 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Beyond Mahalanobis-Based Scores for Textual OOD Detection
Nov 24, 2022
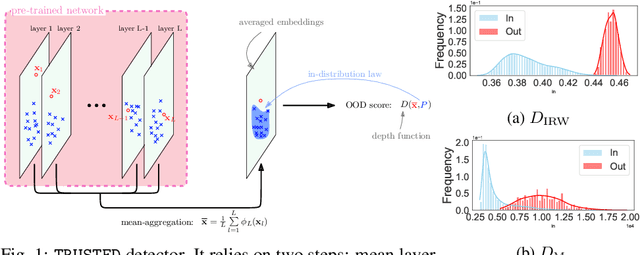
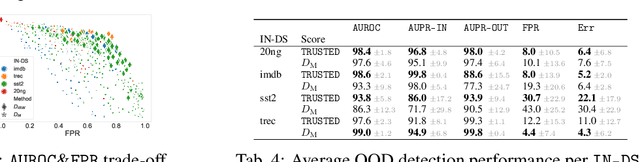
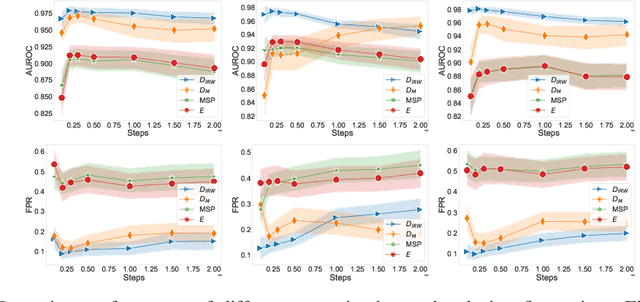
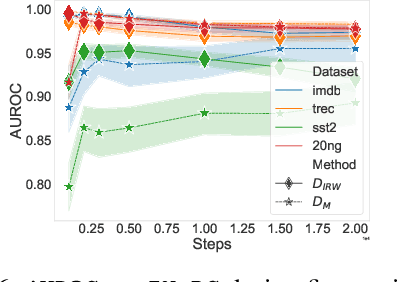
Deep learning methods have boosted the adoption of NLP systems in real-life applications. However, they turn out to be vulnerable to distribution shifts over time which may cause severe dysfunctions in production systems, urging practitioners to develop tools to detect out-of-distribution (OOD) samples through the lens of the neural network. In this paper, we introduce TRUSTED, a new OOD detector for classifiers based on Transformer architectures that meets operational requirements: it is unsupervised and fast to compute. The efficiency of TRUSTED relies on the fruitful idea that all hidden layers carry relevant information to detect OOD examples. Based on this, for a given input, TRUSTED consists in (i) aggregating this information and (ii) computing a similarity score by exploiting the training distribution, leveraging the powerful concept of data depth. Our extensive numerical experiments involve 51k model configurations, including various checkpoints, seeds, and datasets, and demonstrate that TRUSTED achieves state-of-the-art performances. In particular, it improves previous AUROC over 3 points.
ExARN: self-attending RNN for target speaker extraction
Dec 02, 2022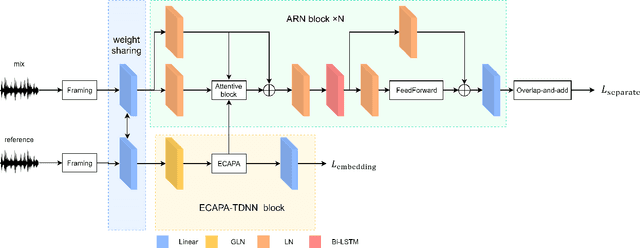
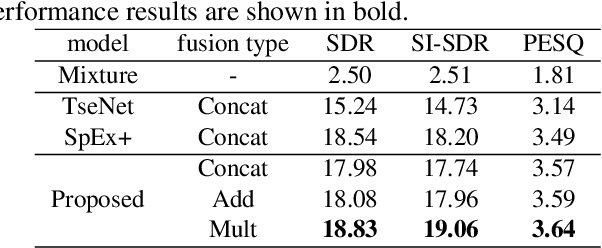
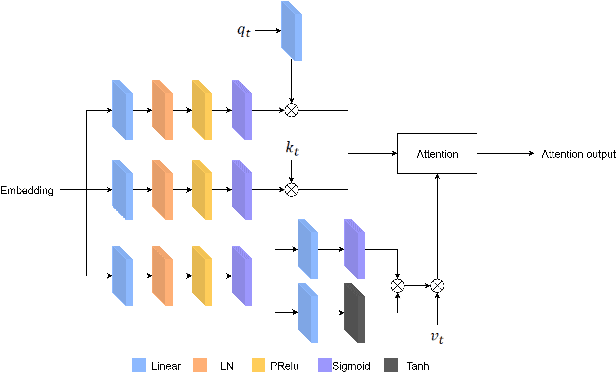
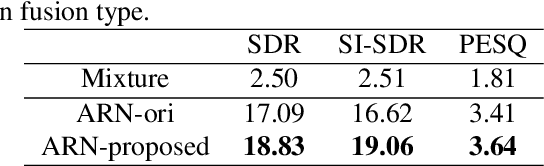
Target speaker extraction is to extract the target speaker, specified by enrollment utterance, in an environment with other competing speakers. Therefore, the task needs to solve two problems, speaker identification and separation, at the same time. In this paper, we combine self-attention and Recurrent Neural Networks (RNN). Further, we exploit various ways to combining different auxiliary information with mixed representations. Experimental results show that our proposed model achieves excellent performance on the task of target speaker extraction.
Pivotal Role of Language Modeling in Recommender Systems: Enriching Task-specific and Task-agnostic Representation Learning
Dec 13, 2022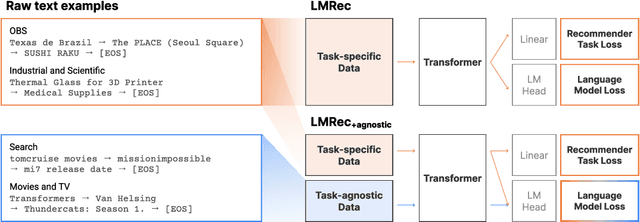
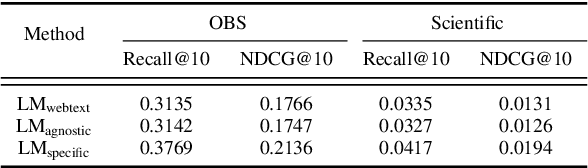

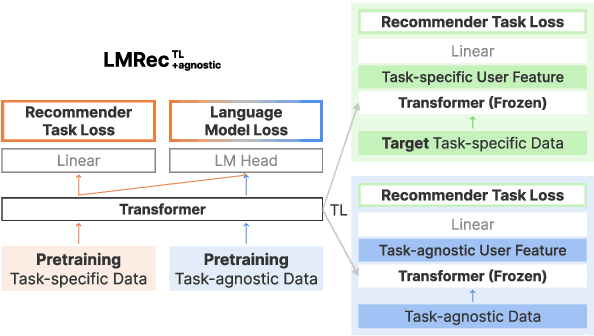
Recent studies have proposed unified user modeling frameworks that leverage user behavior data from various applications. Many of them benefit from utilizing users' behavior sequences as plain texts, representing rich information in any domain or system without losing generality. Hence, a question arises: Can language modeling for user history corpus help improve recommender systems? While its versatile usability has been widely investigated in many domains, its applications to recommender systems still remain underexplored. We show that language modeling applied directly to task-specific user histories achieves excellent results on diverse recommendation tasks. Also, leveraging additional task-agnostic user histories delivers significant performance benefits. We further demonstrate that our approach can provide promising transfer learning capabilities for a broad spectrum of real-world recommender systems, even on unseen domains and services.
Relational Sentence Embedding for Flexible Semantic Matching
Dec 17, 2022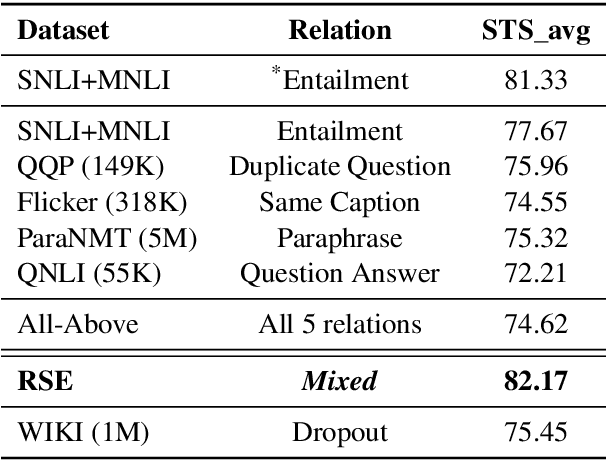
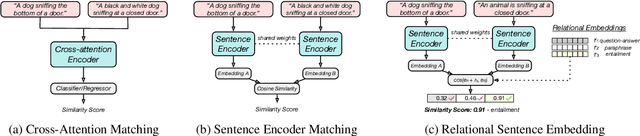
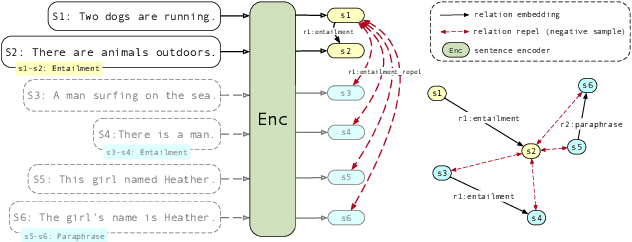
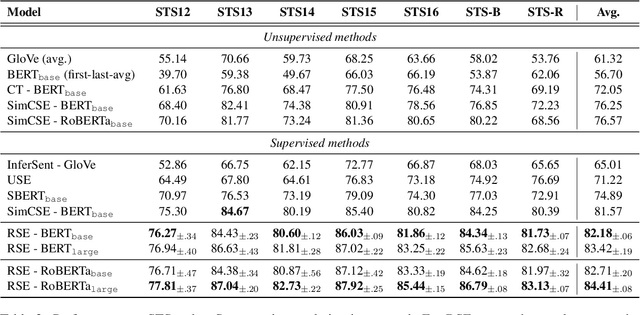
We present Relational Sentence Embedding (RSE), a new paradigm to further discover the potential of sentence embeddings. Prior work mainly models the similarity between sentences based on their embedding distance. Because of the complex semantic meanings conveyed, sentence pairs can have various relation types, including but not limited to entailment, paraphrasing, and question-answer. It poses challenges to existing embedding methods to capture such relational information. We handle the problem by learning associated relational embeddings. Specifically, a relation-wise translation operation is applied to the source sentence to infer the corresponding target sentence with a pre-trained Siamese-based encoder. The fine-grained relational similarity scores can be computed from learned embeddings. We benchmark our method on 19 datasets covering a wide range of tasks, including semantic textual similarity, transfer, and domain-specific tasks. Experimental results show that our method is effective and flexible in modeling sentence relations and outperforms a series of state-of-the-art sentence embedding methods. https://github.com/BinWang28/RSE
HyPe: Better Pre-trained Language Model Fine-tuning with Hidden Representation Perturbation
Dec 17, 2022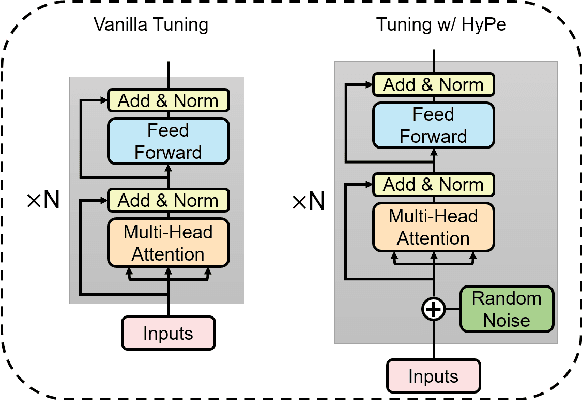
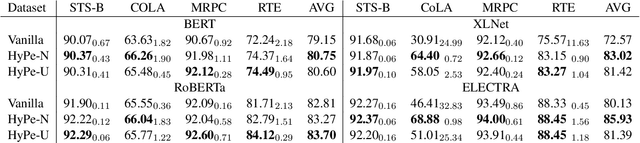

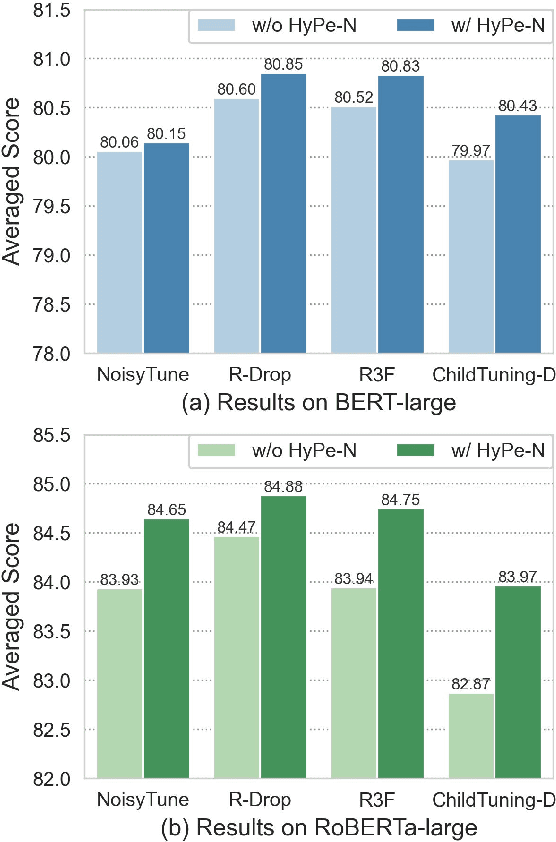
Language models with the Transformers structure have shown great performance in natural language processing. However, there still poses problems when fine-tuning pre-trained language models on downstream tasks, such as over-fitting or representation collapse. In this work, we propose HyPe, a simple yet effective fine-tuning technique to alleviate such problems by perturbing hidden representations of Transformers layers. Unlike previous works that only add noise to inputs or parameters, we argue that the hidden representations of Transformers layers convey more diverse and meaningful language information. Therefore, making the Transformers layers more robust to hidden representation perturbations can further benefit the fine-tuning of PLMs en bloc. We conduct extensive experiments and analyses on GLUE and other natural language inference datasets. Results demonstrate that HyPe outperforms vanilla fine-tuning and enhances generalization of hidden representations from different layers. In addition, HyPe acquires negligible computational overheads, and is better than and compatible with previous state-of-the-art fine-tuning techniques.
Absolute Wrong Makes Better: Boosting Weakly Supervised Object Detection via Negative Deterministic Information
Apr 21, 2022
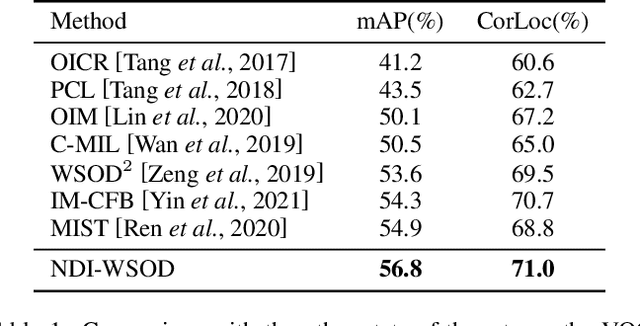
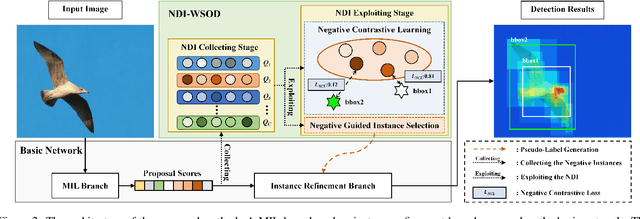
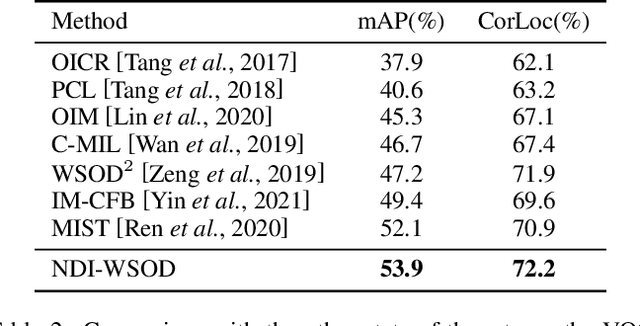
Weakly supervised object detection (WSOD) is a challenging task, in which image-level labels (e.g., categories of the instances in the whole image) are used to train an object detector. Many existing methods follow the standard multiple instance learning (MIL) paradigm and have achieved promising performance. However, the lack of deterministic information leads to part domination and missing instances. To address these issues, this paper focuses on identifying and fully exploiting the deterministic information in WSOD. We discover that negative instances (i.e. absolutely wrong instances), ignored in most of the previous studies, normally contain valuable deterministic information. Based on this observation, we here propose a negative deterministic information (NDI) based method for improving WSOD, namely NDI-WSOD. Specifically, our method consists of two stages: NDI collecting and exploiting. In the collecting stage, we design several processes to identify and distill the NDI from negative instances online. In the exploiting stage, we utilize the extracted NDI to construct a novel negative contrastive learning mechanism and a negative guided instance selection strategy for dealing with the issues of part domination and missing instances, respectively. Experimental results on several public benchmarks including VOC 2007, VOC 2012 and MS COCO show that our method achieves satisfactory performance.
Cross-view Geo-localization via Learning Disentangled Geometric Layout Correspondence
Dec 08, 2022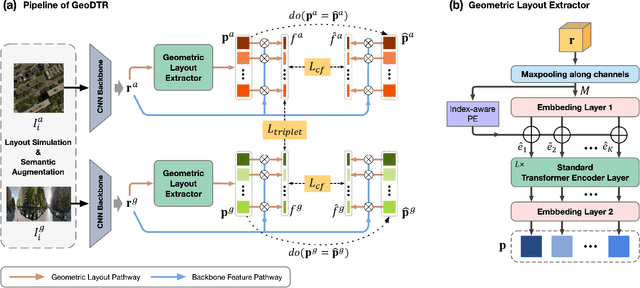
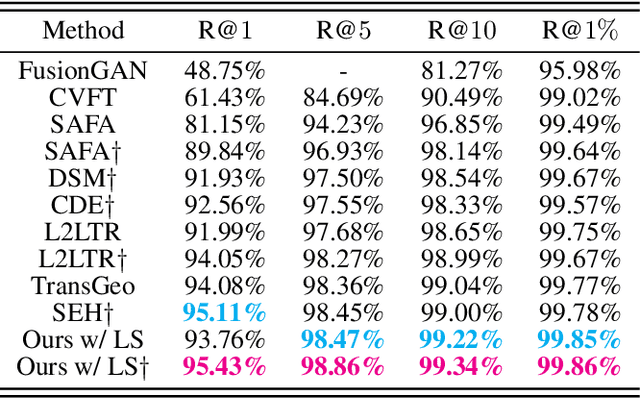

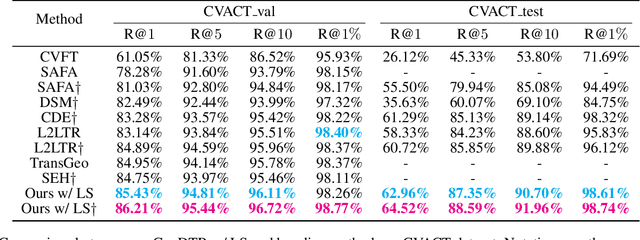
Cross-view geo-localization aims to estimate the location of a query ground image by matching it to a reference geo-tagged aerial images database. As an extremely challenging task, its difficulties root in the drastic view changes and different capturing time between two views. Despite these difficulties, recent works achieve outstanding progress on cross-view geo-localization benchmarks. However, existing methods still suffer from poor performance on the cross-area benchmarks, in which the training and testing data are captured from two different regions. We attribute this deficiency to the lack of ability to extract the spatial configuration of visual feature layouts and models' overfitting on low-level details from the training set. In this paper, we propose GeoDTR which explicitly disentangles geometric information from raw features and learns the spatial correlations among visual features from aerial and ground pairs with a novel geometric layout extractor module. This module generates a set of geometric layout descriptors, modulating the raw features and producing high-quality latent representations. In addition, we elaborate on two categories of data augmentations, (i) Layout simulation, which varies the spatial configuration while keeping the low-level details intact. (ii) Semantic augmentation, which alters the low-level details and encourages the model to capture spatial configurations. These augmentations help to improve the performance of the cross-view geo-localization models, especially on the cross-area benchmarks. Moreover, we propose a counterfactual-based learning process to benefit the geometric layout extractor in exploring spatial information. Extensive experiments show that GeoDTR not only achieves state-of-the-art results but also significantly boosts the performance on same-area and cross-area benchmarks.
Sampling with Attribute-Related Information for Controlling Language Models
May 12, 2022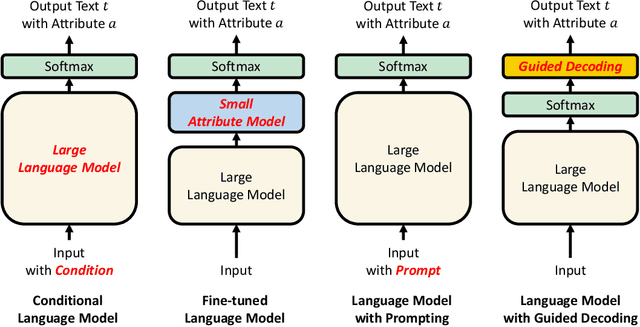
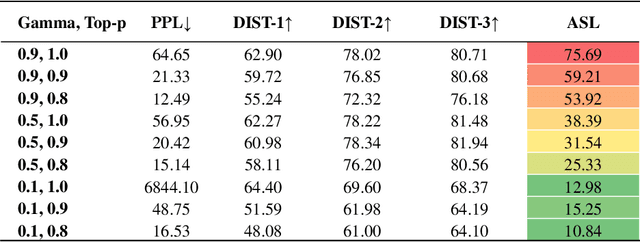

The dominant approaches for controlling language models are based on fine-tuning large language models or prompt engineering. However, these methods often require condition-specific data or considerable hand-crafting. We propose a new simple guided decoding method, Gamma Sampling, which does not require complex engineering and any extra data. Gamma Sampling introduces attribute-related information (provided by humans or language models themselves) into the sampling process to guide language models to generate texts with desired attributes. Experiments on controlling topics and sentiments of generated text show Gamma Sampling to be superior in diversity, attribute relevance and overall quality of generated samples while maintaining a fast generation speed. In addition, we successfully applied Gamma Sampling to control other attributes of language such as relatedness and repetition, which further demonstrates the versatility and effectiveness of this method. Gamma Sampling is now available in the python package samplings via import gamma sampling from samplings.
SMS: Spiking Marching Scheme for Efficient Long Time Integration of Differential Equations
Nov 17, 2022
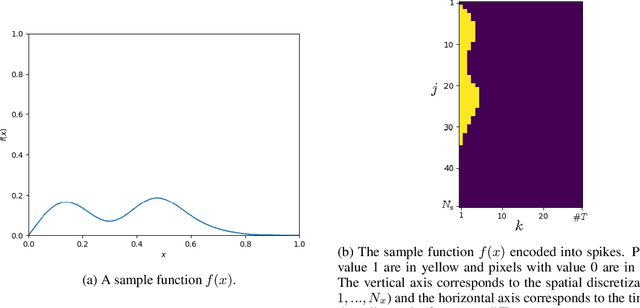
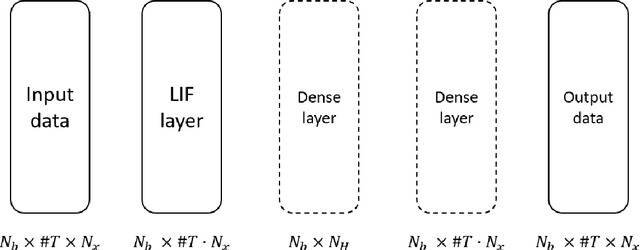
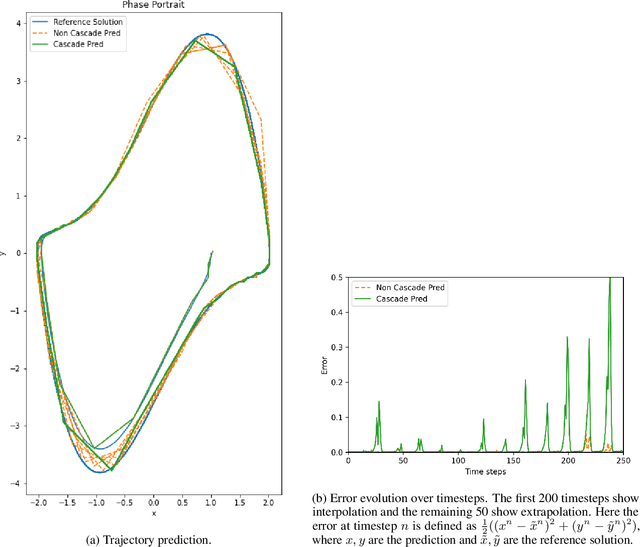
We propose a Spiking Neural Network (SNN)-based explicit numerical scheme for long time integration of time-dependent Ordinary and Partial Differential Equations (ODEs, PDEs). The core element of the method is a SNN, trained to use spike-encoded information about the solution at previous timesteps to predict spike-encoded information at the next timestep. After the network has been trained, it operates as an explicit numerical scheme that can be used to compute the solution at future timesteps, given a spike-encoded initial condition. A decoder is used to transform the evolved spiking-encoded solution back to function values. We present results from numerical experiments of using the proposed method for ODEs and PDEs of varying complexity.
Self-Supervised Surgical Instrument 3D Reconstruction from a Single Camera Image
Nov 26, 2022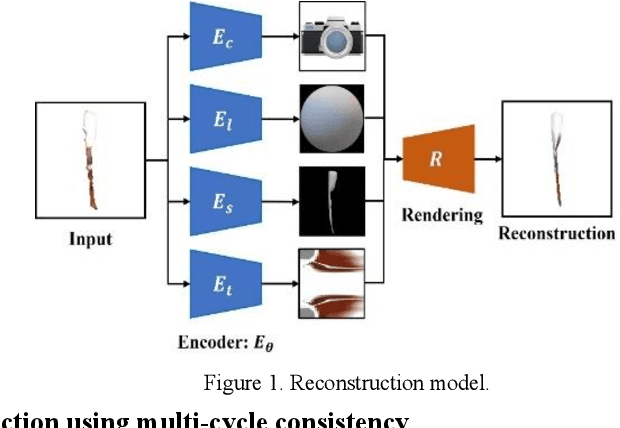
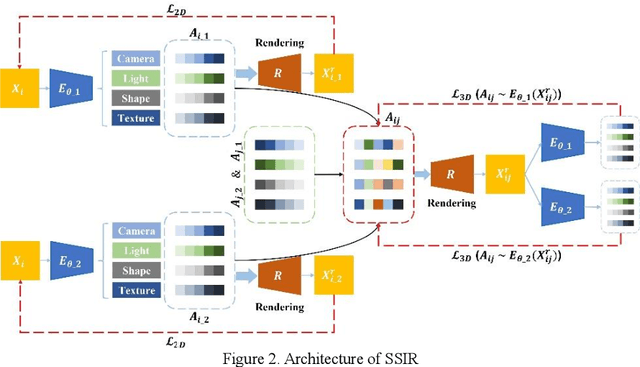
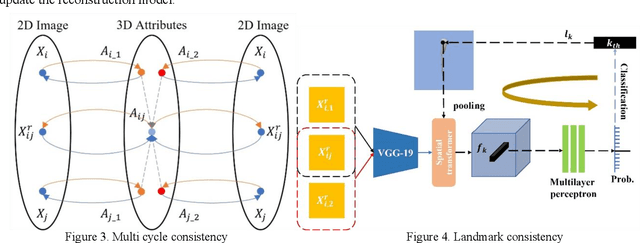

Surgical instrument tracking is an active research area that can provide surgeons feedback about the location of their tools relative to anatomy. Recent tracking methods are mainly divided into two parts: segmentation and object detection. However, both can only predict 2D information, which is limiting for application to real-world surgery. An accurate 3D surgical instrument model is a prerequisite for precise predictions of the pose and depth of the instrument. Recent single-view 3D reconstruction methods are only used in natural object reconstruction and do not achieve satisfying reconstruction accuracy without 3D attribute-level supervision. Further, those methods are not suitable for the surgical instruments because of their elongated shapes. In this paper, we firstly propose an end-to-end surgical instrument reconstruction system -- Self-supervised Surgical Instrument Reconstruction (SSIR). With SSIR, we propose a multi-cycle-consistency strategy to help capture the texture information from a slim instrument while only requiring a binary instrument label map. Experiments demonstrate that our approach improves the reconstruction quality of surgical instruments compared to other self-supervised methods and achieves promising results.