 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTORM: Stepwise Token Optimization with Reward-Guided Beam Search
Jun 09, 2026Modern retrieval increasingly relies on dense and learned-sparse neural models that are effective but require encoding the entire corpus into a specialized index, rebuilt whenever the model changes. Lexical retrievers like BM25 stay efficient and transparent on a standard inverted index that need not change as models evolve, but suffer from vocabulary mismatch. LLM query rewriting can help, yet prompted rewriters emit well-formed but retrieval-ineffective or harmful-terms, and training against a retrieval reward gives only delayed, sequence-level supervision that obscures which terms helped. We introduce STORM (Stepwise Token Optimization with Reward-guided beaM search), a self-supervised framework for lexical query expansion. STORM trains the rewriter through generation guided by retrieval metrics: at each step, candidate expansions are scored against the BM25 index and low-reward continuations pruned, turning the retrieval reward into a token-level signal that concentrates exploration on retrieval-effective vocabulary. Across TREC DL and BEIR, STORM lets 0.6B-8B backbones match or surpass competitive LLM rewriters while retrieving as fast as plain BM25; at 8B it rivals far larger proprietary rewriters. It further transfers zero-shot to 18 languages (MIRACL), beating dedicated multilingual dense retrievers on average, making STORM a competitive, infrastructure-light alternative to dense neural retrieval.
$ECUAS_n$: A family of metrics for principled evaluation of uncertainty-augmented systems
May 21, 2026In high-stakes automated decision-making, access to predictive uncertainty is essential for enabling users -- human or downstream systems -- to accept or reject predictions based on application-specific cost trade-offs. Such uncertainty-augmented (UA) systems -- i.e., systems that output both predictions and uncertainty scores -- are currently being assessed in the literature in a variety of ways, using separate metrics to evaluate the predictions and the uncertainty scores, setting a cost function with a fixed rejection cost or integrating over a coverage-risk curve. We argue that these evaluation approaches are inadequate for assessing overall performance of the UA system for decision making under uncertainty and propose a novel family of metrics, $ECUAS_n$, formulated as proper scoring rules for the task of interest. The parameter $n$ controls the trade-off between the cost of incorrect predictions and imperfect uncertainties depending on the needs of the use-case. We demonstrate the advantages of the $ECUAS_n$ metrics both theoretically and empirically, through experiments on diverse classification and generation datasets, including a manually annotated subset of TriviaQA.
MolRGen: A Training and Evaluation Setting for De Novo Molecular Generation with Reasonning Models
Mar 18, 2026Recent advances in reasoning-based large language models (LLMs) have demonstrated substantial improvements in complex problem-solving tasks. Motivated by these advances, several works have explored the application of reasoning LLMs to drug discovery and molecular design. However, most existing approaches either focus on evaluation or rely on training setups that require ground-truth labels, such as molecule pairs with known property modifications. Such supervision is unavailable in \textit{de novo} molecular generation, where the objective is to generate novel molecules that optimize a desirability score without prior knowledge of high-scoring candidates. To bridge this gap, we introduce MolRGen, a large-scale benchmark and dataset for training and evaluating reasoning-based LLMs on \textit{de novo} molecular generation. Our contributions are threefold. First, we propose a setting to evaluate and train models for \textit{de novo} molecular generation and property prediction. Second, we introduce a novel diversity-aware top-$k$ score that captures both the quality and diversity of generated molecules. Third, we show our setting can be used to train LLMs for molecular generation, training a 24B LLM with reinforcement learning, and we provide a detailed analysis of its performance and limitations.
QUESTER: Query Specification for Generative Retrieval
Nov 07, 2025Generative Retrieval (GR) differs from the traditional index-then-retrieve pipeline by storing relevance in model parameters and directly generating document identifiers. However, GR often struggles to generalize and is costly to scale. We introduce QUESTER (QUEry SpecificaTion gEnerative Retrieval), which reframes GR as query specification generation - in this work, a simple keyword query handled by BM25 - using a (small) LLM. The policy is trained using reinforcement learning techniques (GRPO). Across in- and out-of-domain evaluations, we show that our model is more effective than BM25, and competitive with neural IR models, while maintaining a good efficiency
Collaborative Rational Speech Act: Pragmatic Reasoning for Multi-Turn Dialog
Jul 18, 2025As AI systems take on collaborative roles, they must reason about shared goals and beliefs-not just generate fluent language. The Rational Speech Act (RSA) framework offers a principled approach to pragmatic reasoning, but existing extensions face challenges in scaling to multi-turn, collaborative scenarios. In this paper, we introduce Collaborative Rational Speech Act (CRSA), an information-theoretic (IT) extension of RSA that models multi-turn dialog by optimizing a gain function adapted from rate-distortion theory. This gain is an extension of the gain model that is maximized in the original RSA model but takes into account the scenario in which both agents in a conversation have private information and produce utterances conditioned on the dialog. We demonstrate the effectiveness of CRSA on referential games and template-based doctor-patient dialogs in the medical domain. Empirical results show that CRSA yields more consistent, interpretable, and collaborative behavior than existing baselines-paving the way for more pragmatic and socially aware language agents.
THUNDER: Tile-level Histopathology image UNDERstanding benchmark
Jul 10, 2025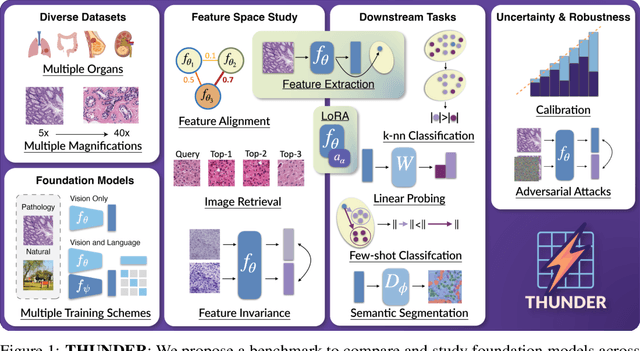
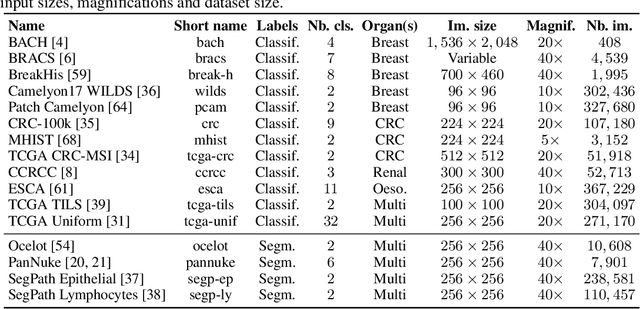
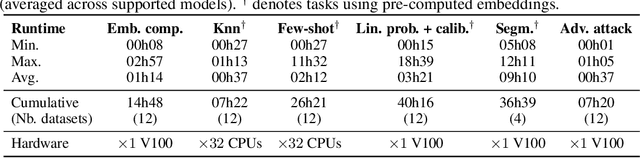
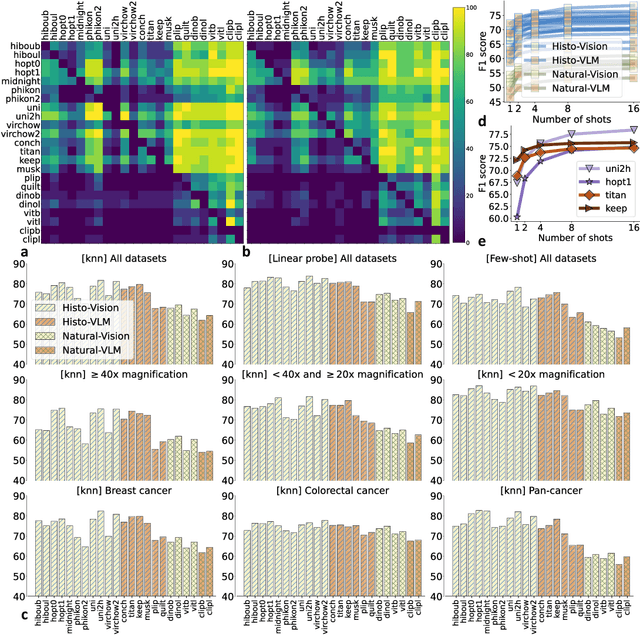
Progress in a research field can be hard to assess, in particular when many concurrent methods are proposed in a short period of time. This is the case in digital pathology, where many foundation models have been released recently to serve as feature extractors for tile-level images, being used in a variety of downstream tasks, both for tile- and slide-level problems. Benchmarking available methods then becomes paramount to get a clearer view of the research landscape. In particular, in critical domains such as healthcare, a benchmark should not only focus on evaluating downstream performance, but also provide insights about the main differences between methods, and importantly, further consider uncertainty and robustness to ensure a reliable usage of proposed models. For these reasons, we introduce THUNDER, a tile-level benchmark for digital pathology foundation models, allowing for efficient comparison of many models on diverse datasets with a series of downstream tasks, studying their feature spaces and assessing the robustness and uncertainty of predictions informed by their embeddings. THUNDER is a fast, easy-to-use, dynamic benchmark that can already support a large variety of state-of-the-art foundation, as well as local user-defined models for direct tile-based comparison. In this paper, we provide a comprehensive comparison of 23 foundation models on 16 different datasets covering diverse tasks, feature analysis, and robustness. The code for THUNDER is publicly available at https://github.com/MICS-Lab/thunder.
$(RSA)^2$: A Rhetorical-Strategy-Aware Rational Speech Act Framework for Figurative Language Understanding
Jun 10, 2025Figurative language (e.g., irony, hyperbole, understatement) is ubiquitous in human communication, resulting in utterances where the literal and the intended meanings do not match. The Rational Speech Act (RSA) framework, which explicitly models speaker intentions, is the most widespread theory of probabilistic pragmatics, but existing implementations are either unable to account for figurative expressions or require modeling the implicit motivations for using figurative language (e.g., to express joy or annoyance) in a setting-specific way. In this paper, we introduce the Rhetorical-Strategy-Aware RSA $(RSA)^2$ framework which models figurative language use by considering a speaker's employed rhetorical strategy. We show that $(RSA)^2$ enables human-compatible interpretations of non-literal utterances without modeling a speaker's motivations for being non-literal. Combined with LLMs, it achieves state-of-the-art performance on the ironic split of PragMega+, a new irony interpretation dataset introduced in this study.
Rational Retrieval Acts: Leveraging Pragmatic Reasoning to Improve Sparse Retrieval
May 06, 2025Current sparse neural information retrieval (IR) methods, and to a lesser extent more traditional models such as BM25, do not take into account the document collection and the complex interplay between different term weights when representing a single document. In this paper, we show how the Rational Speech Acts (RSA), a linguistics framework used to minimize the number of features to be communicated when identifying an object in a set, can be adapted to the IR case -- and in particular to the high number of potential features (here, tokens). RSA dynamically modulates token-document interactions by considering the influence of other documents in the dataset, better contrasting document representations. Experiments show that incorporating RSA consistently improves multiple sparse retrieval models and achieves state-of-the-art performance on out-of-domain datasets from the BEIR benchmark. https://github.com/arthur-75/Rational-Retrieval-Acts
Statistical Deficiency for Task Inclusion Estimation
Mar 07, 2025Tasks are central in machine learning, as they are the most natural objects to assess the capabilities of current models. The trend is to build general models able to address any task. Even though transfer learning and multitask learning try to leverage the underlying task space, no well-founded tools are available to study its structure. This study proposes a theoretically grounded setup to define the notion of task and to compute the {\bf inclusion} between two tasks from a statistical deficiency point of view. We propose a tractable proxy as information sufficiency to estimate the degree of inclusion between tasks, show its soundness on synthetic data, and use it to reconstruct empirically the classic NLP pipeline.
Membership Inference Risks in Quantized Models: A Theoretical and Empirical Study
Feb 10, 2025



Quantizing machine learning models has demonstrated its effectiveness in lowering memory and inference costs while maintaining performance levels comparable to the original models. In this work, we investigate the impact of quantization procedures on the privacy of data-driven models, specifically focusing on their vulnerability to membership inference attacks. We derive an asymptotic theoretical analysis of Membership Inference Security (MIS), characterizing the privacy implications of quantized algorithm weights against the most powerful (and possibly unknown) attacks. Building on these theoretical insights, we propose a novel methodology to empirically assess and rank the privacy levels of various quantization procedures. Using synthetic datasets, we demonstrate the effectiveness of our approach in assessing the MIS of different quantizers. Furthermore, we explore the trade-off between privacy and performance using real-world data and models in the context of molecular modeling.