 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeg2Track++: Probabilistic Track Validation and Data Association for Multi-Object Tracking and Segmentation
Jun 02, 2026Autonomous systems require robust Multi-Object Tracking and Segmentation (MOTS) to operate reliably in dynamic environments, ensuring consistent object identities and precise mask-level delineation. Foundation models such as SAM2 have shown strong zero-shot generalization for segmentation, but their direct application to MOTS is limited by unreliable track association and false-positive propagation. This work introduces Seg2Track++, a framework that integrates instance segmentation with SAM2 and a novel track management module to perform zero-shot MOTS with enhanced temporal consistency. Tracks are associated using Mask Centroid Distance (MCD) and Confidence-Aware Cost Modulation (CCM), while Probabilistic Track Validation (PTV) employs a Bernoulli filter to validate track existence and suppress ghost tracks. Experimental results on KITTI MOTS demonstrate improved identity preservation, reduced false-positive propagation, and robust track management without fine-tuning.
Semantic-weighted ICP for LiDAR Odometry: Class-Aware Residual Reweighting for Robust Scan Registration
Jun 02, 2026LiDAR odometry is a fundamental component of autonomous robotic systems, relying on geometric registration between consecutive point clouds to estimate ego-motion. However, traditional geometric approaches often degrade in dynamic or unstructured environments due to unreliable correspondences caused by moving objects, sparse geometric features, vegetation, and semantically ambiguous structures. Existing works have shown that, some of these limitations can be addressed by introducing semantic information from the environment in the registration process. In this work, we build on this, and show that not all elements in the environment are equally relevant for registration. Hence, we propose a semantic class-weighted ICP for LiDAR odometry. Instead of strictly filtering out points belonging to specific semantic classes, the proposed approach weights the residuals of points belonging to semantic categories based on their expected geometric stability. This strategy enables informative but potentially unstable structures, to contribute to the registration process while mitigating the influence of dynamic objects. The experimental evaluation was conducted on the SemanticKITTI and RELLIS-3D datasets, which include urban, highway, rural, and off-road environments. The empirical results show that the proposed Semantic-weighted ICP improves pose estimation, especially in challenging off-road scenarios where conventional rigid features are scarce. Furthermore, the analysis reveals that the effectiveness of this weighting strategy is highly environment-dependent, influenced by the structural and semantic composition of the scene.
HortiMulti: A Multi-Sensor Dataset for Localisation and Mapping in Horticultural Polytunnels
Mar 23, 2026Agricultural robotics is gaining increasing relevance in both research and real-world deployment. As these systems are expected to operate autonomously in more complex tasks, the availability of representative real-world datasets becomes essential. While domains such as urban and forestry robotics benefit from large and established benchmarks, horticultural environments remain comparatively under-explored despite the economic significance of this sector. To address this gap, we present HortiMulti, a multimodal, cross-season dataset collected in commercial strawberry and raspberry polytunnels across an entire growing season, capturing substantial appearance variation, dynamic foliage, specular reflections from plastic covers, severe perceptual aliasing, and GNSS-unreliable conditions, all of which directly degrade existing localisation and perception algorithms. The sensor suite includes two 3D LiDARs, four RGB cameras, an IMU, GNSS, and wheel odometry. Ground truth trajectories are derived from a combination of Total Station surveying, AprilTag fiducial markers, and LiDAR-inertial odometry, spanning dense, sparse, and marker-free coverage to support evaluation under both controlled and realistic conditions. We release time-synchronised raw measurements, calibration files, reference trajectories, and baseline benchmarks for visual, LiDAR, and multi-sensor SLAM, with results confirming that current state-of-the-art methods remain inadequate for reliable polytunnel deployment, establishing HortiMulti as a one-stop resource for developing and testing robotic perception systems in horticulture environments.
Exploiting Object-based and Segmentation-based Semantic Features for Deep Learning-based Indoor Scene Classification
Apr 11, 2024Indoor scenes are usually characterized by scattered objects and their relationships, which turns the indoor scene classification task into a challenging computer vision task. Despite the significant performance boost in classification tasks achieved in recent years, provided by the use of deep-learning-based methods, limitations such as inter-category ambiguity and intra-category variation have been holding back their performance. To overcome such issues, gathering semantic information has been shown to be a promising source of information towards a more complete and discriminative feature representation of indoor scenes. Therefore, the work described in this paper uses both semantic information, obtained from object detection, and semantic segmentation techniques. While object detection techniques provide the 2D location of objects allowing to obtain spatial distributions between objects, semantic segmentation techniques provide pixel-level information that allows to obtain, at a pixel-level, a spatial distribution and shape-related features of the segmentation categories. Hence, a novel approach that uses a semantic segmentation mask to provide Hu-moments-based segmentation categories' shape characterization, designated by Segmentation-based Hu-Moments Features (SHMFs), is proposed. Moreover, a three-main-branch network, designated by GOS$^2$F$^2$App, that exploits deep-learning-based global features, object-based features, and semantic segmentation-based features is also proposed. GOS$^2$F$^2$App was evaluated in two indoor scene benchmark datasets: SUN RGB-D and NYU Depth V2, where, to the best of our knowledge, state-of-the-art results were achieved on both datasets, which present evidences of the effectiveness of the proposed approach.
Multispectral Image Segmentation in Agriculture: A Comprehensive Study on Fusion Approaches
Jul 31, 2023Multispectral imagery is frequently incorporated into agricultural tasks, providing valuable support for applications such as image segmentation, crop monitoring, field robotics, and yield estimation. From an image segmentation perspective, multispectral cameras can provide rich spectral information, helping with noise reduction and feature extraction. As such, this paper concentrates on the use of fusion approaches to enhance the segmentation process in agricultural applications. More specifically, in this work, we compare different fusion approaches by combining RGB and NDVI as inputs for crop row detection, which can be useful in autonomous robots operating in the field. The inputs are used individually as well as combined at different times of the process (early and late fusion) to perform classical and DL-based semantic segmentation. In this study, two agriculture-related datasets are subjected to analysis using both deep learning (DL)-based and classical segmentation methodologies. The experiments reveal that classical segmentation methods, utilizing techniques such as edge detection and thresholding, can effectively compete with DL-based algorithms, particularly in tasks requiring precise foreground-background separation. This suggests that traditional methods retain their efficacy in certain specialized applications within the agricultural domain. Moreover, among the fusion strategies examined, late fusion emerges as the most robust approach, demonstrating superiority in adaptability and effectiveness across varying segmentation scenarios. The dataset and code is available at https://github.com/Cybonic/MISAgriculture.git.
TReR: A Lightweight Transformer Re-Ranking Approach for 3D LiDAR Place Recognition
May 29, 2023



Autonomous driving systems often require reliable loop closure detection to guarantee reduced localization drift. Recently, 3D LiDAR-based localization methods have used retrieval-based place recognition to find revisited places efficiently. However, when deployed in challenging real-world scenarios, the place recognition models become more complex, which comes at the cost of high computational demand. This work tackles this problem from an information-retrieval perspective, adopting a first-retrieve-then-re-ranking paradigm, where an initial loop candidate ranking, generated from a 3D place recognition model, is re-ordered by a proposed lightweight transformer-based re-ranking approach (TReR). The proposed approach relies on global descriptors only, being agnostic to the place recognition model. The experimental evaluation, conducted on the KITTI Odometry dataset, where we compared TReR with s.o.t.a. re-ranking approaches such as alphaQE and SGV, indicate the robustness and efficiency when compared to alphaQE while offering a good trade-off between robustness and efficiency when compared to SGV.
Approaching Test Time Augmentation in the Context of Uncertainty Calibration for Deep Neural Networks
Apr 11, 2023



With the rise of Deep Neural Networks, machine learning systems are nowadays ubiquitous in a number of real-world applications, which bears the need for highly reliable models. This requires a thorough look not only at the accuracy of such systems, but also to their predictive uncertainty. Hence, we propose a novel technique (with two different variations, named M-ATTA and V-ATTA) based on test time augmentation, to improve the uncertainty calibration of deep models for image classification. Unlike other test time augmentation approaches, M/V-ATTA improves uncertainty calibration without affecting the model's accuracy, by leveraging an adaptive weighting system. We evaluate the performance of the technique with respect to different metrics of uncertainty calibration. Empirical results, obtained on CIFAR-10, CIFAR-100, as well as on the benchmark Aerial Image Dataset, indicate that the proposed approach outperforms state-of-the-art calibration techniques, while maintaining the baseline classification performance. Code for M/V-ATTA available at: https://github.com/pedrormconde/MV-ATTA.
A Deep Learning-based Global and Segmentation-based Semantic Feature Fusion Approach for Indoor Scene Classification
Feb 13, 2023



Indoor scene classification has become an important task in perception modules and has been widely used in various applications. However, problems such as intra-category variability and inter-category similarity have been holding back the models' performance, which leads to the need for new types of features to obtain a more meaningful scene representation. A semantic segmentation mask provides pixel-level information about the objects available in the scene, which makes it a promising source of information to obtain a more meaningful local representation of the scene. Therefore, in this work, a novel approach that uses a semantic segmentation mask to obtain a 2D spatial layout of the object categories across the scene, designated by segmentation-based semantic features (SSFs), is proposed. These features represent, per object category, the pixel count, as well as the 2D average position and respective standard deviation values. Moreover, a two-branch network, GS2F2App, that exploits CNN-based global features extracted from RGB images and the segmentation-based features extracted from the proposed SSFs, is also proposed. GS2F2App was evaluated in two indoor scene benchmark datasets: the SUN RGB-D and the NYU Depth V2, achieving state-of-the-art results on both datasets.
Journal Impact Factor and Peer Review Thoroughness and Helpfulness: A Supervised Machine Learning Study
Jul 23, 2022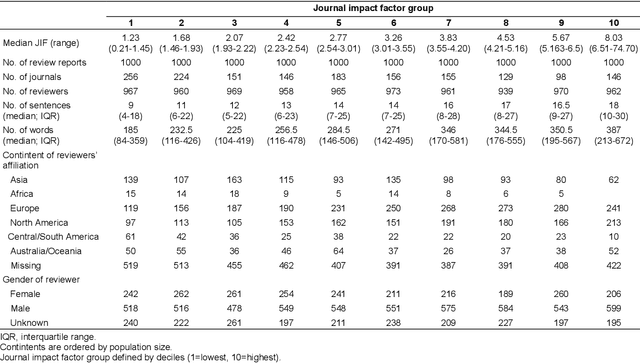
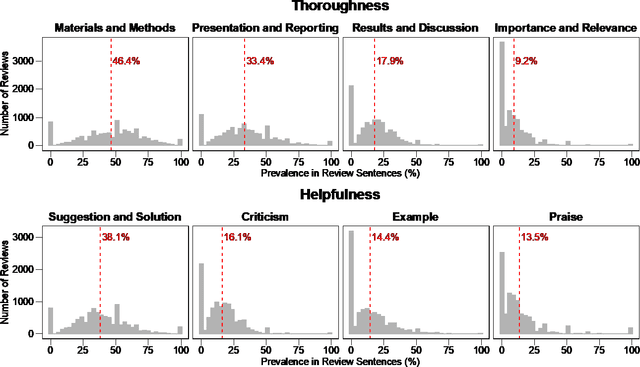
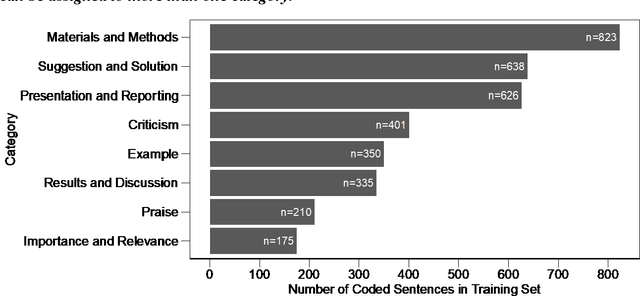
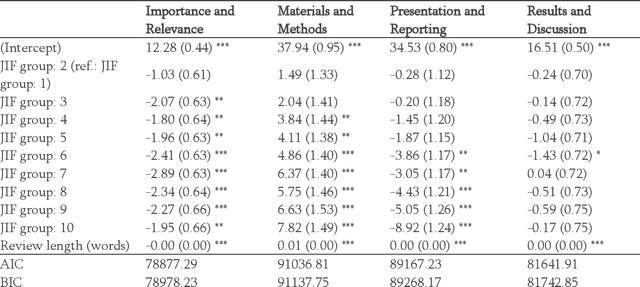
The journal impact factor (JIF) is often equated with journal quality and the quality of the peer review of the papers submitted to the journal. We examined the association between the content of peer review and JIF by analysing 10,000 peer review reports submitted to 1,644 medical and life sciences journals. Two researchers hand-coded a random sample of 2,000 sentences. We then trained machine learning models to classify all 187,240 sentences as contributing or not contributing to content categories. We examined the association between ten groups of journals defined by JIF deciles and the content of peer reviews using linear mixed-effects models, adjusting for the length of the review. The JIF ranged from 0.21 to 74.70. The length of peer reviews increased from the lowest (median number of words 185) to the JIF group (387 words). The proportion of sentences allocated to different content categories varied widely, even within JIF groups. For thoroughness, sentences on 'Materials and Methods' were more common in the highest JIF journals than in the lowest JIF group (difference of 7.8 percentage points; 95% CI 4.9 to 10.7%). The trend for 'Presentation and Reporting' went in the opposite direction, with the highest JIF journals giving less emphasis to such content (difference -8.9%; 95% CI -11.3 to -6.5%). For helpfulness, reviews for higher JIF journals devoted less attention to 'Suggestion and Solution' and provided fewer Examples than lower impact factor journals. No, or only small differences were evident for other content categories. In conclusion, peer review in journals with higher JIF tends to be more thorough in discussing the methods used but less helpful in terms of suggesting solutions and providing examples. Differences were modest and variability high, indicating that the JIF is a bad predictor for the quality of peer review of an individual manuscript.
Place recognition survey: An update on deep learning approaches
Jun 22, 2021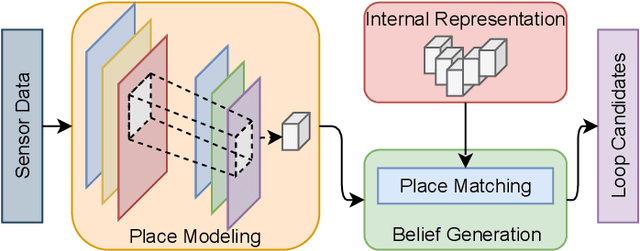

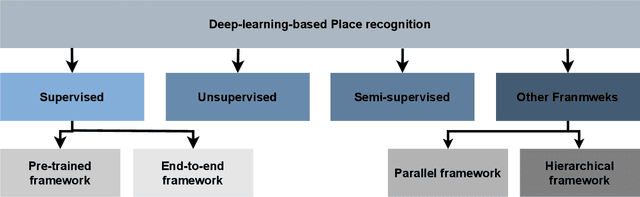
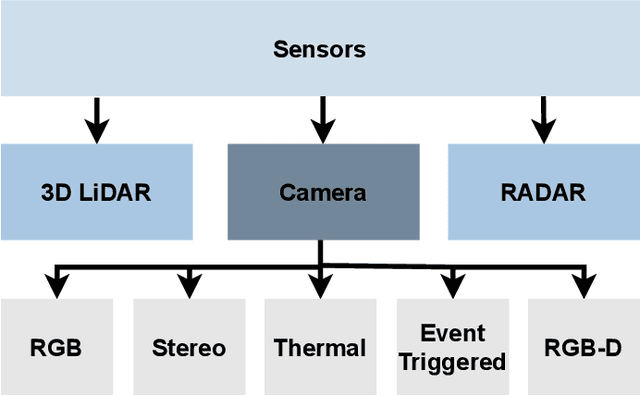
Autonomous Vehicles (AV) are becoming more capable of navigating in complex environments with dynamic and changing conditions. A key component that enables these intelligent vehicles to overcome such conditions and become more autonomous is the sophistication of the perception and localization systems. As part of the localization system, place recognition has benefited from recent developments in other perception tasks such as place categorization or object recognition, namely with the emergence of deep learning (DL) frameworks. This paper surveys recent approaches and methods used in place recognition, particularly those based on deep learning. The contributions of this work are twofold: surveying recent sensors such as 3D LiDARs and RADARs, applied in place recognition; and categorizing the various DL-based place recognition works into supervised, unsupervised, semi-supervised, parallel, and hierarchical categories. First, this survey introduces key place recognition concepts to contextualize the reader. Then, sensor characteristics are addressed. This survey proceeds by elaborating on the various DL-based works, presenting summaries for each framework. Some lessons learned from this survey include: the importance of NetVLAD for supervised end-to-end learning; the advantages of unsupervised approaches in place recognition, namely for cross-domain applications; or the increasing tendency of recent works to seek, not only for higher performance but also for higher efficiency.