 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unified Song Generation and Singing Voice Conversion with Accompaniment Co-Generation
Jun 05, 2026While song generation and singing voice conversion (SVC) have evolved significantly, they have long been developed isolated: the former lacks zero-shot speaker cloning, while the latter overlooks vocal-accompaniment synergy. To bridge this gap, we propose UniSinger, the first end-to-end framework unifying speaker cloning song generation and accompaniment co-generation SVC. Building on the multimodal diffusion transformer, we construct a unified speaker embedding space transferring speaker representation from SVC to song generation, endowing fine-grained cross-task timbre control. To mitigate multi-task optimization conflicts, we design a curriculum learning strategy using task-specific modality masking to guide the model to gradually master the generative mechanisms among semantic content, vocal timbre, and accompaniment. Experiments show state-of-the-art performance on both tasks and realizes complementary benefits, offering new possibilities for intelligent music production.
Unveiling Multi-regime Patterns in SciML: Distinct Failure Modes and Regime-specific Optimization
May 27, 2026Neural networks trained under different hyperparameter settings can fall into distinct training "regimes," with consistent behavior within regimes and qualitative differences across regimes. In this paper, we study such multi-regime behavior in scientific machine learning (SciML) models through a regime-aware diagnostic framework that jointly analyzes performance, training dynamics, and loss-landscape geometry. We identify three key findings: (i) a consistent three-regime structure emerges across many standard SciML models, different constraint enforcements, and various optimizer designs; (ii) optimization effectiveness is regime-specific, with no single method performing well across all regimes; and (iii) SciML models can exhibit fine-grained failure modes that can challenge conventional interpretations of standard loss-landscape metrics. Our results provide an approach to establish a unified, task-oblivious perspective on failure modes in SciML and to inform regime-aware guidance for improving robustness. We validate these findings across widely-used SciML models, including physics-informed neural networks, neural operators, and neural ordinary differential equations, on benchmarks spanning representative ordinary and partial differential equations.
Iterative Refinement Neural Operators are Learned Fixed-Point Solvers: A Principled Approach to Spectral Bias Mitigation
May 26, 2026Neural operators serve as fast, data-driven surrogates for scientific modeling but typically rely on a monolithic, single-pass inference procedure that struggles to resolve high-frequency details, a limitation known as spectral bias. We introduce the Iterative Refinement Neural Operator (IRNO), which augments pre-trained operators with a learned refinement module iteratively applied via fixed-point iteration. IRNO decomposes the prediction into a coarse initialization followed by successive residual corrections, paralleling classical numerical solvers. Under local assumptions, we establish contraction of the induced operator, ensuring convergence to a unique fixed point. To explicitly target high-frequency errors, we propose a progressive spectral loss that adaptively increases penalty on high-frequency components over refinement steps during training. Across physical systems, IRNO consistently lowers error, with up to 56.05% improvement on turbulent flow. On Active Matter, spectral analysis reveals that, relative to base operator, the normalized error ratios decrease to 27.72-36.10% in low-, 5.07-6.68% in mid-, and 1.48-2.04% in high-frequencies, remaining stable beyond the trained iteration count. Code is available at https://github.com/xiaotianliu-dartmouth/Iterative_Refinement_Neural_Operator
UniSonate: A Unified Model for Speech, Music, and Sound Effect Generation with Text Instructions
Apr 24, 2026Generative audio modeling has largely been fragmented into specialized tasks, text-to-speech (TTS), text-to-music (TTM), and text-to-audio (TTA), each operating under heterogeneous control paradigms. Unifying these modalities remains a fundamental challenge due to the intrinsic dissonance between structured semantic representations (speech/music) and unstructured acoustic textures (sound effects). In this paper, we introduce UniSonate, a unified flow-matching framework capable of synthesizing speech, music, and sound effects through a standardized, reference-free natural language instruction interface. To reconcile structural disparities, we propose a novel dynamic token injection mechanism that projects unstructured environmental sounds into a structured temporal latent space, enabling precise duration control within a phoneme-driven Multimodal Diffusion Transformer (MM-DiT). Coupled with a multi-stage curriculum learning strategy, this approach effectively mitigates cross-modal optimization conflicts. Extensive experiments demonstrate that UniSonate achieves state-of-the-art performance in instruction-based TTS (WER 1.47%) and TTM (SongEval Coherence 3.18), while maintaining competitive fidelity in TTA. Crucially, we observe positive transfer, where joint training on diverse audio data significantly enhances structural coherence and prosodic expressiveness compared to single-task baselines. Audio samples are available at https://qiangchunyu.github.io/UniSonate/.
AT-ADD: All-Type Audio Deepfake Detection Challenge Evaluation Plan
Apr 09, 2026The rapid advancement of Audio Large Language Models (ALLMs) has enabled cost-effective, high-fidelity generation and manipulation of both speech and non-speech audio, including sound effects, singing voices, and music. While these capabilities foster creativity and content production, they also introduce significant security and trust challenges, as realistic audio deepfakes can now be generated and disseminated at scale. Existing audio deepfake detection (ADD) countermeasures (CMs) and benchmarks, however, remain largely speech-centric, often relying on speech-specific artifacts and exhibiting limited robustness to real-world distortions, as well as restricted generalization to heterogeneous audio types and emerging spoofing techniques. To address these gaps, we propose the All-Type Audio Deepfake Detection (AT-ADD) Grand Challenge for ACM Multimedia 2026, designed to bridge controlled academic evaluation with practical multimedia forensics. AT-ADD comprises two tracks: (1) Robust Speech Deepfake Detection, which evaluates detectors under real-world scenarios and against unseen, state-of-the-art speech generation methods; and (2) All-Type Audio Deepfake Detection, which extends detection beyond speech to diverse, unknown audio types and promotes type-agnostic generalization across speech, sound, singing, and music. By providing standardized datasets, rigorous evaluation protocols, and reproducible baselines, AT-ADD aims to accelerate the development of robust and generalizable audio forensic technologies, supporting secure communication, reliable media verification, and responsible governance in an era of pervasive synthetic audio.
MM-Sonate: Multimodal Controllable Audio-Video Generation with Zero-Shot Voice Cloning
Jan 08, 2026Joint audio-video generation aims to synthesize synchronized multisensory content, yet current unified models struggle with fine-grained acoustic control, particularly for identity-preserving speech. Existing approaches either suffer from temporal misalignment due to cascaded generation or lack the capability to perform zero-shot voice cloning within a joint synthesis framework. In this work, we present MM-Sonate, a multimodal flow-matching framework that unifies controllable audio-video joint generation with zero-shot voice cloning capabilities. Unlike prior works that rely on coarse semantic descriptions, MM-Sonate utilizes a unified instruction-phoneme input to enforce strict linguistic and temporal alignment. To enable zero-shot voice cloning, we introduce a timbre injection mechanism that effectively decouples speaker identity from linguistic content. Furthermore, addressing the limitations of standard classifier-free guidance in multimodal settings, we propose a noise-based negative conditioning strategy that utilizes natural noise priors to significantly enhance acoustic fidelity. Empirical evaluations demonstrate that MM-Sonate establishes new state-of-the-art performance in joint generation benchmarks, significantly outperforming baselines in lip synchronization and speech intelligibility, while achieving voice cloning fidelity comparable to specialized Text-to-Speech systems.
Interpretable All-Type Audio Deepfake Detection with Audio LLMs via Frequency-Time Reinforcement Learning
Jan 06, 2026Recent advances in audio large language models (ALLMs) have made high-quality synthetic audio widely accessible, increasing the risk of malicious audio deepfakes across speech, environmental sounds, singing voice, and music. Real-world audio deepfake detection (ADD) therefore requires all-type detectors that generalize across heterogeneous audio and provide interpretable decisions. Given the strong multi-task generalization ability of ALLMs, we first investigate their performance on all-type ADD under both supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). However, SFT using only binary real/fake labels tends to reduce the model to a black-box classifier, sacrificing interpretability. Meanwhile, vanilla RFT under sparse supervision is prone to reward hacking and can produce hallucinated, ungrounded rationales. To address this, we propose an automatic annotation and polishing pipeline that constructs Frequency-Time structured chain-of-thought (CoT) rationales, producing ~340K cold-start demonstrations. Building on CoT data, we propose Frequency Time-Group Relative Policy Optimization (FT-GRPO), a two-stage training paradigm that cold-starts ALLMs with SFT and then applies GRPO under rule-based frequency-time constraints. Experiments demonstrate that FT-GRPO achieves state-of-the-art performance on all-type ADD while producing interpretable, FT-grounded rationales. The data and code are available online.
Kling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio Generation
Jun 24, 2025
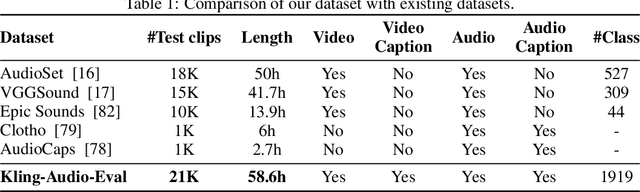
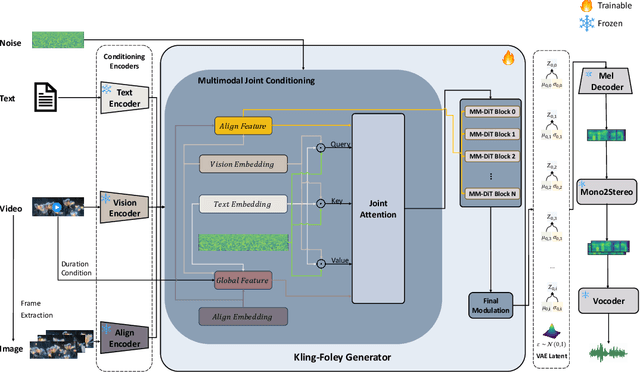
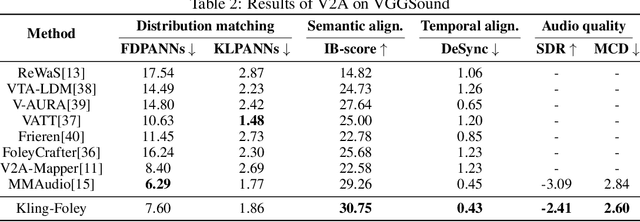
We propose Kling-Foley, a large-scale multimodal Video-to-Audio generation model that synthesizes high-quality audio synchronized with video content. In Kling-Foley, we introduce multimodal diffusion transformers to model the interactions between video, audio, and text modalities, and combine it with a visual semantic representation module and an audio-visual synchronization module to enhance alignment capabilities. Specifically, these modules align video conditions with latent audio elements at the frame level, thereby improving semantic alignment and audio-visual synchronization. Together with text conditions, this integrated approach enables precise generation of video-matching sound effects. In addition, we propose a universal latent audio codec that can achieve high-quality modeling in various scenarios such as sound effects, speech, singing, and music. We employ a stereo rendering method that imbues synthesized audio with a spatial presence. At the same time, in order to make up for the incomplete types and annotations of the open-source benchmark, we also open-source an industrial-level benchmark Kling-Audio-Eval. Our experiments show that Kling-Foley trained with the flow matching objective achieves new audio-visual SOTA performance among public models in terms of distribution matching, semantic alignment, temporal alignment and audio quality.
Artificial Protozoa Optimizer (APO): A novel bio-inspired metaheuristic algorithm for engineering optimization
May 06, 2025



This study proposes a novel artificial protozoa optimizer (APO) that is inspired by protozoa in nature. The APO mimics the survival mechanisms of protozoa by simulating their foraging, dormancy, and reproductive behaviors. The APO was mathematically modeled and implemented to perform the optimization processes of metaheuristic algorithms. The performance of the APO was verified via experimental simulations and compared with 32 state-of-the-art algorithms. Wilcoxon signed-rank test was performed for pairwise comparisons of the proposed APO with the state-of-the-art algorithms, and Friedman test was used for multiple comparisons. First, the APO was tested using 12 functions of the 2022 IEEE Congress on Evolutionary Computation benchmark. Considering practicality, the proposed APO was used to solve five popular engineering design problems in a continuous space with constraints. Moreover, the APO was applied to solve a multilevel image segmentation task in a discrete space with constraints. The experiments confirmed that the APO could provide highly competitive results for optimization problems. The source codes of Artificial Protozoa Optimizer are publicly available at https://seyedalimirjalili.com/projects and https://ww2.mathworks.cn/matlabcentral/fileexchange/162656-artificial-protozoa-optimizer.
Detect All-Type Deepfake Audio: Wavelet Prompt Tuning for Enhanced Auditory Perception
Apr 09, 2025



The rapid advancement of audio generation technologies has escalated the risks of malicious deepfake audio across speech, sound, singing voice, and music, threatening multimedia security and trust. While existing countermeasures (CMs) perform well in single-type audio deepfake detection (ADD), their performance declines in cross-type scenarios. This paper is dedicated to studying the alltype ADD task. We are the first to comprehensively establish an all-type ADD benchmark to evaluate current CMs, incorporating cross-type deepfake detection across speech, sound, singing voice, and music. Then, we introduce the prompt tuning self-supervised learning (PT-SSL) training paradigm, which optimizes SSL frontend by learning specialized prompt tokens for ADD, requiring 458x fewer trainable parameters than fine-tuning (FT). Considering the auditory perception of different audio types,we propose the wavelet prompt tuning (WPT)-SSL method to capture type-invariant auditory deepfake information from the frequency domain without requiring additional training parameters, thereby enhancing performance over FT in the all-type ADD task. To achieve an universally CM, we utilize all types of deepfake audio for co-training. Experimental results demonstrate that WPT-XLSR-AASIST achieved the best performance, with an average EER of 3.58% across all evaluation sets. The code is available online.