 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning at the Intersection: Certified Robustness as a Tool for 3D Vision
Aug 23, 2024



This paper presents preliminary work on a novel connection between certified robustness in machine learning and the modeling of 3D objects. We highlight an intriguing link between the Maximal Certified Radius (MCR) of a classifier representing a space's occupancy and the space's Signed Distance Function (SDF). Leveraging this relationship, we propose to use the certification method of randomized smoothing (RS) to compute SDFs. Since RS' high computational cost prevents its practical usage as a way to compute SDFs, we propose an algorithm to efficiently run RS in low-dimensional applications, such as 3D space, by expressing RS' fundamental operations as Gaussian smoothing on pre-computed voxel grids. Our approach offers an innovative and practical tool to compute SDFs, validated through proof-of-concept experiments in novel view synthesis. This paper bridges two previously disparate areas of machine learning, opening new avenues for further exploration and potential cross-domain advancements.
TrackNeRF: Bundle Adjusting NeRF from Sparse and Noisy Views via Feature Tracks
Aug 20, 2024



Neural radiance fields (NeRFs) generally require many images with accurate poses for accurate novel view synthesis, which does not reflect realistic setups where views can be sparse and poses can be noisy. Previous solutions for learning NeRFs with sparse views and noisy poses only consider local geometry consistency with pairs of views. Closely following \textit{bundle adjustment} in Structure-from-Motion (SfM), we introduce TrackNeRF for more globally consistent geometry reconstruction and more accurate pose optimization. TrackNeRF introduces \textit{feature tracks}, \ie connected pixel trajectories across \textit{all} visible views that correspond to the \textit{same} 3D points. By enforcing reprojection consistency among feature tracks, TrackNeRF encourages holistic 3D consistency explicitly. Through extensive experiments, TrackNeRF sets a new benchmark in noisy and sparse view reconstruction. In particular, TrackNeRF shows significant improvements over the state-of-the-art BARF and SPARF by $\sim8$ and $\sim1$ in terms of PSNR on DTU under various sparse and noisy view setups. The code is available at \href{https://tracknerf.github.io/}.
DATENeRF: Depth-Aware Text-based Editing of NeRFs
Apr 06, 2024Recent advancements in diffusion models have shown remarkable proficiency in editing 2D images based on text prompts. However, extending these techniques to edit scenes in Neural Radiance Fields (NeRF) is complex, as editing individual 2D frames can result in inconsistencies across multiple views. Our crucial insight is that a NeRF scene's geometry can serve as a bridge to integrate these 2D edits. Utilizing this geometry, we employ a depth-conditioned ControlNet to enhance the coherence of each 2D image modification. Moreover, we introduce an inpainting approach that leverages the depth information of NeRF scenes to distribute 2D edits across different images, ensuring robustness against errors and resampling challenges. Our results reveal that this methodology achieves more consistent, lifelike, and detailed edits than existing leading methods for text-driven NeRF scene editing.
Enhancing Neural Rendering Methods with Image Augmentations
Jun 15, 2023



Faithfully reconstructing 3D geometry and generating novel views of scenes are critical tasks in 3D computer vision. Despite the widespread use of image augmentations across computer vision applications, their potential remains underexplored when learning neural rendering methods (NRMs) for 3D scenes. This paper presents a comprehensive analysis of the use of image augmentations in NRMs, where we explore different augmentation strategies. We found that introducing image augmentations during training presents challenges such as geometric and photometric inconsistencies for learning NRMs from images. Specifically, geometric inconsistencies arise from alterations in shapes, positions, and orientations from the augmentations, disrupting spatial cues necessary for accurate 3D reconstruction. On the other hand, photometric inconsistencies arise from changes in pixel intensities introduced by the augmentations, affecting the ability to capture the underlying 3D structures of the scene. We alleviate these issues by focusing on color manipulations and introducing learnable appearance embeddings that allow NRMs to explain away photometric variations. Our experiments demonstrate the benefits of incorporating augmentations when learning NRMs, including improved photometric quality and surface reconstruction, as well as enhanced robustness against data quality issues, such as reduced training data and image degradations.
Re-ReND: Real-time Rendering of NeRFs across Devices
Mar 15, 2023



This paper proposes a novel approach for rendering a pre-trained Neural Radiance Field (NeRF) in real-time on resource-constrained devices. We introduce Re-ReND, a method enabling Real-time Rendering of NeRFs across Devices. Re-ReND is designed to achieve real-time performance by converting the NeRF into a representation that can be efficiently processed by standard graphics pipelines. The proposed method distills the NeRF by extracting the learned density into a mesh, while the learned color information is factorized into a set of matrices that represent the scene's light field. Factorization implies the field is queried via inexpensive MLP-free matrix multiplications, while using a light field allows rendering a pixel by querying the field a single time-as opposed to hundreds of queries when employing a radiance field. Since the proposed representation can be implemented using a fragment shader, it can be directly integrated with standard rasterization frameworks. Our flexible implementation can render a NeRF in real-time with low memory requirements and on a wide range of resource-constrained devices, including mobiles and AR/VR headsets. Notably, we find that Re-ReND can achieve over a 2.6-fold increase in rendering speed versus the state-of-the-art without perceptible losses in quality.
SegNeRF: 3D Part Segmentation with Neural Radiance Fields
Nov 22, 2022



Recent advances in Neural Radiance Fields (NeRF) boast impressive performances for generative tasks such as novel view synthesis and 3D reconstruction. Methods based on neural radiance fields are able to represent the 3D world implicitly by relying exclusively on posed images. Yet, they have seldom been explored in the realm of discriminative tasks such as 3D part segmentation. In this work, we attempt to bridge that gap by proposing SegNeRF: a neural field representation that integrates a semantic field along with the usual radiance field. SegNeRF inherits from previous works the ability to perform novel view synthesis and 3D reconstruction, and enables 3D part segmentation from a few images. Our extensive experiments on PartNet show that SegNeRF is capable of simultaneously predicting geometry, appearance, and semantic information from posed images, even for unseen objects. The predicted semantic fields allow SegNeRF to achieve an average mIoU of $\textbf{30.30%}$ for 2D novel view segmentation, and $\textbf{37.46%}$ for 3D part segmentation, boasting competitive performance against point-based methods by using only a few posed images. Additionally, SegNeRF is able to generate an explicit 3D model from a single image of an object taken in the wild, with its corresponding part segmentation.
AdvPC: Transferable Adversarial Perturbations on 3D Point Clouds
Dec 01, 2019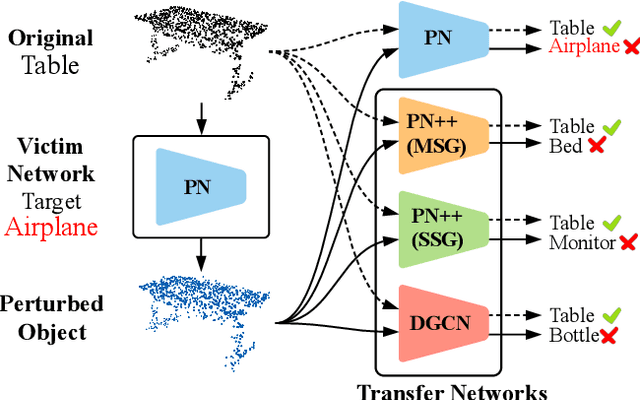
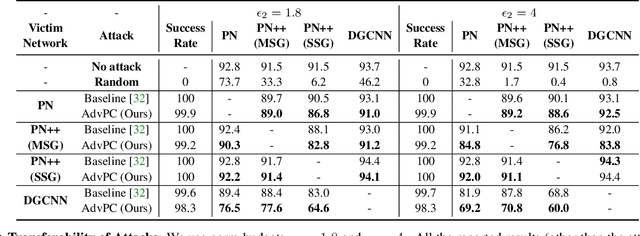
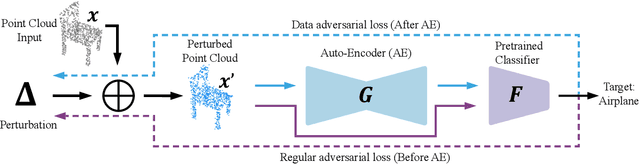
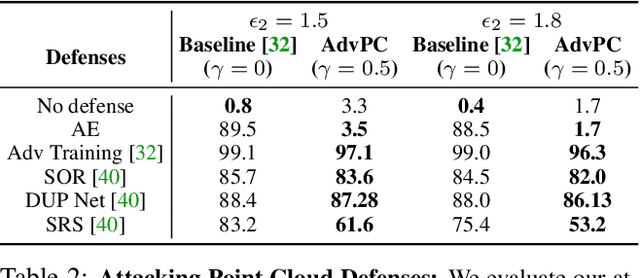
Deep neural networks are vulnerable to adversarial attacks, in which imperceptible perturbations to their input lead to erroneous network predictions. This phenomenon has been extensively studied in the image domain, and only recently extended to 3D point clouds. In this work, we present novel data-driven adversarial attacks against 3D point cloud networks. We aim to address the following problems in current 3D point cloud adversarial attacks: they do not transfer well between different networks, and they are easy to defend against simple statistical methods. To this extent, we develop new point cloud attacks (we dub AdvPC) that exploit input data distributions. These attacks lead to perturbations that are resilient against current defenses while remaining highly transferable compared to state-of-the-art attacks. We test our attacks using four popular point cloud networks: PointNet, PointNet++ (MSG and SSG), and DGCNN. Our proposed attack enables an increase in the transferability of up to 20 points for some networks. It also increases the ability to break defenses of up to 23 points on ModelNet40 data.