 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiColor: Image Colorization by Learning from Multiple Color Spaces
Aug 08, 2024Deep networks have shown impressive performance in the image restoration tasks, such as image colorization. However, we find that previous approaches rely on the digital representation from single color model with a specific mapping function, a.k.a., color space, during the colorization pipeline. In this paper, we first investigate the modeling of different color spaces, and find each of them exhibiting distinctive characteristics with unique distribution of colors. The complementarity among multiple color spaces leads to benefits for the image colorization task. We present MultiColor, a new learning-based approach to automatically colorize grayscale images that combines clues from multiple color spaces. Specifically, we employ a set of dedicated colorization modules for individual color space. Within each module, a transformer decoder is first employed to refine color query embeddings and then a color mapper produces color channel prediction using the embeddings and semantic features. With these predicted color channels representing various color spaces, a complementary network is designed to exploit the complementarity and generate pleasing and reasonable colorized images. We conduct extensive experiments on real-world datasets, and the results demonstrate superior performance over the state-of-the-arts.
Minutes to Seconds: Speeded-up DDPM-based Image Inpainting with Coarse-to-Fine Sampling
Jul 08, 2024



For image inpainting, the existing Denoising Diffusion Probabilistic Model (DDPM) based method i.e. RePaint can produce high-quality images for any inpainting form. It utilizes a pre-trained DDPM as a prior and generates inpainting results by conditioning on the reverse diffusion process, namely denoising process. However, this process is significantly time-consuming. In this paper, we propose an efficient DDPM-based image inpainting method which includes three speed-up strategies. First, we utilize a pre-trained Light-Weight Diffusion Model (LWDM) to reduce the number of parameters. Second, we introduce a skip-step sampling scheme of Denoising Diffusion Implicit Models (DDIM) for the denoising process. Finally, we propose Coarse-to-Fine Sampling (CFS), which speeds up inference by reducing image resolution in the coarse stage and decreasing denoising timesteps in the refinement stage. We conduct extensive experiments on both faces and general-purpose image inpainting tasks, and our method achieves competitive performance with approximately 60 times speedup.
Fine-Grained Scene Image Classification with Modality-Agnostic Adapter
Jul 03, 2024



When dealing with the task of fine-grained scene image classification, most previous works lay much emphasis on global visual features when doing multi-modal feature fusion. In other words, models are deliberately designed based on prior intuitions about the importance of different modalities. In this paper, we present a new multi-modal feature fusion approach named MAA (Modality-Agnostic Adapter), trying to make the model learn the importance of different modalities in different cases adaptively, without giving a prior setting in the model architecture. More specifically, we eliminate the modal differences in distribution and then use a modality-agnostic Transformer encoder for a semantic-level feature fusion. Our experiments demonstrate that MAA achieves state-of-the-art results on benchmarks by applying the same modalities with previous methods. Besides, it is worth mentioning that new modalities can be easily added when using MAA and further boost the performance. Code is available at https://github.com/quniLcs/MAA.
Efficient scene text image super-resolution with semantic guidance
Mar 20, 2024



Scene text image super-resolution has significantly improved the accuracy of scene text recognition. However, many existing methods emphasize performance over efficiency and ignore the practical need for lightweight solutions in deployment scenarios. Faced with the issues, our work proposes an efficient framework called SGENet to facilitate deployment on resource-limited platforms. SGENet contains two branches: super-resolution branch and semantic guidance branch. We apply a lightweight pre-trained recognizer as a semantic extractor to enhance the understanding of text information. Meanwhile, we design the visual-semantic alignment module to achieve bidirectional alignment between image features and semantics, resulting in the generation of highquality prior guidance. We conduct extensive experiments on benchmark dataset, and the proposed SGENet achieves excellent performance with fewer computational costs. Code is available at https://github.com/SijieLiu518/SGENet
DDT: Dual-branch Deformable Transformer for Image Denoising
Apr 13, 2023



Transformer is beneficial for image denoising tasks since it can model long-range dependencies to overcome the limitations presented by inductive convolutional biases. However, directly applying the transformer structure to remove noise is challenging because its complexity grows quadratically with the spatial resolution. In this paper, we propose an efficient Dual-branch Deformable Transformer (DDT) denoising network which captures both local and global interactions in parallel. We divide features with a fixed patch size and a fixed number of patches in local and global branches, respectively. In addition, we apply deformable attention operation in both branches, which helps the network focus on more important regions and further reduces computational complexity. We conduct extensive experiments on real-world and synthetic denoising tasks, and the proposed DDT achieves state-of-the-art performance with significantly fewer computational costs.
Aggregated Text Transformer for Scene Text Detection
Nov 25, 2022



This paper explores the multi-scale aggregation strategy for scene text detection in natural images. We present the Aggregated Text TRansformer(ATTR), which is designed to represent texts in scene images with a multi-scale self-attention mechanism. Starting from the image pyramid with multiple resolutions, the features are first extracted at different scales with shared weight and then fed into an encoder-decoder architecture of Transformer. The multi-scale image representations are robust and contain rich information on text contents of various sizes. The text Transformer aggregates these features to learn the interaction across different scales and improve text representation. The proposed method detects scene texts by representing each text instance as an individual binary mask, which is tolerant of curve texts and regions with dense instances. Extensive experiments on public scene text detection datasets demonstrate the effectiveness of the proposed framework.
Progressive Scene Text Erasing with Self-Supervision
Jul 23, 2022


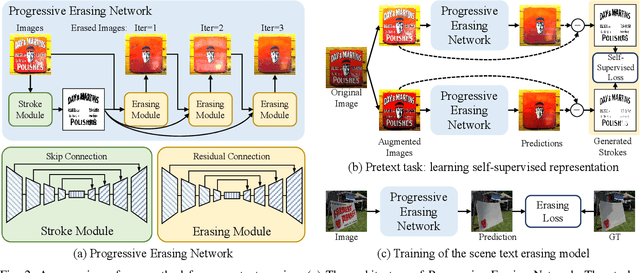
Scene text erasing seeks to erase text contents from scene images and current state-of-the-art text erasing models are trained on large-scale synthetic data. Although data synthetic engines can provide vast amounts of annotated training samples, there are differences between synthetic and real-world data. In this paper, we employ self-supervision for feature representation on unlabeled real-world scene text images. A novel pretext task is designed to keep consistent among text stroke masks of image variants. We design the Progressive Erasing Network in order to remove residual texts. The scene text is erased progressively by leveraging the intermediate generated results which provide the foundation for subsequent higher quality results. Experiments show that our method significantly improves the generalization of the text erasing task and achieves state-of-the-art performance on public benchmarks.
Cross-Domain Document Layout Analysis via Unsupervised Document Style Guide
Jan 24, 2022
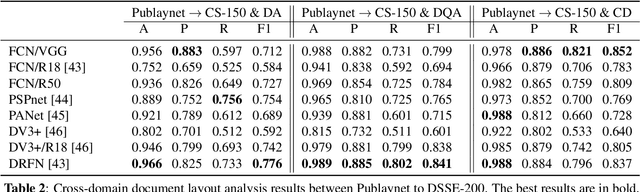
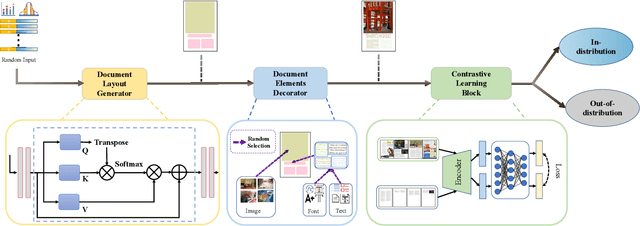
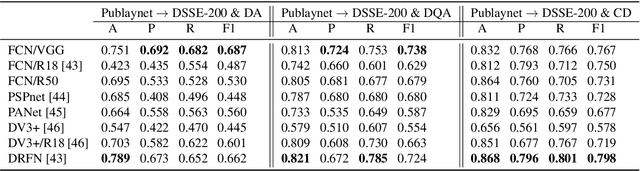
The document layout analysis (DLA) aims to decompose document images into high-level semantic areas (i.e., figures, tables, texts, and background). Creating a DLA framework with strong generalization capabilities is a challenge due to document objects are diversity in layout, size, aspect ratio, texture, etc. Many researchers devoted this challenge by synthesizing data to build large training sets. However, the synthetic training data has different styles and erratic quality. Besides, there is a large gap between the source data and the target data. In this paper, we propose an unsupervised cross-domain DLA framework based on document style guidance. We integrated the document quality assessment and the document cross-domain analysis into a unified framework. Our framework is composed of three components, Document Layout Generator (GLD), Document Elements Decorator(GED), and Document Style Discriminator(DSD). The GLD is used to document layout generates, the GED is used to document layout elements fill, and the DSD is used to document quality assessment and cross-domain guidance. First, we apply GLD to predict the positions of the generated document. Then, we design a novel algorithm based on aesthetic guidance to fill the document positions. Finally, we use contrastive learning to evaluate the quality assessment of the document. Besides, we design a new strategy to change the document quality assessment component into a document cross-domain style guide component. Our framework is an unsupervised document layout analysis framework. We have proved through numerous experiments that our proposed method has achieved remarkable performance.
Document Layout Analysis with Aesthetic-Guided Image Augmentation
Nov 27, 2021
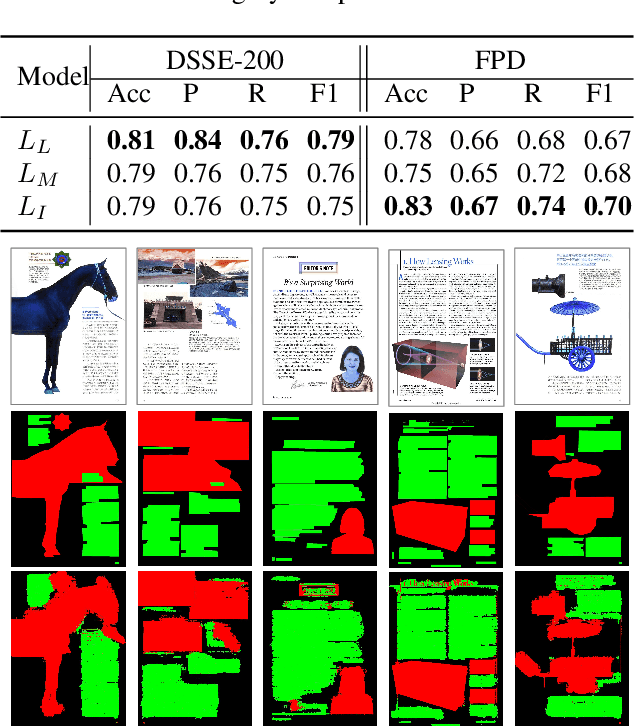
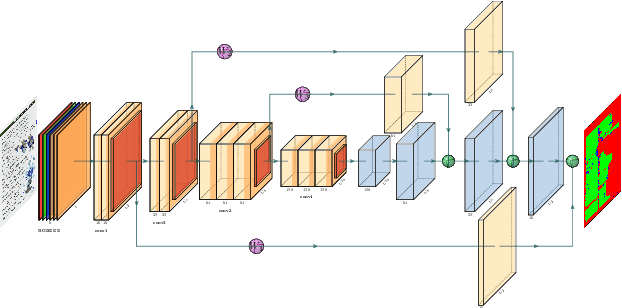
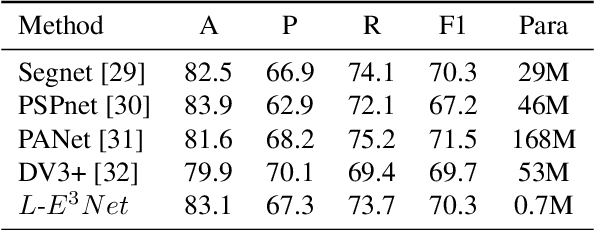
Document layout analysis (DLA) plays an important role in information extraction and document understanding. At present, document layout analysis has reached a milestone achievement, however, document layout analysis of non-Manhattan is still a challenge. In this paper, we propose an image layer modeling method to tackle this challenge. To measure the proposed image layer modeling method, we propose a manually-labeled non-Manhattan layout fine-grained segmentation dataset named FPD. As far as we know, FPD is the first manually-labeled non-Manhattan layout fine-grained segmentation dataset. To effectively extract fine-grained features of documents, we propose an edge embedding network named L-E^3Net. Experimental results prove that our proposed image layer modeling method can better deal with the fine-grained segmented document of the non-Manhattan layout.
Document Layout Analysis via Dynamic Residual Feature Fusion
Apr 07, 2021
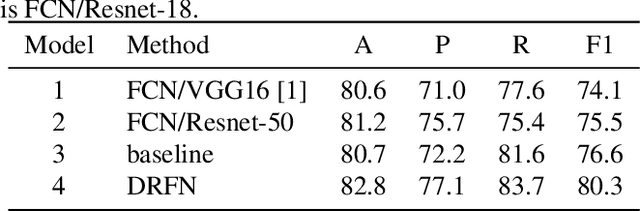
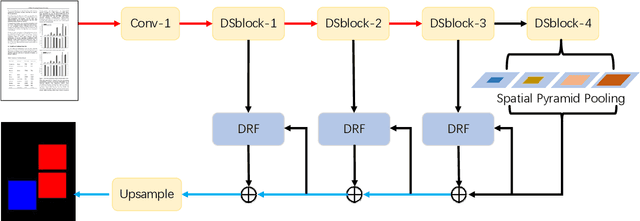
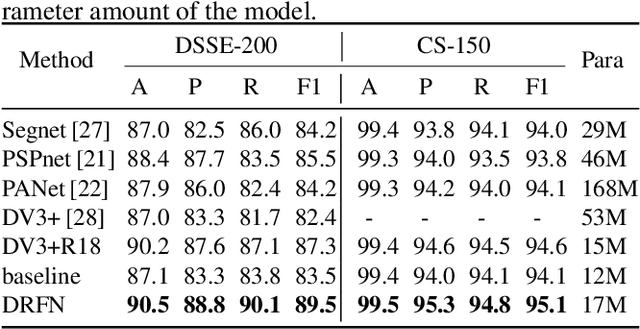
The document layout analysis (DLA) aims to split the document image into different interest regions and understand the role of each region, which has wide application such as optical character recognition (OCR) systems and document retrieval. However, it is a challenge to build a DLA system because the training data is very limited and lacks an efficient model. In this paper, we propose an end-to-end united network named Dynamic Residual Fusion Network (DRFN) for the DLA task. Specifically, we design a dynamic residual feature fusion module which can fully utilize low-dimensional information and maintain high-dimensional category information. Besides, to deal with the model overfitting problem that is caused by lacking enough data, we propose the dynamic select mechanism for efficient fine-tuning in limited train data. We experiment with two challenging datasets and demonstrate the effectiveness of the proposed module.
* 7 pages, 6 figures