 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZIPP:Zero-shot Image Personalization from Personas
Jun 07, 2026Text-to-image diffusion models are increasingly deployed in open-ended creative contexts, yet their outputs remain impersonal, optimized for aggregate aesthetics rather than individual taste. Human preferences are pluralistic: one user favoring muted, nostalgic portraits may prefer vibrant street photography, while another gravitates toward dreamy film aesthetics. Existing methods require dense interaction histories or per-user fine-tuning, failing in cold-start settings and collapsing context-dependent preferences into a static representation. We introduce zero-shot image personalization from personas (ZIPP), which conditions image generation on natural-language personas (concise descriptors of a user's identity and aesthetic sensibilities) without any user-specific data or weight updates. ZIPP uses an LLM to rewrite prompts from the perspective of a given persona, steering diffusion models toward personalized outputs. To mine personas at scale, we train an inductive Graph Attention Network over a 22M-user Reddit interaction graph with dual contrastive objectives aligning graph structure with visual behavior, then verbalize learned representations into natural-language personas via an MLLM. We introduce ZIPBench, the first zero-shot personalization benchmark with 1.5K users, graph-mined personas, and 40K generated images. Across four benchmarks and 14 LLMs spanning five model families, persona conditioning yields consistent gains (13-20%), with frontier models benefiting most. In the few-shot setting, ZIPP matches or exceeds fine-tuned baselines trained on 100+ examples per user. ZIPP achieves the lowest preference distributional divergence (CMMD 0.16 vs. 0.55), and IPF-normalized demographic evaluation shows it substantially reduces subpopulation bias present in existing methods. Human evaluation confirms a 79% win rate over generic generation and 58-65% over all fine-tuned baselines.
Measuring and Improving Persuasiveness of Generative Models
Oct 03, 2024



LLMs are increasingly being used in workflows involving generating content to be consumed by humans (e.g., marketing) and also in directly interacting with humans (e.g., through chatbots). The development of such systems that are capable of generating verifiably persuasive messages presents both opportunities and challenges for society. On the one hand, such systems could positively impact domains like advertising and social good, such as addressing drug addiction, and on the other, they could be misused for spreading misinformation and shaping political opinions. To channel LLMs' impact on society, we need to develop systems to measure and benchmark their persuasiveness. With this motivation, we introduce PersuasionBench and PersuasionArena, the first large-scale benchmark and arena containing a battery of tasks to measure the persuasion ability of generative models automatically. We investigate to what extent LLMs know and leverage linguistic patterns that can help them generate more persuasive language. Our findings indicate that the persuasiveness of LLMs correlates positively with model size, but smaller models can also be made to have a higher persuasiveness than much larger models. Notably, targeted training using synthetic and natural datasets significantly enhances smaller models' persuasive capabilities, challenging scale-dependent assumptions. Our findings carry key implications for both model developers and policymakers. For instance, while the EU AI Act and California's SB-1047 aim to regulate AI models based on the number of floating point operations, we demonstrate that simple metrics like this alone fail to capture the full scope of AI's societal impact. We invite the community to explore and contribute to PersuasionArena and PersuasionBench, available at https://bit.ly/measure-persuasion, to advance our understanding of AI-driven persuasion and its societal implications.
LLaVA Finds Free Lunch: Teaching Human Behavior Improves Content Understanding Abilities Of LLMs
May 02, 2024



Communication is defined as ``Who says what to whom with what effect.'' A message from a communicator generates downstream receiver effects, also known as behavior. Receiver behavior, being a downstream effect of the message, carries rich signals about it. Even after carrying signals about the message, the behavior data is often ignored while training large language models. We show that training LLMs on receiver behavior can actually help improve their content-understanding abilities. Specifically, we show that training LLMs to predict the receiver behavior of likes and comments improves the LLM's performance on a wide variety of downstream content understanding tasks. We show this performance increase over 40 video and image understanding tasks over 23 benchmark datasets across both 0-shot and fine-tuning settings, outperforming many supervised baselines. Moreover, since receiver behavior, such as likes and comments, is collected by default on the internet and does not need any human annotations to be useful, the performance improvement we get after training on this data is essentially free-lunch. We release the receiver behavior cleaned comments and likes of 750k images and videos collected from multiple platforms along with our instruction-tuning data.
Large Content And Behavior Models To Understand, Simulate, And Optimize Content And Behavior
Sep 08, 2023



Shannon, in his seminal paper introducing information theory, divided the communication into three levels: technical, semantic, and effectivenss. While the technical level is concerned with accurate reconstruction of transmitted symbols, the semantic and effectiveness levels deal with the inferred meaning and its effect on the receiver. Thanks to telecommunications, the first level problem has produced great advances like the internet. Large Language Models (LLMs) make some progress towards the second goal, but the third level still remains largely untouched. The third problem deals with predicting and optimizing communication for desired receiver behavior. LLMs, while showing wide generalization capabilities across a wide range of tasks, are unable to solve for this. One reason for the underperformance could be a lack of "behavior tokens" in LLMs' training corpora. Behavior tokens define receiver behavior over a communication, such as shares, likes, clicks, purchases, retweets, etc. While preprocessing data for LLM training, behavior tokens are often removed from the corpora as noise. Therefore, in this paper, we make some initial progress towards reintroducing behavior tokens in LLM training. The trained models, other than showing similar performance to LLMs on content understanding tasks, show generalization capabilities on behavior simulation, content simulation, behavior understanding, and behavior domain adaptation. Using a wide range of tasks on two corpora, we show results on all these capabilities. We call these models Large Content and Behavior Models (LCBMs). Further, to spur more research on LCBMs, we release our new Content Behavior Corpus (CBC), a repository containing communicator, message, and corresponding receiver behavior.
Long-Term Memorability On Advertisements
Sep 01, 2023



Marketers spend billions of dollars on advertisements but to what end? At the purchase time, if customers cannot recognize a brand for which they saw an ad, the money spent on the ad is essentially wasted. Despite its importance in marketing, until now, there has been no study on the memorability of ads in the ML literature. Most studies have been conducted on short-term recall (<5 mins) on specific content types like object and action videos. On the other hand, the advertising industry only cares about long-term memorability (a few hours or longer), and advertisements are almost always highly multimodal, depicting a story through its different modalities (text, images, and videos). With this motivation, we conduct the first large scale memorability study consisting of 1203 participants and 2205 ads covering 276 brands. Running statistical tests over different participant subpopulations and ad-types, we find many interesting insights into what makes an ad memorable - both content and human factors. For example, we find that brands which use commercials with fast moving scenes are more memorable than those with slower scenes (p=8e-10) and that people who use ad-blockers remember lower number of ads than those who don't (p=5e-3). Further, with the motivation of simulating the memorability of marketing materials for a particular audience, ultimately helping create one, we present a novel model, Sharingan, trained to leverage real-world knowledge of LLMs and visual knowledge of visual encoders to predict the memorability of a content. We test our model on all the prominent memorability datasets in literature (both images and videos) and achieve state of the art across all of them. We conduct extensive ablation studies across memory types, modality, brand, and architectural choices to find insights into what drives memory.
AES Systems Are Both Overstable And Oversensitive: Explaining Why And Proposing Defenses
Oct 14, 2021

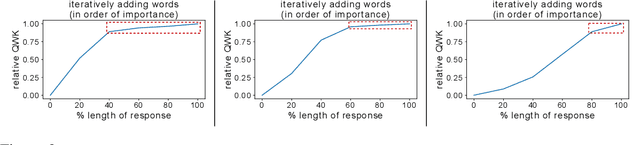
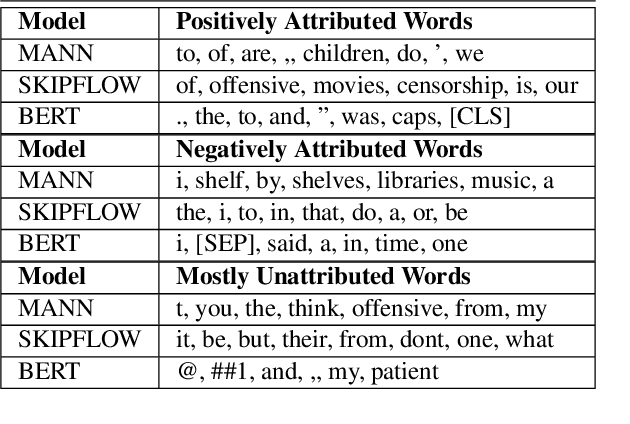
Deep-learning based Automatic Essay Scoring (AES) systems are being actively used by states and language testing agencies alike to evaluate millions of candidates for life-changing decisions ranging from college applications to visa approvals. However, little research has been put to understand and interpret the black-box nature of deep-learning based scoring algorithms. Previous studies indicate that scoring models can be easily fooled. In this paper, we explore the reason behind their surprising adversarial brittleness. We utilize recent advances in interpretability to find the extent to which features such as coherence, content, vocabulary, and relevance are important for automated scoring mechanisms. We use this to investigate the oversensitivity i.e., large change in output score with a little change in input essay content) and overstability i.e., little change in output scores with large changes in input essay content) of AES. Our results indicate that autoscoring models, despite getting trained as "end-to-end" models with rich contextual embeddings such as BERT, behave like bag-of-words models. A few words determine the essay score without the requirement of any context making the model largely overstable. This is in stark contrast to recent probing studies on pre-trained representation learning models, which show that rich linguistic features such as parts-of-speech and morphology are encoded by them. Further, we also find that the models have learnt dataset biases, making them oversensitive. To deal with these issues, we propose detection-based protection models that can detect oversensitivity and overstability causing samples with high accuracies. We find that our proposed models are able to detect unusual attribution patterns and flag adversarial samples successfully.
MINIMAL: Mining Models for Data Free Universal Adversarial Triggers
Sep 25, 2021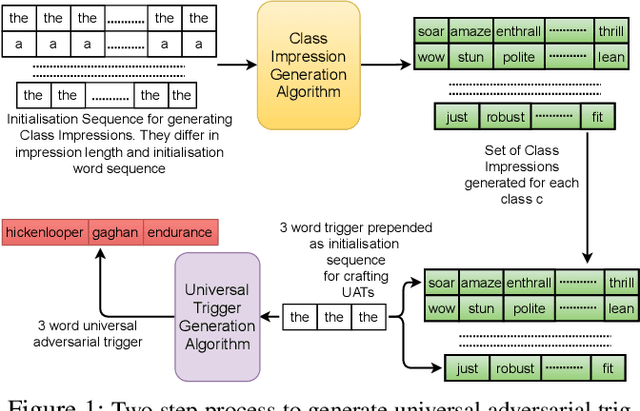
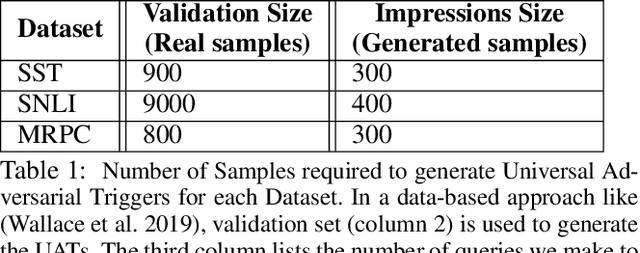
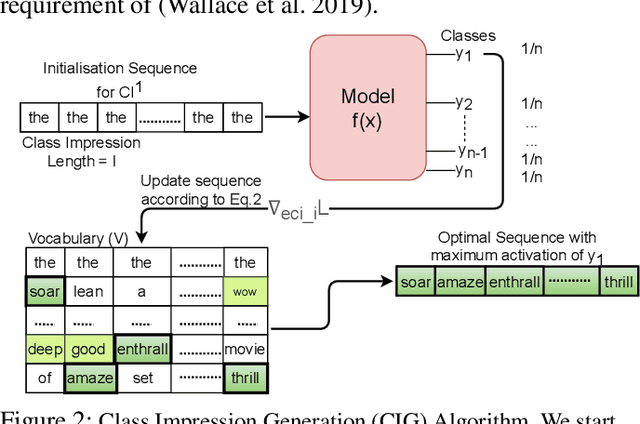
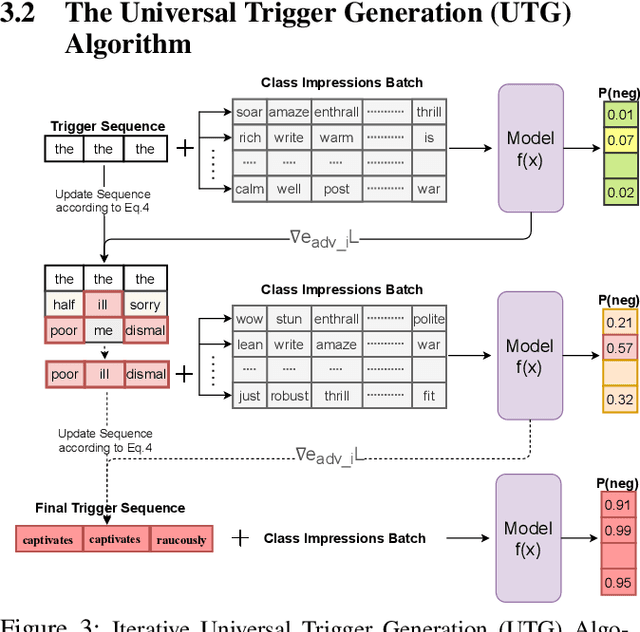
It is well known that natural language models are vulnerable to adversarial attacks, which are mostly input-specific in nature. Recently, it has been shown that there also exist input-agnostic attacks in NLP models, called universal adversarial triggers. However, existing methods to craft universal triggers are data intensive. They require large amounts of data samples to generate adversarial triggers, which are typically inaccessible by attackers. For instance, previous works take 3000 data samples per class for the SNLI dataset to generate adversarial triggers. In this paper, we present a novel data-free approach, MINIMAL, to mine input-agnostic adversarial triggers from models. Using the triggers produced with our data-free algorithm, we reduce the accuracy of Stanford Sentiment Treebank's positive class from 93.6% to 9.6%. Similarly, for the Stanford Natural Language Inference (SNLI), our single-word trigger reduces the accuracy of the entailment class from 90.95% to less than 0.6\%. Despite being completely data-free, we get equivalent accuracy drops as data-dependent methods.
BPGC at SemEval-2020 Task 11: Propaganda Detection in News Articles with Multi-Granularity Knowledge Sharing and Linguistic Features based Ensemble Learning
May 31, 2020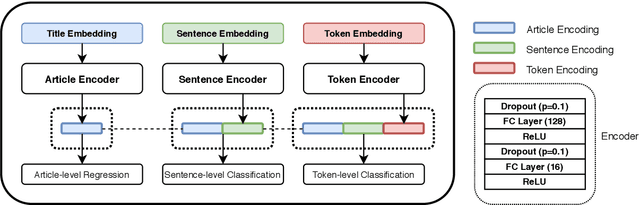
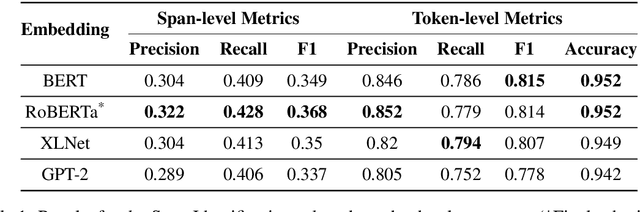
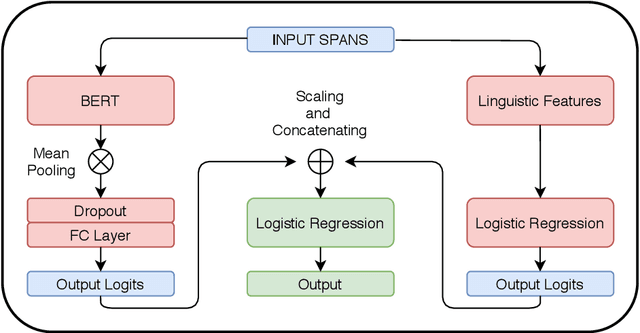
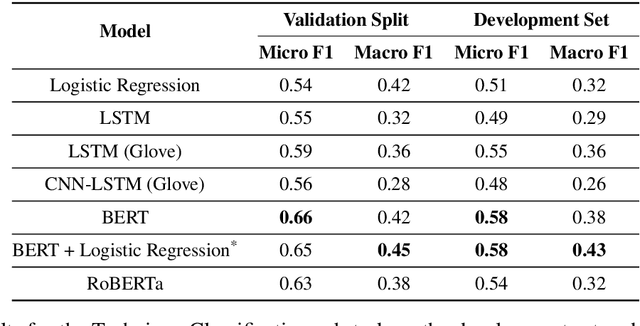
Propaganda spreads the ideology and beliefs of like-minded people, brainwashing their audiences, and sometimes leading to violence. SemEval 2020 Task-11 aims to design automated systems for news propaganda detection. Task-11 consists of two sub-tasks, namely, Span Identification - given any news article, the system tags those specific fragments which contain at least one propaganda technique; and Technique Classification - correctly classify a given propagandist statement amongst 14 propaganda techniques. For sub-task 1, we use contextual embeddings extracted from pre-trained transformer models to represent the text data at various granularities and propose a multi-granularity knowledge sharing approach. For sub-task 2, we use an ensemble of BERT and logistic regression classifiers with linguistic features. Our results reveal that the linguistic features are the strong indicators for covering minority classes in a highly imbalanced dataset.