 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sensing-Assisted Communication in Vehicular Networks with Intelligent Surface
Dec 11, 2022
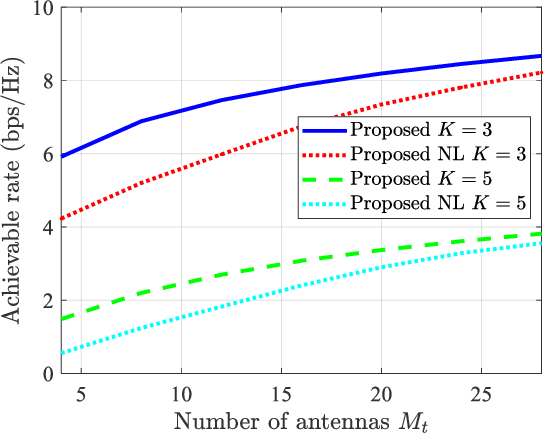
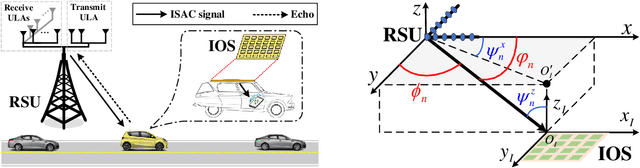
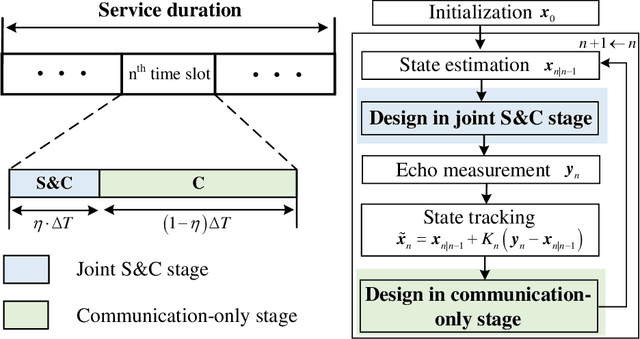
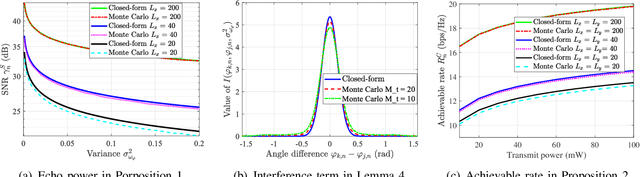
The recent development of integrated sensing and communications (ISAC) technology offers new opportunities to meet high-throughput and low-latency communication as well as high-resolution localization requirements in vehicular networks. However, considering the limited transmit power of the road site units (RSUs) and the relatively small radar cross section (RCS) of vehicles with random reflection coefficients, the power of echo signals may be too weak to be utilized for effective target detection and tracking. Moreover, high-frequency signals usually suffer from large fading loss when penetrating vehicles, which seriously degrades the quality of communication services inside the vehicles. To handle this issue, we propose a novel sensing-assisted communication mechanism by employing an intelligent omni-surface (IOS) on the surface of vehicles to enhance both sensing and communication (S&C) performance. To this end, we first propose a two-stage ISAC protocol, including the joint S&C stage and the communication-only stage, to fulfill more efficient communication performance improvements benefited from sensing. The achievable communication rate maximization problem is formulated by jointly optimizing the transmit beamforming, the IOS phase shifts, and the duration of the joint S&C stage. However, solving this ISAC optimization problem is highly non-trivial since inaccurate estimation and measurement information renders the achievable rate lack of closed-form expression. To handle this issue, we first derive a closed-form expression of the achievable rate under uncertain location information, and then unveil a sufficient and necessary condition for the existence of the joint S&C stage to offer useful insights for practical system design. Moreover, two typical scenarios including interference-limited and noise-limited cases are analyzed.
Not Just Plain Text! Fuel Document-Level Relation Extraction with Explicit Syntax Refinement and Subsentence Modeling
Nov 10, 2022

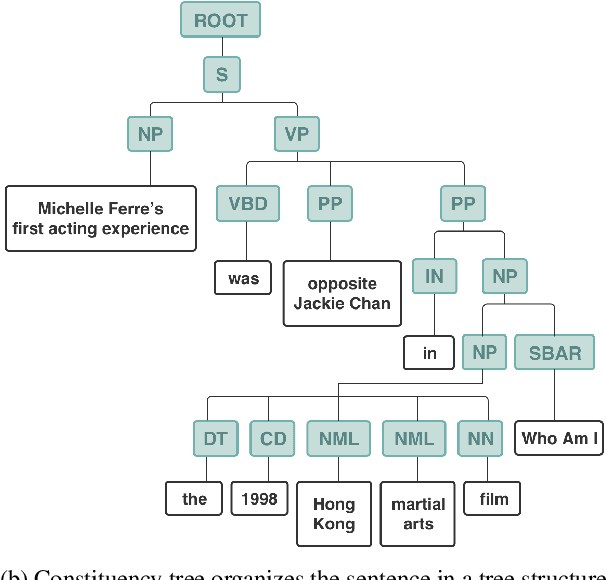
Document-level relation extraction (DocRE) aims to identify semantic labels among entities within a single document. One major challenge of DocRE is to dig decisive details regarding a specific entity pair from long text. However, in many cases, only a fraction of text carries required information, even in the manually labeled supporting evidence. To better capture and exploit instructive information, we propose a novel expLicit syntAx Refinement and Subsentence mOdeliNg based framework (LARSON). By introducing extra syntactic information, LARSON can model subsentences of arbitrary granularity and efficiently screen instructive ones. Moreover, we incorporate refined syntax into text representations which further improves the performance of LARSON. Experimental results on three benchmark datasets (DocRED, CDR, and GDA) demonstrate that LARSON significantly outperforms existing methods.
MECCH: Metapath Context Convolution-based Heterogeneous Graph Neural Networks
Nov 23, 2022

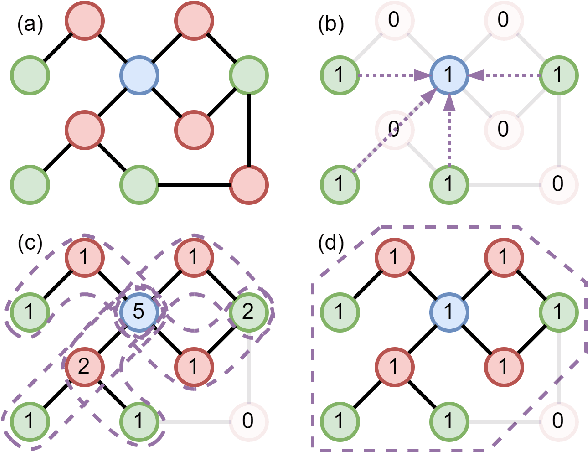

Heterogeneous graph neural networks (HGNNs) were proposed for representation learning on structural data with multiple types of nodes and edges. Researchers have developed metapath-based HGNNs to deal with the over-smoothing problem of relation-based HGNNs. However, existing metapath-based models suffer from either information loss or high computation costs. To address these problems, we design a new Metapath Context Convolution-based Heterogeneous Graph Neural Network (MECCH). Specifically, MECCH applies three novel components after feature preprocessing to extract comprehensive information from the input graph efficiently: (1) metapath context construction, (2) metapath context encoder, and (3) convolutional metapath fusion. Experiments on five real-world heterogeneous graph datasets for node classification and link prediction show that MECCH achieves superior prediction accuracy compared with state-of-the-art baselines with improved computational efficiency.
Morphology-based non-rigid registration of coronary computed tomography and intravascular images through virtual catheter path optimization
Dec 30, 2022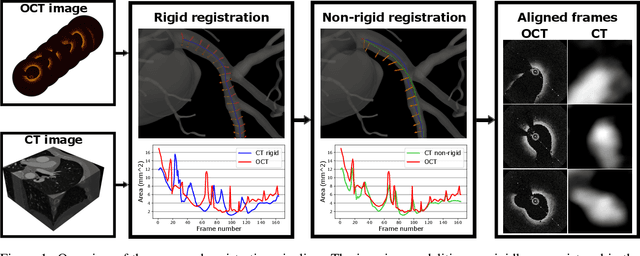

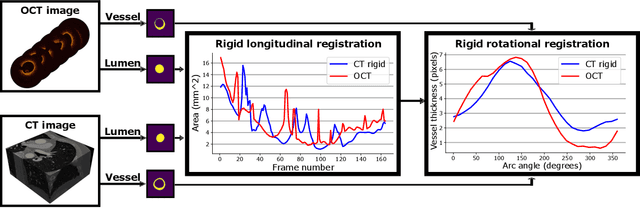
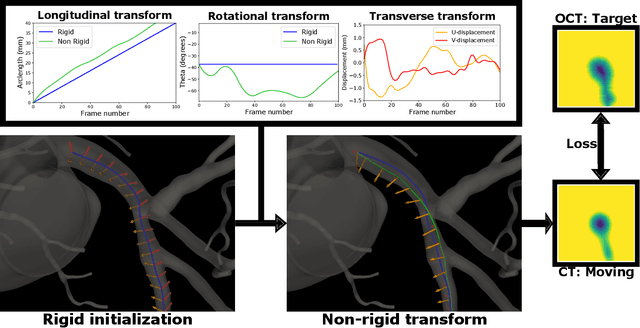
Coronary Computed Tomography Angiography (CCTA) provides information on the presence, extent, and severity of obstructive coronary artery disease. Large-scale clinical studies analyzing CCTA-derived metrics typically require ground-truth validation in the form of high-fidelity 3D intravascular imaging. However, manual rigid alignment of intravascular images to corresponding CCTA images is both time consuming and user-dependent. Moreover, intravascular modalities suffer from several non-rigid motion-induced distortions arising from distortions in the imaging catheter path. To address these issues, we here present a semi-automatic segmentation-based framework for both rigid and non-rigid matching of intravascular images to CCTA images. We formulate the problem in terms of finding the optimal \emph{virtual catheter path} that samples the CCTA data to recapitulate the coronary artery morphology found in the intravascular image. We validate our co-registration framework on a cohort of $n=40$ patients using bifurcation landmarks as ground truth for longitudinal and rotational registration. Our results indicate that our non-rigid registration significantly outperforms other co-registration approaches for luminal bifurcation alignment in both longitudinal (mean mismatch: 3.3 frames) and rotational directions (mean mismatch: 28.6 degrees). By providing a differentiable framework for automatic multi-modal intravascular data fusion, our developed co-registration modules significantly reduces the manual effort required to conduct large-scale multi-modal clinical studies while also providing a solid foundation for the development of machine learning-based co-registration approaches.
Heterogeneous Information Network based Default Analysis on Banking Micro and Small Enterprise Users
May 02, 2022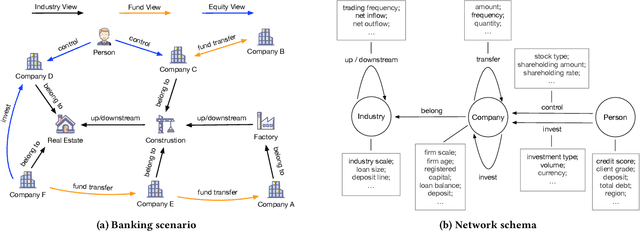
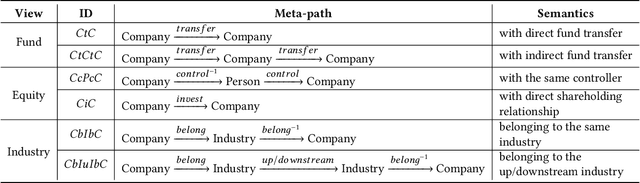

Risk assessment is a substantial problem for financial institutions that has been extensively studied both for its methodological richness and its various practical applications. With the expansion of inclusive finance, recent attentions are paid to micro and small-sized enterprises (MSEs). Compared with large companies, MSEs present a higher exposure rate to default owing to their insecure financial stability. Conventional efforts learn classifiers from historical data with elaborate feature engineering. However, the main obstacle for MSEs involves severe deficiency in credit-related information, which may degrade the performance of prediction. Besides, financial activities have diverse explicit and implicit relations, which have not been fully exploited for risk judgement in commercial banks. In particular, the observations on real data show that various relationships between company users have additional power in financial risk analysis. In this paper, we consider a graph of banking data, and propose a novel HIDAM model for the purpose. Specifically, we attempt to incorporate heterogeneous information network with rich attributes on multi-typed nodes and links for modeling the scenario of business banking service. To enhance feature representation of MSEs, we extract interactive information through meta-paths and fully exploit path information. Furthermore, we devise a hierarchical attention mechanism respectively to learn the importance of contents inside each meta-path and the importance of different metapahs. Experimental results verify that HIDAM outperforms state-of-the-art competitors on real-world banking data.
Search Behavior Prediction: A Hypergraph Perspective
Nov 29, 2022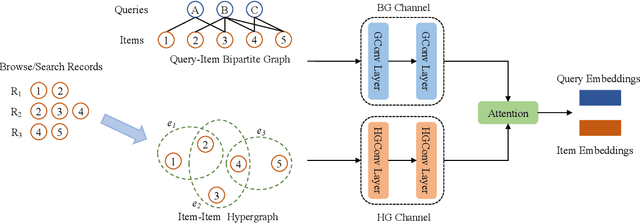
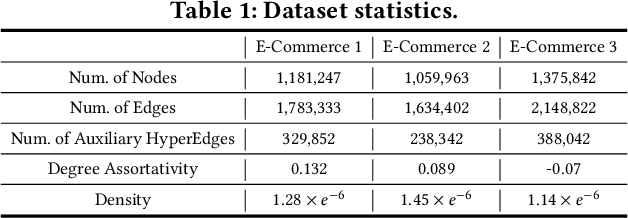
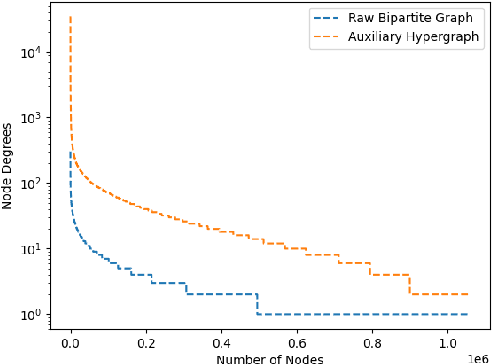
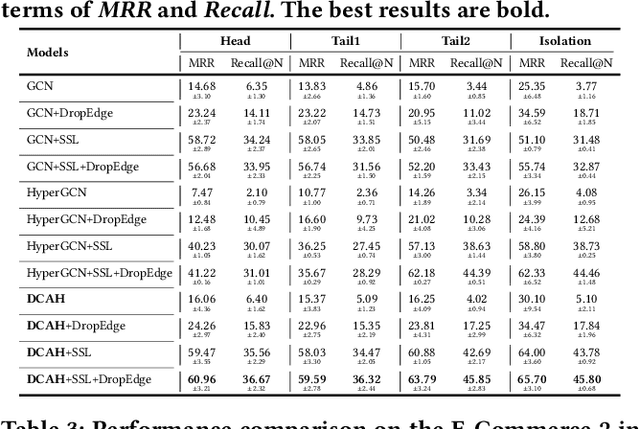
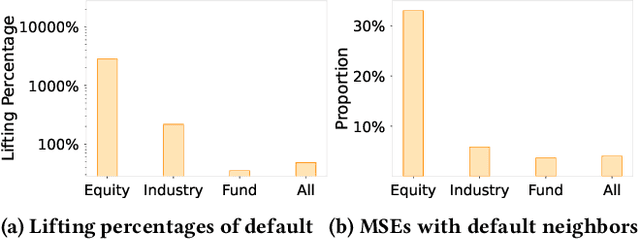
Although the bipartite shopping graphs are straightforward to model search behavior, they suffer from two challenges: 1) The majority of items are sporadically searched and hence have noisy/sparse query associations, leading to a \textit{long-tail} distribution. 2) Infrequent queries are more likely to link to popular items, leading to another hurdle known as \textit{disassortative mixing}. To address these two challenges, we go beyond the bipartite graph to take a hypergraph perspective, introducing a new paradigm that leverages \underline{auxiliary} information from anonymized customer engagement sessions to assist the \underline{main task} of query-item link prediction. This auxiliary information is available at web scale in the form of search logs. We treat all items appearing in the same customer session as a single hyperedge. The hypothesis is that items in a customer session are unified by a common shopping interest. With these hyperedges, we augment the original bipartite graph into a new \textit{hypergraph}. We develop a \textit{\textbf{D}ual-\textbf{C}hannel \textbf{A}ttention-Based \textbf{H}ypergraph Neural Network} (\textbf{DCAH}), which synergizes information from two potentially noisy sources (original query-item edges and item-item hyperedges). In this way, items on the tail are better connected due to the extra hyperedges, thereby enhancing their link prediction performance. We further integrate DCAH with self-supervised graph pre-training and/or DropEdge training, both of which effectively alleviate disassortative mixing. Extensive experiments on three proprietary E-Commerce datasets show that DCAH yields significant improvements of up to \textbf{24.6\% in mean reciprocal rank (MRR)} and \textbf{48.3\% in recall} compared to GNN-based baselines. Our source code is available at \url{https://github.com/amazon-science/dual-channel-hypergraph-neural-network}.
GENIE: Large Scale Pre-training for Text Generation with Diffusion Model
Dec 22, 2022
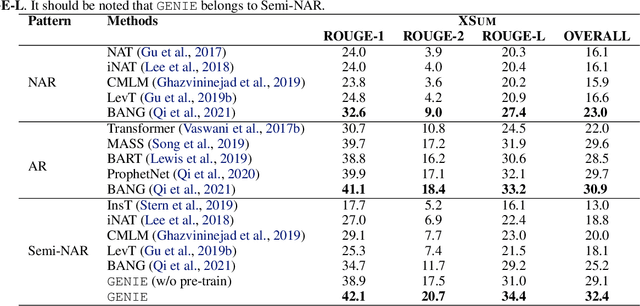

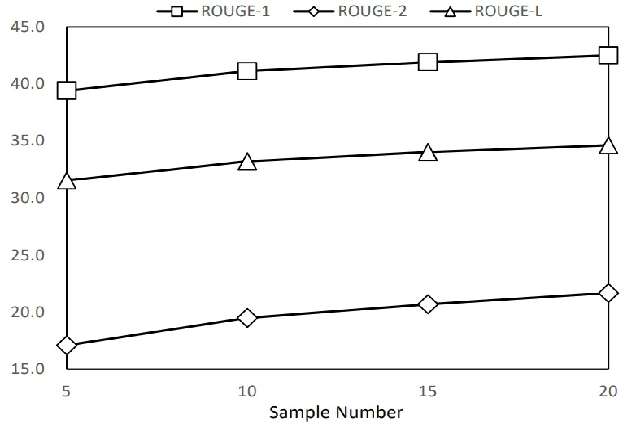
In this paper, we propose a large-scale language pre-training for text GENeration using dIffusion modEl, which is named GENIE. GENIE is a pre-training sequence-to-sequence text generation model which combines Transformer and diffusion. The diffusion model accepts the latent information from the encoder, which is used to guide the denoising of the current time step. After multiple such denoise iterations, the diffusion model can restore the Gaussian noise to the diverse output text which is controlled by the input text. Moreover, such architecture design also allows us to adopt large scale pre-training on the GENIE. We propose a novel pre-training method named continuous paragraph denoise based on the characteristics of the diffusion model. Extensive experiments on the XSum, CNN/DailyMail, and Gigaword benchmarks shows that GENIE can achieves comparable performance with various strong baselines, especially after pre-training, the generation quality of GENIE is greatly improved. We have also conduct a lot of experiments on the generation diversity and parameter impact of GENIE. The code for GENIE will be made publicly available.
Coded Illumination for 3D Lensless Imaging
Dec 22, 2022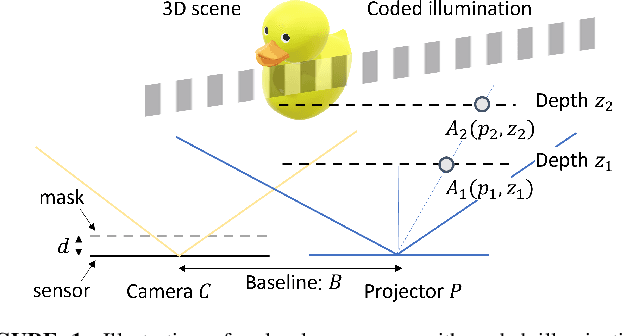
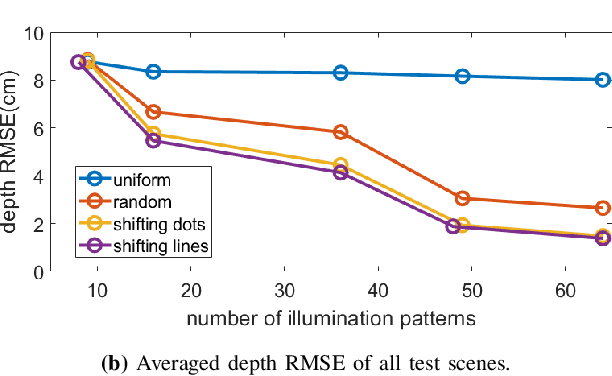
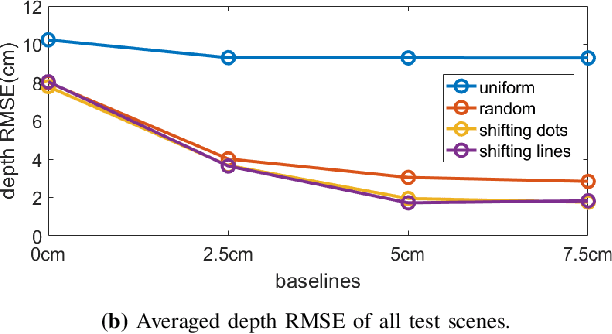
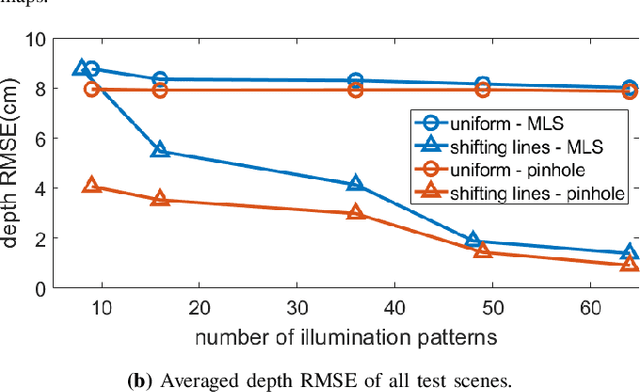
Mask-based lensless cameras offer a novel design for imaging systems by replacing the lens in a conventional camera with a layer of coded mask. Each pixel of the lensless camera encodes the information of the entire 3D scene. Existing methods for 3D reconstruction from lensless measurements suffer from poor spatial and depth resolution. This is partially due to the system ill conditioning that arises because the point-spread functions (PSFs) from different depth planes are very similar. In this paper, we propose to capture multiple measurements of the scene under a sequence of coded illumination patterns to improve the 3D image reconstruction quality. In addition, we put the illumination source at a distance away from the camera. With such baseline distance between the lensless camera and illumination source, the camera observes a slice of the 3D volume, and the PSF of each depth plane becomes more resolvable from each other. We present simulation results along with experimental results with a camera prototype to demonstrate the effectiveness of our approach.
A machine learning framework for neighbor generation in metaheuristic search
Dec 22, 2022

This paper presents a methodology for integrating machine learning techniques into metaheuristics for solving combinatorial optimization problems. Namely, we propose a general machine learning framework for neighbor generation in metaheuristic search. We first define an efficient neighborhood structure constructed by applying a transformation to a selected subset of variables from the current solution. Then, the key of the proposed methodology is to generate promising neighbors by selecting a proper subset of variables that contains a descent of the objective in the solution space. To learn a good variable selection strategy, we formulate the problem as a classification task that exploits structural information from the characteristics of the problem and from high-quality solutions. We validate our methodology on two metaheuristic applications: a Tabu Search scheme for solving a Wireless Network Optimization problem and a Large Neighborhood Search heuristic for solving Mixed-Integer Programs. The experimental results show that our approach is able to achieve a satisfactory trade-off between the exploration of a larger solution space and the exploitation of high-quality solution regions on both applications.
Large-Scale Traffic Signal Control by a Nash Deep Q-network Approach
Jan 02, 2023
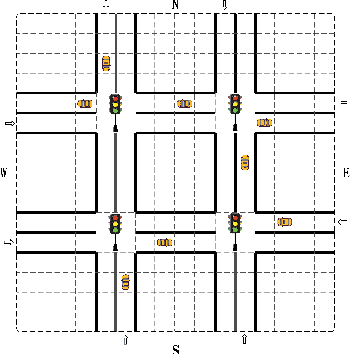
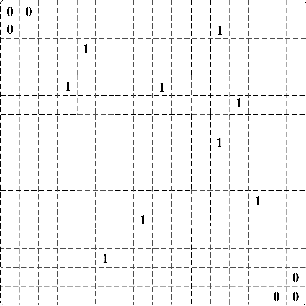
Reinforcement Learning (RL) is currently one of the most commonly used techniques for traffic signal control (TSC), which can adaptively adjusted traffic signal phase and duration according to real-time traffic data. However, a fully centralized RL approach is beset with difficulties in a multi-network scenario because of exponential growth in state-action space with increasing intersections. Multi-agent reinforcement learning (MARL) can overcome the high-dimension problem by employing the global control of each local RL agent, but it also brings new challenges, such as the failure of convergence caused by the non-stationary Markov Decision Process (MDP). In this paper, we introduce an off-policy nash deep Q-Network (OPNDQN) algorithm, which mitigates the weakness of both fully centralized and MARL approaches. The OPNDQN algorithm solves the problem that traditional algorithms cannot be used in large state-action space traffic models by utilizing a fictitious game approach at each iteration to find the nash equilibrium among neighboring intersections, from which no intersection has incentive to unilaterally deviate. One of main advantages of OPNDQN is to mitigate the non-stationarity of multi-agent Markov process because it considers the mutual influence among neighboring intersections by sharing their actions. On the other hand, for training a large traffic network, the convergence rate of OPNDQN is higher than that of existing MARL approaches because it does not incorporate all state information of each agent. We conduct an extensive experiments by using Simulation of Urban MObility simulator (SUMO), and show the dominant superiority of OPNDQN over several existing MARL approaches in terms of average queue length, episode training reward and average waiting time.