 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVIS: Adaptive Test-Time Scaling for Vision-Language Models
Jun 10, 2026Modern Vision-Language Models (VLMs) benefit from chain-of-thought prompting and test-time scaling, but these gains often come with prohibitive inference cost due to large visual contexts and long decoding chains. We view this cost through two coupled axes: Visual Context Scaling (VCS), which controls how much visual evidence is passed to the language model, and Visual Reasoning Scaling (VRS), which controls how much inference-time reasoning search is performed. Existing methods typically optimize one axis at a time, leaving the joint allocation of compute across these axes underexplored. We introduce Adaptive Visual Inference Scaling (AVIS), a lightweight policy that adapts both VCS and VRS per query. AVIS realizes VCS through Key Diversity Visual (KDV) pruning, a training-free $O(N)$ key-based rule for removing redundant visual tokens before prefilling, and realizes VRS through adaptive self-consistency, using a learned difficulty predictor to select the number of reasoning rollouts. AVIS is deployment-friendly and compatible with shared-prefill inference, where all rollouts reuse a single prefilling pass and KV cache. Across diverse image and video reasoning benchmarks, AVIS improves the accuracy--compute trade-off relative to VCS-only and VRS-only baselines, and remains effective on top of RL post-trained VLMs while keeping compute and latency low.
SEGA: Spectral-Energy Guided Attention for Resolution Extrapolation in Diffusion Transformers
May 21, 2026Diffusion transformers (DiTs) have emerged as a dominant architecture for text-to-image generation, yet their performance drops when generating at resolutions beyond their training range. Existing training-free approaches mitigate this by modifying inference-time attention behavior, often through Rotary Position Embeddings (RoPE) extrapolation combined with attention scaling. However, these strategies apply a uniform and content-agnostic scaling across RoPE components with distinct frequency characteristics, inducing a trade-off between preserving global structure and recovering fine detail. We introduce SEGA, a training-free method that dynamically scales attention across RoPE components according to the latent's spatial-frequency structure at each denoising step. This adaptive scaling improves both structural coherence and fine-detail fidelity. Experiments show that SEGA consistently improves high-resolution synthesis across multiple target resolutions, outperforming state-of-the-art training-free baselines.
Face2Scene: Using Facial Degradation as an Oracle for Diffusion-Based Scene Restoration
Mar 17, 2026Recent advances in image restoration have enabled high-fidelity recovery of faces from degraded inputs using reference-based face restoration models (Ref-FR). However, such methods focus solely on facial regions, neglecting degradation across the full scene, including body and background, which limits practical usability. Meanwhile, full-scene restorers often ignore degradation cues entirely, leading to underdetermined predictions and visual artifacts. In this work, we propose Face2Scene, a two-stage restoration framework that leverages the face as a perceptual oracle to estimate degradation and guide the restoration of the entire image. Given a degraded image and one or more identity references, we first apply a Ref-FR model to reconstruct high-quality facial details. From the restored-degraded face pair, we extract a face-derived degradation code that captures degradation attributes (e.g., noise, blur, compression), which is then transformed into multi-scale degradation-aware tokens. These tokens condition a diffusion model to restore the full scene in a single step, including the body and background. Extensive experiments demonstrate the superior effectiveness of the proposed method compared to state-of-the-art methods.
When Does RL Help Medical VLMs? Disentangling Vision, SFT, and RL Gains
Mar 01, 2026Reinforcement learning (RL) is increasingly used to post-train medical Vision-Language Models (VLMs), yet it remains unclear whether RL improves medical visual reasoning or mainly sharpens behaviors already induced by supervised fine-tuning (SFT). We present a controlled study that disentangles these effects along three axes: vision, SFT, and RL. Using MedMNIST as a multi-modality testbed, we probe visual perception by benchmarking VLM vision towers against vision-only baselines, quantify reasoning support and sampling efficiency via Accuracy@1 versus Pass@K, and evaluate when RL closes the support gap and how gains transfer across modalities. We find that RL is most effective when the model already has non-trivial support (high Pass@K): it primarily sharpens the output distribution, improving Acc@1 and sampling efficiency, while SFT expands support and makes RL effective. Based on these findings, we propose a boundary-aware recipe and instantiate it by RL post-training an OctoMed-initialized model on a small, balanced subset of PMC multiple-choice VQA, achieving strong average performance across six medical VQA benchmarks.
LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation
Feb 11, 2026Looped Transformers have emerged as an efficient and powerful class of models for reasoning in the language domain. Recent studies show that these models achieve strong performance on algorithmic and reasoning tasks, suggesting that looped architectures possess an inductive bias toward latent reasoning. However, prior approaches fix the number of loop iterations during training and inference, leaving open the question of whether these models can flexibly adapt their computational depth under variable compute budgets. We introduce LoopFormer, a looped Transformer trained on variable-length trajectories to enable budget-conditioned reasoning. Our core contribution is a shortcut-consistency training scheme that aligns trajectories of different lengths, ensuring that shorter loops yield informative representations while longer loops continue to refine them. LoopFormer conditions each loop on the current time and step size, enabling representations to evolve consistently across trajectories of varying length rather than drifting or stagnating. Empirically, LoopFormer demonstrates robust performance on language modeling and reasoning benchmarks even under aggressive compute constraints, while scaling gracefully with additional budget. These results show that looped Transformers are inherently suited for adaptive language modeling, opening a path toward controllable and budget-aware large language models.
Puzzle Curriculum GRPO for Vision-Centric Reasoning
Dec 16, 2025Recent reinforcement learning (RL) approaches like outcome-supervised GRPO have advanced chain-of-thought reasoning in Vision Language Models (VLMs), yet key issues linger: (i) reliance on costly and noisy hand-curated annotations or external verifiers; (ii) flat and sparse reward schemes in GRPO; and (iii) logical inconsistency between a chain's reasoning and its final answer. We present Puzzle Curriculum GRPO (PC-GRPO), a supervision-free recipe for RL with Verifiable Rewards (RLVR) that strengthens visual reasoning in VLMs without annotations or external verifiers. PC-GRPO replaces labels with three self-supervised puzzle environments: PatchFit, Rotation (with binary rewards) and Jigsaw (with graded partial credit mitigating reward sparsity). To counter flat rewards and vanishing group-relative advantages, we introduce a difficulty-aware curriculum that dynamically weights samples and peaks at medium difficulty. We further monitor Reasoning-Answer Consistency (RAC) during post-training: mirroring reports for vanilla GRPO in LLMs, RAC typically rises early then degrades; our curriculum delays this decline, and consistency-enforcing reward schemes further boost RAC. RAC correlates with downstream accuracy. Across diverse benchmarks and on Qwen-7B and Qwen-3B backbones, PC-GRPO improves reasoning quality, training stability, and end-task accuracy, offering a practical path to scalable, verifiable, and interpretable RL post-training for VLMs.
CARE-PD: A Multi-Site Anonymized Clinical Dataset for Parkinson's Disease Gait Assessment
Oct 05, 2025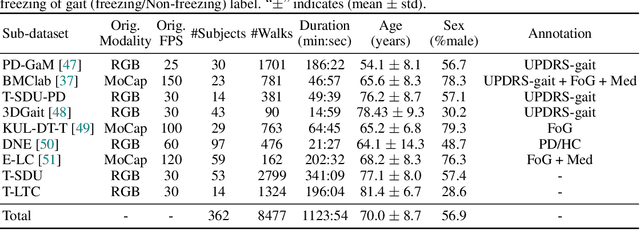
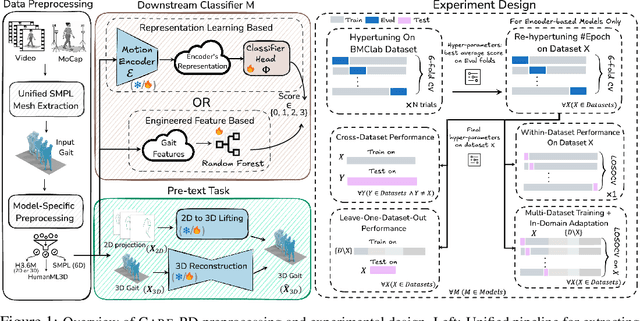
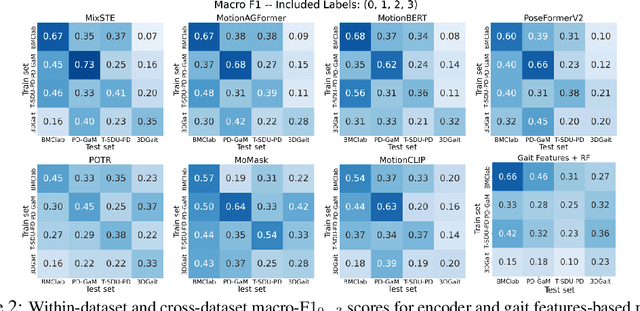
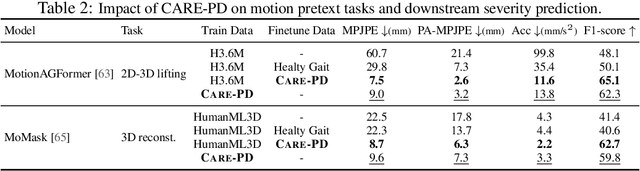
Objective gait assessment in Parkinson's Disease (PD) is limited by the absence of large, diverse, and clinically annotated motion datasets. We introduce CARE-PD, the largest publicly available archive of 3D mesh gait data for PD, and the first multi-site collection spanning 9 cohorts from 8 clinical centers. All recordings (RGB video or motion capture) are converted into anonymized SMPL meshes via a harmonized preprocessing pipeline. CARE-PD supports two key benchmarks: supervised clinical score prediction (estimating Unified Parkinson's Disease Rating Scale, UPDRS, gait scores) and unsupervised motion pretext tasks (2D-to-3D keypoint lifting and full-body 3D reconstruction). Clinical prediction is evaluated under four generalization protocols: within-dataset, cross-dataset, leave-one-dataset-out, and multi-dataset in-domain adaptation. To assess clinical relevance, we compare state-of-the-art motion encoders with a traditional gait-feature baseline, finding that encoders consistently outperform handcrafted features. Pretraining on CARE-PD reduces MPJPE (from 60.8mm to 7.5mm) and boosts PD severity macro-F1 by 17 percentage points, underscoring the value of clinically curated, diverse training data. CARE-PD and all benchmark code are released for non-commercial research at https://neurips2025.care-pd.ca/.
Mitigating Multi-Sequence 3D Prostate MRI Data Scarcity through Domain Adaptation using Locally-Trained Latent Diffusion Models for Prostate Cancer Detection
Jul 08, 2025Objective: Latent diffusion models (LDMs) could mitigate data scarcity challenges affecting machine learning development for medical image interpretation. The recent CCELLA LDM improved prostate cancer detection performance using synthetic MRI for classifier training but was limited to the axial T2-weighted (AxT2) sequence, did not investigate inter-institutional domain shift, and prioritized radiology over histopathology outcomes. We propose CCELLA++ to address these limitations and improve clinical utility. Methods: CCELLA++ expands CCELLA for simultaneous biparametric prostate MRI (bpMRI) generation, including the AxT2, high b-value diffusion series (HighB) and apparent diffusion coefficient map (ADC). Domain adaptation was investigated by pretraining classifiers on real or LDM-generated synthetic data from an internal institution, followed with fine-tuning on progressively smaller fractions of an out-of-distribution, external dataset. Results: CCELLA++ improved 3D FID for HighB and ADC but not AxT2 (0.013, 0.012, 0.063 respectively) sequences compared to CCELLA (0.060). Classifier pretraining with CCELLA++ bpMRI outperformed real bpMRI in AP and AUC for all domain adaptation scenarios. CCELLA++ pretraining achieved highest classifier performance below 50% (n=665) external dataset volume. Conclusion: Synthetic bpMRI generated by our method can improve downstream classifier generalization and performance beyond real bpMRI or CCELLA-generated AxT2-only images. Future work should seek to quantify medical image sample quality, balance multi-sequence LDM training, and condition the LDM with additional information. Significance: The proposed CCELLA++ LDM can generate synthetic bpMRI that outperforms real data for domain adaptation with a limited target institution dataset. Our code is available at https://github.com/grabkeem/CCELLA-plus-plus
Prompt-Guided Latent Diffusion with Predictive Class Conditioning for 3D Prostate MRI Generation
Jun 11, 2025



Latent diffusion models (LDM) could alleviate data scarcity challenges affecting machine learning development for medical imaging. However, medical LDM training typically relies on performance- or scientific accessibility-limiting strategies including a reliance on short-prompt text encoders, the reuse of non-medical LDMs, or a requirement for fine-tuning with large data volumes. We propose a Class-Conditioned Efficient Large Language model Adapter (CCELLA) to address these limitations. CCELLA is a novel dual-head conditioning approach that simultaneously conditions the LDM U-Net with non-medical large language model-encoded text features through cross-attention and with pathology classification through the timestep embedding. We also propose a joint loss function and a data-efficient LDM training framework. In combination, these strategies enable pathology-conditioned LDM training for high-quality medical image synthesis given limited data volume and human data annotation, improving LDM performance and scientific accessibility. Our method achieves a 3D FID score of 0.025 on a size-limited prostate MRI dataset, significantly outperforming a recent foundation model with FID 0.071. When training a classifier for prostate cancer prediction, adding synthetic images generated by our method to the training dataset improves classifier accuracy from 69% to 74%. Training a classifier solely on our method's synthetic images achieved comparable performance to training on real images alone.
Token Perturbation Guidance for Diffusion Models
Jun 10, 2025Classifier-free guidance (CFG) has become an essential component of modern diffusion models to enhance both generation quality and alignment with input conditions. However, CFG requires specific training procedures and is limited to conditional generation. To address these limitations, we propose Token Perturbation Guidance (TPG), a novel method that applies perturbation matrices directly to intermediate token representations within the diffusion network. TPG employs a norm-preserving shuffling operation to provide effective and stable guidance signals that improve generation quality without architectural changes. As a result, TPG is training-free and agnostic to input conditions, making it readily applicable to both conditional and unconditional generation. We further analyze the guidance term provided by TPG and show that its effect on sampling more closely resembles CFG compared to existing training-free guidance techniques. Extensive experiments on SDXL and Stable Diffusion 2.1 show that TPG achieves nearly a 2$\times$ improvement in FID for unconditional generation over the SDXL baseline, while closely matching CFG in prompt alignment. These results establish TPG as a general, condition-agnostic guidance method that brings CFG-like benefits to a broader class of diffusion models. The code is available at https://github.com/TaatiTeam/Token-Perturbation-Guidance