 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Referring Video Object Segmentation with Inter-Frame Interaction and Cross-Modal Correlation
Jul 02, 2023
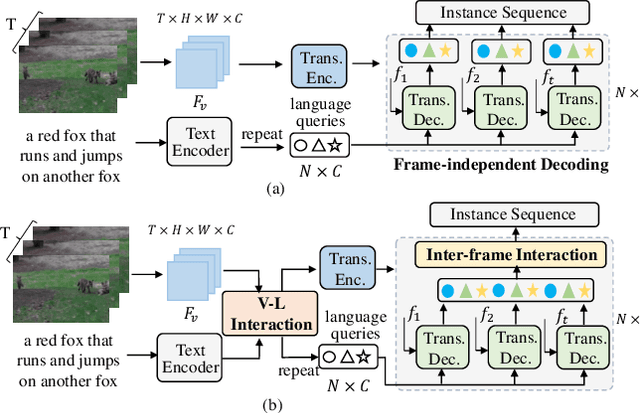
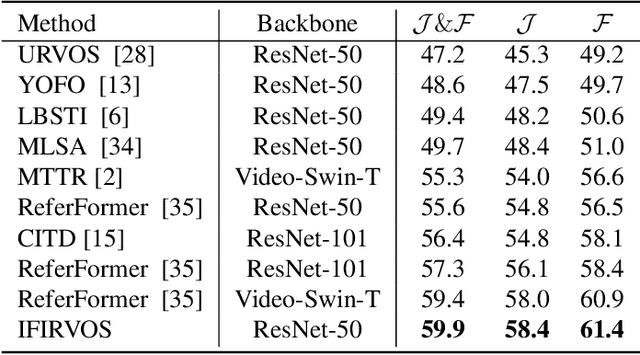
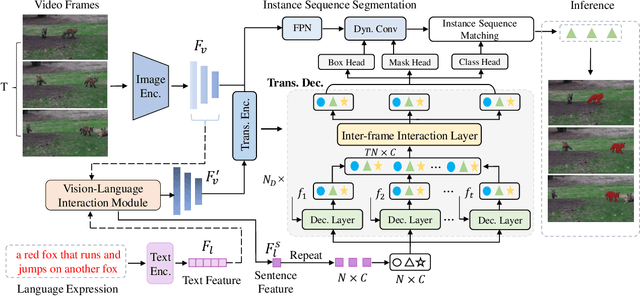
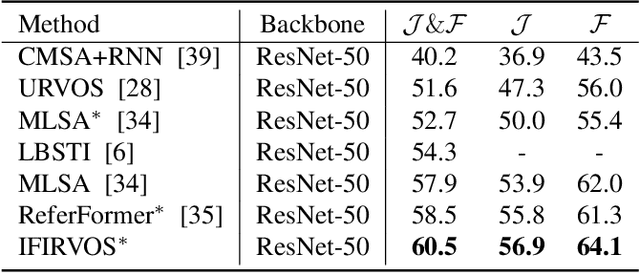
Referring video object segmentation (RVOS) aims to segment the target object in a video sequence described by a language expression. Typical query-based methods process the video sequence in a frame-independent manner to reduce the high computational cost, which however affects the performance due to the lack of inter-frame interaction for temporal coherence modeling and spatio-temporal representation learning of the referred object. Besides, they directly adopt the raw and high-level sentence feature as the language queries to decode the visual features, where the weak correlation between visual and linguistic features also increases the difficulty of decoding the target information and limits the performance of the model. In this paper, we proposes a novel RVOS framework, dubbed IFIRVOS, to address these issues. Specifically, we design a plug-and-play inter-frame interaction module in the Transformer decoder to efficiently learn the spatio-temporal features of the referred object, so as to decode the object information in the video sequence more precisely and generate more accurate segmentation results. Moreover, we devise the vision-language interaction module before the multimodal Transformer to enhance the correlation between the visual and linguistic features, thus facilitating the process of decoding object information from visual features by language queries in Transformer decoder and improving the segmentation performance. Extensive experimental results on three benchmarks validate the superiority of our IFIRVOS over state-of-the-art methods and the effectiveness of our proposed modules.
Comparison of Point Cloud and Image-based Models for Calorimeter Fast Simulation
Jul 10, 2023
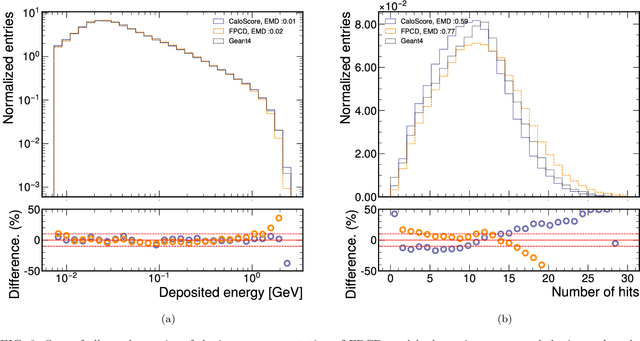
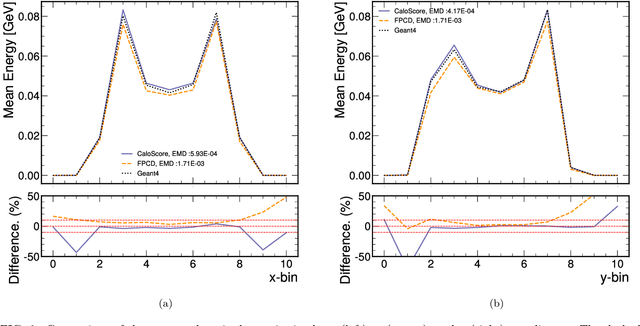
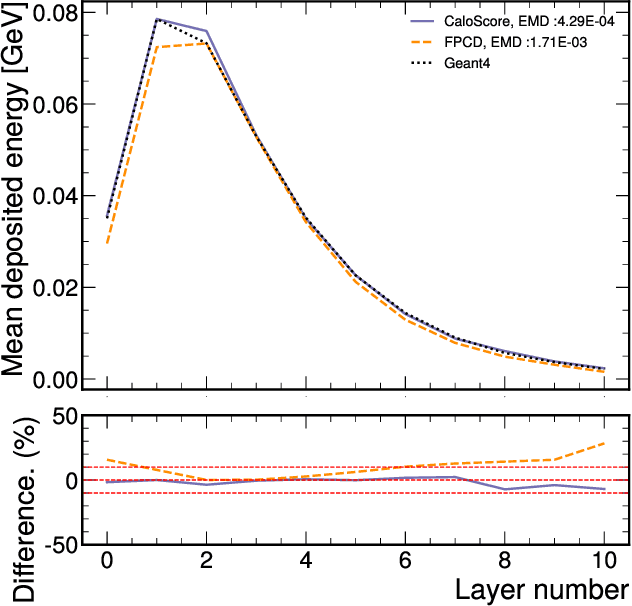
Score based generative models are a new class of generative models that have been shown to accurately generate high dimensional calorimeter datasets. Recent advances in generative models have used images with 3D voxels to represent and model complex calorimeter showers. Point clouds, however, are likely a more natural representation of calorimeter showers, particularly in calorimeters with high granularity. Point clouds preserve all of the information of the original simulation, more naturally deal with sparse datasets, and can be implemented with more compact models and data files. In this work, two state-of-the-art score based models are trained on the same set of calorimeter simulation and directly compared.
AE-RED: A Hyperspectral Unmixing Framework Powered by Deep Autoencoder and Regularization by Denoising
Jul 01, 2023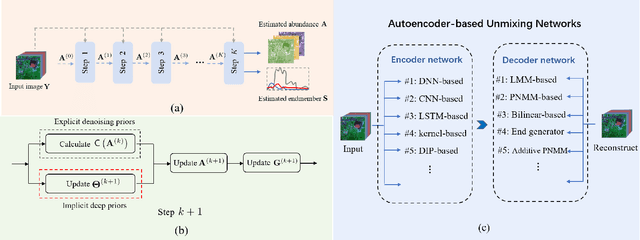
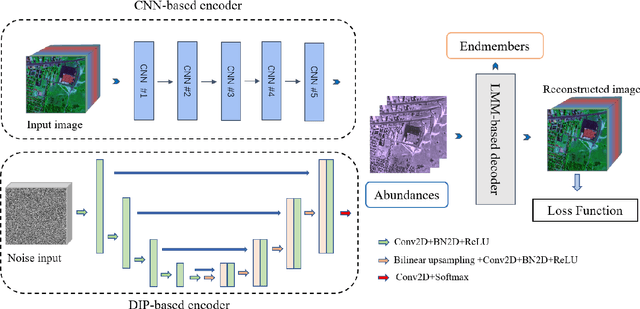
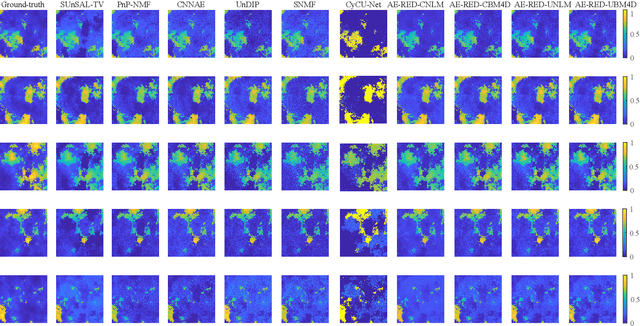
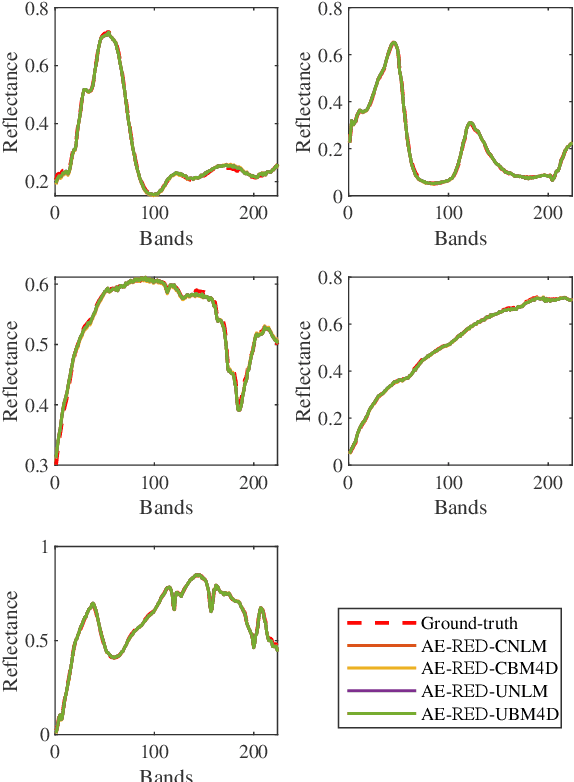
Spectral unmixing has been extensively studied with a variety of methods and used in many applications. Recently, data-driven techniques with deep learning methods have obtained great attention to spectral unmixing for its superior learning ability to automatically learn the structure information. In particular, autoencoder based architectures are elaborately designed to solve blind unmixing and model complex nonlinear mixtures. Nevertheless, these methods perform unmixing task as blackboxes and lack of interpretability. On the other hand, conventional unmixing methods carefully design the regularizer to add explicit information, in which algorithms such as plug-and-play (PnP) strategies utilize off-the-shelf denoisers to plug powerful priors. In this paper, we propose a generic unmixing framework to integrate the autoencoder network with regularization by denoising (RED), named AE-RED. More specially, we decompose the unmixing optimized problem into two subproblems. The first one is solved using deep autoencoders to implicitly regularize the estimates and model the mixture mechanism. The second one leverages the denoiser to bring in the explicit information. In this way, both the characteristics of the deep autoencoder based unmixing methods and priors provided by denoisers are merged into our well-designed framework to enhance the unmixing performance. Experiment results on both synthetic and real data sets show the superiority of our proposed framework compared with state-of-the-art unmixing approaches.
On decoder-only architecture for speech-to-text and large language model integration
Jul 14, 2023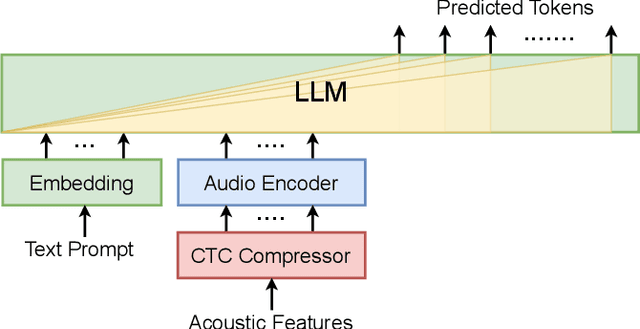
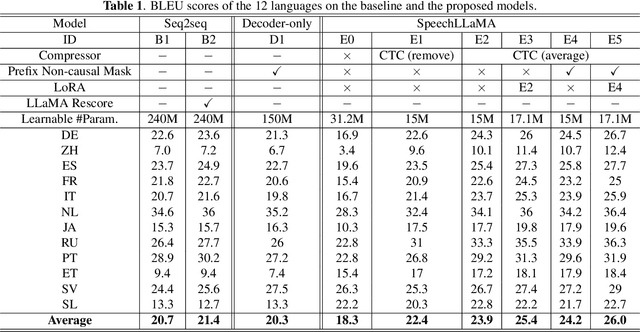
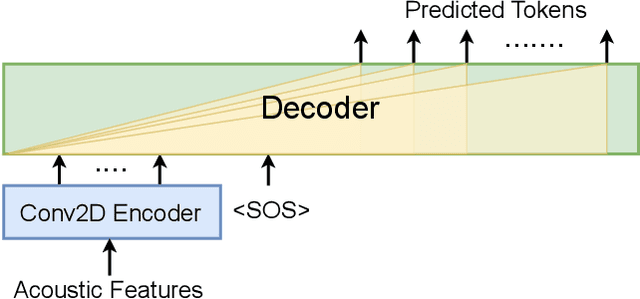
Large language models (LLMs) have achieved remarkable success in the field of natural language processing, enabling better human-computer interaction using natural language. However, the seamless integration of speech signals into LLMs has not been explored well. The "decoder-only" architecture has also not been well studied for speech processing tasks. In this research, we introduce Speech-LLaMA, a novel approach that effectively incorporates acoustic information into text-based large language models. Our method leverages Connectionist Temporal Classification and a simple audio encoder to map the compressed acoustic features to the continuous semantic space of the LLM. In addition, we further probe the decoder-only architecture for speech-to-text tasks by training a smaller scale randomly initialized speech-LLaMA model from speech-text paired data alone. We conduct experiments on multilingual speech-to-text translation tasks and demonstrate a significant improvement over strong baselines, highlighting the potential advantages of decoder-only models for speech-to-text conversion.
The CHiME-7 DASR Challenge: Distant Meeting Transcription with Multiple Devices in Diverse Scenarios
Jul 14, 2023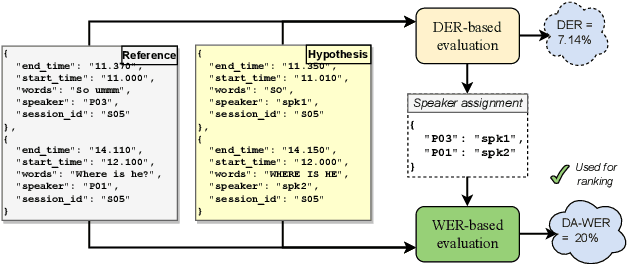
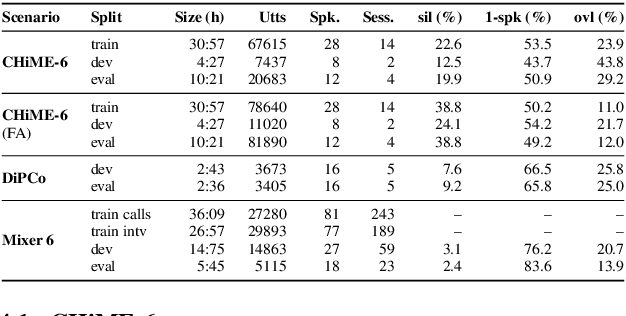
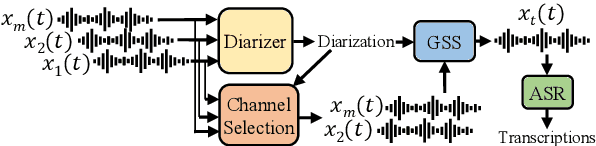
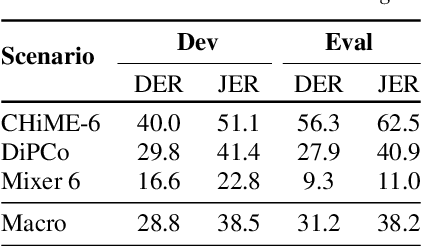
The CHiME challenges have played a significant role in the development and evaluation of robust automatic speech recognition (ASR) systems. We introduce the CHiME-7 distant ASR (DASR) task, within the 7th CHiME challenge. This task comprises joint ASR and diarization in far-field settings with multiple, and possibly heterogeneous, recording devices. Different from previous challenges, we evaluate systems on 3 diverse scenarios: CHiME-6, DiPCo, and Mixer 6. The goal is for participants to devise a single system that can generalize across different array geometries and use cases with no a-priori information. Another departure from earlier CHiME iterations is that participants are allowed to use open-source pre-trained models and datasets. In this paper, we describe the challenge design, motivation, and fundamental research questions in detail. We also present the baseline system, which is fully array-topology agnostic and features multi-channel diarization, channel selection, guided source separation and a robust ASR model that leverages self-supervised speech representations (SSLR).
ACF-Net: An Attention-enhanced Co-interactive Fusion Network for Automated Structural Condition Assessment in Visual Inspection
Jul 14, 2023Efficiently monitoring the condition of civil infrastructures necessitates automating the structural condition assessment in visual inspection. This paper proposes an Attention-enhanced Co-interactive Fusion Network (ACF-Net) for automatic structural condition assessment in visual bridge inspection. The ACF-Net can simultaneously parse structural elements and segment surface defects on the elements in inspection images. It integrates two task-specific relearning subnets to extract task-specific features from an overall feature embedding and a co-interactive feature fusion module to capture the spatial correlation and facilitate information sharing between tasks. Experimental results demonstrate that the proposed ACF-Net outperforms the current state-of-the-art approaches, achieving promising performance with 92.11% mIoU for element parsing and 87.16% mIoU for corrosion segmentation on the new benchmark dataset Steel Bridge Condition Inspection Visual (SBCIV) testing set. An ablation study reveals the strengths of ACF-Net, and a case study showcases its capability to automate structural condition assessment. The code will be open-source after acceptance.
Improved Flood Insights: Diffusion-Based SAR to EO Image Translation
Jul 14, 2023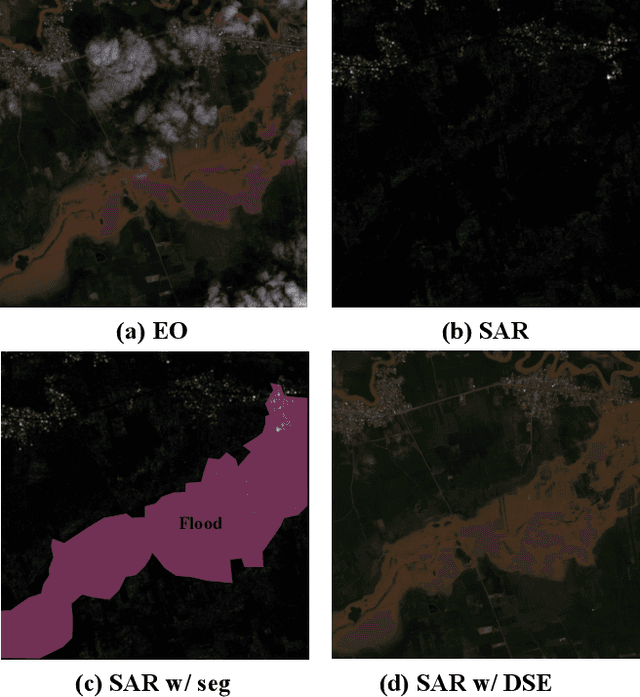
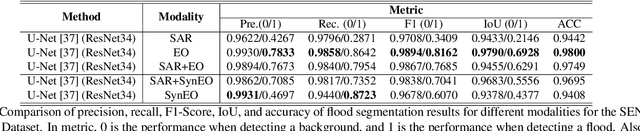
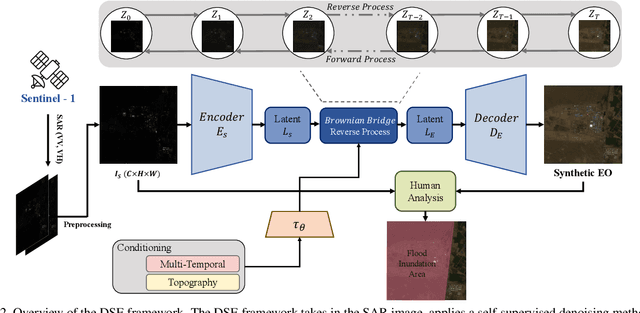
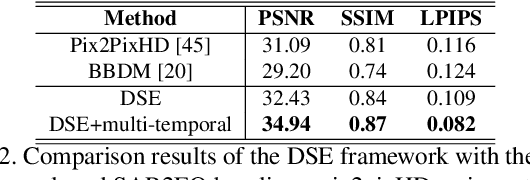
Driven by rapid climate change, the frequency and intensity of flood events are increasing. Electro-Optical (EO) satellite imagery is commonly utilized for rapid response. However, its utilities in flood situations are hampered by issues such as cloud cover and limitations during nighttime, making accurate assessment of damage challenging. Several alternative flood detection techniques utilizing Synthetic Aperture Radar (SAR) data have been proposed. Despite the advantages of SAR over EO in the aforementioned situations, SAR presents a distinct drawback: human analysts often struggle with data interpretation. To tackle this issue, this paper introduces a novel framework, Diffusion-Based SAR to EO Image Translation (DSE). The DSE framework converts SAR images into EO images, thereby enhancing the interpretability of flood insights for humans. Experimental results on the Sen1Floods11 and SEN12-FLOOD datasets confirm that the DSE framework not only delivers enhanced visual information but also improves performance across all tested flood segmentation baselines.
Vulnerability-Aware Instance Reweighting For Adversarial Training
Jul 14, 2023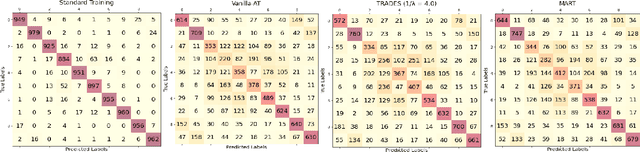


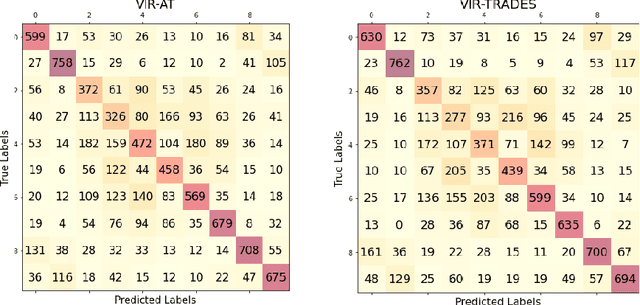
Adversarial Training (AT) has been found to substantially improve the robustness of deep learning classifiers against adversarial attacks. AT involves obtaining robustness by including adversarial examples in training a classifier. Most variants of AT algorithms treat every training example equally. However, recent works have shown that better performance is achievable by treating them unequally. In addition, it has been observed that AT exerts an uneven influence on different classes in a training set and unfairly hurts examples corresponding to classes that are inherently harder to classify. Consequently, various reweighting schemes have been proposed that assign unequal weights to robust losses of individual examples in a training set. In this work, we propose a novel instance-wise reweighting scheme. It considers the vulnerability of each natural example and the resulting information loss on its adversarial counterpart occasioned by adversarial attacks. Through extensive experiments, we show that our proposed method significantly improves over existing reweighting schemes, especially against strong white and black-box attacks.
Improving BERT with Hybrid Pooling Network and Drop Mask
Jul 14, 2023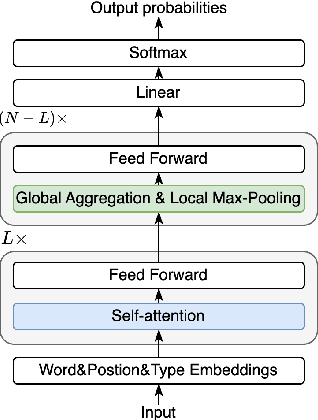
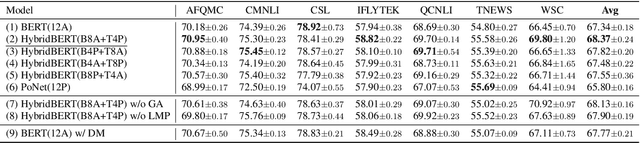
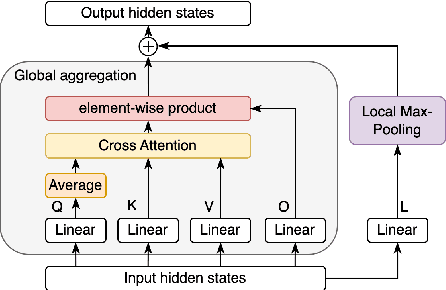
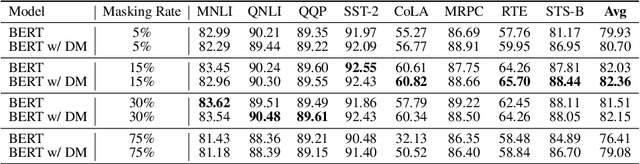
Transformer-based pre-trained language models, such as BERT, achieve great success in various natural language understanding tasks. Prior research found that BERT captures a rich hierarchy of linguistic information at different layers. However, the vanilla BERT uses the same self-attention mechanism for each layer to model the different contextual features. In this paper, we propose a HybridBERT model which combines self-attention and pooling networks to encode different contextual features in each layer. Additionally, we propose a simple DropMask method to address the mismatch between pre-training and fine-tuning caused by excessive use of special mask tokens during Masked Language Modeling pre-training. Experiments show that HybridBERT outperforms BERT in pre-training with lower loss, faster training speed (8% relative), lower memory cost (13% relative), and also in transfer learning with 1.5% relative higher accuracies on downstream tasks. Additionally, DropMask improves accuracies of BERT on downstream tasks across various masking rates.
LooPy: A Research-Friendly Mix Framework for Music Information Retrieval on Electronic Dance Music
May 01, 2023
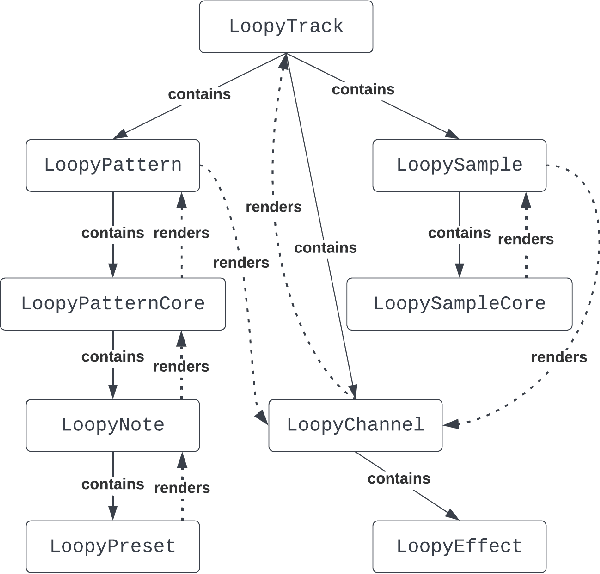
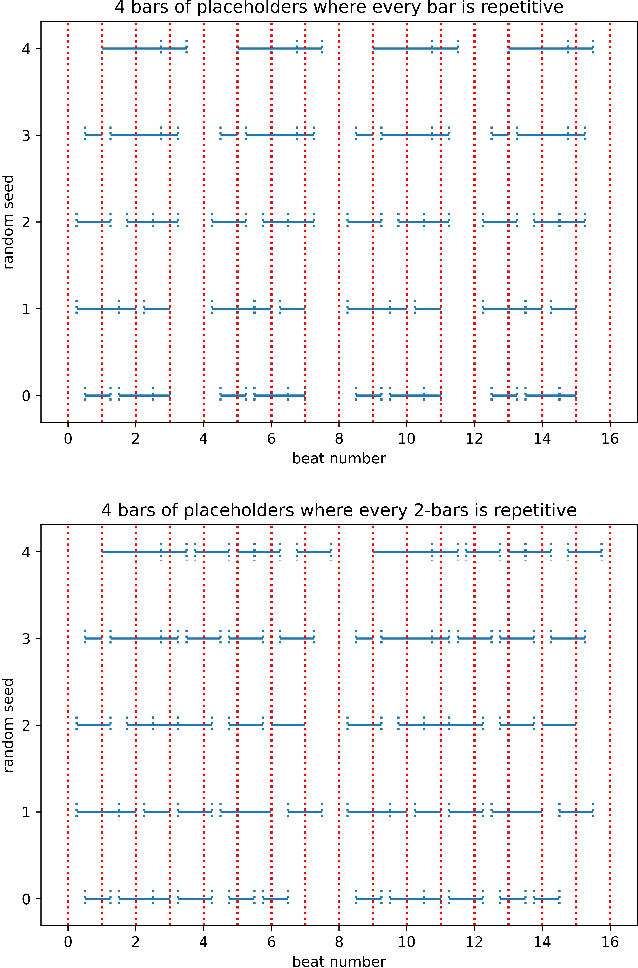
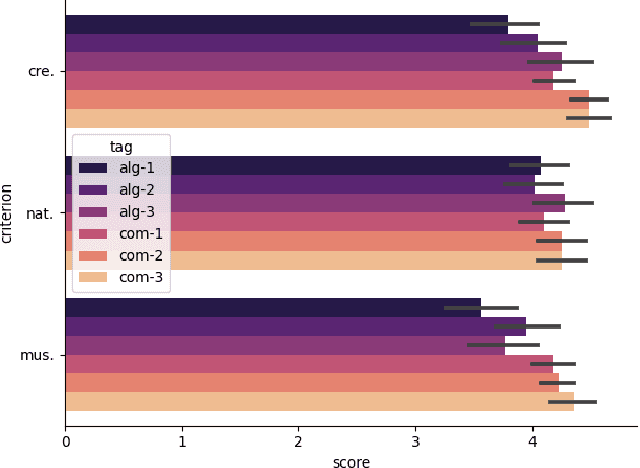
Music information retrieval (MIR) has gone through an explosive development with the advancement of deep learning in recent years. However, music genres like electronic dance music (EDM) has always been relatively less investigated compared to others. Considering its wide range of applications, we present a Python package for automated EDM audio generation as an infrastructure for MIR for EDM songs, to mitigate the difficulty of acquiring labelled data. It is a convenient tool that could be easily concatenated to the end of many symbolic music generation pipelines. Inside this package, we provide a framework to build professional-level templates that could render a well-produced track from specified melody and chords, or produce massive tracks given only a specific key by our probabilistic symbolic melody generator. Experiments show that our mixes could achieve the same quality of the original reference songs produced by world-famous artists, with respect to both subjective and objective criteria. Our code is accessible in this repository: https://github.com/Gariscat/loopy and the official site of the project is also online https://loopy4edm.com .