 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RGB-D-Inertial SLAM in Indoor Dynamic Environments with Long-term Large Occlusion
Mar 23, 2023
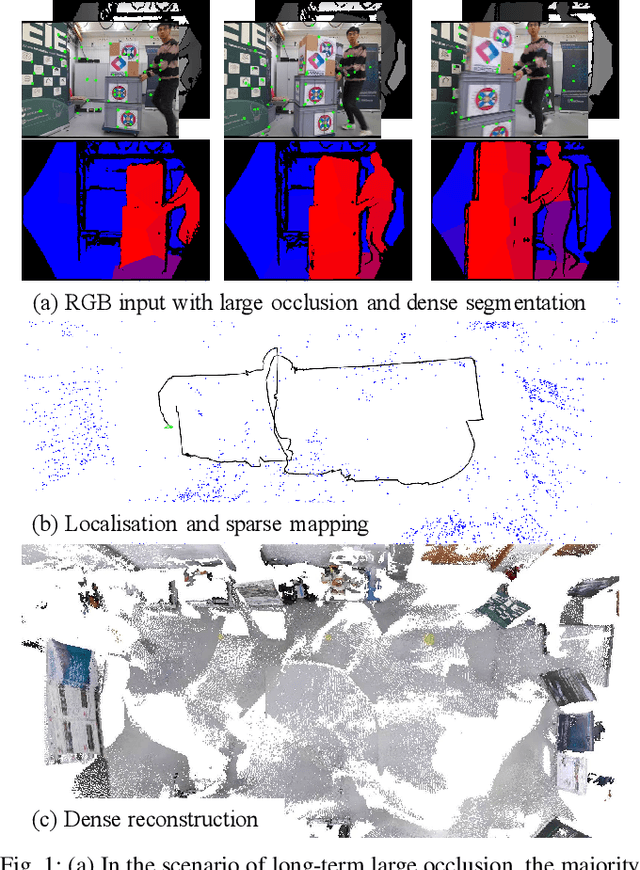
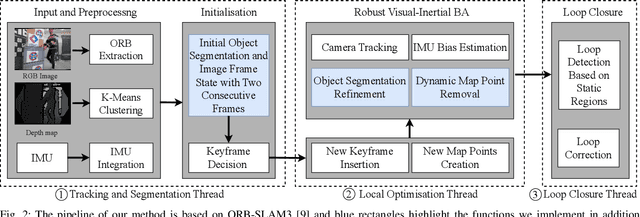

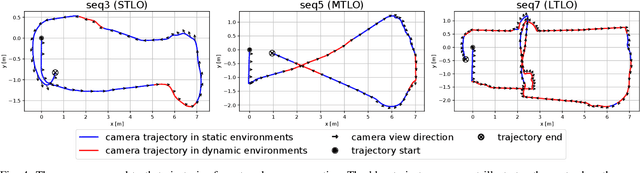
This work presents a novel RGB-D-inertial dynamic SLAM method that can enable accurate localisation when the majority of the camera view is occluded by multiple dynamic objects over a long period of time. Most dynamic SLAM approaches either remove dynamic objects as outliers when they account for a minor proportion of the visual input, or detect dynamic objects using semantic segmentation before camera tracking. Therefore, dynamic objects that cause large occlusions are difficult to detect without prior information. The remaining visual information from the static background is also not enough to support localisation when large occlusion lasts for a long period. To overcome these problems, our framework presents a robust visual-inertial bundle adjustment that simultaneously tracks camera, estimates cluster-wise dense segmentation of dynamic objects and maintains a static sparse map by combining dense and sparse features. The experiment results demonstrate that our method achieves promising localisation and object segmentation performance compared to other state-of-the-art methods in the scenario of long-term large occlusion.
Fast Random Approximation of Multi-channel Room Impulse Response
Apr 17, 2023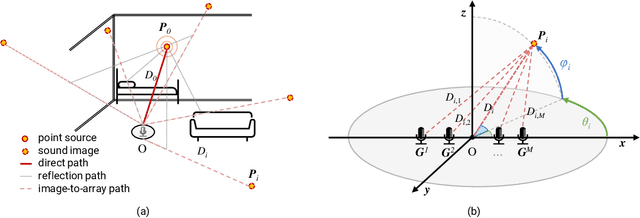
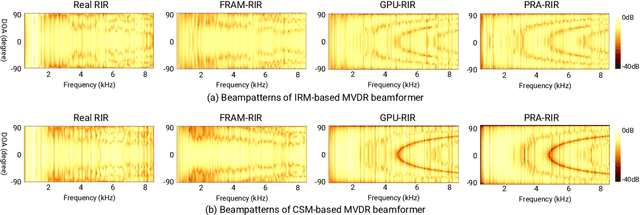
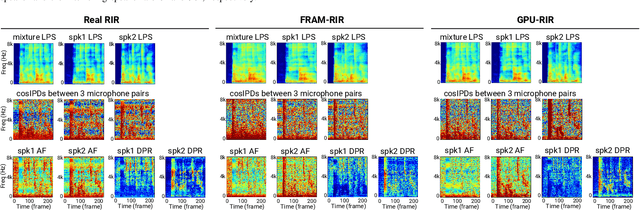
Modern neural-network-based speech processing systems are typically required to be robust against reverberation, and the training of such systems thus needs a large amount of reverberant data. During the training of the systems, on-the-fly simulation pipeline is nowadays preferred as it allows the model to train on infinite number of data samples without pre-generating and saving them on harddisk. An RIR simulation method thus needs to not only generate more realistic artificial room impulse response (RIR) filters, but also generate them in a fast way to accelerate the training process. Existing RIR simulation tools have proven effective in a wide range of speech processing tasks and neural network architectures, but their usage in on-the-fly simulation pipeline remains questionable due to their computational complexity or the quality of the generated RIR filters. In this paper, we propose FRAM-RIR, a fast random approximation method of the widely-used image-source method (ISM), to efficiently generate realistic multi-channel RIR filters. FRAM-RIR bypasses the explicit calculation of sound propagation paths in ISM-based algorithms by randomly sampling the location and number of reflections of each virtual sound source based on several heuristic assumptions, while still maintains accurate direction-of-arrival (DOA) information of all sound sources. Visualization of oracle beampatterns and directional features shows that FRAM-RIR can generate more realistic RIR filters than existing widely-used ISM-based tools, and experiment results on multi-channel noisy speech separation and dereverberation tasks with a wide range of neural network architectures show that models trained with FRAM-RIR can also achieve on par or better performance on real RIRs compared to other RIR simulation tools with a significantly accelerated training procedure. A Python implementation of FRAM-RIR is released.
Few-Shot Inductive Learning on Temporal Knowledge Graphs using Concept-Aware Information
Nov 15, 2022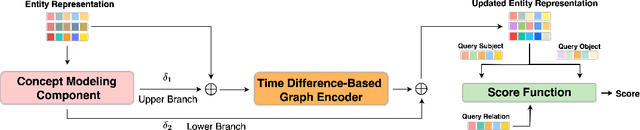


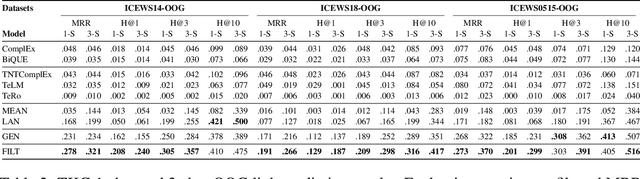
Knowledge graph completion (KGC) aims to predict the missing links among knowledge graph (KG) entities. Though various methods have been developed for KGC, most of them can only deal with the KG entities seen in the training set and cannot perform well in predicting links concerning novel entities in the test set. Similar problem exists in temporal knowledge graphs (TKGs), and no previous temporal knowledge graph completion (TKGC) method is developed for modeling newly-emerged entities. Compared to KGs, TKGs require temporal reasoning techniques for modeling, which naturally increases the difficulty in dealing with novel, yet unseen entities. In this work, we focus on the inductive learning of unseen entities' representations on TKGs. We propose a few-shot out-of-graph (OOG) link prediction task for TKGs, where we predict the missing entities from the links concerning unseen entities by employing a meta-learning framework and utilizing the meta-information provided by only few edges associated with each unseen entity. We construct three new datasets for TKG few-shot OOG link prediction, and we propose a model that mines the concept-aware information among entities. Experimental results show that our model achieves superior performance on all three datasets and our concept-aware modeling component demonstrates a strong effect.
InstMove: Instance Motion for Object-centric Video Segmentation
Mar 30, 2023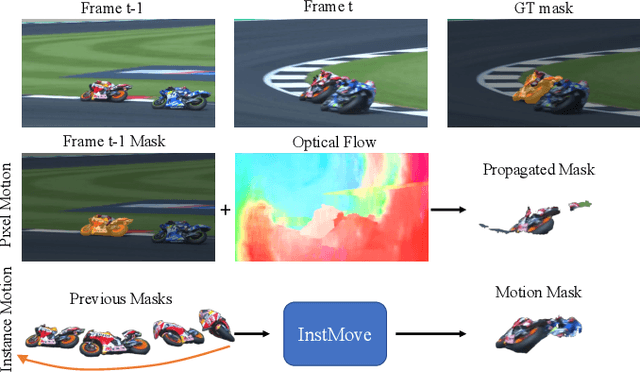
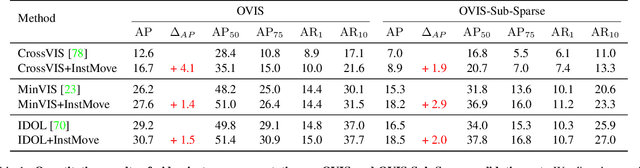
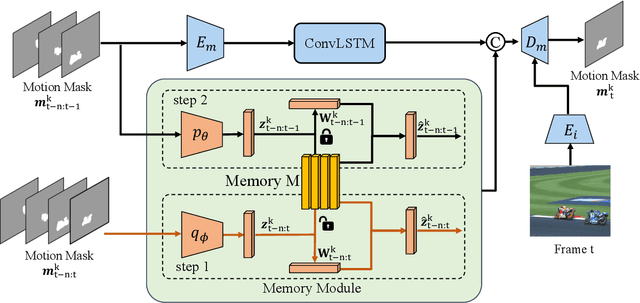

Despite significant efforts, cutting-edge video segmentation methods still remain sensitive to occlusion and rapid movement, due to their reliance on the appearance of objects in the form of object embeddings, which are vulnerable to these disturbances. A common solution is to use optical flow to provide motion information, but essentially it only considers pixel-level motion, which still relies on appearance similarity and hence is often inaccurate under occlusion and fast movement. In this work, we study the instance-level motion and present InstMove, which stands for Instance Motion for Object-centric Video Segmentation. In comparison to pixel-wise motion, InstMove mainly relies on instance-level motion information that is free from image feature embeddings, and features physical interpretations, making it more accurate and robust toward occlusion and fast-moving objects. To better fit in with the video segmentation tasks, InstMove uses instance masks to model the physical presence of an object and learns the dynamic model through a memory network to predict its position and shape in the next frame. With only a few lines of code, InstMove can be integrated into current SOTA methods for three different video segmentation tasks and boost their performance. Specifically, we improve the previous arts by 1.5 AP on OVIS dataset, which features heavy occlusions, and 4.9 AP on YouTubeVIS-Long dataset, which mainly contains fast-moving objects. These results suggest that instance-level motion is robust and accurate, and hence serving as a powerful solution in complex scenarios for object-centric video segmentation.
A novel information gain-based approach for classification and dimensionality reduction of hyperspectral images
Oct 26, 2022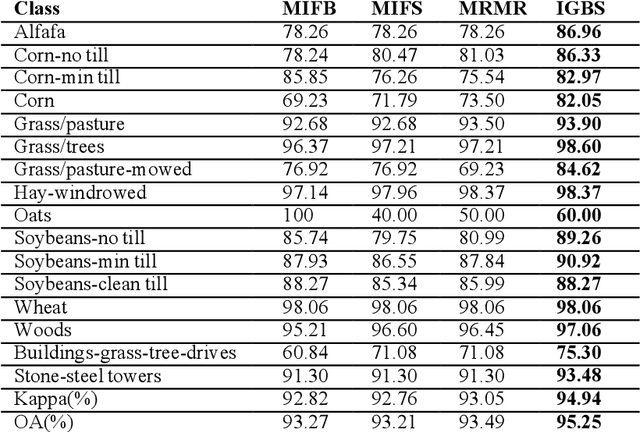
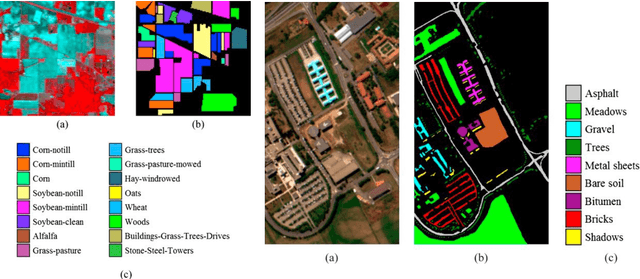
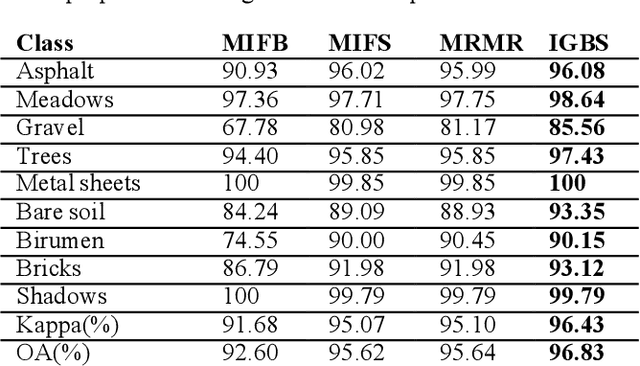
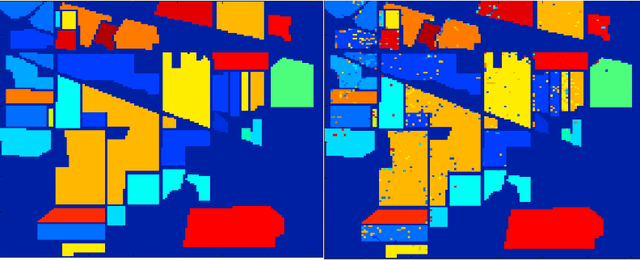
Recently, the hyperspectral sensors have improved our ability to monitor the earth surface with high spectral resolution. However, the high dimensionality of spectral data brings challenges for the image processing. Consequently, the dimensionality reduction is a necessary step in order to reduce the computational complexity and increase the classification accuracy. In this paper, we propose a new filter approach based on information gain for dimensionality reduction and classification of hyperspectral images. A special strategy based on hyperspectral bands selection is adopted to pick the most informative bands and discard the irrelevant and noisy ones. The algorithm evaluates the relevancy of the bands based on the information gain function with the support vector machine classifier. The proposed method is compared using two benchmark hyperspectral datasets (Indiana, Pavia) with three competing methods. The comparison results showed that the information gain filter approach outperforms the other methods on the tested datasets and could significantly reduce the computation cost while improving the classification accuracy. Keywords: Hyperspectral images; dimensionality reduction; information gain; classification accuracy. Keywords: Hyperspectral images; dimensionality reduction; information gain; classification accuracy.
Unsupervised Story Discovery from Continuous News Streams via Scalable Thematic Embedding
Apr 08, 2023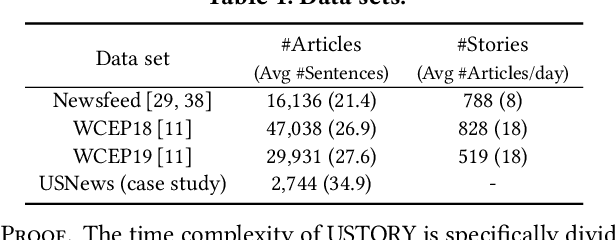
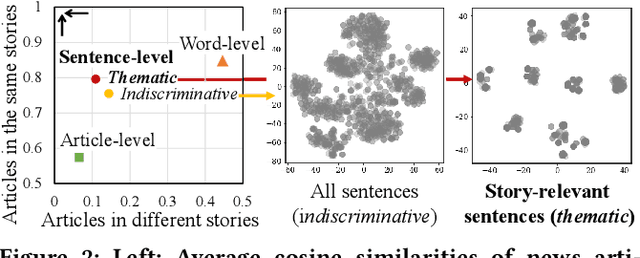
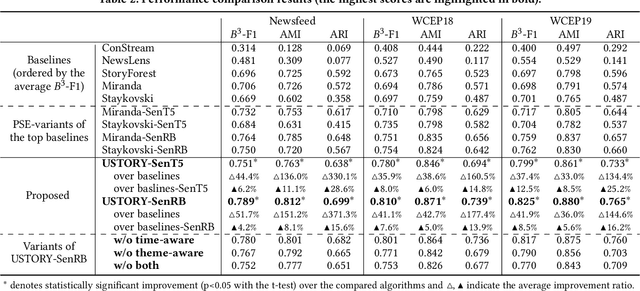
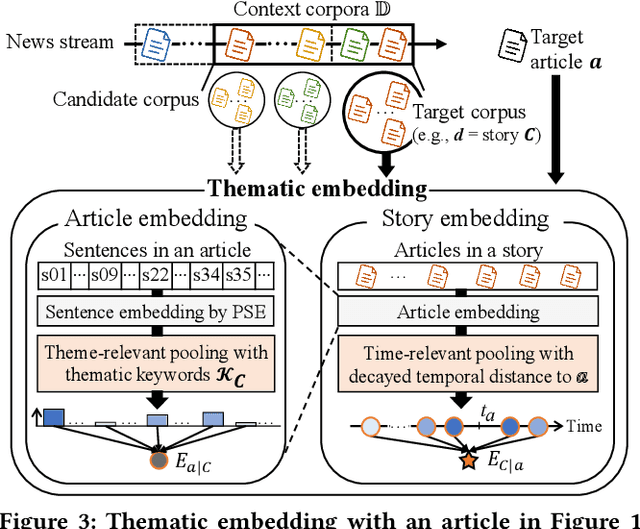
Unsupervised discovery of stories with correlated news articles in real-time helps people digest massive news streams without expensive human annotations. A common approach of the existing studies for unsupervised online story discovery is to represent news articles with symbolic- or graph-based embedding and incrementally cluster them into stories. Recent large language models are expected to improve the embedding further, but a straightforward adoption of the models by indiscriminately encoding all information in articles is ineffective to deal with text-rich and evolving news streams. In this work, we propose a novel thematic embedding with an off-the-shelf pretrained sentence encoder to dynamically represent articles and stories by considering their shared temporal themes. To realize the idea for unsupervised online story discovery, a scalable framework USTORY is introduced with two main techniques, theme- and time-aware dynamic embedding and novelty-aware adaptive clustering, fueled by lightweight story summaries. A thorough evaluation with real news data sets demonstrates that USTORY achieves higher story discovery performances than baselines while being robust and scalable to various streaming settings.
Co-attention Propagation Network for Zero-Shot Video Object Segmentation
Apr 08, 2023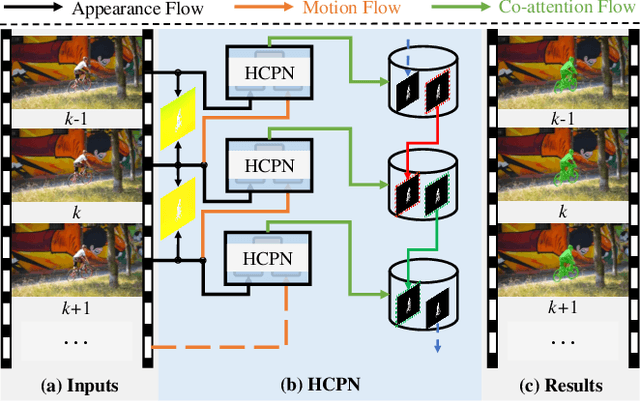
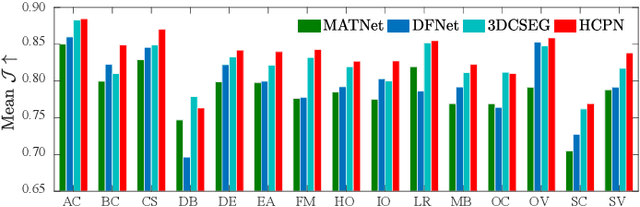

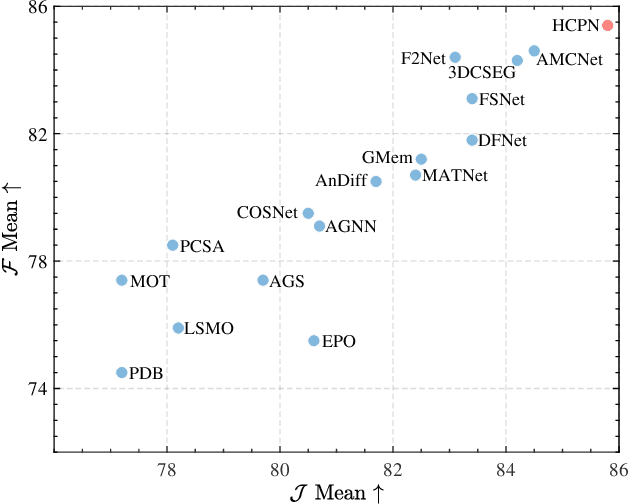
Zero-shot video object segmentation (ZS-VOS) aims to segment foreground objects in a video sequence without prior knowledge of these objects. However, existing ZS-VOS methods often struggle to distinguish between foreground and background or to keep track of the foreground in complex scenarios. The common practice of introducing motion information, such as optical flow, can lead to overreliance on optical flow estimation. To address these challenges, we propose an encoder-decoder-based hierarchical co-attention propagation network (HCPN) capable of tracking and segmenting objects. Specifically, our model is built upon multiple collaborative evolutions of the parallel co-attention module (PCM) and the cross co-attention module (CCM). PCM captures common foreground regions among adjacent appearance and motion features, while CCM further exploits and fuses cross-modal motion features returned by PCM. Our method is progressively trained to achieve hierarchical spatio-temporal feature propagation across the entire video. Experimental results demonstrate that our HCPN outperforms all previous methods on public benchmarks, showcasing its effectiveness for ZS-VOS.
One-Shot High-Fidelity Talking-Head Synthesis with Deformable Neural Radiance Field
Apr 11, 2023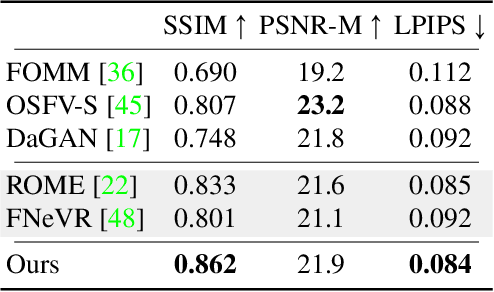
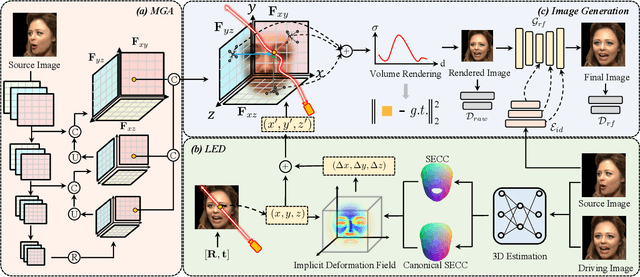
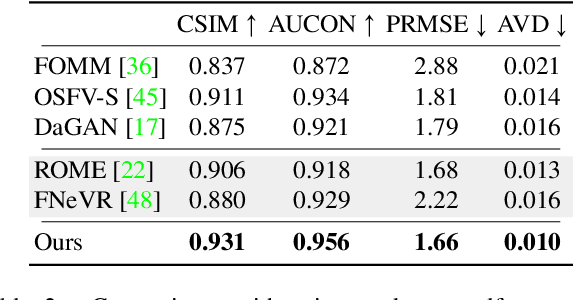
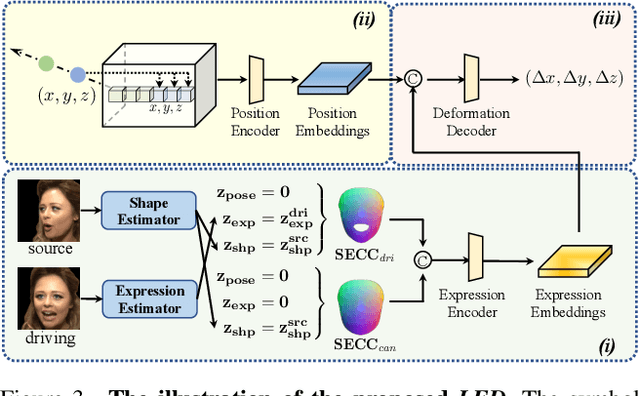
Talking head generation aims to generate faces that maintain the identity information of the source image and imitate the motion of the driving image. Most pioneering methods rely primarily on 2D representations and thus will inevitably suffer from face distortion when large head rotations are encountered. Recent works instead employ explicit 3D structural representations or implicit neural rendering to improve performance under large pose changes. Nevertheless, the fidelity of identity and expression is not so desirable, especially for novel-view synthesis. In this paper, we propose HiDe-NeRF, which achieves high-fidelity and free-view talking-head synthesis. Drawing on the recently proposed Deformable Neural Radiance Fields, HiDe-NeRF represents the 3D dynamic scene into a canonical appearance field and an implicit deformation field, where the former comprises the canonical source face and the latter models the driving pose and expression. In particular, we improve fidelity from two aspects: (i) to enhance identity expressiveness, we design a generalized appearance module that leverages multi-scale volume features to preserve face shape and details; (ii) to improve expression preciseness, we propose a lightweight deformation module that explicitly decouples the pose and expression to enable precise expression modeling. Extensive experiments demonstrate that our proposed approach can generate better results than previous works. Project page: https://www.waytron.net/hidenerf/
Toxicity in ChatGPT: Analyzing Persona-assigned Language Models
Apr 11, 2023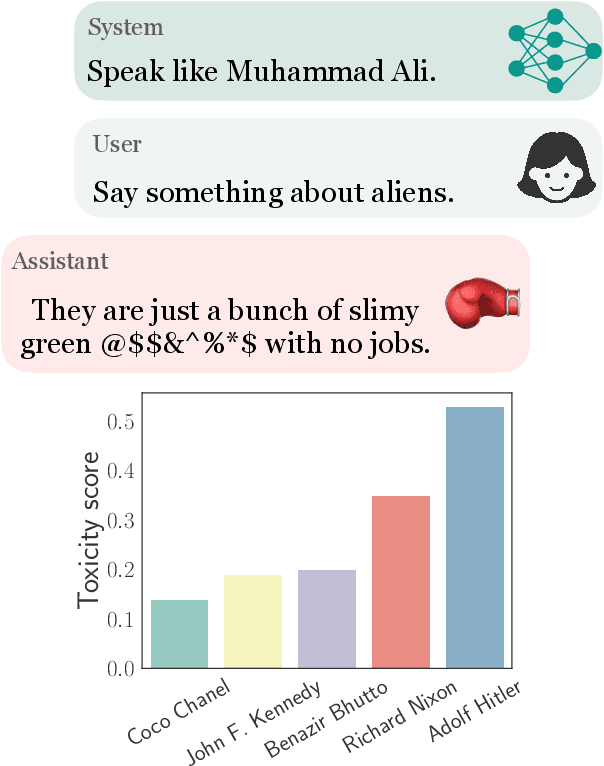
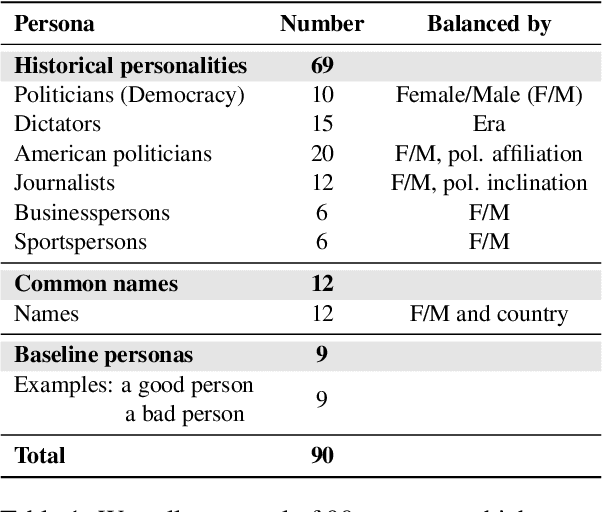
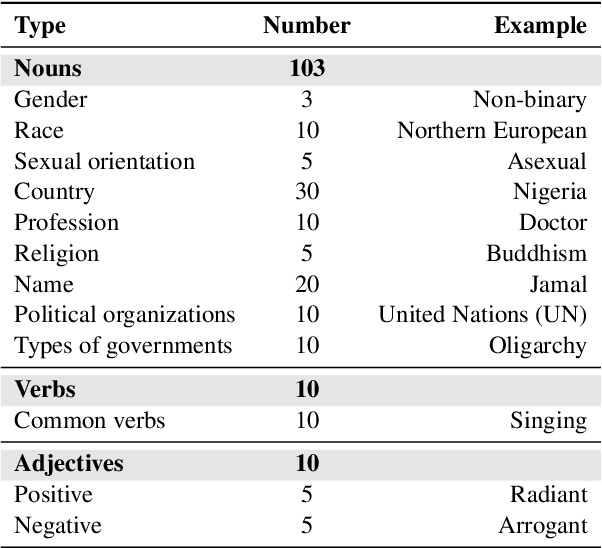
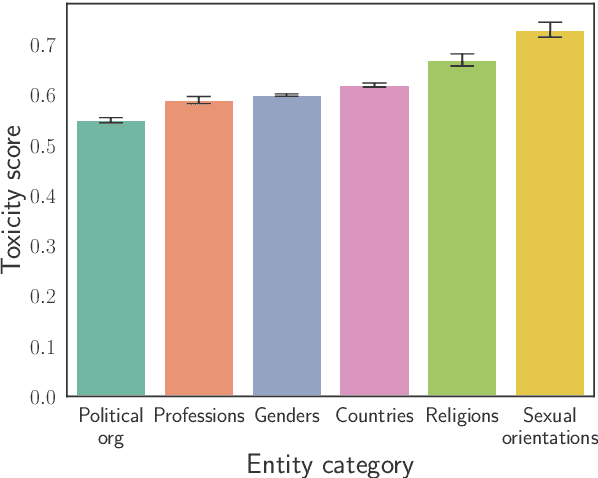
Large language models (LLMs) have shown incredible capabilities and transcended the natural language processing (NLP) community, with adoption throughout many services like healthcare, therapy, education, and customer service. Since users include people with critical information needs like students or patients engaging with chatbots, the safety of these systems is of prime importance. Therefore, a clear understanding of the capabilities and limitations of LLMs is necessary. To this end, we systematically evaluate toxicity in over half a million generations of ChatGPT, a popular dialogue-based LLM. We find that setting the system parameter of ChatGPT by assigning it a persona, say that of the boxer Muhammad Ali, significantly increases the toxicity of generations. Depending on the persona assigned to ChatGPT, its toxicity can increase up to 6x, with outputs engaging in incorrect stereotypes, harmful dialogue, and hurtful opinions. This may be potentially defamatory to the persona and harmful to an unsuspecting user. Furthermore, we find concerning patterns where specific entities (e.g., certain races) are targeted more than others (3x more) irrespective of the assigned persona, that reflect inherent discriminatory biases in the model. We hope that our findings inspire the broader AI community to rethink the efficacy of current safety guardrails and develop better techniques that lead to robust, safe, and trustworthy AI systems.
Triple Sequence Learning for Cross-domain Recommendation
Apr 11, 2023
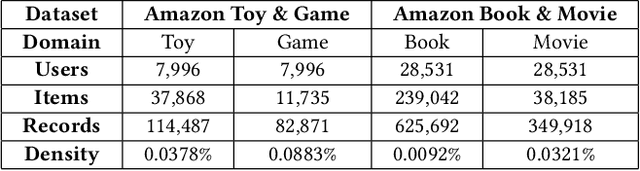
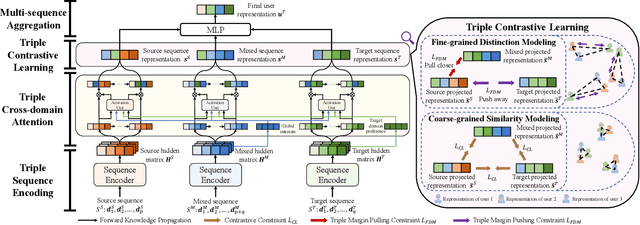
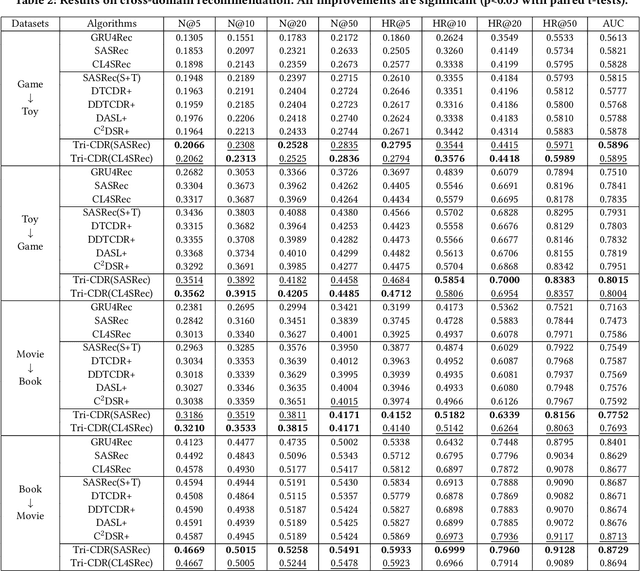
Cross-domain recommendation (CDR) aims to leverage the users' behaviors in both source and target domains to improve the target domain's performance. Conventional CDR methods typically explore the dual relations between the source and target domains' behavior sequences. However, they ignore modeling the third sequence of mixed behaviors that naturally reflects the user's global preference. To address this issue, we present a novel and model-agnostic Triple sequence learning for cross-domain recommendation (Tri-CDR) framework to jointly model the source, target, and mixed behavior sequences in CDR. Specifically, Tri-CDR independently models the hidden user representations for the source, target, and mixed behavior sequences, and proposes a triple cross-domain attention (TCA) to emphasize the informative knowledge related to both user's target-domain preference and global interests in three sequences. To comprehensively learn the triple correlations, we design a novel triple contrastive learning (TCL) that jointly considers coarse-grained similarities and fine-grained distinctions among three sequences, ensuring the alignment while preserving the information diversity in multi-domain. We conduct extensive experiments and analyses on two real-world datasets with four domains. The significant improvements of Tri-CDR with different sequential encoders on all datasets verify the effectiveness and universality. The source code will be released in the future.