 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AutoRE: Document-Level Relation Extraction with Large Language Models
Mar 21, 2024
Large Language Models (LLMs) have demonstrated exceptional abilities in comprehending and generating text, motivating numerous researchers to utilize them for Information Extraction (IE) purposes, including Relation Extraction (RE). Nonetheless, most existing methods are predominantly designed for Sentence-level Relation Extraction (SentRE) tasks, which typically encompass a restricted set of relations and triplet facts within a single sentence. Furthermore, certain approaches resort to treating relations as candidate choices integrated into prompt templates, leading to inefficient processing and suboptimal performance when tackling Document-Level Relation Extraction (DocRE) tasks, which entail handling multiple relations and triplet facts distributed across a given document, posing distinct challenges. To overcome these limitations, we introduce AutoRE, an end-to-end DocRE model that adopts a novel RE extraction paradigm named RHF (Relation-Head-Facts). Unlike existing approaches, AutoRE does not rely on the assumption of known relation options, making it more reflective of real-world scenarios. Additionally, we have developed an easily extensible RE framework using a Parameters Efficient Fine Tuning (PEFT) algorithm (QLoRA). Our experiments on the RE-DocRED dataset showcase AutoRE's best performance, achieving state-of-the-art results, surpassing TAG by 10.03% and 9.03% respectively on the dev and test set.
WeatherProof: Leveraging Language Guidance for Semantic Segmentation in Adverse Weather
Mar 21, 2024We propose a method to infer semantic segmentation maps from images captured under adverse weather conditions. We begin by examining existing models on images degraded by weather conditions such as rain, fog, or snow, and found that they exhibit a large performance drop as compared to those captured under clear weather. To control for changes in scene structures, we propose WeatherProof, the first semantic segmentation dataset with accurate clear and adverse weather image pairs that share an underlying scene. Through this dataset, we analyze the error modes in existing models and found that they were sensitive to the highly complex combination of different weather effects induced on the image during capture. To improve robustness, we propose a way to use language as guidance by identifying contributions of adverse weather conditions and injecting that as "side information". Models trained using our language guidance exhibit performance gains by up to 10.2% in mIoU on WeatherProof, up to 8.44% in mIoU on the widely used ACDC dataset compared to standard training techniques, and up to 6.21% in mIoU on the ACDC dataset as compared to previous SOTA methods.
A LiDAR-Aided Channel Model for Vehicular Intelligent Sensing-Communication Integration
Mar 21, 2024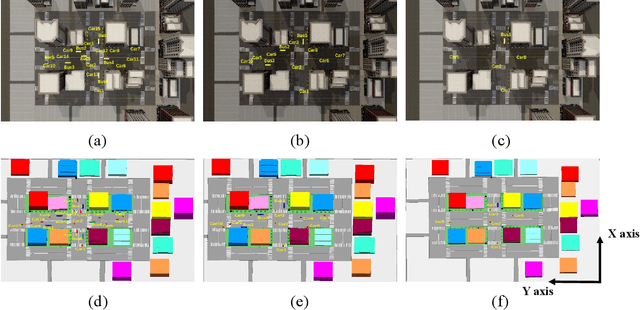
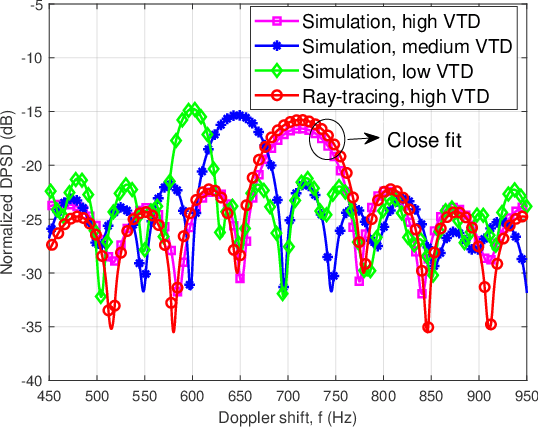
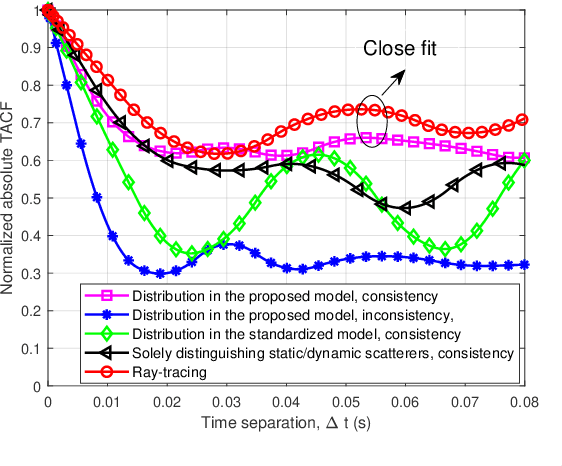
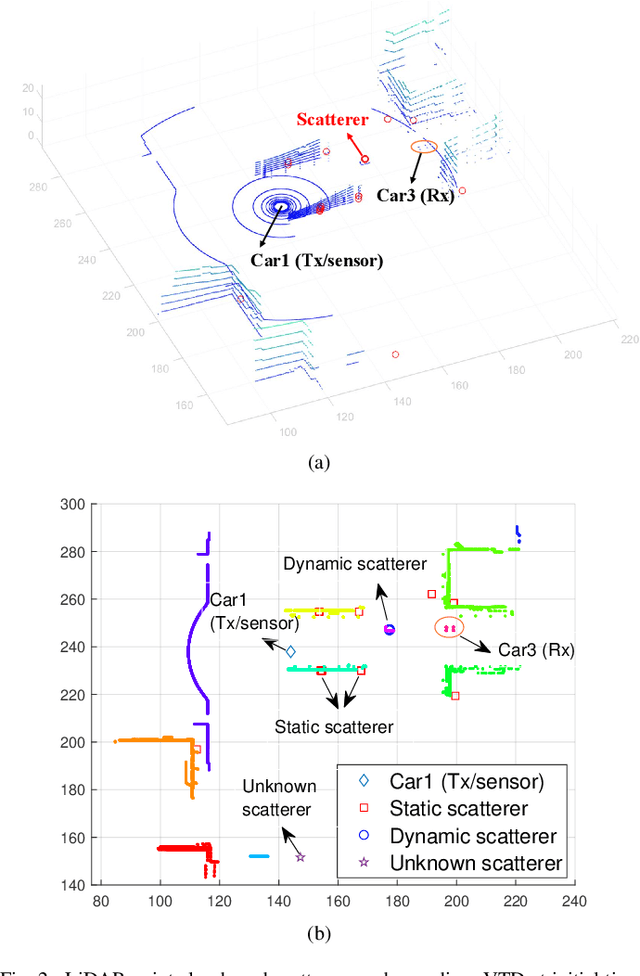
In this paper, a novel channel modeling approach, named light detection and ranging (LiDAR)-aided geometry-based stochastic modeling (LA-GBSM), is developed. Based on the developed LA-GBSM approach, a new millimeter wave (mmWave) channel model for sixth-generation (6G) vehicular intelligent sensing-communication integration is proposed, which can support the design of intelligent transportation systems (ITSs). The proposed LA-GBSM is accurately parameterized under high, medium, and low vehicular traffic density (VTD) conditions via a sensing-communication simulation dataset with LiDAR point clouds and scatterer information for the first time. Specifically, by detecting dynamic vehicles and static building/tress through LiDAR point clouds via machine learning, scatterers are divided into static and dynamic scatterers. Furthermore, statistical distributions of parameters, e.g., distance, angle, number, and power, related to static and dynamic scatterers are quantified under high, medium, and low VTD conditions. To mimic channel non-stationarity and consistency, based on the quantified statistical distributions, a new visibility region (VR)-based algorithm in consideration of newly generated static/dynamic scatterers is developed. Key channel statistics are derived and simulated. By comparing simulation results and ray-tracing (RT)-based results, the utility of the proposed LA-GBSM is verified.
ViTGaze: Gaze Following with Interaction Features in Vision Transformers
Mar 19, 2024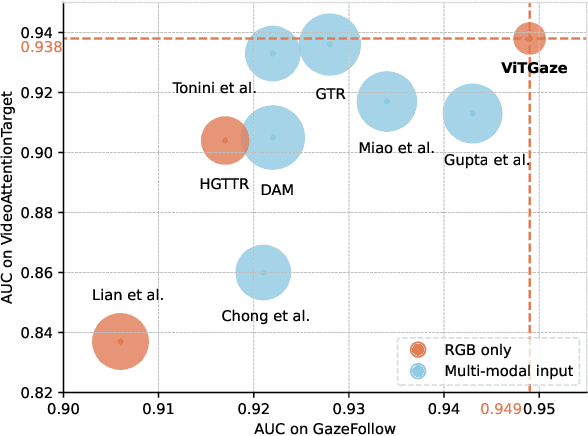
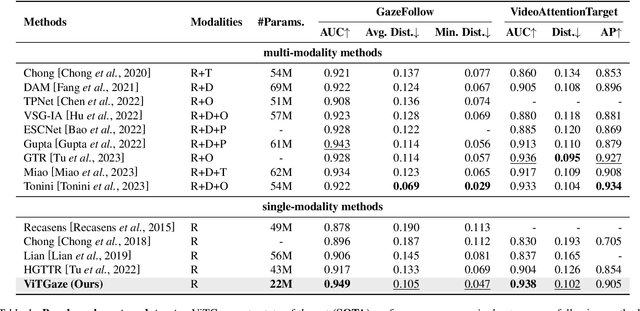
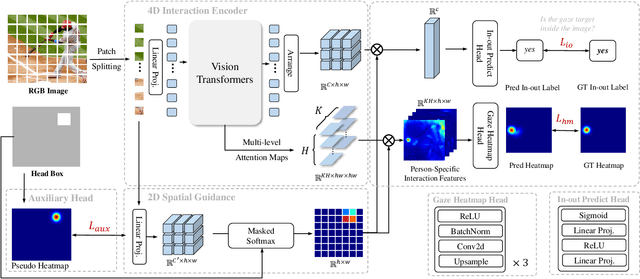
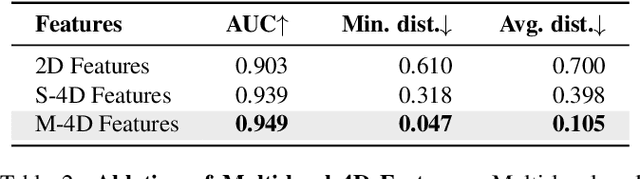
Gaze following aims to interpret human-scene interactions by predicting the person's focal point of gaze. Prevailing approaches often use multi-modality inputs, most of which adopt a two-stage framework. Hence their performance highly depends on the previous prediction accuracy. Others use a single-modality approach with complex decoders, increasing network computational load. Inspired by the remarkable success of pre-trained plain Vision Transformers (ViTs), we introduce a novel single-modality gaze following framework, ViTGaze. In contrast to previous methods, ViTGaze creates a brand new gaze following framework based mainly on powerful encoders (dec. param. less than 1%). Our principal insight lies in that the inter-token interactions within self-attention can be transferred to interactions between humans and scenes. Leveraging this presumption, we formulate a framework consisting of a 4D interaction encoder and a 2D spatial guidance module to extract human-scene interaction information from self-attention maps. Furthermore, our investigation reveals that ViT with self-supervised pre-training exhibits an enhanced ability to extract correlated information. A large number of experiments have been conducted to demonstrate the performance of the proposed method. Our method achieves state-of-the-art (SOTA) performance among all single-modality methods (3.4% improvement on AUC, 5.1% improvement on AP) and very comparable performance against multi-modality methods with 59% number of parameters less.
Efficient scene text image super-resolution with semantic guidance
Mar 20, 2024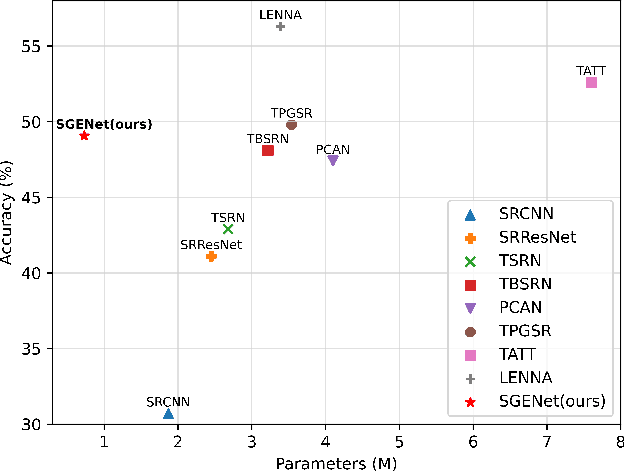
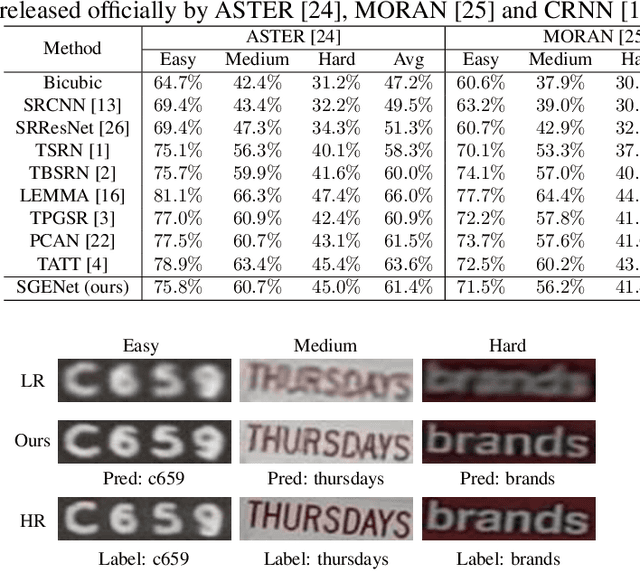
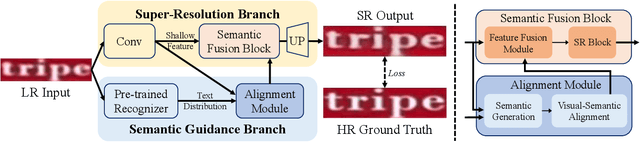
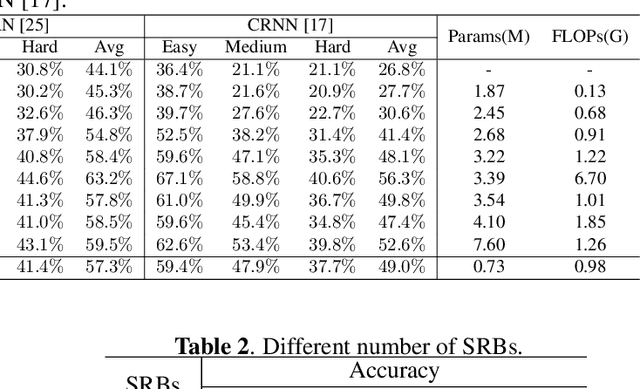
Scene text image super-resolution has significantly improved the accuracy of scene text recognition. However, many existing methods emphasize performance over efficiency and ignore the practical need for lightweight solutions in deployment scenarios. Faced with the issues, our work proposes an efficient framework called SGENet to facilitate deployment on resource-limited platforms. SGENet contains two branches: super-resolution branch and semantic guidance branch. We apply a lightweight pre-trained recognizer as a semantic extractor to enhance the understanding of text information. Meanwhile, we design the visual-semantic alignment module to achieve bidirectional alignment between image features and semantics, resulting in the generation of highquality prior guidance. We conduct extensive experiments on benchmark dataset, and the proposed SGENet achieves excellent performance with fewer computational costs. Code is available at https://github.com/SijieLiu518/SGENet
CONLINE: Complex Code Generation and Refinement with Online Searching and Correctness Testing
Mar 20, 2024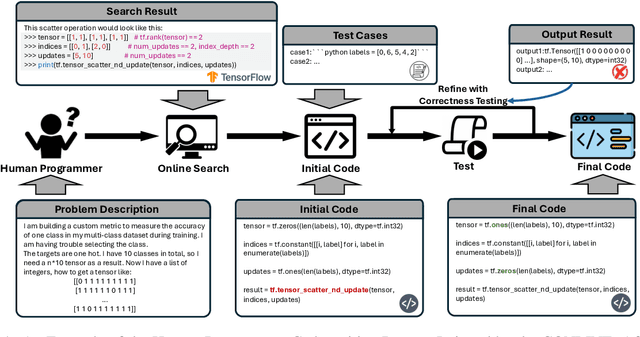
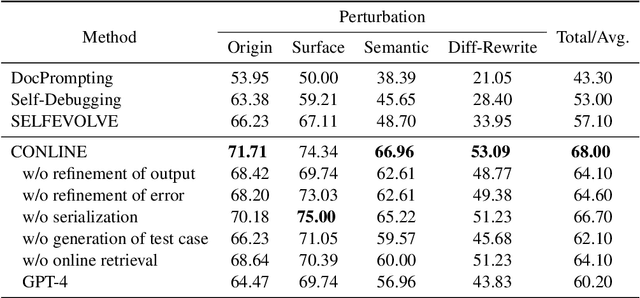
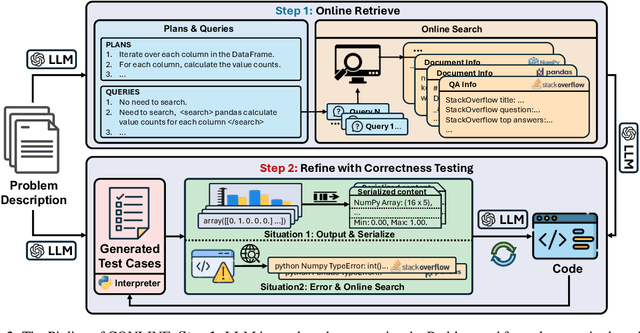
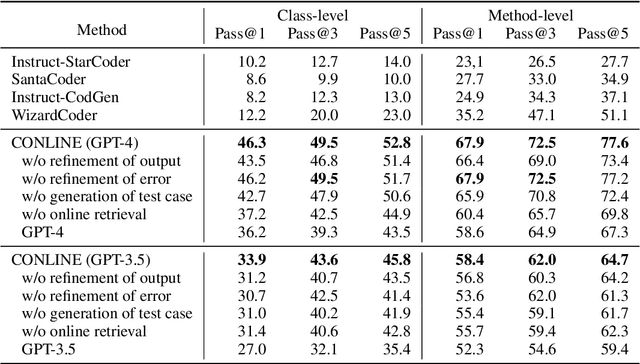
Large Language Models (LLMs) have revolutionized code generation ability by converting natural language descriptions into executable code. However, generating complex code within real-world scenarios remains challenging due to intricate structures, subtle bugs, understanding of advanced data types, and lack of supplementary contents. To address these challenges, we introduce the CONLINE framework, which enhances code generation by incorporating planned online searches for information retrieval and automated correctness testing for iterative refinement. CONLINE also serializes the complex inputs and outputs to improve comprehension and generate test case to ensure the framework's adaptability for real-world applications. CONLINE is validated through rigorous experiments on the DS-1000 and ClassEval datasets. It shows that CONLINE substantially improves the quality of complex code generation, highlighting its potential to enhance the practicality and reliability of LLMs in generating intricate code.
Depth Information Assisted Collaborative Mutual Promotion Network for Single Image Dehazing
Mar 02, 2024Recovering a clear image from a single hazy image is an open inverse problem. Although significant research progress has been made, most existing methods ignore the effect that downstream tasks play in promoting upstream dehazing. From the perspective of the haze generation mechanism, there is a potential relationship between the depth information of the scene and the hazy image. Based on this, we propose a dual-task collaborative mutual promotion framework to achieve the dehazing of a single image. This framework integrates depth estimation and dehazing by a dual-task interaction mechanism and achieves mutual enhancement of their performance. To realize the joint optimization of the two tasks, an alternative implementation mechanism with the difference perception is developed. On the one hand, the difference perception between the depth maps of the dehazing result and the ideal image is proposed to promote the dehazing network to pay attention to the non-ideal areas of the dehazing. On the other hand, by improving the depth estimation performance in the difficult-to-recover areas of the hazy image, the dehazing network can explicitly use the depth information of the hazy image to assist the clear image recovery. To promote the depth estimation, we propose to use the difference between the dehazed image and the ground truth to guide the depth estimation network to focus on the dehazed unideal areas. It allows dehazing and depth estimation to leverage their strengths in a mutually reinforcing manner. Experimental results show that the proposed method can achieve better performance than that of the state-of-the-art approaches.
Hierarchical Generative Network for Face Morphing Attacks
Mar 17, 2024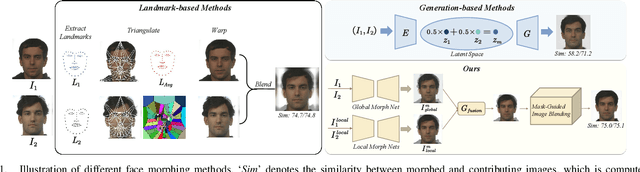
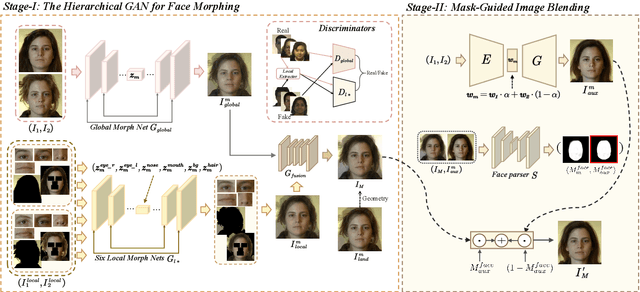
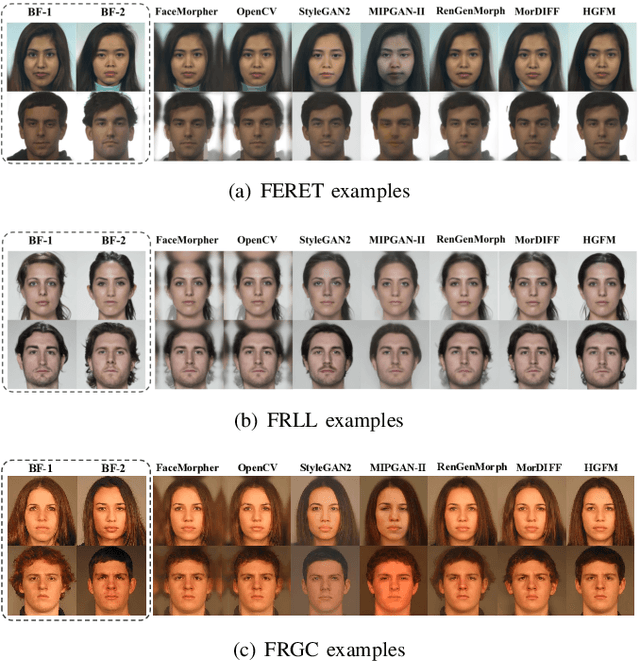

Face morphing attacks circumvent face recognition systems (FRSs) by creating a morphed image that contains multiple identities. However, existing face morphing attack methods either sacrifice image quality or compromise the identity preservation capability. Consequently, these attacks fail to bypass FRSs verification well while still managing to deceive human observers. These methods typically rely on global information from contributing images, ignoring the detailed information from effective facial regions. To address the above issues, we propose a novel morphing attack method to improve the quality of morphed images and better preserve the contributing identities. Our proposed method leverages the hierarchical generative network to capture both local detailed and global consistency information. Additionally, a mask-guided image blending module is dedicated to removing artifacts from areas outside the face to improve the image's visual quality. The proposed attack method is compared to state-of-the-art methods on three public datasets in terms of FRSs' vulnerability, attack detectability, and image quality. The results show our method's potential threat of deceiving FRSs while being capable of passing multiple morphing attack detection (MAD) scenarios.
DVN-SLAM: Dynamic Visual Neural SLAM Based on Local-Global Encoding
Mar 18, 2024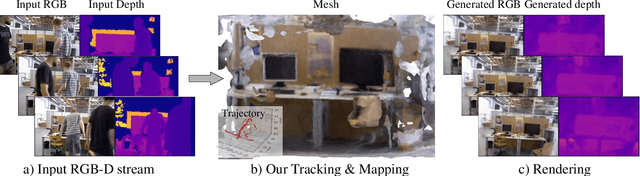
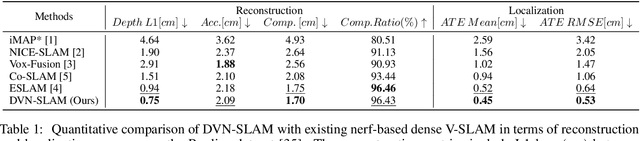
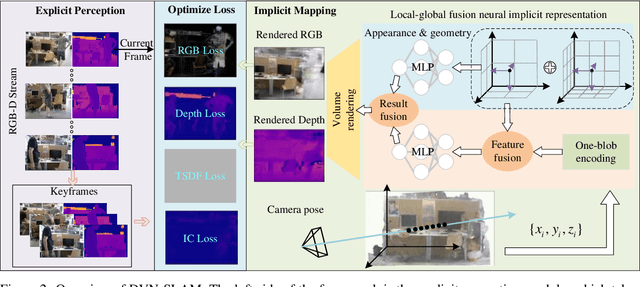
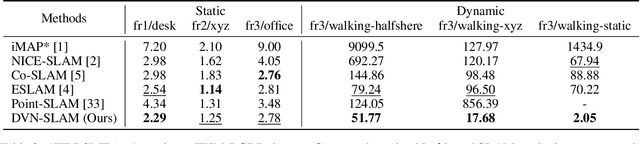
Recent research on Simultaneous Localization and Mapping (SLAM) based on implicit representation has shown promising results in indoor environments. However, there are still some challenges: the limited scene representation capability of implicit encodings, the uncertainty in the rendering process from implicit representations, and the disruption of consistency by dynamic objects. To address these challenges, we propose a real-time dynamic visual SLAM system based on local-global fusion neural implicit representation, named DVN-SLAM. To improve the scene representation capability, we introduce a local-global fusion neural implicit representation that enables the construction of an implicit map while considering both global structure and local details. To tackle uncertainties arising from the rendering process, we design an information concentration loss for optimization, aiming to concentrate scene information on object surfaces. The proposed DVN-SLAM achieves competitive performance in localization and mapping across multiple datasets. More importantly, DVN-SLAM demonstrates robustness in dynamic scenes, a trait that sets it apart from other NeRF-based methods.
TARN-VIST: Topic Aware Reinforcement Network for Visual Storytelling
Mar 18, 2024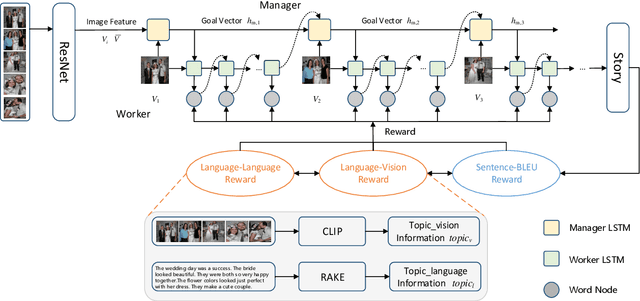
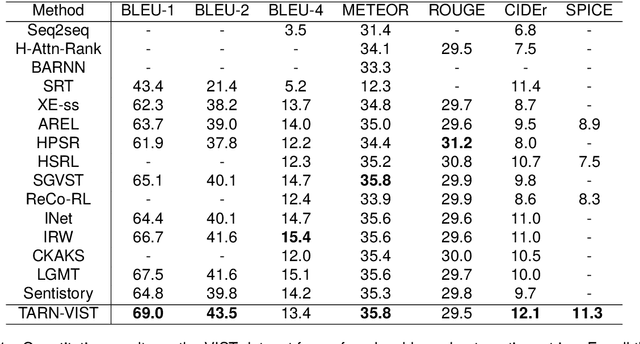
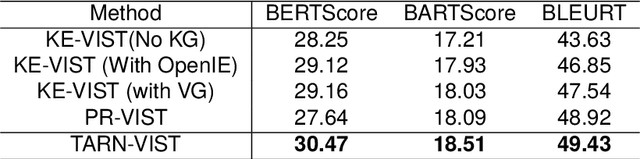

As a cross-modal task, visual storytelling aims to generate a story for an ordered image sequence automatically. Different from the image captioning task, visual storytelling requires not only modeling the relationships between objects in the image but also mining the connections between adjacent images. Recent approaches primarily utilize either end-to-end frameworks or multi-stage frameworks to generate relevant stories, but they usually overlook latent topic information. In this paper, in order to generate a more coherent and relevant story, we propose a novel method, Topic Aware Reinforcement Network for VIsual StoryTelling (TARN-VIST). In particular, we pre-extracted the topic information of stories from both visual and linguistic perspectives. Then we apply two topic-consistent reinforcement learning rewards to identify the discrepancy between the generated story and the human-labeled story so as to refine the whole generation process. Extensive experimental results on the VIST dataset and human evaluation demonstrate that our proposed model outperforms most of the competitive models across multiple evaluation metrics.