 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Path-Specific Counterfactual Fairness for Recommender Systems
Jun 05, 2023
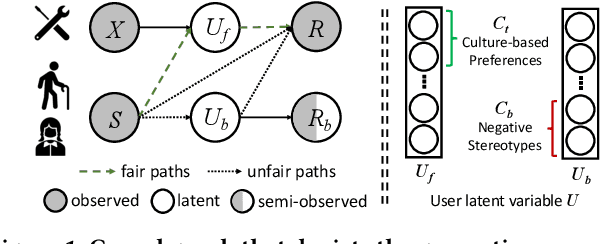
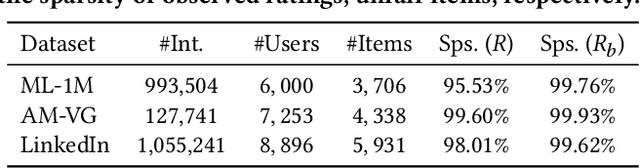
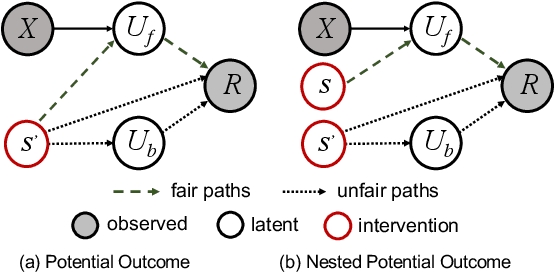
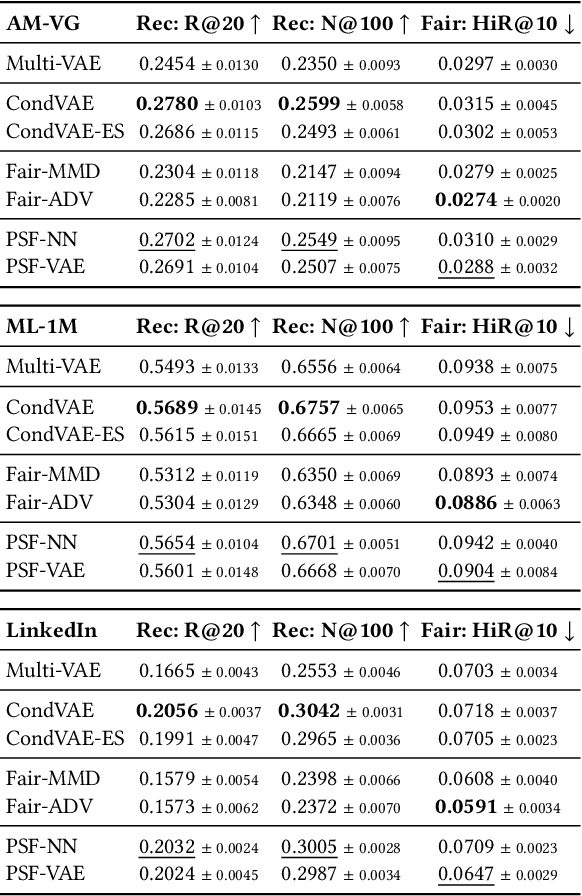
Recommender systems (RSs) have become an indispensable part of online platforms. With the growing concerns of algorithmic fairness, RSs are not only expected to deliver high-quality personalized content, but are also demanded not to discriminate against users based on their demographic information. However, existing RSs could capture undesirable correlations between sensitive features and observed user behaviors, leading to biased recommendations. Most fair RSs tackle this problem by completely blocking the influences of sensitive features on recommendations. But since sensitive features may also affect user interests in a fair manner (e.g., race on culture-based preferences), indiscriminately eliminating all the influences of sensitive features inevitably degenerate the recommendations quality and necessary diversities. To address this challenge, we propose a path-specific fair RS (PSF-RS) for recommendations. Specifically, we summarize all fair and unfair correlations between sensitive features and observed ratings into two latent proxy mediators, where the concept of path-specific bias (PS-Bias) is defined based on path-specific counterfactual inference. Inspired by Pearl's minimal change principle, we address the PS-Bias by minimally transforming the biased factual world into a hypothetically fair world, where a fair RS model can be learned accordingly by solving a constrained optimization problem. For the technical part, we propose a feasible implementation of PSF-RS, i.e., PSF-VAE, with weakly-supervised variational inference, which robustly infers the latent mediators such that unfairness can be mitigated while necessary recommendation diversities can be maximally preserved simultaneously. Experiments conducted on semi-simulated and real-world datasets demonstrate the effectiveness of PSF-RS.
Using Sequences of Life-events to Predict Human Lives
Jun 05, 2023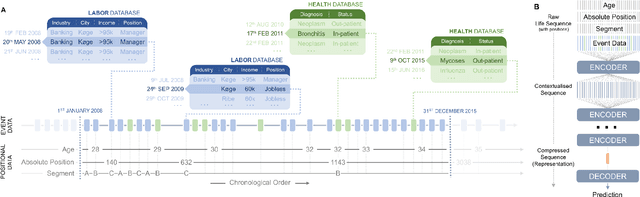
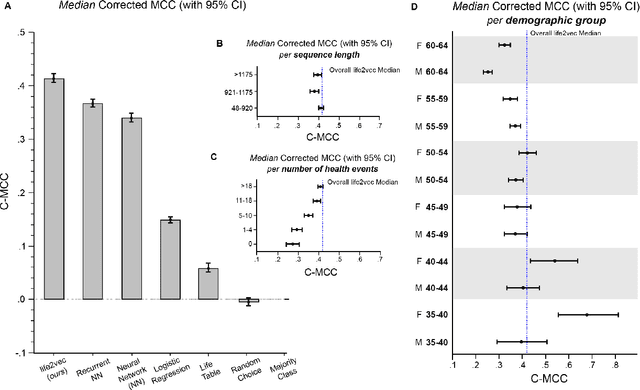
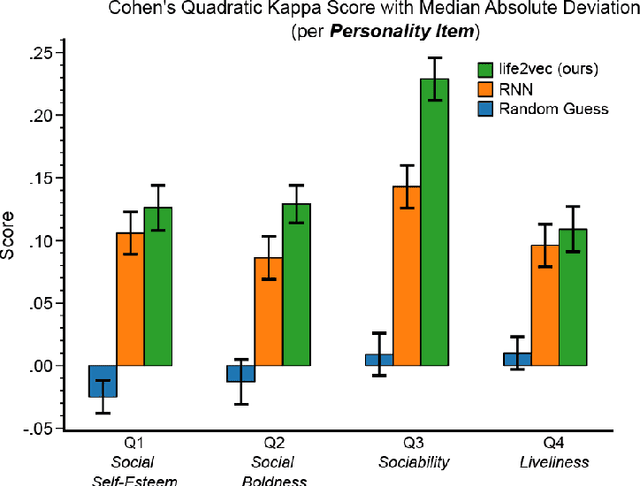
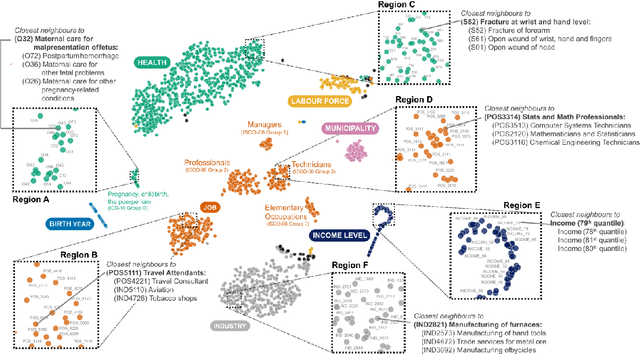
Over the past decade, machine learning has revolutionized computers' ability to analyze text through flexible computational models. Due to their structural similarity to written language, transformer-based architectures have also shown promise as tools to make sense of a range of multi-variate sequences from protein-structures, music, electronic health records to weather-forecasts. We can also represent human lives in a way that shares this structural similarity to language. From one perspective, lives are simply sequences of events: People are born, visit the pediatrician, start school, move to a new location, get married, and so on. Here, we exploit this similarity to adapt innovations from natural language processing to examine the evolution and predictability of human lives based on detailed event sequences. We do this by drawing on arguably the most comprehensive registry data in existence, available for an entire nation of more than six million individuals across decades. Our data include information about life-events related to health, education, occupation, income, address, and working hours, recorded with day-to-day resolution. We create embeddings of life-events in a single vector space showing that this embedding space is robust and highly structured. Our models allow us to predict diverse outcomes ranging from early mortality to personality nuances, outperforming state-of-the-art models by a wide margin. Using methods for interpreting deep learning models, we probe the algorithm to understand the factors that enable our predictions. Our framework allows researchers to identify new potential mechanisms that impact life outcomes and associated possibilities for personalized interventions.
Asymptotically Optimal Pure Exploration for Infinite-Armed Bandits
Jun 03, 2023We study pure exploration with infinitely many bandit arms generated i.i.d. from an unknown distribution. Our goal is to efficiently select a single high quality arm whose average reward is, with probability $1-\delta$, within $\varepsilon$ of being among the top $\eta$-fraction of arms; this is a natural adaptation of the classical PAC guarantee for infinite action sets. We consider both the fixed confidence and fixed budget settings, aiming respectively for minimal expected and fixed sample complexity. For fixed confidence, we give an algorithm with expected sample complexity $O\left(\frac{\log (1/\eta)\log (1/\delta)}{\eta\varepsilon^2}\right)$. This is optimal except for the $\log (1/\eta)$ factor, and the $\delta$-dependence closes a quadratic gap in the literature. For fixed budget, we show the asymptotically optimal sample complexity as $\delta\to 0$ is $c^{-1}\log(1/\delta)\big(\log\log(1/\delta)\big)^2$ to leading order. Equivalently, the optimal failure probability given exactly $N$ samples decays as $\exp\big(-cN/\log^2 N\big)$, up to a factor $1\pm o_N(1)$ inside the exponent. The constant $c$ depends explicitly on the problem parameters (including the unknown arm distribution) through a certain Fisher information distance. Even the strictly super-linear dependence on $\log(1/\delta)$ was not known and resolves a question of Grossman and Moshkovitz (FOCS 2016, SIAM Journal on Computing 2020).
TransDocAnalyser: A Framework for Offline Semi-structured Handwritten Document Analysis in the Legal Domain
Jun 03, 2023
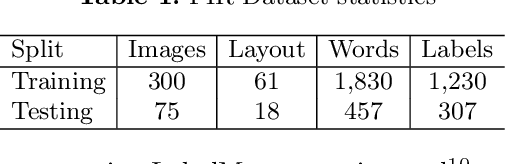

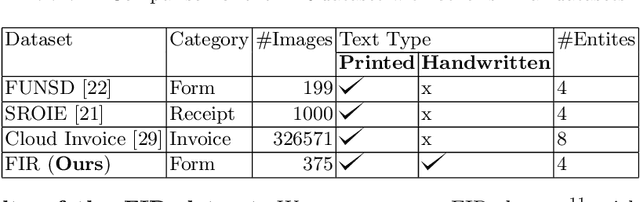
State-of-the-art offline Optical Character Recognition (OCR) frameworks perform poorly on semi-structured handwritten domain-specific documents due to their inability to localize and label form fields with domain-specific semantics. Existing techniques for semi-structured document analysis have primarily used datasets comprising invoices, purchase orders, receipts, and identity-card documents for benchmarking. In this work, we build the first semi-structured document analysis dataset in the legal domain by collecting a large number of First Information Report (FIR) documents from several police stations in India. This dataset, which we call the FIR dataset, is more challenging than most existing document analysis datasets, since it combines a wide variety of handwritten text with printed text. We also propose an end-to-end framework for offline processing of handwritten semi-structured documents, and benchmark it on our novel FIR dataset. Our framework used Encoder-Decoder architecture for localizing and labelling the form fields and for recognizing the handwritten content. The encoder consists of Faster-RCNN and Vision Transformers. Further the Transformer-based decoder architecture is trained with a domain-specific tokenizer. We also propose a post-correction method to handle recognition errors pertaining to the domain-specific terms. Our proposed framework achieves state-of-the-art results on the FIR dataset outperforming several existing models
Improving Isochronous Machine Translation with Target Factors and Auxiliary Counters
May 22, 2023
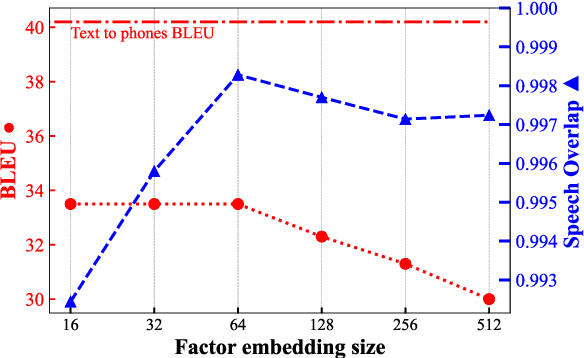
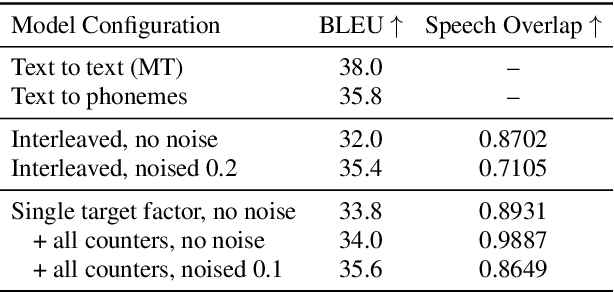
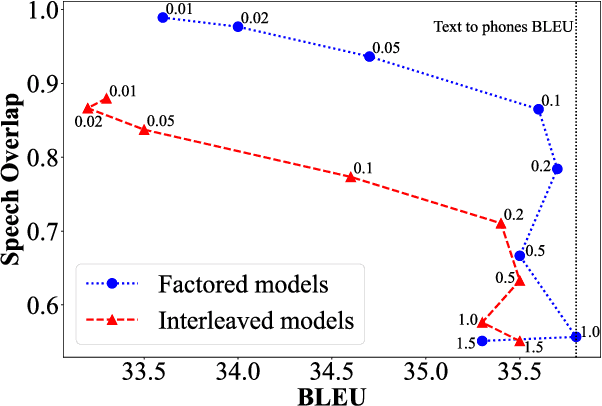
To translate speech for automatic dubbing, machine translation needs to be isochronous, i.e. translated speech needs to be aligned with the source in terms of speech durations. We introduce target factors in a transformer model to predict durations jointly with target language phoneme sequences. We also introduce auxiliary counters to help the decoder to keep track of the timing information while generating target phonemes. We show that our model improves translation quality and isochrony compared to previous work where the translation model is instead trained to predict interleaved sequences of phonemes and durations.
Learning Lagrangian Fluid Mechanics with E($3$)-Equivariant Graph Neural Networks
May 24, 2023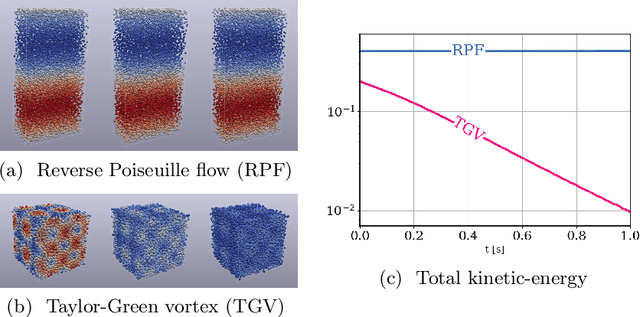
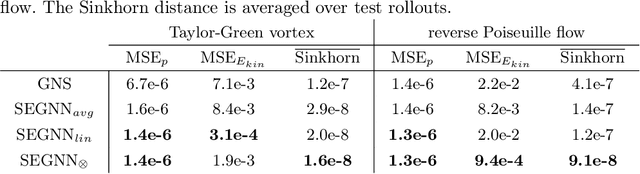
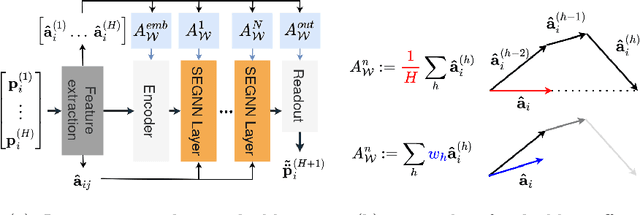
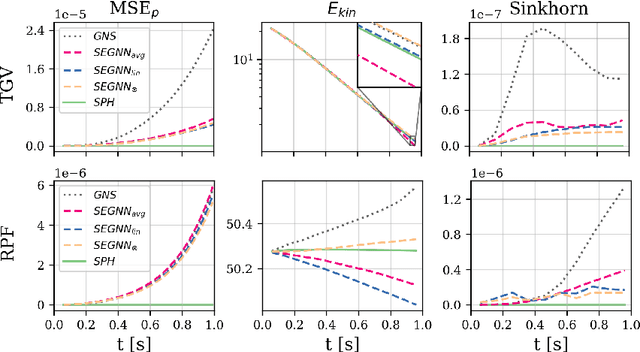
We contribute to the vastly growing field of machine learning for engineering systems by demonstrating that equivariant graph neural networks have the potential to learn more accurate dynamic-interaction models than their non-equivariant counterparts. We benchmark two well-studied fluid-flow systems, namely 3D decaying Taylor-Green vortex and 3D reverse Poiseuille flow, and evaluate the models based on different performance measures, such as kinetic energy or Sinkhorn distance. In addition, we investigate different embedding methods of physical-information histories for equivariant models. We find that while currently being rather slow to train and evaluate, equivariant models with our proposed history embeddings learn more accurate physical interactions.
Vision + Language Applications: A Survey
May 24, 2023
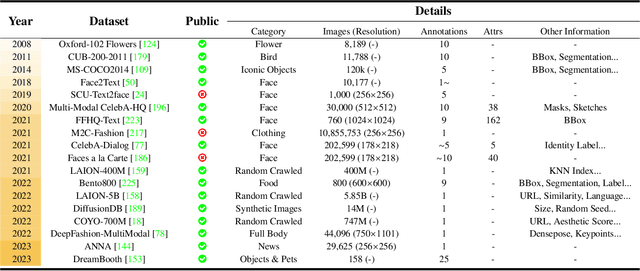


Text-to-image generation has attracted significant interest from researchers and practitioners in recent years due to its widespread and diverse applications across various industries. Despite the progress made in the domain of vision and language research, the existing literature remains relatively limited, particularly with regard to advancements and applications in this field. This paper explores a relevant research track within multimodal applications, including text, vision, audio, and others. In addition to the studies discussed in this paper, we are also committed to continually updating the latest relevant papers, datasets, application projects and corresponding information at https://github.com/Yutong-Zhou-cv/Awesome-Text-to-Image
Multi-Scale Attention for Audio Question Answering
May 29, 2023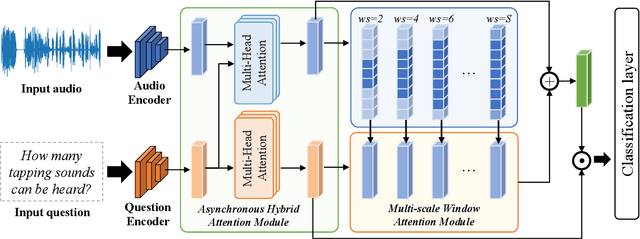
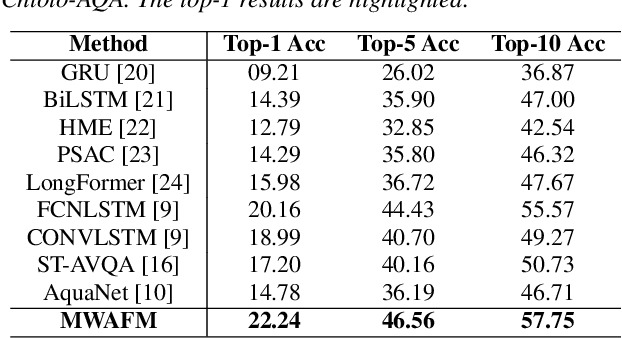
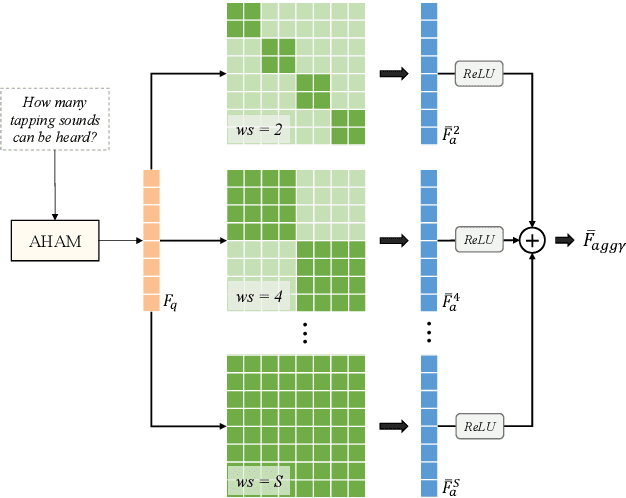
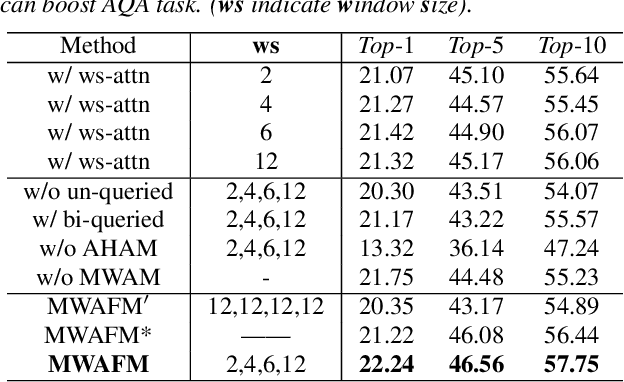
Audio question answering (AQA), acting as a widely used proxy task to explore scene understanding, has got more attention. The AQA is challenging for it requires comprehensive temporal reasoning from different scales' events of an audio scene. However, existing methods mostly extend the structures of visual question answering task to audio ones in a simple pattern but may not perform well when perceiving a fine-grained audio scene. To this end, we present a Multi-scale Window Attention Fusion Model (MWAFM) consisting of an asynchronous hybrid attention module and a multi-scale window attention module. The former is designed to aggregate unimodal and cross-modal temporal contexts, while the latter captures sound events of varying lengths and their temporal dependencies for a more comprehensive understanding. Extensive experiments are conducted to demonstrate that the proposed MWAFM can effectively explore temporal information to facilitate AQA in the fine-grained scene.Code: https://github.com/GeWu-Lab/MWAFM
GridFormer: Residual Dense Transformer with Grid Structure for Image Restoration in Adverse Weather Conditions
May 29, 2023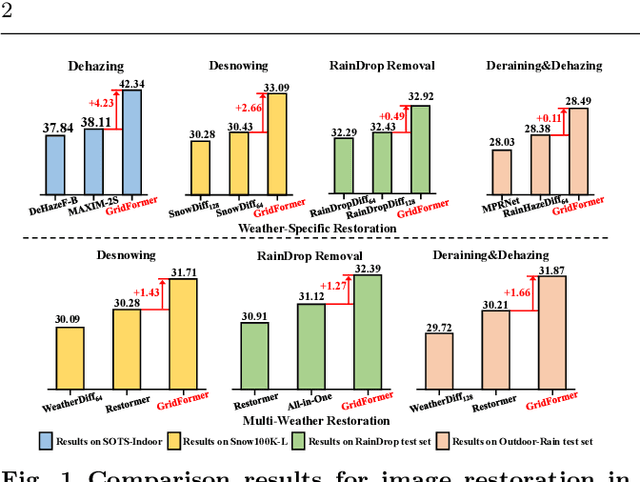
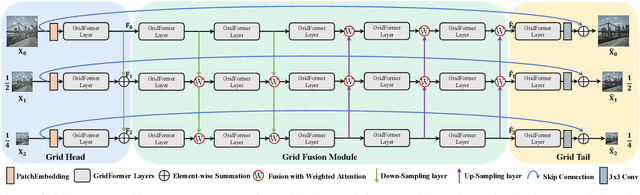
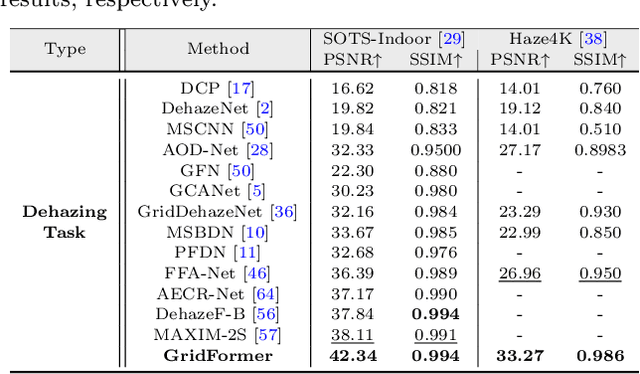
Image restoration in adverse weather conditions is a difficult task in computer vision. In this paper, we propose a novel transformer-based framework called GridFormer which serves as a backbone for image restoration under adverse weather conditions. GridFormer is designed in a grid structure using a residual dense transformer block, and it introduces two core designs. First, it uses an enhanced attention mechanism in the transformer layer. The mechanism includes stages of the sampler and compact self-attention to improve efficiency, and a local enhancement stage to strengthen local information. Second, we introduce a residual dense transformer block (RDTB) as the final GridFormer layer. This design further improves the network's ability to learn effective features from both preceding and current local features. The GridFormer framework achieves state-of-the-art results on five diverse image restoration tasks in adverse weather conditions, including image deraining, dehazing, deraining & dehazing, desnowing, and multi-weather restoration. The source code and pre-trained models will be released.
TReR: A Lightweight Transformer Re-Ranking Approach for 3D LiDAR Place Recognition
May 29, 2023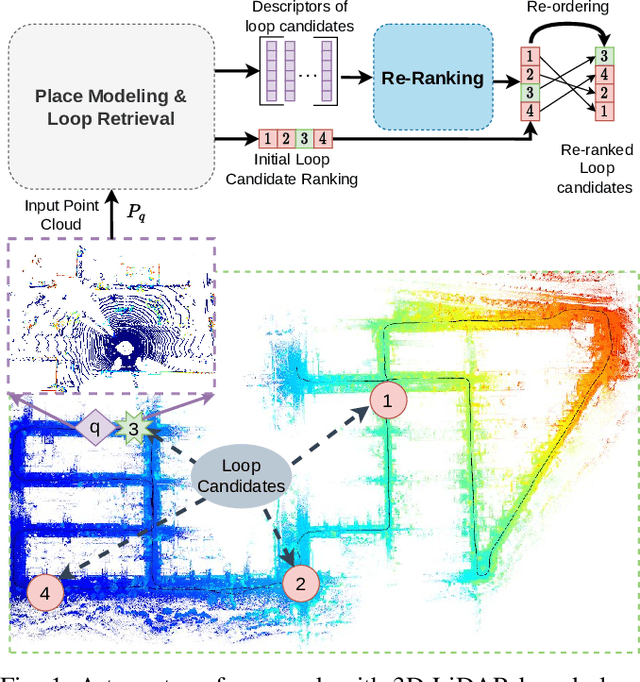
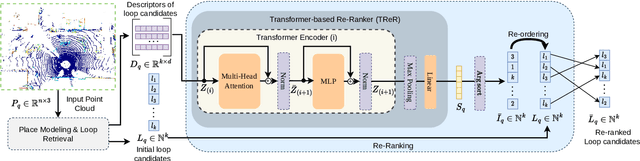
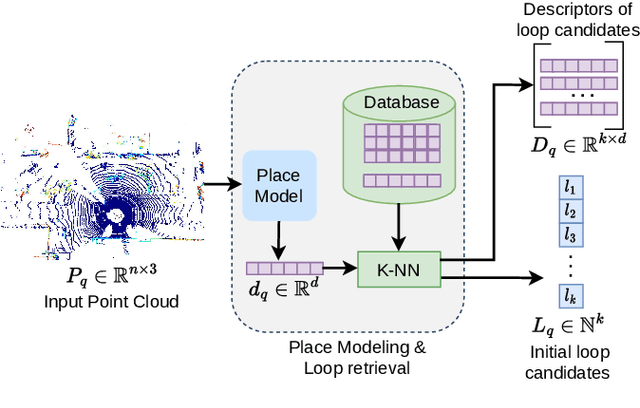
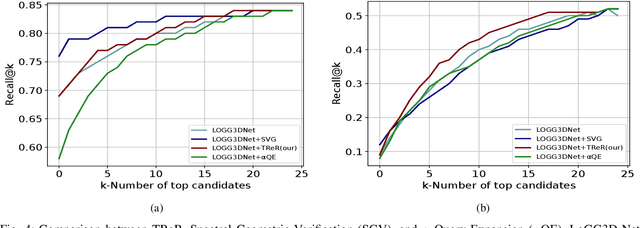
Autonomous driving systems often require reliable loop closure detection to guarantee reduced localization drift. Recently, 3D LiDAR-based localization methods have used retrieval-based place recognition to find revisited places efficiently. However, when deployed in challenging real-world scenarios, the place recognition models become more complex, which comes at the cost of high computational demand. This work tackles this problem from an information-retrieval perspective, adopting a first-retrieve-then-re-ranking paradigm, where an initial loop candidate ranking, generated from a 3D place recognition model, is re-ordered by a proposed lightweight transformer-based re-ranking approach (TReR). The proposed approach relies on global descriptors only, being agnostic to the place recognition model. The experimental evaluation, conducted on the KITTI Odometry dataset, where we compared TReR with s.o.t.a. re-ranking approaches such as alphaQE and SGV, indicate the robustness and efficiency when compared to alphaQE while offering a good trade-off between robustness and efficiency when compared to SGV.