 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Skeleton-based Motion Encoder Models for Clinical Applications: Estimating Parkinson's Disease Severity in Walking Sequences
May 28, 2024



This study investigates the application of general human motion encoders trained on large-scale human motion datasets for analyzing gait patterns in PD patients. Although these models have learned a wealth of human biomechanical knowledge, their effectiveness in analyzing pathological movements, such as parkinsonian gait, has yet to be fully validated. We propose a comparative framework and evaluate six pre-trained state-of-the-art human motion encoder models on their ability to predict the Movement Disorder Society - Unified Parkinson's Disease Rating Scale (MDS-UPDRS-III) gait scores from motion capture data. We compare these against a traditional gait feature-based predictive model in a recently released large public PD dataset, including PD patients on and off medication. The feature-based model currently shows higher weighted average accuracy, precision, recall, and F1-score. Motion encoder models with closely comparable results demonstrate promise for scalability and efficiency in clinical settings. This potential is underscored by the enhanced performance of the encoder model upon fine-tuning on PD training set. Four of the six human motion models examined provided prediction scores that were significantly different between on- and off-medication states. This finding reveals the sensitivity of motion encoder models to nuanced clinical changes. It also underscores the necessity for continued customization of these models to better capture disease-specific features, thereby reducing the reliance on labor-intensive feature engineering. Lastly, we establish a benchmark for the analysis of skeleton-based motion encoder models in clinical settings. To the best of our knowledge, this is the first study to provide a benchmark that enables state-of-the-art models to be tested and compete in a clinical context. Codes and benchmark leaderboard are available at code.
Pose2Gait: Extracting Gait Features from Monocular Video of Individuals with Dementia
Aug 22, 2023



Video-based ambient monitoring of gait for older adults with dementia has the potential to detect negative changes in health and allow clinicians and caregivers to intervene early to prevent falls or hospitalizations. Computer vision-based pose tracking models can process video data automatically and extract joint locations; however, publicly available models are not optimized for gait analysis on older adults or clinical populations. In this work we train a deep neural network to map from a two dimensional pose sequence, extracted from a video of an individual walking down a hallway toward a wall-mounted camera, to a set of three-dimensional spatiotemporal gait features averaged over the walking sequence. The data of individuals with dementia used in this work was captured at two sites using a wall-mounted system to collect the video and depth information used to train and evaluate our model. Our Pose2Gait model is able to extract velocity and step length values from the video that are correlated with the features from the depth camera, with Spearman's correlation coefficients of .83 and .60 respectively, showing that three dimensional spatiotemporal features can be predicted from monocular video. Future work remains to improve the accuracy of other features, such as step time and step width, and test the utility of the predicted values for detecting meaningful changes in gait during longitudinal ambient monitoring.
Estimating Parkinsonism Severity in Natural Gait Videos of Older Adults with Dementia
May 07, 2021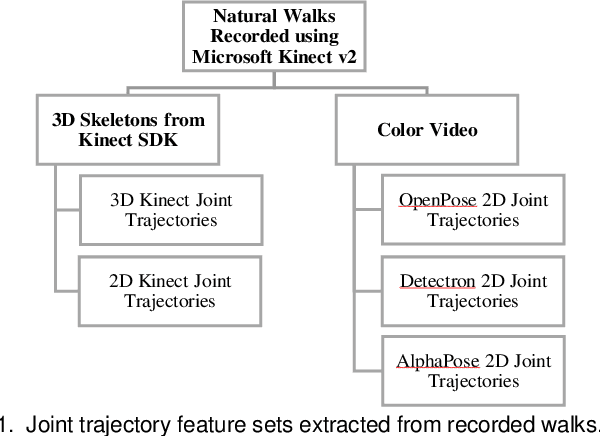


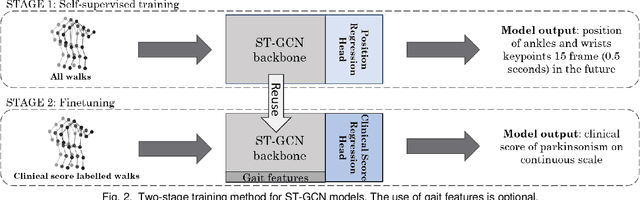
Drug-induced parkinsonism affects many older adults with dementia, often causing gait disturbances. New advances in vision-based human pose-estimation have opened possibilities for frequent and unobtrusive analysis of gait in residential settings. This work proposes novel spatial-temporal graph convolutional network (ST-GCN) architectures and training procedures to predict clinical scores of parkinsonism in gait from video of individuals with dementia. We propose a two-stage training approach consisting of a self-supervised pretraining stage that encourages the ST-GCN model to learn about gait patterns before predicting clinical scores in the finetuning stage. The proposed ST-GCN models are evaluated on joint trajectories extracted from video and are compared against traditional (ordinal, linear, random forest) regression models and temporal convolutional network baselines. Three 2D human pose-estimation libraries (OpenPose, Detectron, AlphaPose) and the Microsoft Kinect (2D and 3D) are used to extract joint trajectories of 4787 natural walking bouts from 53 older adults with dementia. A subset of 399 walks from 14 participants is annotated with scores of parkinsonism severity on the gait criteria of the Unified Parkinson's Disease Rating Scale (UPDRS) and the Simpson-Angus Scale (SAS). Our results demonstrate that ST-GCN models operating on 3D joint trajectories extracted from the Kinect consistently outperform all other models and feature sets. Prediction of parkinsonism scores in natural walking bouts of unseen participants remains a challenging task, with the best models achieving macro-averaged F1-scores of 0.53 +/- 0.03 and 0.40 +/- 0.02 for UPDRS-gait and SAS-gait, respectively. Pre-trained model and demo code for this work is available: https://github.com/TaatiTeam/stgcn_parkinsonism_prediction.