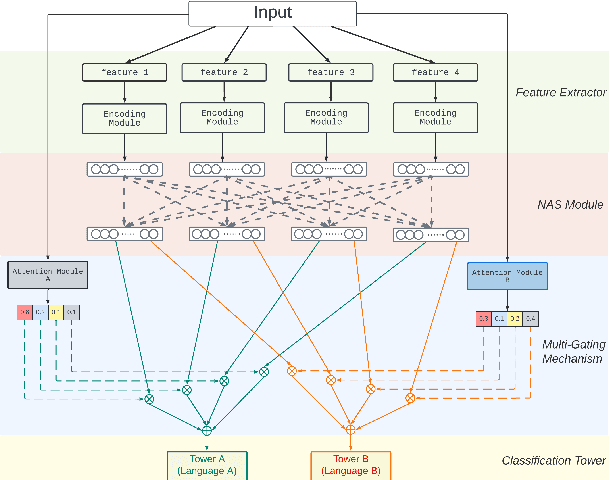

Speech emotion recognition (SER) classifies audio into emotion categories such as Happy, Angry, Fear, Disgust and Neutral. While Speech Emotion Recognition (SER) is a common application for popular languages, it continues to be a problem for low-resourced languages, i.e., languages with no pretrained speech-to-text recognition models. This paper firstly proposes a language-specific model that extract emotional information from multiple pre-trained speech models, and then designs a multi-domain model that simultaneously performs SER for various languages. Our multidomain model employs a multi-gating mechanism to generate unique weighted feature combination for each language, and also searches for specific neural network structure for each language through a neural architecture search module. In addition, we introduce a contrastive auxiliary loss to build more separable representations for audio data. Our experiments show that our model raises the state-of-the-art accuracy by 3% for German and 14.3% for French.
ToolFlowNet: Robotic Manipulation with Tools via Predicting Tool Flow from Point Clouds
Nov 16, 2022
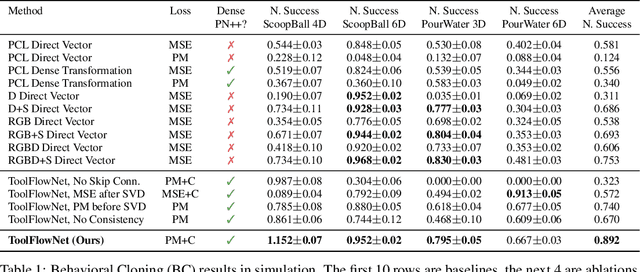
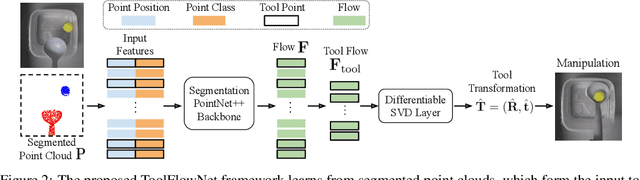
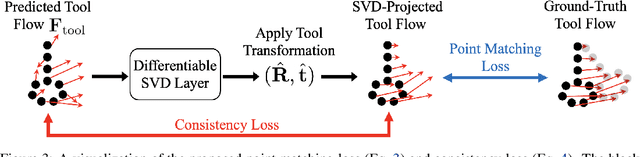
Point clouds are a widely available and canonical data modality which convey the 3D geometry of a scene. Despite significant progress in classification and segmentation from point clouds, policy learning from such a modality remains challenging, and most prior works in imitation learning focus on learning policies from images or state information. In this paper, we propose a novel framework for learning policies from point clouds for robotic manipulation with tools. We use a novel neural network, ToolFlowNet, which predicts dense per-point flow on the tool that the robot controls, and then uses the flow to derive the transformation that the robot should execute. We apply this framework to imitation learning of challenging deformable object manipulation tasks with continuous movement of tools, including scooping and pouring, and demonstrate significantly improved performance over baselines which do not use flow. We perform 50 physical scooping experiments with ToolFlowNet and attain 82% scooping success. See https://tinyurl.com/toolflownet for supplementary material.
XDBERT: Distilling Visual Information to BERT from Cross-Modal Systems to Improve Language Understanding
Apr 29, 2022
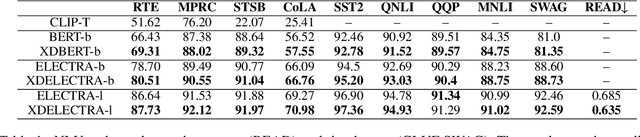
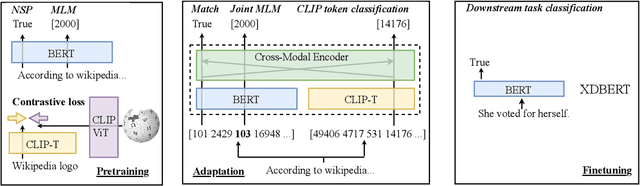

Transformer-based models are widely used in natural language understanding (NLU) tasks, and multimodal transformers have been effective in visual-language tasks. This study explores distilling visual information from pretrained multimodal transformers to pretrained language encoders. Our framework is inspired by cross-modal encoders' success in visual-language tasks while we alter the learning objective to cater to the language-heavy characteristics of NLU. After training with a small number of extra adapting steps and finetuned, the proposed XDBERT (cross-modal distilled BERT) outperforms pretrained-BERT in general language understanding evaluation (GLUE), situations with adversarial generations (SWAG) benchmarks, and readability benchmarks. We analyze the performance of XDBERT on GLUE to show that the improvement is likely visually grounded.
ATCO2 corpus: A Large-Scale Dataset for Research on Automatic Speech Recognition and Natural Language Understanding of Air Traffic Control Communications
Nov 08, 2022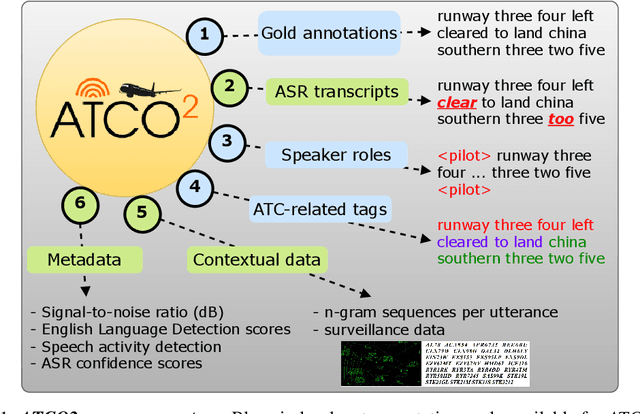
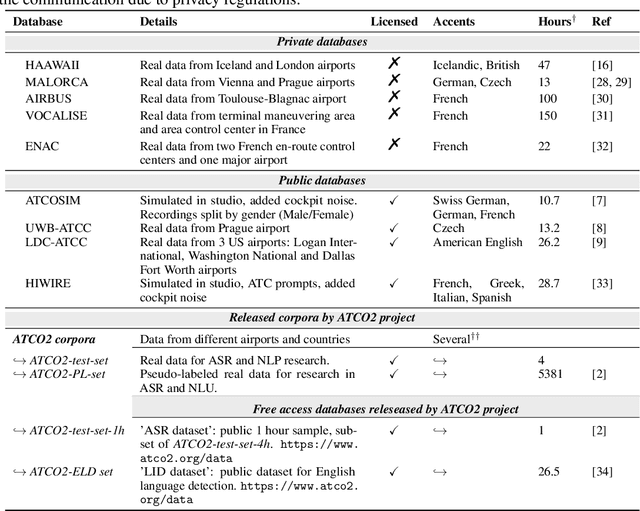
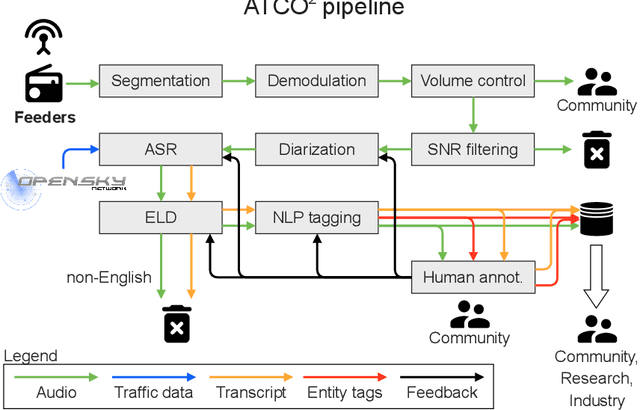

Personal assistants, automatic speech recognizers and dialogue understanding systems are becoming more critical in our interconnected digital world. A clear example is air traffic control (ATC) communications. ATC aims at guiding aircraft and controlling the airspace in a safe and optimal manner. These voice-based dialogues are carried between an air traffic controller (ATCO) and pilots via very-high frequency radio channels. In order to incorporate these novel technologies into ATC (low-resource domain), large-scale annotated datasets are required to develop the data-driven AI systems. Two examples are automatic speech recognition (ASR) and natural language understanding (NLU). In this paper, we introduce the ATCO2 corpus, a dataset that aims at fostering research on the challenging ATC field, which has lagged behind due to lack of annotated data. The ATCO2 corpus covers 1) data collection and pre-processing, 2) pseudo-annotations of speech data, and 3) extraction of ATC-related named entities. The ATCO2 corpus is split into three subsets. 1) ATCO2-test-set corpus contains 4 hours of ATC speech with manual transcripts and a subset with gold annotations for named-entity recognition (callsign, command, value). 2) The ATCO2-PL-set corpus consists of 5281 hours of unlabeled ATC data enriched with automatic transcripts from an in-domain speech recognizer, contextual information, speaker turn information, signal-to-noise ratio estimate and English language detection score per sample. Both available for purchase through ELDA at http://catalog.elra.info/en-us/repository/browse/ELRA-S0484. 3) The ATCO2-test-set-1h corpus is a one-hour subset from the original test set corpus, that we are offering for free at https://www.atco2.org/data. We expect the ATCO2 corpus will foster research on robust ASR and NLU not only in the field of ATC communications but also in the general research community.
DeSTSeg: Segmentation Guided Denoising Student-Teacher for Anomaly Detection
Nov 21, 2022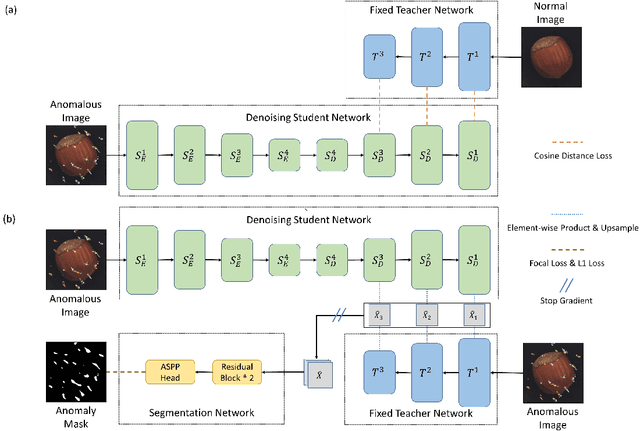

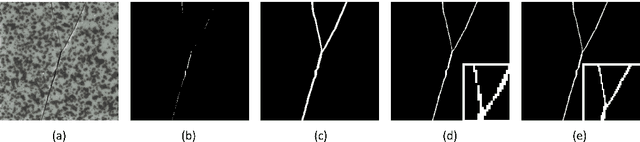
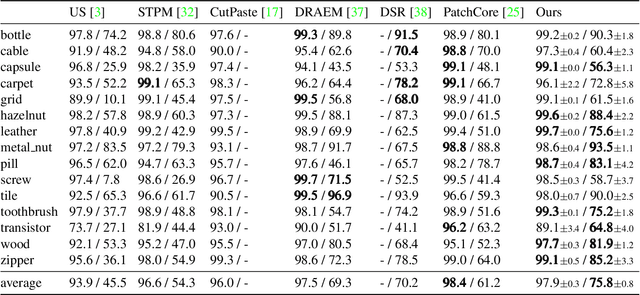
Visual anomaly detection, an important problem in computer vision, is usually formulated as a one-class classification and segmentation task. The student-teacher (S-T) framework has proved to be effective in solving this challenge. However, previous works based on S-T only empirically applied constraints on normal data and fused multi-level information. In this study, we propose an improved model called DeSTSeg, which integrates a pre-trained teacher network, a denoising student encoder-decoder, and a segmentation network into one framework. First, to strengthen the constraints on anomalous data, we introduce a denoising procedure that allows the student network to learn more robust representations. From synthetically corrupted normal images, we train the student network to match the teacher network feature of the same images without corruption. Second, to fuse the multi-level S-T features adaptively, we train a segmentation network with rich supervision from synthetic anomaly masks, achieving a substantial performance improvement. Experiments on the industrial inspection benchmark dataset demonstrate that our method achieves state-of-the-art performance, 98.6% on image-level ROC, 75.8% on pixel-level average precision, and 76.4% on instance-level average precision.
C3: Cross-instance guided Contrastive Clustering
Nov 21, 2022
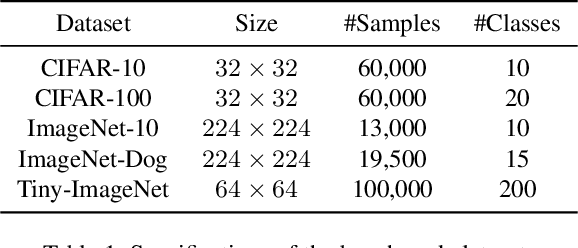
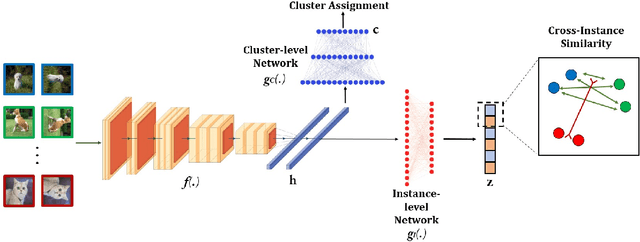
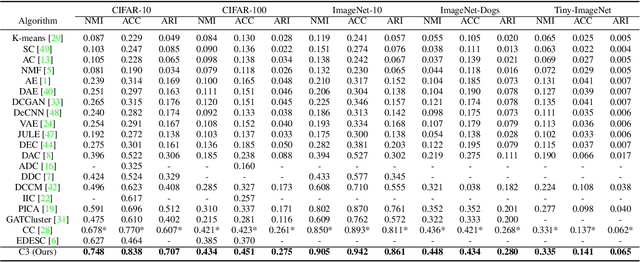
Clustering is the task of gathering similar data samples into clusters without using any predefined labels. It has been widely studied in machine learning literature, and recent advancements in deep learning have revived interest in this field. Contrastive clustering (CC) models are a staple of deep clustering in which positive and negative pairs of each data instance are generated through data augmentation. CC models aim to learn a feature space where instance-level and cluster-level representations of positive pairs are grouped together. Despite improving the SOTA, these algorithms ignore the cross-instance patterns, which carry essential information for improving clustering performance. In this paper, we propose a novel contrastive clustering method, Cross-instance guided Contrastive Clustering (C3), that considers the cross-sample relationships to increase the number of positive pairs. In particular, we define a new loss function that identifies similar instances using the instance-level representation and encourages them to aggregate together. Extensive experimental evaluations show that our proposed method can outperform state-of-the-art algorithms on benchmark computer vision datasets: we improve the clustering accuracy by 6.8%, 2.8%, 4.9%, 1.3% and 0.4% on CIFAR-10, CIFAR-100, ImageNet-10, ImageNet-Dogs, and Tiny-ImageNet, respectively.
SegNeRF: 3D Part Segmentation with Neural Radiance Fields
Nov 21, 2022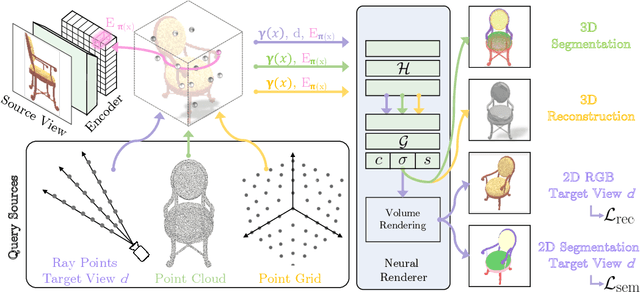


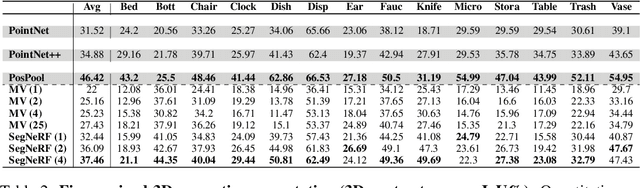
Recent advances in Neural Radiance Fields (NeRF) boast impressive performances for generative tasks such as novel view synthesis and 3D reconstruction. Methods based on neural radiance fields are able to represent the 3D world implicitly by relying exclusively on posed images. Yet, they have seldom been explored in the realm of discriminative tasks such as 3D part segmentation.In this work, we attempt to bridge that gap by proposing SegNeRF: a neural field representation that integrates a semantic field along with the usual radiance field. SegNeRF inherits from previous works the ability to perform novel view synthesis and 3D reconstruction, and enables 3D part segmentation from a few images. Our extensive experiments on PartNet show that SegNeRF is capable of simultaneously predicting geometry, appearance, and semantic information from posed images, even for unseen objects. The predicted semantic fields allow SegNeRF to achieve an average mIoU of $\textbf{30.30%}$ for 2D novel view segmentation, and $\textbf{37.46%}$ for 3D part segmentation, boasting competitive performance against point-based methods by using only a few posed images. Additionally, SegNeRF is able to generate an explicit 3D model from a single image of an object taken in the wild, with its corresponding part segmentation.
Model-based Trajectory Stitching for Improved Offline Reinforcement Learning
Nov 21, 2022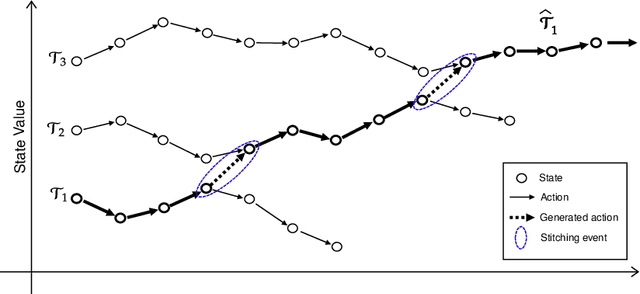
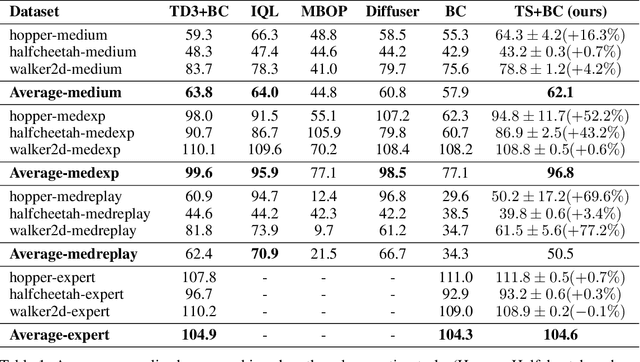
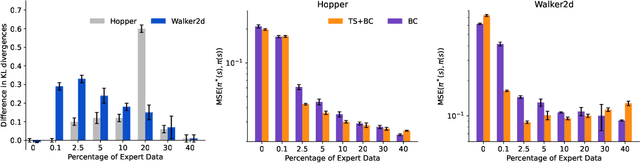
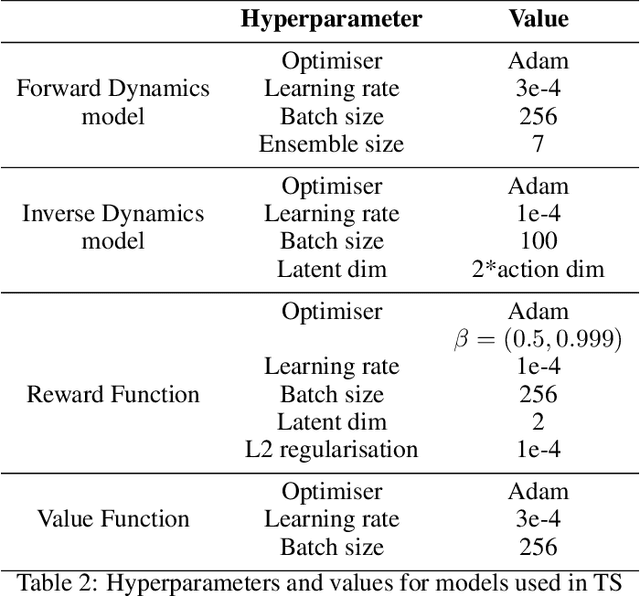
In many real-world applications, collecting large and high-quality datasets may be too costly or impractical. Offline reinforcement learning (RL) aims to infer an optimal decision-making policy from a fixed set of data. Getting the most information from historical data is then vital for good performance once the policy is deployed. We propose a model-based data augmentation strategy, Trajectory Stitching (TS), to improve the quality of sub-optimal historical trajectories. TS introduces unseen actions joining previously disconnected states: using a probabilistic notion of state reachability, it effectively `stitches' together parts of the historical demonstrations to generate new, higher quality ones. A stitching event consists of a transition between a pair of observed states through a synthetic and highly probable action. New actions are introduced only when they are expected to be beneficial, according to an estimated state-value function. We show that using this data augmentation strategy jointly with behavioural cloning (BC) leads to improvements over the behaviour-cloned policy from the original dataset. Improving over the BC policy could then be used as a launchpad for online RL through planning and demonstration-guided RL.
A Graph Regularized Point Process Model For Event Propagation Sequence
Nov 21, 2022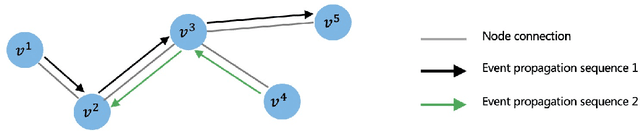
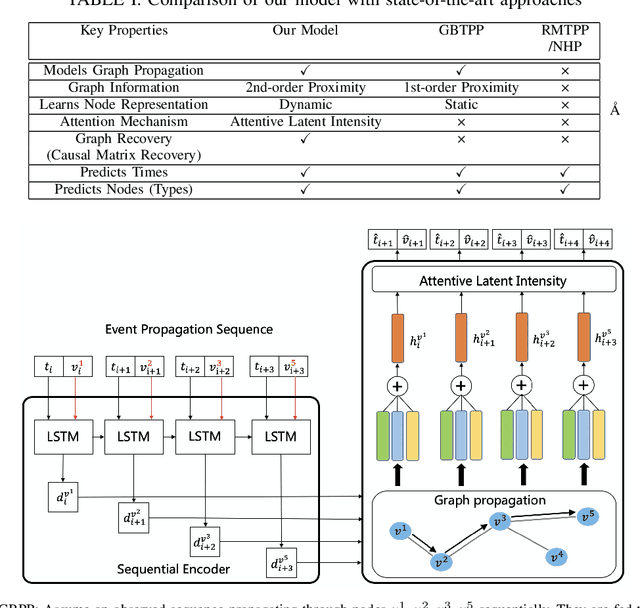
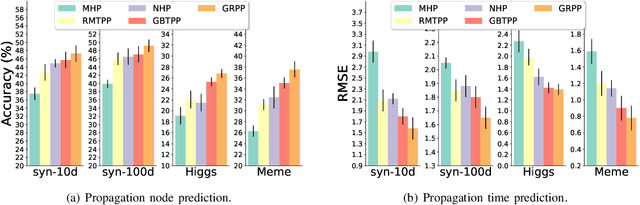
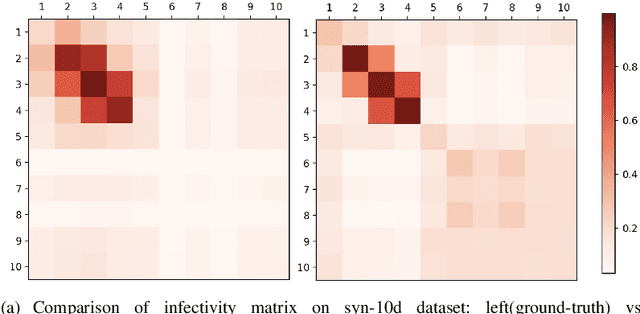
Point process is the dominant paradigm for modeling event sequences occurring at irregular intervals. In this paper we aim at modeling latent dynamics of event propagation in graph, where the event sequence propagates in a directed weighted graph whose nodes represent event marks (e.g., event types). Most existing works have only considered encoding sequential event history into event representation and ignored the information from the latent graph structure. Besides they also suffer from poor model explainability, i.e., failing to uncover causal influence across a wide variety of nodes. To address these problems, we propose a Graph Regularized Point Process (GRPP) that can be decomposed into: 1) a graph propagation model that characterizes the event interactions across nodes with neighbors and inductively learns node representations; 2) a temporal attentive intensity model, whose excitation and time decay factors of past events on the current event are constructed via the contextualization of the node embedding. Moreover, by applying a graph regularization method, GRPP provides model interpretability by uncovering influence strengths between nodes. Numerical experiments on various datasets show that GRPP outperforms existing models on both the propagation time and node prediction by notable margins.
* IJCNN 2021