 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluoCLIP: Stain-Aware Focus Quality Assessment in Fluorescence Microscopy
Feb 27, 2026Accurate focus quality assessment (FQA) in fluorescence microscopy remains challenging, as the stain-dependent optical properties of fluorescent dyes cause abrupt and heterogeneous focus shifts. However, existing datasets and models overlook this variability, treating focus quality as a stain-agnostic problem. In this work, we formulate the task of stain-aware FQA, emphasizing that focus behavior in fluorescence microscopy must be modeled as a function of staining characteristics. Through quantitative analysis of existing datasets (FocusPath, BBBC006) and our newly curated FluoMix, we demonstrate that focus-rank relationships vary substantially across stains, underscoring the need for stain-aware modeling in fluorescence microscopy. To support this new formulation, we propose FluoMix, the first dataset for stain-aware FQA that encompasses multiple tissues, fluorescent stains, and focus variations. Building on this dataset, we propose FluoCLIP, a two-stage vision-language framework that leverages CLIP's alignment capability to interpret focus quality in the context of biological staining. In the stain-grounding phase, FluoCLIP learns general stain representations by aligning textual stain tokens with visual features, while in the stain-guided ranking phase, it optimizes stain-specific rank prompts for ordinal focus prediction. Together, our formulation, dataset, and framework establish the first foundation for stain-aware FQA, and FluoCLIP achieves strong generalization across diverse fluorescence microscopy conditions.
Improved Flood Insights: Diffusion-Based SAR to EO Image Translation
Jul 14, 2023



Driven by rapid climate change, the frequency and intensity of flood events are increasing. Electro-Optical (EO) satellite imagery is commonly utilized for rapid response. However, its utilities in flood situations are hampered by issues such as cloud cover and limitations during nighttime, making accurate assessment of damage challenging. Several alternative flood detection techniques utilizing Synthetic Aperture Radar (SAR) data have been proposed. Despite the advantages of SAR over EO in the aforementioned situations, SAR presents a distinct drawback: human analysts often struggle with data interpretation. To tackle this issue, this paper introduces a novel framework, Diffusion-Based SAR to EO Image Translation (DSE). The DSE framework converts SAR images into EO images, thereby enhancing the interpretability of flood insights for humans. Experimental results on the Sen1Floods11 and SEN12-FLOOD datasets confirm that the DSE framework not only delivers enhanced visual information but also improves performance across all tested flood segmentation baselines.
Training with the Invisibles: Obfuscating Images to Share Safely for Learning Visual Recognition Models
Jan 01, 2019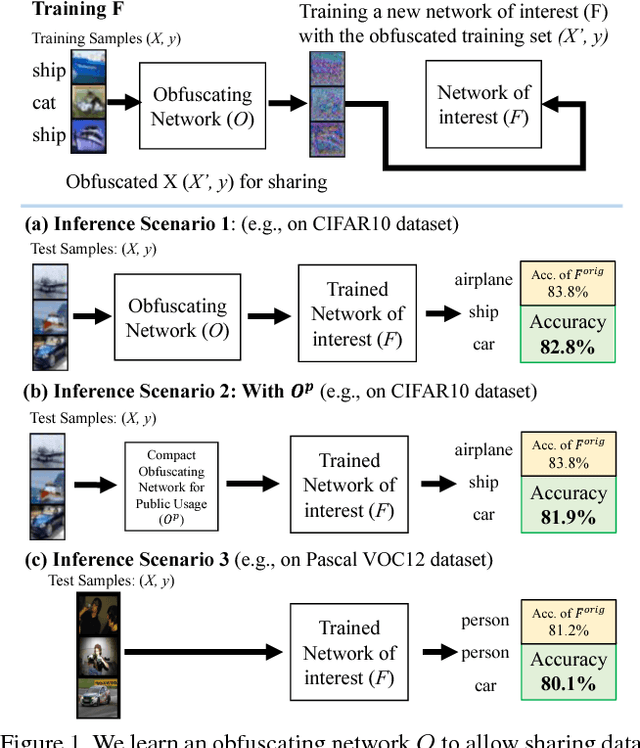
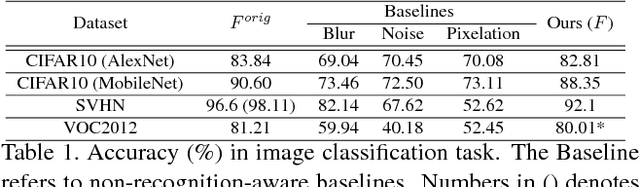

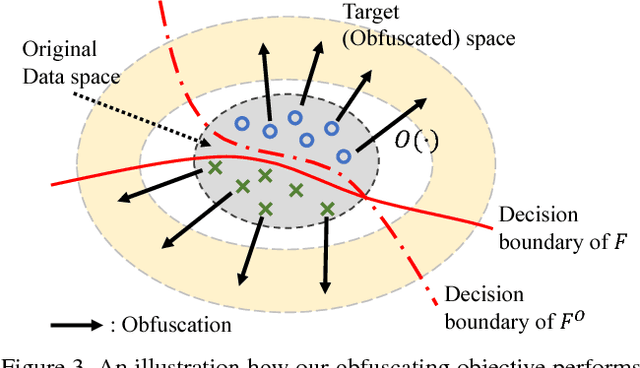
High-performance visual recognition systems generally require a large collection of labeled images to train. The expensive data curation can be an obstacle for improving recognition performance. Sharing more data allows training for better models. But personal and private information in the data prevent such sharing. To promote sharing visual data for learning a recognition model, we propose to obfuscate the images so that humans are not able to recognize their detailed contents, while machines can still utilize them to train new models. We validate our approach by comprehensive experiments on three challenging visual recognition tasks; image classification, attribute classification, and facial landmark detection on several datasets including SVHN, CIFAR10, Pascal VOC 2012, CelebA, and MTFL. Our method successfully obfuscates the images from humans recognition, but a machine model trained with them performs within about 1% margin (up to 0.48%) of the performance of a model trained with the original, non-obfuscated data.