 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond APIs: Probing the Limits of MLLMs in Physical Tool Use
Jun 09, 2026Multimodal Large Language Models (MLLMs) excel at utilizing digital APIs and increasingly serve as the "brain" of embodied AI, instructing robots to interact with the physical world. In such embodied settings, a central capability is the use of physical tools, which underpins MLLMs' ability to assist humans in real-world tasks. Despite the importance, MLLMs' proficiency in physical tool use remains largely unexplored. To address this gap, we introduce PhysTool-Bench, the first physical tool-use benchmark designed to evaluate MLLMs' ability to comprehend real-world scenarios, identify physical tools, and plan their use. PhysTool-Bench comprises 2,510 queries over 2,678 real-world physical tools spanning diverse domains, including manufacturing, electrical work, agriculture, and healthcare. Concretely, models are evaluated along two primary dimensions: 1) recognizing all physical tools present in the scene, and 2) planning the tool selection and use sequence based on the instruction and visual context. Across 13 leading MLLMs, even the strongest model (Gemini-3.1-Pro) identifies only 58.7% of tools in a scene and completes merely 21.0% of queries end-to-end. Our analysis reveals a two-level deficit: MLLMs struggle to perceive tools in realistic scenes, and the much larger drop at the planning stage further indicates a lack of functional commonsense for mapping perceived tools onto task semantics, pinpointing a critical bottleneck for the development of practical embodied AI.
Representation Collapse in Sequential Post-Training of Large Language Models
May 28, 2026Large language models are now adapted through chains of post-training stages rather than through a single instruction-tuning pass. This paper studies whether such sequential post-training gradually compresses internal representations into low-rank, anisotropic, and homogeneous feature spaces. We define a measurement suite for hidden states, logits, token trajectories, and LoRA updates, and we use it to analyze supervised fine-tuning, preference optimization, safety/refusal tuning, math and code specialization, and long chain-of-thought tuning under controlled stage orderings. The central hypothesis is that excessive representation concentration is not merely a geometric curiosity: it predicts reduced plasticity during later adaptation, weaker out-of-domain generalization, and poorer calibration. We further evaluate lightweight interventions, including mixed-domain replay, feature refresh, representation diversity regularization, and LoRA update decorrelation, as ways to preserve future learnability without giving up the behavioral gains of post-training.
Agentic Explainable Artificial Intelligence (Agentic XAI) Approach To Explore Better Explanation
Dec 24, 2025Explainable artificial intelligence (XAI) enables data-driven understanding of factor associations with response variables, yet communicating XAI outputs to laypersons remains challenging, hindering trust in AI-based predictions. Large language models (LLMs) have emerged as promising tools for translating technical explanations into accessible narratives, yet the integration of agentic AI, where LLMs operate as autonomous agents through iterative refinement, with XAI remains unexplored. This study proposes an agentic XAI framework combining SHAP-based explainability with multimodal LLM-driven iterative refinement to generate progressively enhanced explanations. As a use case, we tested this framework as an agricultural recommendation system using rice yield data from 26 fields in Japan. The Agentic XAI initially provided a SHAP result and explored how to improve the explanation through additional analysis iteratively across 11 refinement rounds (Rounds 0-10). Explanations were evaluated by human experts (crop scientists) (n=12) and LLMs (n=14) against seven metrics: Specificity, Clarity, Conciseness, Practicality, Contextual Relevance, Cost Consideration, and Crop Science Credibility. Both evaluator groups confirmed that the framework successfully enhanced recommendation quality with an average score increase of 30-33% from Round 0, peaking at Rounds 3-4. However, excessive refinement showed a substantial drop in recommendation quality, indicating a bias-variance trade-off where early rounds lacked explanation depth (bias) while excessive iteration introduced verbosity and ungrounded abstraction (variance), as revealed by metric-specific analysis. These findings suggest that strategic early stopping (regularization) is needed for optimizing practical utility, challenging assumptions about monotonic improvement and providing evidence-based design principles for agentic XAI systems.
From Images to Insights: Explainable Biodiversity Monitoring with Plain Language Habitat Explanations
Jun 12, 2025Explaining why the species lives at a particular location is important for understanding ecological systems and conserving biodiversity. However, existing ecological workflows are fragmented and often inaccessible to non-specialists. We propose an end-to-end visual-to-causal framework that transforms a species image into interpretable causal insights about its habitat preference. The system integrates species recognition, global occurrence retrieval, pseudo-absence sampling, and climate data extraction. We then discover causal structures among environmental features and estimate their influence on species occurrence using modern causal inference methods. Finally, we generate statistically grounded, human-readable causal explanations from structured templates and large language models. We demonstrate the framework on a bee and a flower species and report early results as part of an ongoing project, showing the potential of the multimodal AI assistant backed up by a recommended ecological modeling practice for describing species habitat in human-understandable language.
Phasing Through the Flames: Rapid Motion Planning with the AGHF PDE for Arbitrary Objective Functions and Constraints
May 02, 2025The generation of optimal trajectories for high-dimensional robotic systems under constraints remains computationally challenging due to the need to simultaneously satisfy dynamic feasibility, input limits, and task-specific objectives while searching over high-dimensional spaces. Recent approaches using the Affine Geometric Heat Flow (AGHF) Partial Differential Equation (PDE) have demonstrated promising results, generating dynamically feasible trajectories for complex systems like the Digit V3 humanoid within seconds. These methods efficiently solve trajectory optimization problems over a two-dimensional domain by evolving an initial trajectory to minimize control effort. However, these AGHF approaches are limited to a single type of optimal control problem (i.e., minimizing the integral of squared control norms) and typically require initial guesses that satisfy constraints to ensure satisfactory convergence. These limitations restrict the potential utility of the AGHF PDE especially when trying to synthesize trajectories for robotic systems. This paper generalizes the AGHF formulation to accommodate arbitrary cost functions, significantly expanding the classes of trajectories that can be generated. This work also introduces a Phase1 - Phase 2 Algorithm that enables the use of constraint-violating initial guesses while guaranteeing satisfactory convergence. The effectiveness of the proposed method is demonstrated through comparative evaluations against state-of-the-art techniques across various dynamical systems and challenging trajectory generation problems. Project Page: https://roahmlab.github.io/BLAZE/
AgriBench: A Hierarchical Agriculture Benchmark for Multimodal Large Language Models
Nov 30, 2024We introduce AgriBench, the first agriculture benchmark designed to evaluate MultiModal Large Language Models (MM-LLMs) for agriculture applications. To further address the agriculture knowledge-based dataset limitation problem, we propose MM-LUCAS, a multimodal agriculture dataset, that includes 1,784 landscape images, segmentation masks, depth maps, and detailed annotations (geographical location, country, date, land cover and land use taxonomic details, quality scores, aesthetic scores, etc), based on the Land Use/Cover Area Frame Survey (LUCAS) dataset, which contains comparable statistics on land use and land cover for the European Union (EU) territory. This work presents a groundbreaking perspective in advancing agriculture MM-LLMs and is still in progress, offering valuable insights for future developments and innovations in specific expert knowledge-based MM-LLMs.
Vision + Language Applications: A Survey
May 24, 2023Text-to-image generation has attracted significant interest from researchers and practitioners in recent years due to its widespread and diverse applications across various industries. Despite the progress made in the domain of vision and language research, the existing literature remains relatively limited, particularly with regard to advancements and applications in this field. This paper explores a relevant research track within multimodal applications, including text, vision, audio, and others. In addition to the studies discussed in this paper, we are also committed to continually updating the latest relevant papers, datasets, application projects and corresponding information at https://github.com/Yutong-Zhou-cv/Awesome-Text-to-Image
Design a Delicious Lunchbox in Style
May 22, 2023



We propose a cyclic generative adversarial network with spatial-wise and channel-wise attention modules for text-to-image synthesis. To accurately depict and design scenes with multiple occluded objects, we design a pre-trained ordering recovery model and a generative adversarial network to predict layout and composite novel box lunch presentations. In the experiments, we devise the Bento800 dataset to evaluate the performance of the text-to-image synthesis model and the layout generation & image composition model. This paper is the continuation of our previous paper works. We also present additional experiments and qualitative performance comparisons to verify the effectiveness of our proposed method. Bento800 dataset is available at https://github.com/Yutong-Zhou-cv/Bento800_Dataset
Programming Language Agnostic Mining of Code and Language Pairs with Sequence Labeling Based Question Answering
Mar 21, 2022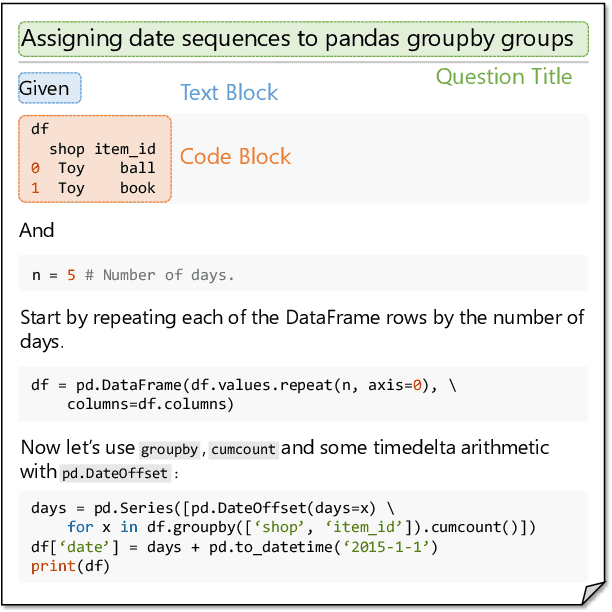
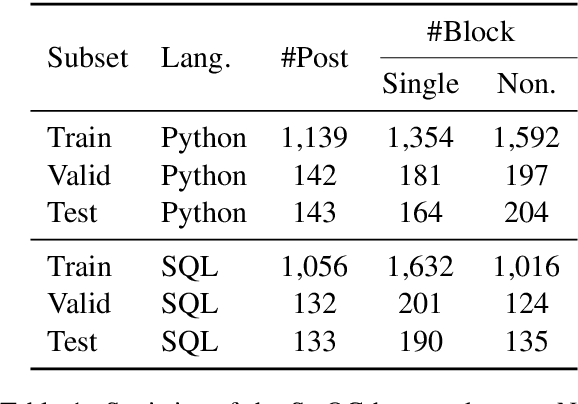
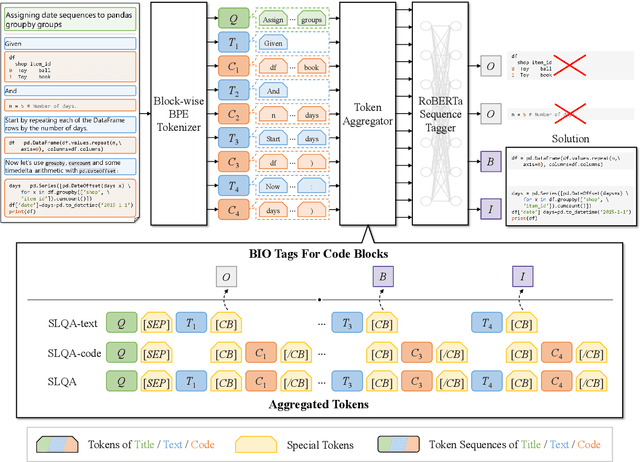
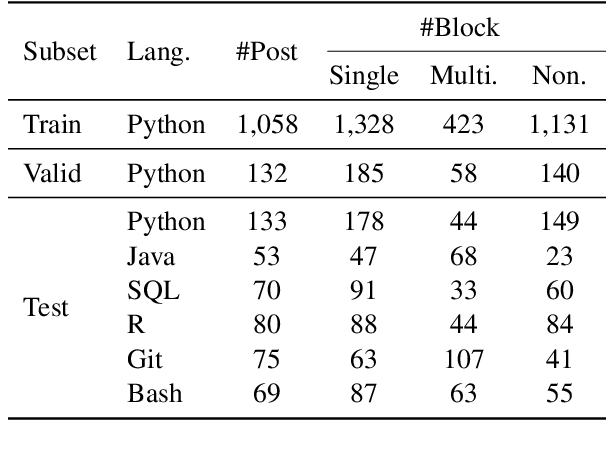
Mining aligned natural language (NL) and programming language (PL) pairs is a critical task to NL-PL understanding. Existing methods applied specialized hand-crafted features or separately-trained models for each PL. However, they usually suffered from low transferability across multiple PLs, especially for niche PLs with less annotated data. Fortunately, a Stack Overflow answer post is essentially a sequence of text and code blocks and its global textual context can provide PL-agnostic supplementary information. In this paper, we propose a Sequence Labeling based Question Answering (SLQA) method to mine NL-PL pairs in a PL-agnostic manner. In particular, we propose to apply the BIO tagging scheme instead of the conventional binary scheme to mine the code solutions which are often composed of multiple blocks of a post. Experiments on current single-PL single-block benchmarks and a manually-labeled cross-PL multi-block benchmark prove the effectiveness and transferability of SLQA. We further present a parallel NL-PL corpus named Lang2Code automatically mined with SLQA, which contains about 1.4M pairs on 6 PLs. Under statistical analysis and downstream evaluation, we demonstrate that Lang2Code is a large-scale high-quality data resource for further NL-PL research.