 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Ranking-aware Uncertainty for Text-guided Image Retrieval
Aug 16, 2023
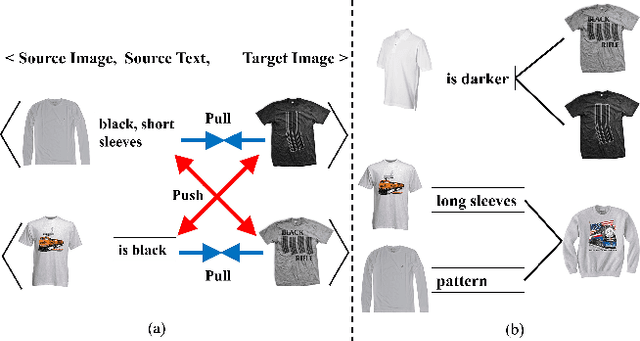
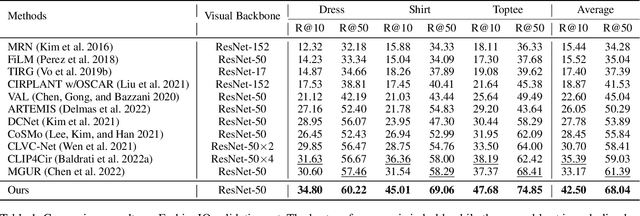
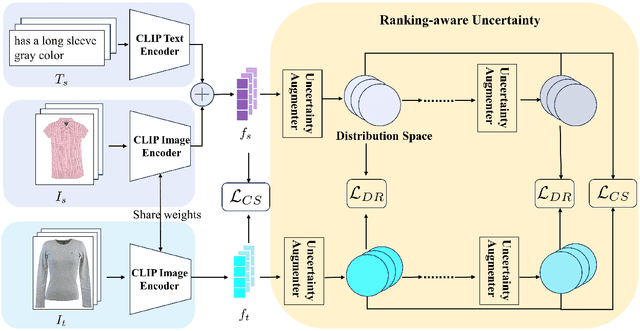
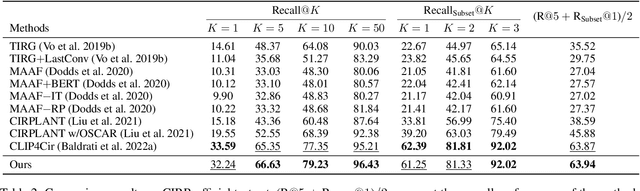
Text-guided image retrieval is to incorporate conditional text to better capture users' intent. Traditionally, the existing methods focus on minimizing the embedding distances between the source inputs and the targeted image, using the provided triplets $\langle$source image, source text, target image$\rangle$. However, such triplet optimization may limit the learned retrieval model to capture more detailed ranking information, e.g., the triplets are one-to-one correspondences and they fail to account for many-to-many correspondences arising from semantic diversity in feedback languages and images. To capture more ranking information, we propose a novel ranking-aware uncertainty approach to model many-to-many correspondences by only using the provided triplets. We introduce uncertainty learning to learn the stochastic ranking list of features. Specifically, our approach mainly comprises three components: (1) In-sample uncertainty, which aims to capture semantic diversity using a Gaussian distribution derived from both combined and target features; (2) Cross-sample uncertainty, which further mines the ranking information from other samples' distributions; and (3) Distribution regularization, which aligns the distributional representations of source inputs and targeted image. Compared to the existing state-of-the-art methods, our proposed method achieves significant results on two public datasets for composed image retrieval.
TeD-SPAD: Temporal Distinctiveness for Self-supervised Privacy-preservation for video Anomaly Detection
Aug 21, 2023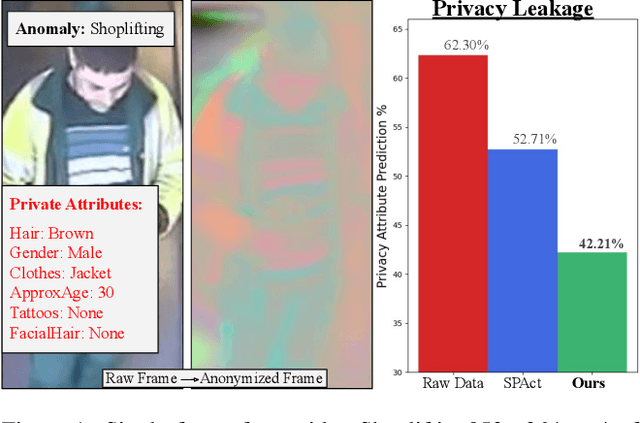

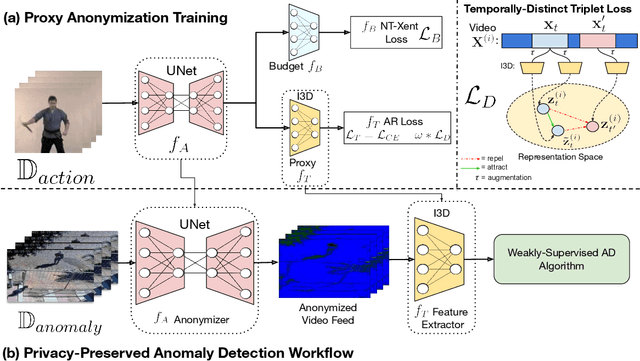

Video anomaly detection (VAD) without human monitoring is a complex computer vision task that can have a positive impact on society if implemented successfully. While recent advances have made significant progress in solving this task, most existing approaches overlook a critical real-world concern: privacy. With the increasing popularity of artificial intelligence technologies, it becomes crucial to implement proper AI ethics into their development. Privacy leakage in VAD allows models to pick up and amplify unnecessary biases related to people's personal information, which may lead to undesirable decision making. In this paper, we propose TeD-SPAD, a privacy-aware video anomaly detection framework that destroys visual private information in a self-supervised manner. In particular, we propose the use of a temporally-distinct triplet loss to promote temporally discriminative features, which complements current weakly-supervised VAD methods. Using TeD-SPAD, we achieve a positive trade-off between privacy protection and utility anomaly detection performance on three popular weakly supervised VAD datasets: UCF-Crime, XD-Violence, and ShanghaiTech. Our proposed anonymization model reduces private attribute prediction by 32.25% while only reducing frame-level ROC AUC on the UCF-Crime anomaly detection dataset by 3.69%. Project Page: https://joefioresi718.github.io/TeD-SPAD_webpage/
Is context all you need? Scaling Neural Sign Language Translation to Large Domains of Discourse
Aug 18, 2023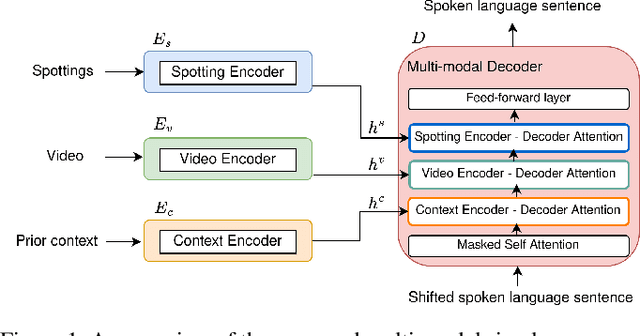
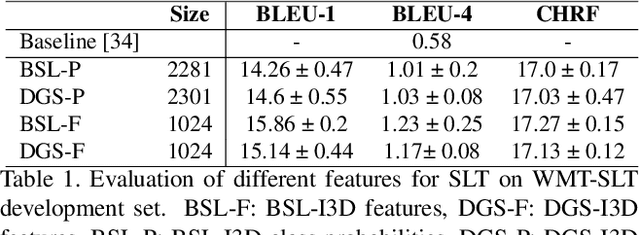
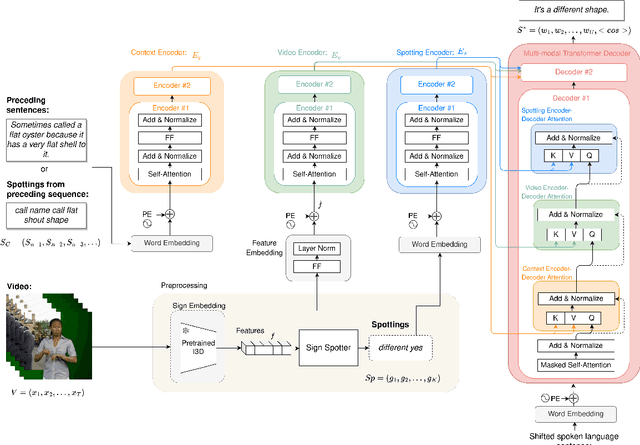
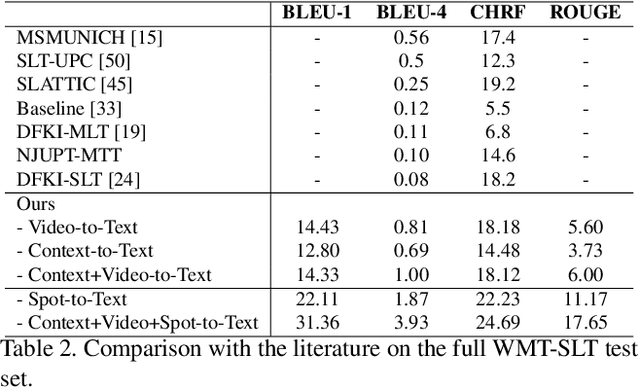
Sign Language Translation (SLT) is a challenging task that aims to generate spoken language sentences from sign language videos, both of which have different grammar and word/gloss order. From a Neural Machine Translation (NMT) perspective, the straightforward way of training translation models is to use sign language phrase-spoken language sentence pairs. However, human interpreters heavily rely on the context to understand the conveyed information, especially for sign language interpretation, where the vocabulary size may be significantly smaller than their spoken language equivalent. Taking direct inspiration from how humans translate, we propose a novel multi-modal transformer architecture that tackles the translation task in a context-aware manner, as a human would. We use the context from previous sequences and confident predictions to disambiguate weaker visual cues. To achieve this we use complementary transformer encoders, namely: (1) A Video Encoder, that captures the low-level video features at the frame-level, (2) A Spotting Encoder, that models the recognized sign glosses in the video, and (3) A Context Encoder, which captures the context of the preceding sign sequences. We combine the information coming from these encoders in a final transformer decoder to generate spoken language translations. We evaluate our approach on the recently published large-scale BOBSL dataset, which contains ~1.2M sequences, and on the SRF dataset, which was part of the WMT-SLT 2022 challenge. We report significant improvements on state-of-the-art translation performance using contextual information, nearly doubling the reported BLEU-4 scores of baseline approaches.
Audio is all in one: speech-driven gesture synthetics using WavLM pre-trained model
Aug 14, 2023
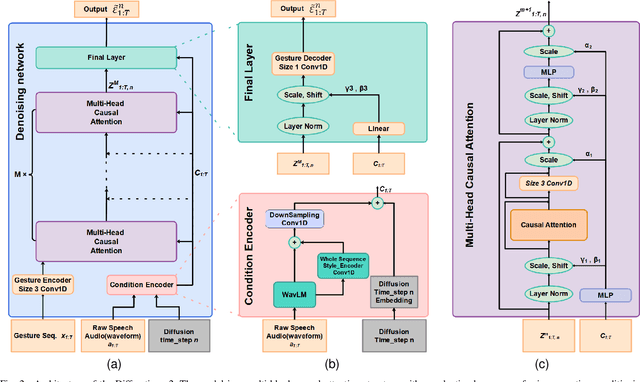
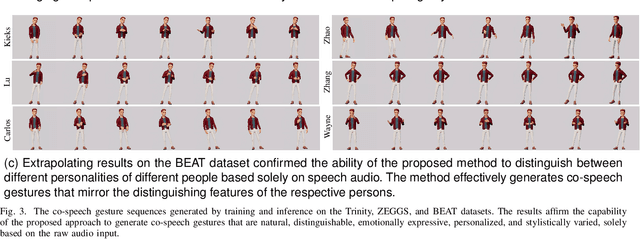
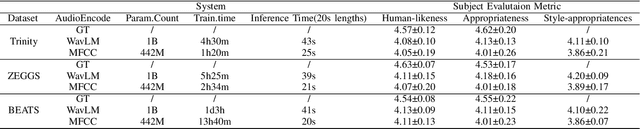
The generation of co-speech gestures for digital humans is an emerging area in the field of virtual human creation. Prior research has made progress by using acoustic and semantic information as input and adopting classify method to identify the person's ID and emotion for driving co-speech gesture generation. However, this endeavour still faces significant challenges. These challenges go beyond the intricate interplay between co-speech gestures, speech acoustic, and semantics; they also encompass the complexities associated with personality, emotion, and other obscure but important factors. This paper introduces "diffmotion-v2," a speech-conditional diffusion-based and non-autoregressive transformer-based generative model with WavLM pre-trained model. It can produce individual and stylized full-body co-speech gestures only using raw speech audio, eliminating the need for complex multimodal processing and manually annotated. Firstly, considering that speech audio not only contains acoustic and semantic features but also conveys personality traits, emotions, and more subtle information related to accompanying gestures, we pioneer the adaptation of WavLM, a large-scale pre-trained model, to extract low-level and high-level audio information. Secondly, we introduce an adaptive layer norm architecture in the transformer-based layer to learn the relationship between speech information and accompanying gestures. Extensive subjective evaluation experiments are conducted on the Trinity, ZEGGS, and BEAT datasets to confirm the WavLM and the model's ability to synthesize natural co-speech gestures with various styles.
On the Importance of Spatial Relations for Few-shot Action Recognition
Aug 14, 2023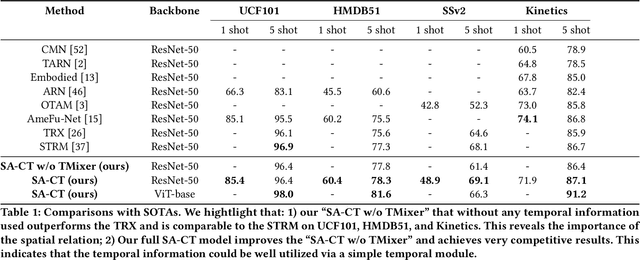
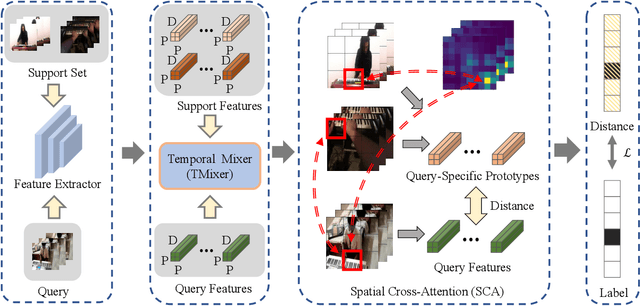
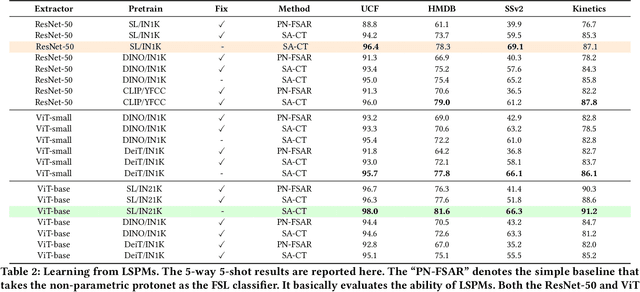
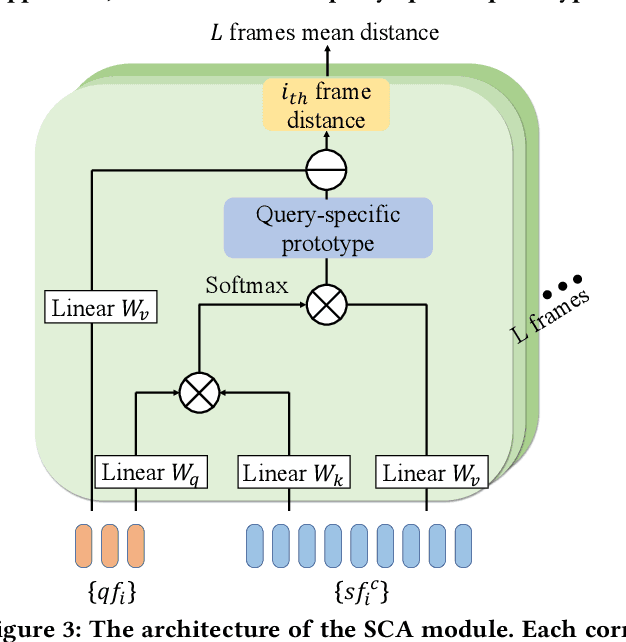
Deep learning has achieved great success in video recognition, yet still struggles to recognize novel actions when faced with only a few examples. To tackle this challenge, few-shot action recognition methods have been proposed to transfer knowledge from a source dataset to a novel target dataset with only one or a few labeled videos. However, existing methods mainly focus on modeling the temporal relations between the query and support videos while ignoring the spatial relations. In this paper, we find that the spatial misalignment between objects also occurs in videos, notably more common than the temporal inconsistency. We are thus motivated to investigate the importance of spatial relations and propose a more accurate few-shot action recognition method that leverages both spatial and temporal information. Particularly, a novel Spatial Alignment Cross Transformer (SA-CT) which learns to re-adjust the spatial relations and incorporates the temporal information is contributed. Experiments reveal that, even without using any temporal information, the performance of SA-CT is comparable to temporal based methods on 3/4 benchmarks. To further incorporate the temporal information, we propose a simple yet effective Temporal Mixer module. The Temporal Mixer enhances the video representation and improves the performance of the full SA-CT model, achieving very competitive results. In this work, we also exploit large-scale pretrained models for few-shot action recognition, providing useful insights for this research direction.
Fusing Monocular Images and Sparse IMU Signals for Real-time Human Motion Capture
Sep 01, 2023
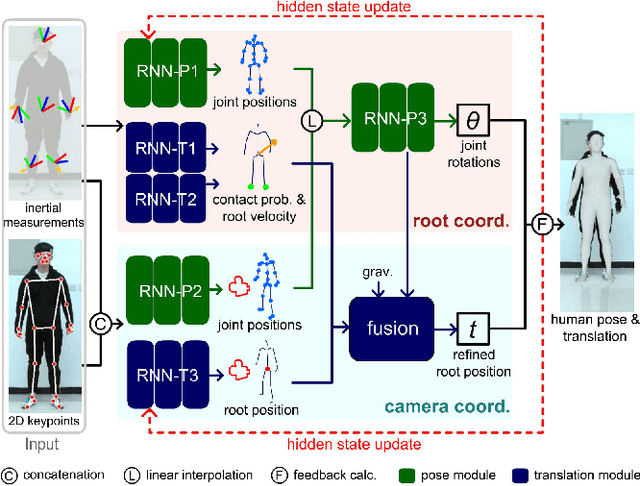
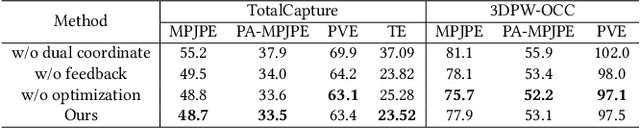

Either RGB images or inertial signals have been used for the task of motion capture (mocap), but combining them together is a new and interesting topic. We believe that the combination is complementary and able to solve the inherent difficulties of using one modality input, including occlusions, extreme lighting/texture, and out-of-view for visual mocap and global drifts for inertial mocap. To this end, we propose a method that fuses monocular images and sparse IMUs for real-time human motion capture. Our method contains a dual coordinate strategy to fully explore the IMU signals with different goals in motion capture. To be specific, besides one branch transforming the IMU signals to the camera coordinate system to combine with the image information, there is another branch to learn from the IMU signals in the body root coordinate system to better estimate body poses. Furthermore, a hidden state feedback mechanism is proposed for both two branches to compensate for their own drawbacks in extreme input cases. Thus our method can easily switch between the two kinds of signals or combine them in different cases to achieve a robust mocap. %The two divided parts can help each other for better mocap results under different conditions. Quantitative and qualitative results demonstrate that by delicately designing the fusion method, our technique significantly outperforms the state-of-the-art vision, IMU, and combined methods on both global orientation and local pose estimation. Our codes are available for research at https://shaohua-pan.github.io/robustcap-page/.
Large Content And Behavior Models To Understand, Simulate, And Optimize Content And Behavior
Sep 01, 2023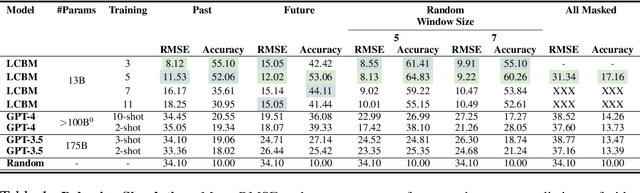
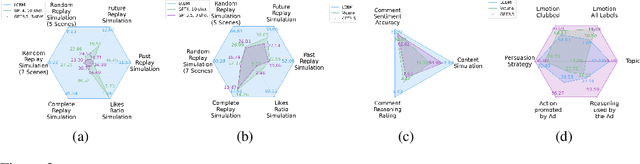
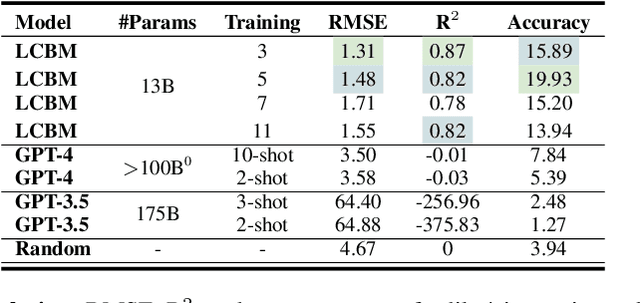
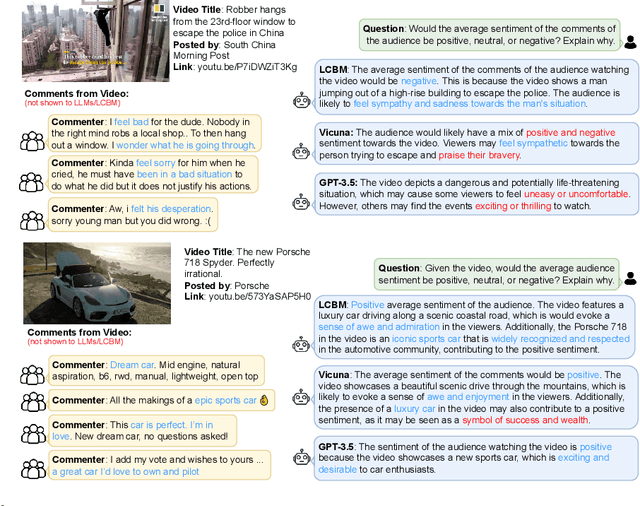
Shannon, in his seminal paper introducing information theory, divided the communication into three levels: technical, semantic, and effectivenss. While the technical level is concerned with accurate reconstruction of transmitted symbols, the semantic and effectiveness levels deal with the inferred meaning and its effect on the receiver. Thanks to telecommunications, the first level problem has produced great advances like the internet. Large Language Models (LLMs) make some progress towards the second goal, but the third level still remains largely untouched. The third problem deals with predicting and optimizing communication for desired receiver behavior. LLMs, while showing wide generalization capabilities across a wide range of tasks, are unable to solve for this. One reason for the underperformance could be a lack of "behavior tokens" in LLMs' training corpora. Behavior tokens define receiver behavior over a communication, such as shares, likes, clicks, purchases, retweets, etc. While preprocessing data for LLM training, behavior tokens are often removed from the corpora as noise. Therefore, in this paper, we make some initial progress towards reintroducing behavior tokens in LLM training. The trained models, other than showing similar performance to LLMs on content understanding tasks, show generalization capabilities on behavior simulation, content simulation, behavior understanding, and behavior domain adaptation. Using a wide range of tasks on two corpora, we show results on all these capabilities. We call these models Large Content and Behavior Models (LCBMs). Further, to spur more research on LCBMs, we release our new Content Behavior Corpus (CBC), a repository containing communicator, message, and corresponding receiver behavior.
The FruitShell French synthesis system at the Blizzard 2023 Challenge
Sep 01, 2023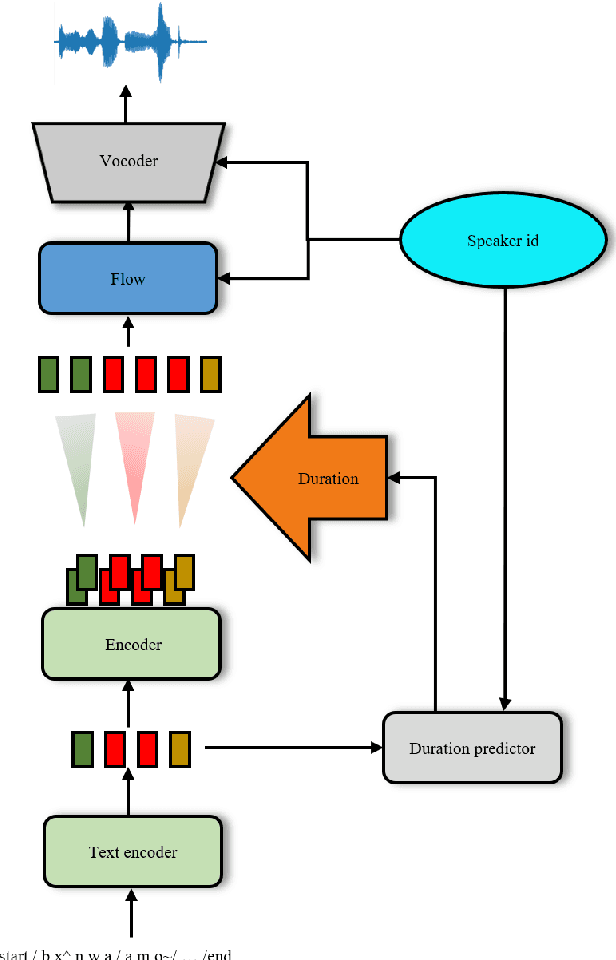
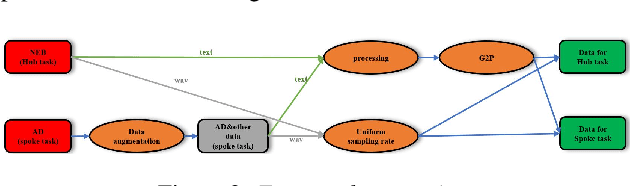
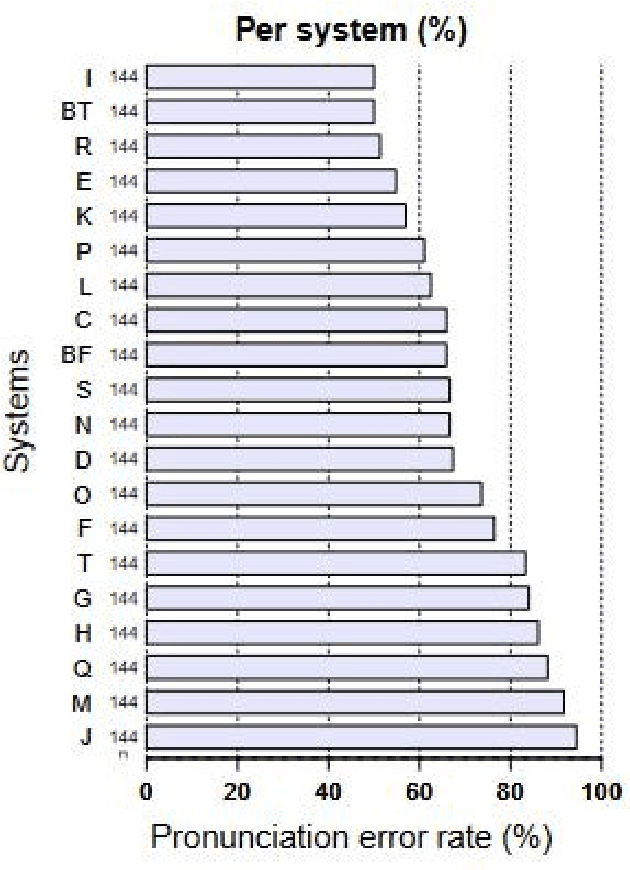
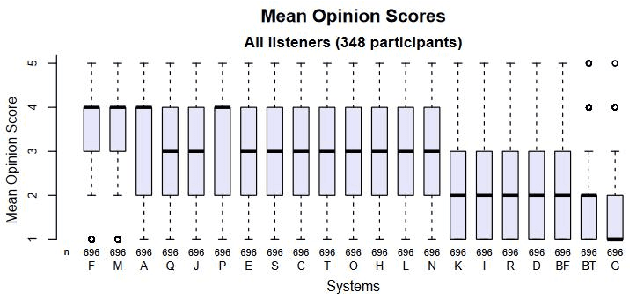
This paper presents a French text-to-speech synthesis system for the Blizzard Challenge 2023. The challenge consists of two tasks: generating high-quality speech from female speakers and generating speech that closely resembles specific individuals. Regarding the competition data, we conducted a screening process to remove missing or erroneous text data. We organized all symbols except for phonemes and eliminated symbols that had no pronunciation or zero duration. Additionally, we added word boundary and start/end symbols to the text, which we have found to improve speech quality based on our previous experience. For the Spoke task, we performed data augmentation according to the competition rules. We used an open-source G2P model to transcribe the French texts into phonemes. As the G2P model uses the International Phonetic Alphabet (IPA), we applied the same transcription process to the provided competition data for standardization. However, due to compiler limitations in recognizing special symbols from the IPA chart, we followed the rules to convert all phonemes into the phonetic scheme used in the competition data. Finally, we resampled all competition audio to a uniform sampling rate of 16 kHz. We employed a VITS-based acoustic model with the hifigan vocoder. For the Spoke task, we trained a multi-speaker model and incorporated speaker information into the duration predictor, vocoder, and flow layers of the model. The evaluation results of our system showed a quality MOS score of 3.6 for the Hub task and 3.4 for the Spoke task, placing our system at an average level among all participating teams.
Feature Modulation Transformer: Cross-Refinement of Global Representation via High-Frequency Prior for Image Super-Resolution
Aug 12, 2023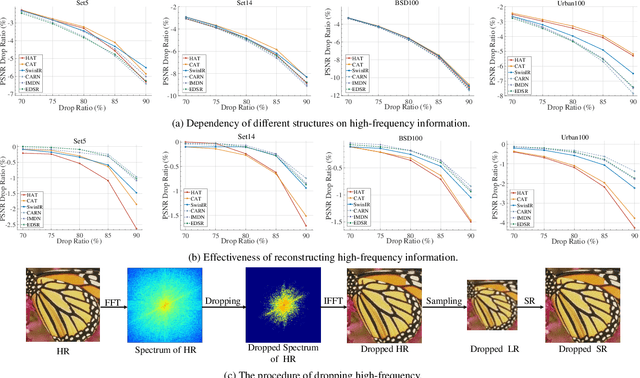
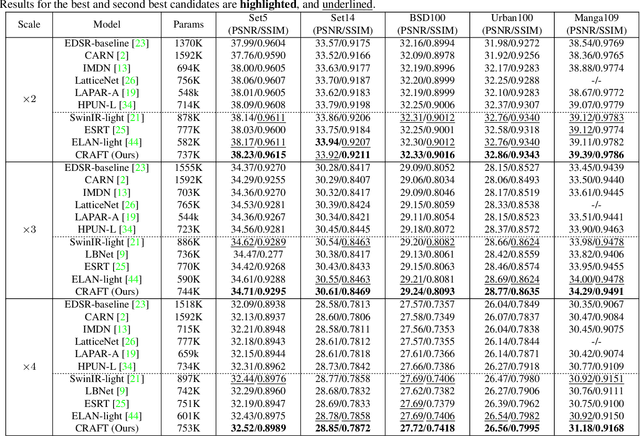
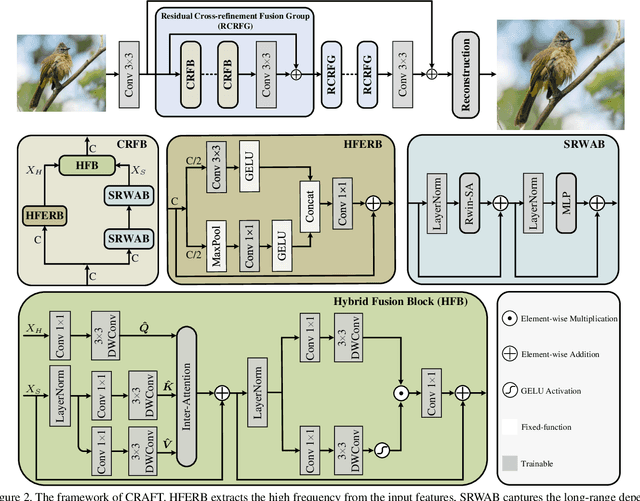
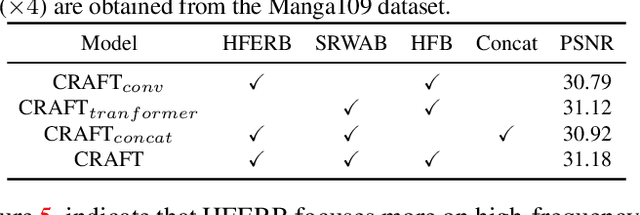
Transformer-based methods have exhibited remarkable potential in single image super-resolution (SISR) by effectively extracting long-range dependencies. However, most of the current research in this area has prioritized the design of transformer blocks to capture global information, while overlooking the importance of incorporating high-frequency priors, which we believe could be beneficial. In our study, we conducted a series of experiments and found that transformer structures are more adept at capturing low-frequency information, but have limited capacity in constructing high-frequency representations when compared to their convolutional counterparts. Our proposed solution, the cross-refinement adaptive feature modulation transformer (CRAFT), integrates the strengths of both convolutional and transformer structures. It comprises three key components: the high-frequency enhancement residual block (HFERB) for extracting high-frequency information, the shift rectangle window attention block (SRWAB) for capturing global information, and the hybrid fusion block (HFB) for refining the global representation. Our experiments on multiple datasets demonstrate that CRAFT outperforms state-of-the-art methods by up to 0.29dB while using fewer parameters. The source code will be made available at: https://github.com/AVC2-UESTC/CRAFT-SR.git.
DomainAdaptor: A Novel Approach to Test-time Adaptation
Aug 20, 2023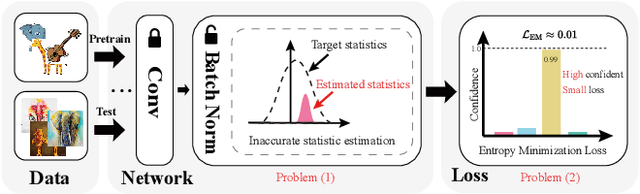
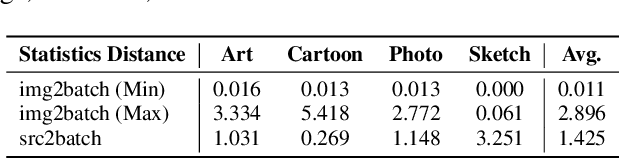

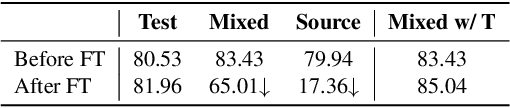
To deal with the domain shift between training and test samples, current methods have primarily focused on learning generalizable features during training and ignore the specificity of unseen samples that are also critical during the test. In this paper, we investigate a more challenging task that aims to adapt a trained CNN model to unseen domains during the test. To maximumly mine the information in the test data, we propose a unified method called DomainAdaptor for the test-time adaptation, which consists of an AdaMixBN module and a Generalized Entropy Minimization (GEM) loss. Specifically, AdaMixBN addresses the domain shift by adaptively fusing training and test statistics in the normalization layer via a dynamic mixture coefficient and a statistic transformation operation. To further enhance the adaptation ability of AdaMixBN, we design a GEM loss that extends the Entropy Minimization loss to better exploit the information in the test data. Extensive experiments show that DomainAdaptor consistently outperforms the state-of-the-art methods on four benchmarks. Furthermore, our method brings more remarkable improvement against existing methods on the few-data unseen domain. The code is available at https://github.com/koncle/DomainAdaptor.