 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Delphic Costs and Benefits in Web Search: A utilitarian and historical analysis
Aug 15, 2023
We present a new framework to conceptualize and operationalize the total user experience of search, by studying the entirety of a search journey from an utilitarian point of view. Web search engines are widely perceived as "free". But search requires time and effort: in reality there are many intermingled non-monetary costs (e.g. time costs, cognitive costs, interactivity costs) and the benefits may be marred by various impairments, such as misunderstanding and misinformation. This characterization of costs and benefits appears to be inherent to the human search for information within the pursuit of some larger task: most of the costs and impairments can be identified in interactions with any web search engine, interactions with public libraries, and even in interactions with ancient oracles. To emphasize this innate connection, we call these costs and benefits Delphic, in contrast to explicitly financial costs and benefits. Our main thesis is that the users' satisfaction with a search engine mostly depends on their experience of Delphic cost and benefits, in other words on their utility. The consumer utility is correlated with classic measures of search engine quality, such as ranking, precision, recall, etc., but is not completely determined by them. To argue our thesis, we catalog the Delphic costs and benefits and show how the development of search engines over the last quarter century, from classic Information Retrieval roots to the integration of Large Language Models, was driven to a great extent by the quest of decreasing Delphic costs and increasing Delphic benefits. We hope that the Delphic costs framework will engender new ideas and new research for evaluating and improving the web experience for everyone.
Deep reinforcement learning for process design: Review and perspective
Aug 15, 2023The transformation towards renewable energy and feedstock supply in the chemical industry requires new conceptual process design approaches. Recently, breakthroughs in artificial intelligence offer opportunities to accelerate this transition. Specifically, deep reinforcement learning, a subclass of machine learning, has shown the potential to solve complex decision-making problems and aid sustainable process design. We survey state-of-the-art research in reinforcement learning for process design through three major elements: (i) information representation, (ii) agent architecture, and (iii) environment and reward. Moreover, we discuss perspectives on underlying challenges and promising future works to unfold the full potential of reinforcement learning for process design in chemical engineering.
Unlimited Knowledge Distillation for Action Recognition in the Dark
Aug 18, 2023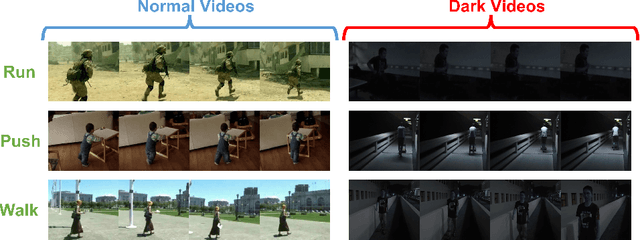

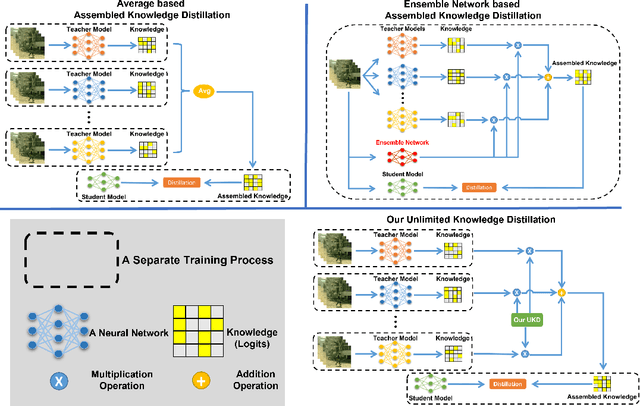

Dark videos often lose essential information, which causes the knowledge learned by networks is not enough to accurately recognize actions. Existing knowledge assembling methods require massive GPU memory to distill the knowledge from multiple teacher models into a student model. In action recognition, this drawback becomes serious due to much computation required by video process. Constrained by limited computation source, these approaches are infeasible. To address this issue, we propose an unlimited knowledge distillation (UKD) in this paper. Compared with existing knowledge assembling methods, our UKD can effectively assemble different knowledge without introducing high GPU memory consumption. Thus, the number of teaching models for distillation is unlimited. With our UKD, the network's learned knowledge can be remarkably enriched. Our experiments show that the single stream network distilled with our UKD even surpasses a two-stream network. Extensive experiments are conducted on the ARID dataset.
Null/No Information Rate (NIR): a statistical test to assess if a classification accuracy is significant for a given problem
Jun 09, 2023In many research contexts, especially in the biomedical field, after studying and developing a classification system a natural question arises: "Is this accuracy enough high?", or better, "Can we say, with a statistically significant confidence, that our classification system is able to solve the problem"? To answer to this question, we can use the statistical test described in this paper, which is referred in some cases as NIR (No Information Rate or Null Information Rate).
MIMO Radar Transmit Signal Optimization for Target Localization Exploiting Prior Information
May 15, 2023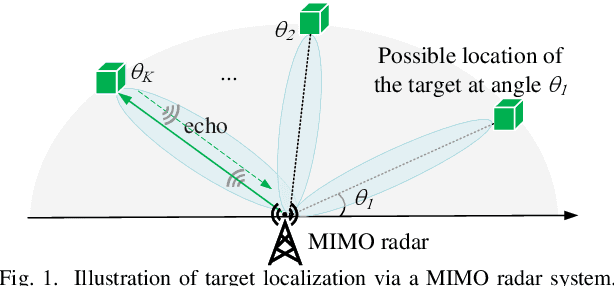
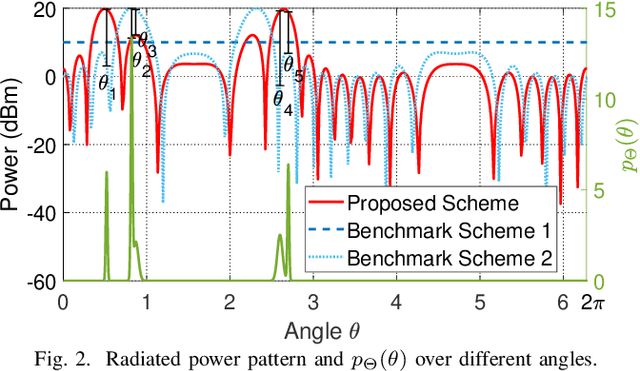
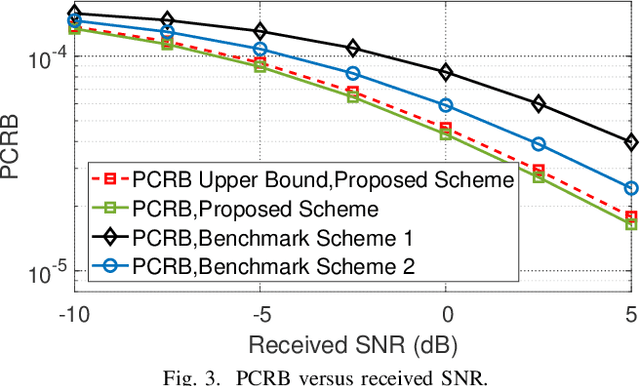
In this paper, we consider a multiple-input multiple-output (MIMO) radar system for localizing a target based on its reflected echo signals. Specifically, we aim to estimate the random and unknown angle information of the target, by exploiting its prior distribution information. First, we characterize the estimation performance by deriving the posterior Cram\'er-Rao bound (PCRB), which quantifies a lower bound of the estimation mean-squared error (MSE). Since the PCRB is in a complicated form, we derive a tight upper bound of it to approximate the estimation performance. Based on this, we analytically show that by exploiting the prior distribution information, the PCRB is always no larger than the Cram\'er-Rao bound (CRB) averaged over random angle realizations without prior information exploitation. Next, we formulate the transmit signal optimization problem to minimize the PCRB upper bound. We show that the optimal sample covariance matrix has a rank-one structure, and derive the optimal signal solution in closed form. Numerical results show that our proposed design achieves significantly improved PCRB performance compared to various benchmark schemes.
FoodSAM: Any Food Segmentation
Aug 11, 2023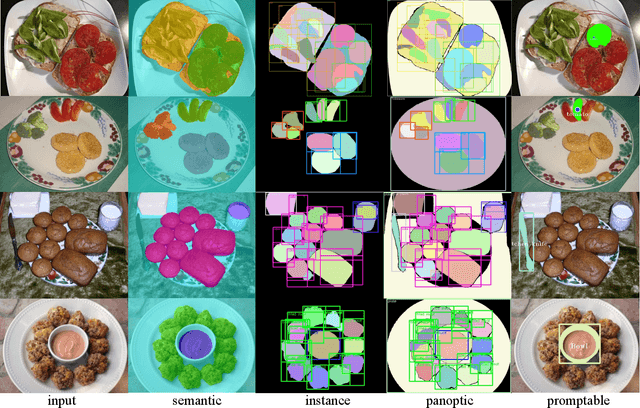
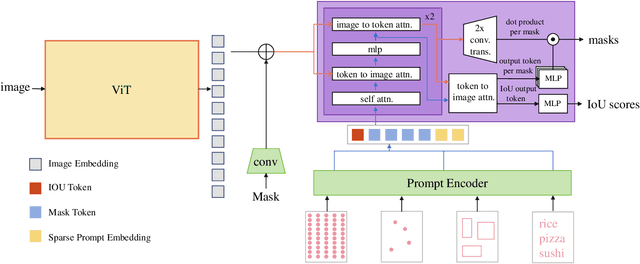
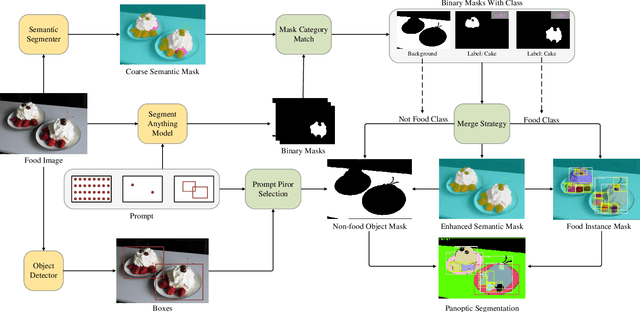
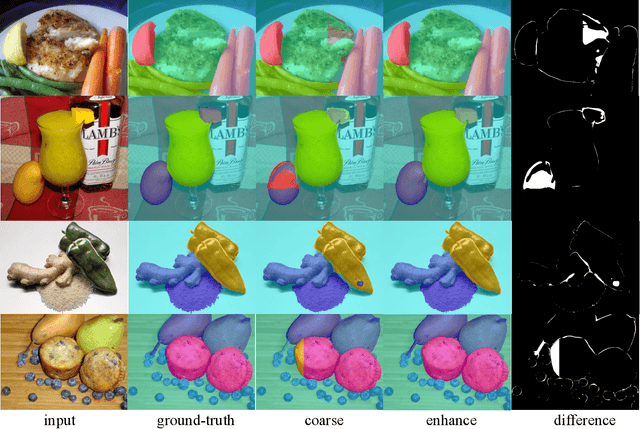
In this paper, we explore the zero-shot capability of the Segment Anything Model (SAM) for food image segmentation. To address the lack of class-specific information in SAM-generated masks, we propose a novel framework, called FoodSAM. This innovative approach integrates the coarse semantic mask with SAM-generated masks to enhance semantic segmentation quality. Besides, we recognize that the ingredients in food can be supposed as independent individuals, which motivated us to perform instance segmentation on food images. Furthermore, FoodSAM extends its zero-shot capability to encompass panoptic segmentation by incorporating an object detector, which renders FoodSAM to effectively capture non-food object information. Drawing inspiration from the recent success of promptable segmentation, we also extend FoodSAM to promptable segmentation, supporting various prompt variants. Consequently, FoodSAM emerges as an all-encompassing solution capable of segmenting food items at multiple levels of granularity. Remarkably, this pioneering framework stands as the first-ever work to achieve instance, panoptic, and promptable segmentation on food images. Extensive experiments demonstrate the feasibility and impressing performance of FoodSAM, validating SAM's potential as a prominent and influential tool within the domain of food image segmentation. We release our code at https://github.com/jamesjg/FoodSAM.
ShadowNet for Data-Centric Quantum System Learning
Aug 22, 2023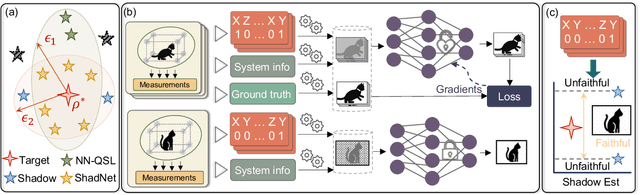
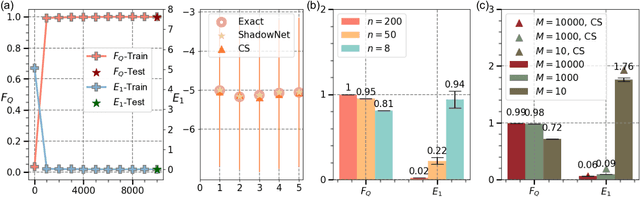
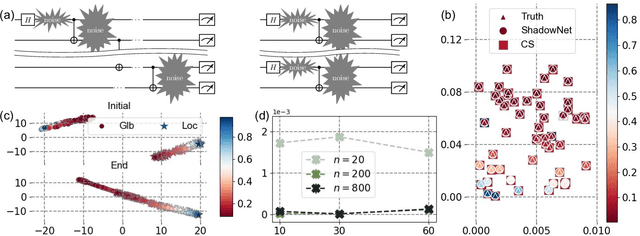
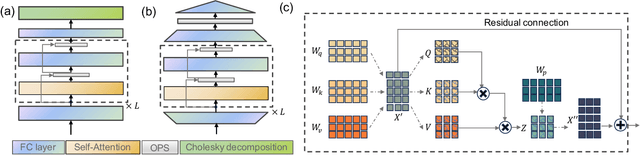
Understanding the dynamics of large quantum systems is hindered by the curse of dimensionality. Statistical learning offers new possibilities in this regime by neural-network protocols and classical shadows, while both methods have limitations: the former is plagued by the predictive uncertainty and the latter lacks the generalization ability. Here we propose a data-centric learning paradigm combining the strength of these two approaches to facilitate diverse quantum system learning (QSL) tasks. Particularly, our paradigm utilizes classical shadows along with other easily obtainable information of quantum systems to create the training dataset, which is then learnt by neural networks to unveil the underlying mapping rule of the explored QSL problem. Capitalizing on the generalization power of neural networks, this paradigm can be trained offline and excel at predicting previously unseen systems at the inference stage, even with few state copies. Besides, it inherits the characteristic of classical shadows, enabling memory-efficient storage and faithful prediction. These features underscore the immense potential of the proposed data-centric approach in discovering novel and large-scale quantum systems. For concreteness, we present the instantiation of our paradigm in quantum state tomography and direct fidelity estimation tasks and conduct numerical analysis up to 60 qubits. Our work showcases the profound prospects of data-centric artificial intelligence to advance QSL in a faithful and generalizable manner.
LAN-HDR: Luminance-based Alignment Network for High Dynamic Range Video Reconstruction
Aug 22, 2023As demands for high-quality videos continue to rise, high-resolution and high-dynamic range (HDR) imaging techniques are drawing attention. To generate an HDR video from low dynamic range (LDR) images, one of the critical steps is the motion compensation between LDR frames, for which most existing works employed the optical flow algorithm. However, these methods suffer from flow estimation errors when saturation or complicated motions exist. In this paper, we propose an end-to-end HDR video composition framework, which aligns LDR frames in the feature space and then merges aligned features into an HDR frame, without relying on pixel-domain optical flow. Specifically, we propose a luminance-based alignment network for HDR (LAN-HDR) consisting of an alignment module and a hallucination module. The alignment module aligns a frame to the adjacent reference by evaluating luminance-based attention, excluding color information. The hallucination module generates sharp details, especially for washed-out areas due to saturation. The aligned and hallucinated features are then blended adaptively to complement each other. Finally, we merge the features to generate a final HDR frame. In training, we adopt a temporal loss, in addition to frame reconstruction losses, to enhance temporal consistency and thus reduce flickering. Extensive experiments demonstrate that our method performs better or comparable to state-of-the-art methods on several benchmarks.
DiffCloth: Diffusion Based Garment Synthesis and Manipulation via Structural Cross-modal Semantic Alignment
Aug 22, 2023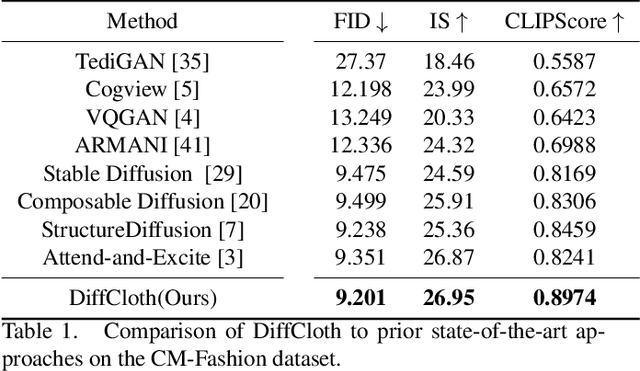

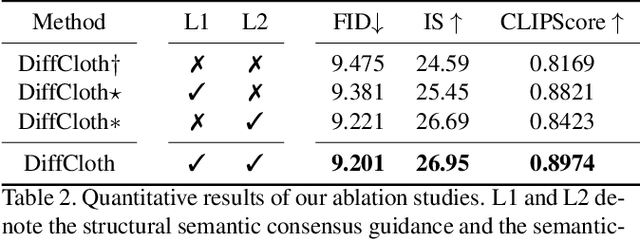
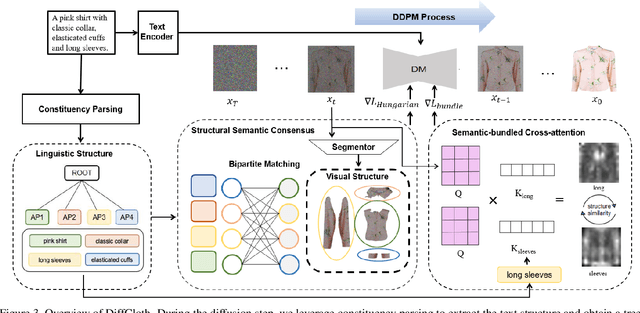
Cross-modal garment synthesis and manipulation will significantly benefit the way fashion designers generate garments and modify their designs via flexible linguistic interfaces.Current approaches follow the general text-to-image paradigm and mine cross-modal relations via simple cross-attention modules, neglecting the structural correspondence between visual and textual representations in the fashion design domain. In this work, we instead introduce DiffCloth, a diffusion-based pipeline for cross-modal garment synthesis and manipulation, which empowers diffusion models with flexible compositionality in the fashion domain by structurally aligning the cross-modal semantics. Specifically, we formulate the part-level cross-modal alignment as a bipartite matching problem between the linguistic Attribute-Phrases (AP) and the visual garment parts which are obtained via constituency parsing and semantic segmentation, respectively. To mitigate the issue of attribute confusion, we further propose a semantic-bundled cross-attention to preserve the spatial structure similarities between the attention maps of attribute adjectives and part nouns in each AP. Moreover, DiffCloth allows for manipulation of the generated results by simply replacing APs in the text prompts. The manipulation-irrelevant regions are recognized by blended masks obtained from the bundled attention maps of the APs and kept unchanged. Extensive experiments on the CM-Fashion benchmark demonstrate that DiffCloth both yields state-of-the-art garment synthesis results by leveraging the inherent structural information and supports flexible manipulation with region consistency.
Pose2Gait: Extracting Gait Features from Monocular Video of Individuals with Dementia
Aug 22, 2023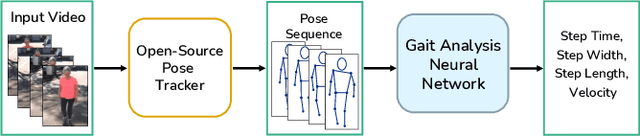

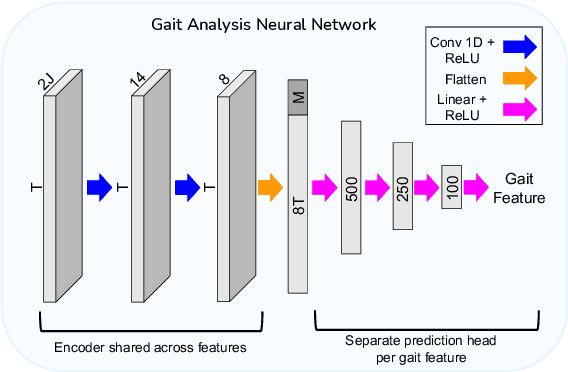

Video-based ambient monitoring of gait for older adults with dementia has the potential to detect negative changes in health and allow clinicians and caregivers to intervene early to prevent falls or hospitalizations. Computer vision-based pose tracking models can process video data automatically and extract joint locations; however, publicly available models are not optimized for gait analysis on older adults or clinical populations. In this work we train a deep neural network to map from a two dimensional pose sequence, extracted from a video of an individual walking down a hallway toward a wall-mounted camera, to a set of three-dimensional spatiotemporal gait features averaged over the walking sequence. The data of individuals with dementia used in this work was captured at two sites using a wall-mounted system to collect the video and depth information used to train and evaluate our model. Our Pose2Gait model is able to extract velocity and step length values from the video that are correlated with the features from the depth camera, with Spearman's correlation coefficients of .83 and .60 respectively, showing that three dimensional spatiotemporal features can be predicted from monocular video. Future work remains to improve the accuracy of other features, such as step time and step width, and test the utility of the predicted values for detecting meaningful changes in gait during longitudinal ambient monitoring.