 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancements in Chinese font generation since deep learning era: A survey
Aug 09, 2025



Chinese font generation aims to create a new Chinese font library based on some reference samples. It is a topic of great concern to many font designers and typographers. Over the past years, with the rapid development of deep learning algorithms, various new techniques have achieved flourishing and thriving progress. Nevertheless, how to improve the overall quality of generated Chinese character images remains a tough issue. In this paper, we conduct a holistic survey of the recent Chinese font generation approaches based on deep learning. To be specific, we first illustrate the research background of the task. Then, we outline our literature selection and analysis methodology, and review a series of related fundamentals, including classical deep learning architectures, font representation formats, public datasets, and frequently-used evaluation metrics. After that, relying on the number of reference samples required to generate a new font, we categorize the existing methods into two major groups: many-shot font generation and few-shot font generation methods. Within each category, representative approaches are summarized, and their strengths and limitations are also discussed in detail. Finally, we conclude our paper with the challenges and future directions, with the expectation to provide some valuable illuminations for the researchers in this field.
Detection Method for Prompt Injection by Integrating Pre-trained Model and Heuristic Feature Engineering
Jun 05, 2025With the widespread adoption of Large Language Models (LLMs), prompt injection attacks have emerged as a significant security threat. Existing defense mechanisms often face critical trade-offs between effectiveness and generalizability. This highlights the urgent need for efficient prompt injection detection methods that are applicable across a wide range of LLMs. To address this challenge, we propose DMPI-PMHFE, a dual-channel feature fusion detection framework. It integrates a pretrained language model with heuristic feature engineering to detect prompt injection attacks. Specifically, the framework employs DeBERTa-v3-base as a feature extractor to transform input text into semantic vectors enriched with contextual information. In parallel, we design heuristic rules based on known attack patterns to extract explicit structural features commonly observed in attacks. Features from both channels are subsequently fused and passed through a fully connected neural network to produce the final prediction. This dual-channel approach mitigates the limitations of relying only on DeBERTa to extract features. Experimental results on diverse benchmark datasets demonstrate that DMPI-PMHFE outperforms existing methods in terms of accuracy, recall, and F1-score. Furthermore, when deployed actually, it significantly reduces attack success rates across mainstream LLMs, including GLM-4, LLaMA 3, Qwen 2.5, and GPT-4o.
AutoSchemaKG: Autonomous Knowledge Graph Construction through Dynamic Schema Induction from Web-Scale Corpora
May 29, 2025



We present AutoSchemaKG, a framework for fully autonomous knowledge graph construction that eliminates the need for predefined schemas. Our system leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text, modeling both entities and events while employing conceptualization to organize instances into semantic categories. Processing over 50 million documents, we construct ATLAS (Automated Triple Linking And Schema induction), a family of knowledge graphs with 900+ million nodes and 5.9 billion edges. This approach outperforms state-of-the-art baselines on multi-hop QA tasks and enhances LLM factuality. Notably, our schema induction achieves 95\% semantic alignment with human-crafted schemas with zero manual intervention, demonstrating that billion-scale knowledge graphs with dynamically induced schemas can effectively complement parametric knowledge in large language models.
A Multi-UAV Formation Obstacle Avoidance Method Combined Improved Simulated Annealing and Adaptive Artificial Potential Field
Apr 15, 2025The traditional Artificial Potential Field (APF) method exhibits limitations in its force distribution: excessive attraction when UAVs are far from the target may cause collisions with obstacles, while insufficient attraction near the goal often results in failure to reach the target. Furthermore, APF is highly susceptible to local minima, compromising motion reliability in complex environments. To address these challenges, this paper presents a novel hybrid obstacle avoidance algorithm-Deflected Simulated Annealing-Adaptive Artificial Potential Field (DSA-AAPF)-which combines an improved simulated annealing mechanism with an enhanced APF model. The proposed approach integrates a Leader-Follower distributed formation strategy with the APF framework, where the resultant force formulation is redefined to smooth UAV trajectories. An adaptive gravitational gain function is introduced to dynamically adjust UAV velocity based on environmental context, and a fast-converging controller ensures accurate and efficient convergence to the target. Moreover, a directional deflection mechanism is embedded within the simulated annealing process, enabling UAVs to escape local minima caused by semi-enclosed obstacles through continuous rotational motion. The simulation results, covering formation reconfiguration, complex obstacle avoidance, and entrapment escape, demonstrate the feasibility, robustness, and superiority of the proposed DSA-AAPF algorithm.
TARN-VIST: Topic Aware Reinforcement Network for Visual Storytelling
Mar 18, 2024



As a cross-modal task, visual storytelling aims to generate a story for an ordered image sequence automatically. Different from the image captioning task, visual storytelling requires not only modeling the relationships between objects in the image but also mining the connections between adjacent images. Recent approaches primarily utilize either end-to-end frameworks or multi-stage frameworks to generate relevant stories, but they usually overlook latent topic information. In this paper, in order to generate a more coherent and relevant story, we propose a novel method, Topic Aware Reinforcement Network for VIsual StoryTelling (TARN-VIST). In particular, we pre-extracted the topic information of stories from both visual and linguistic perspectives. Then we apply two topic-consistent reinforcement learning rewards to identify the discrepancy between the generated story and the human-labeled story so as to refine the whole generation process. Extensive experimental results on the VIST dataset and human evaluation demonstrate that our proposed model outperforms most of the competitive models across multiple evaluation metrics.
Style Transfer for Anime Sketches with Enhanced Residual U-net and Auxiliary Classifier GAN
Jun 13, 2017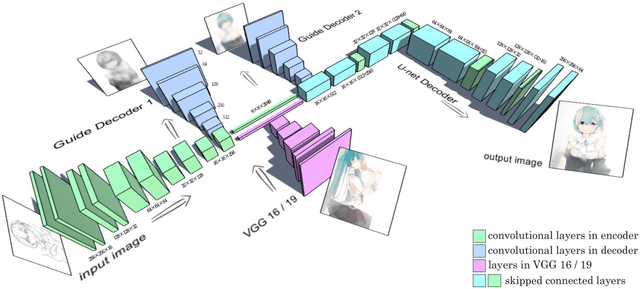
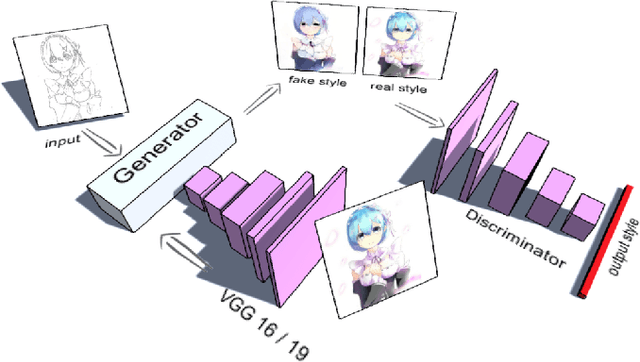
Recently, with the revolutionary neural style transferring methods, creditable paintings can be synthesized automatically from content images and style images. However, when it comes to the task of applying a painting's style to an anime sketch, these methods will just randomly colorize sketch lines as outputs and fail in the main task: specific style tranfer. In this paper, we integrated residual U-net to apply the style to the gray-scale sketch with auxiliary classifier generative adversarial network (AC-GAN). The whole process is automatic and fast, and the results are creditable in the quality of art style as well as colorization.