 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dual-stage Flows-based Generative Modeling for Traceable Urban Planning
Oct 03, 2023
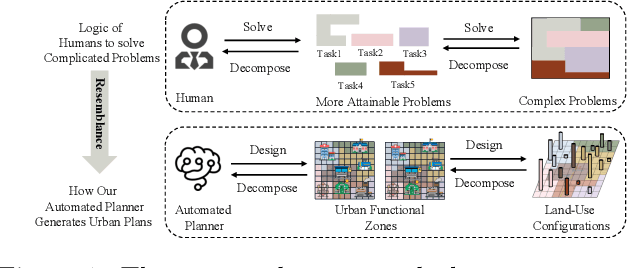


Urban planning, which aims to design feasible land-use configurations for target areas, has become increasingly essential due to the high-speed urbanization process in the modern era. However, the traditional urban planning conducted by human designers can be a complex and onerous task. Thanks to the advancement of deep learning algorithms, researchers have started to develop automated planning techniques. While these models have exhibited promising results, they still grapple with a couple of unresolved limitations: 1) Ignoring the relationship between urban functional zones and configurations and failing to capture the relationship among different functional zones. 2) Less interpretable and stable generation process. To overcome these limitations, we propose a novel generative framework based on normalizing flows, namely Dual-stage Urban Flows (DSUF) framework. Specifically, the first stage is to utilize zone-level urban planning flows to generate urban functional zones based on given surrounding contexts and human guidance. Then we employ an Information Fusion Module to capture the relationship among functional zones and fuse the information of different aspects. The second stage is to use configuration-level urban planning flows to obtain land-use configurations derived from fused information. We design several experiments to indicate that our framework can outperform compared to other generative models for the urban planning task.
ClimateBERT-NetZero: Detecting and Assessing Net Zero and Reduction Targets
Oct 12, 2023
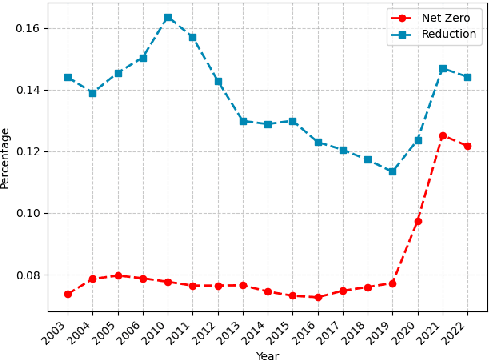
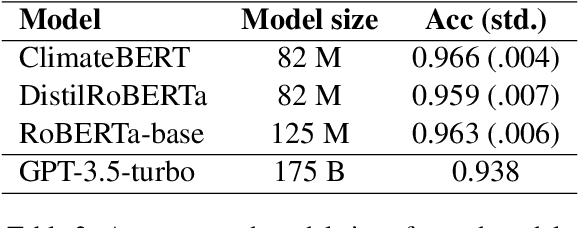
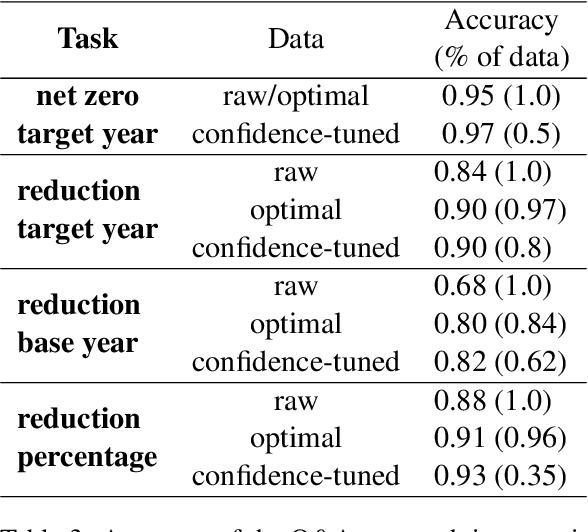
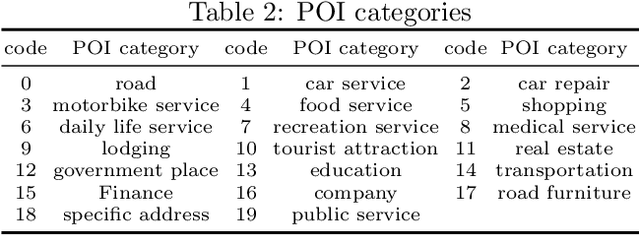
Public and private actors struggle to assess the vast amounts of information about sustainability commitments made by various institutions. To address this problem, we create a novel tool for automatically detecting corporate, national, and regional net zero and reduction targets in three steps. First, we introduce an expert-annotated data set with 3.5K text samples. Second, we train and release ClimateBERT-NetZero, a natural language classifier to detect whether a text contains a net zero or reduction target. Third, we showcase its analysis potential with two use cases: We first demonstrate how ClimateBERT-NetZero can be combined with conventional question-answering (Q&A) models to analyze the ambitions displayed in net zero and reduction targets. Furthermore, we employ the ClimateBERT-NetZero model on quarterly earning call transcripts and outline how communication patterns evolve over time. Our experiments demonstrate promising pathways for extracting and analyzing net zero and emission reduction targets at scale.
Heterophily-Based Graph Neural Network for Imbalanced Classification
Oct 12, 2023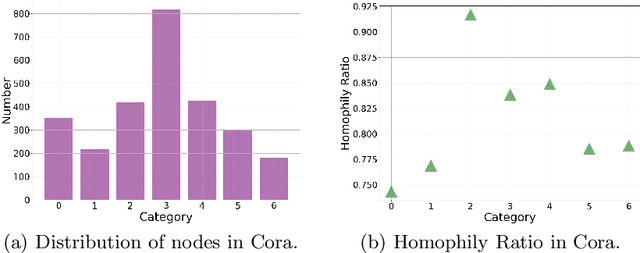

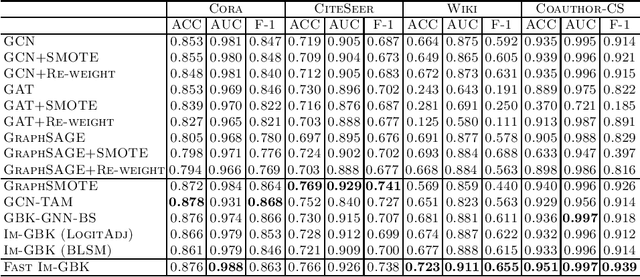
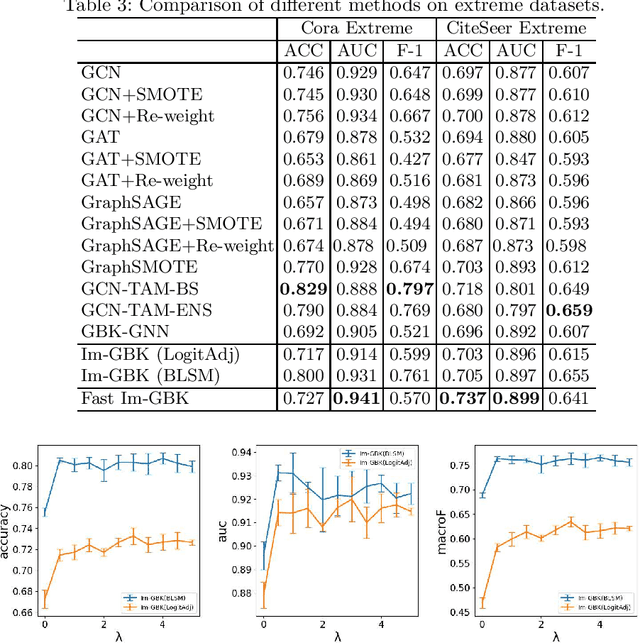
Graph neural networks (GNNs) have shown promise in addressing graph-related problems, including node classification. However, conventional GNNs assume an even distribution of data across classes, which is often not the case in real-world scenarios, where certain classes are severely underrepresented. This leads to suboptimal performance of standard GNNs on imbalanced graphs. In this paper, we introduce a unique approach that tackles imbalanced classification on graphs by considering graph heterophily. We investigate the intricate relationship between class imbalance and graph heterophily, revealing that minority classes not only exhibit a scarcity of samples but also manifest lower levels of homophily, facilitating the propagation of erroneous information among neighboring nodes. Drawing upon this insight, we propose an efficient method, called Fast Im-GBK, which integrates an imbalance classification strategy with heterophily-aware GNNs to effectively address the class imbalance problem while significantly reducing training time. Our experiments on real-world graphs demonstrate our model's superiority in classification performance and efficiency for node classification tasks compared to existing baselines.
Learning to Act from Actionless Videos through Dense Correspondences
Oct 12, 2023In this work, we present an approach to construct a video-based robot policy capable of reliably executing diverse tasks across different robots and environments from few video demonstrations without using any action annotations. Our method leverages images as a task-agnostic representation, encoding both the state and action information, and text as a general representation for specifying robot goals. By synthesizing videos that ``hallucinate'' robot executing actions and in combination with dense correspondences between frames, our approach can infer the closed-formed action to execute to an environment without the need of any explicit action labels. This unique capability allows us to train the policy solely based on RGB videos and deploy learned policies to various robotic tasks. We demonstrate the efficacy of our approach in learning policies on table-top manipulation and navigation tasks. Additionally, we contribute an open-source framework for efficient video modeling, enabling the training of high-fidelity policy models with four GPUs within a single day.
Music- and Lyrics-driven Dance Synthesis
Sep 30, 2023Lyrics often convey information about the songs that are beyond the auditory dimension, enriching the semantic meaning of movements and musical themes. Such insights are important in the dance choreography domain. However, most existing dance synthesis methods mainly focus on music-to-dance generation, without considering the semantic information. To complement it, we introduce JustLMD, a new multimodal dataset of 3D dance motion with music and lyrics. To the best of our knowledge, this is the first dataset with triplet information including dance motion, music, and lyrics. Additionally, we showcase a cross-modal diffusion-based network designed to generate 3D dance motion conditioned on music and lyrics. The proposed JustLMD dataset encompasses 4.6 hours of 3D dance motion in 1867 sequences, accompanied by musical tracks and their corresponding English lyrics.
Landslide Topology Uncovers Failure Movements
Oct 14, 2023The death toll and monetary damages from landslides continue to rise despite advancements in predictive modeling. The predictive capability of these models is limited as landslide databases used in training and assessing the models often have crucial information missing, such as underlying failure types. Here, we present an approach for identifying failure types based on their movements, e.g., slides and flows by leveraging 3D landslide topology. We observe topological proxies reveal prevalent signatures of mass movement mechanics embedded in the landslide's morphology or shape, such as detecting coupled movement styles within complex landslides. We find identical failure types exhibit similar topological properties, and by using them as predictors, we can identify failure types in historic and event-specific landslide databases (including multi-temporal) from various geomorphological and climatic contexts such as Italy, the US Pacific Northwest region, Denmark, Turkey, and China with 80 to 94 % accuracy. To demonstrate the real-world application of the method, we implement it in two undocumented datasets from China and publicly release the datasets. These new insights can considerably improve the performance of landslide predictive models and impact assessments. Moreover, our work introduces a new paradigm for studying landslide shapes to understand underlying processes through the lens of landslide topology.
Detecting Moving Objects Using a Novel Optical-Flow-Based Range-Independent Invariant
Oct 14, 2023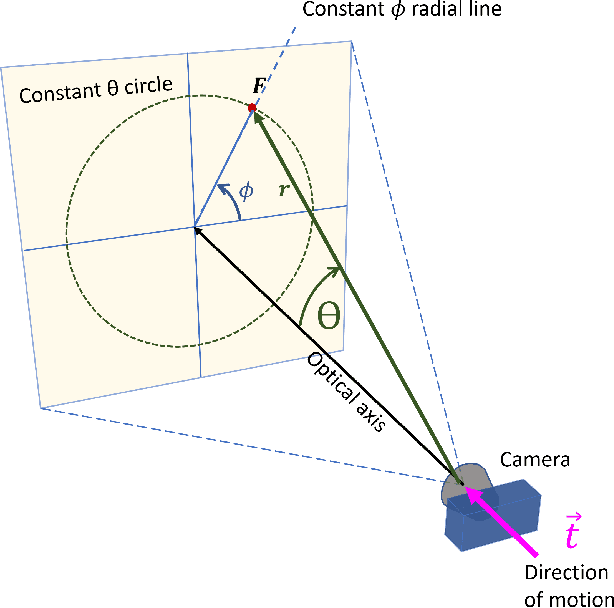



This paper focuses on a novel approach for detecting moving objects during camera motion. We present an optical-flow-based transformation that yields a consistent 2D invariant image output regardless of time instants, range of points in 3D, and the speed of the camera. In other words, this transformation generates a lookup image that remains invariant despite the changing projection of the 3D scene and camera motion. In the new domain, projections of 3D points that deviate from the values of the predefined lookup image can be clearly identified as moving relative to the stationary 3D environment, making them seamlessly detectable. The method does not require prior knowledge of the direction of motion or speed of the camera, nor does it necessitate 3D point range information. It is well-suited for real-time parallel processing, rendering it highly practical for implementation. We have validated the effectiveness of the new domain through simulations and experiments, demonstrating its robustness in scenarios involving rectilinear camera motion, both in simulations and with real-world data. This approach introduces new ways for moving objects detection during camera motion, and also lays the foundation for future research in the context of moving object detection during six-degrees-of-freedom camera motion.
HIO-SDF: Hierarchical Incremental Online Signed Distance Fields
Oct 14, 2023A good representation of a large, complex mobile robot workspace must be space-efficient yet capable of encoding relevant geometric details. When exploring unknown environments, it needs to be updatable incrementally in an online fashion. We introduce HIO-SDF, a new method that represents the environment as a Signed Distance Field (SDF). State of the art representations of SDFs are based on either neural networks or voxel grids. Neural networks are capable of representing the SDF continuously. However, they are hard to update incrementally as neural networks tend to forget previously observed parts of the environment unless an extensive sensor history is stored for training. Voxel-based representations do not have this problem but they are not space-efficient especially in large environments with fine details. HIO-SDF combines the advantages of these representations using a hierarchical approach which employs a coarse voxel grid that captures the observed parts of the environment together with high-resolution local information to train a neural network. HIO-SDF achieves a 46% lower mean global SDF error across all test scenes than a state of the art continuous representation, and a 30% lower error than a discrete representation at the same resolution as our coarse global SDF grid.
PC-bzip2: a phase-space continuity enhanced lossless compression algorithm for light field microscopy data
Oct 14, 2023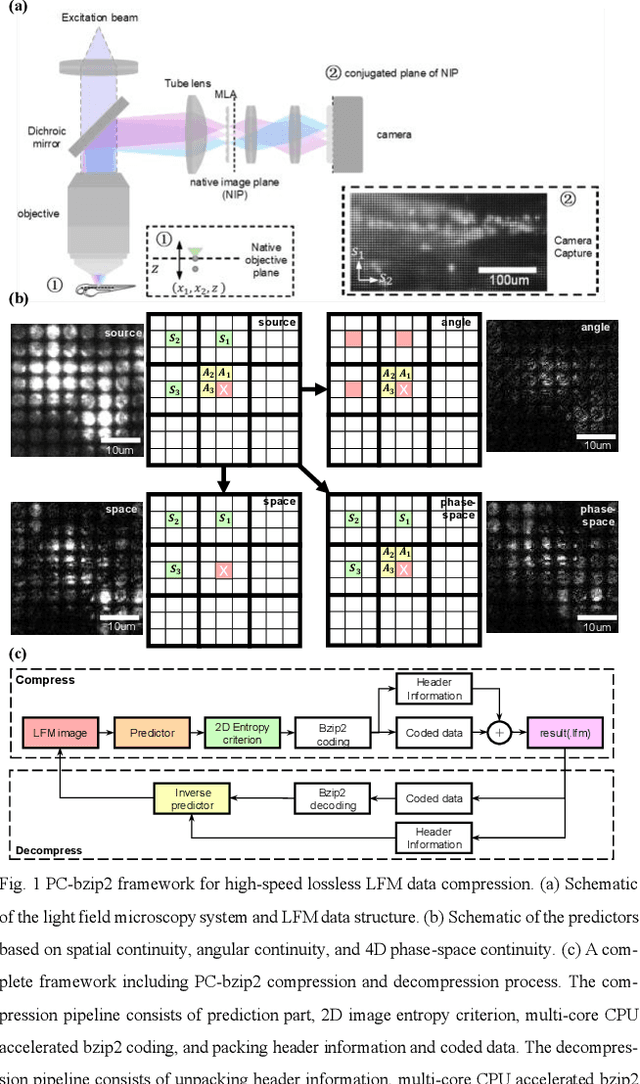
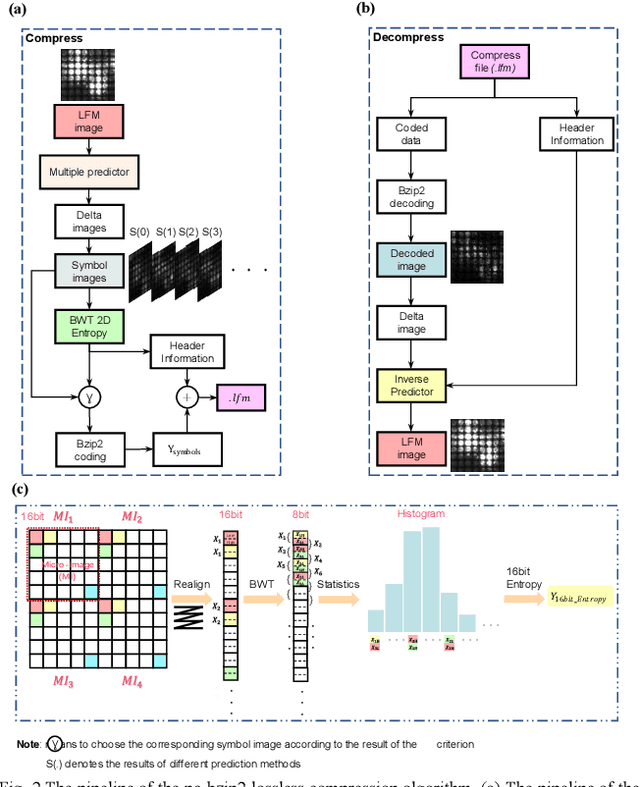
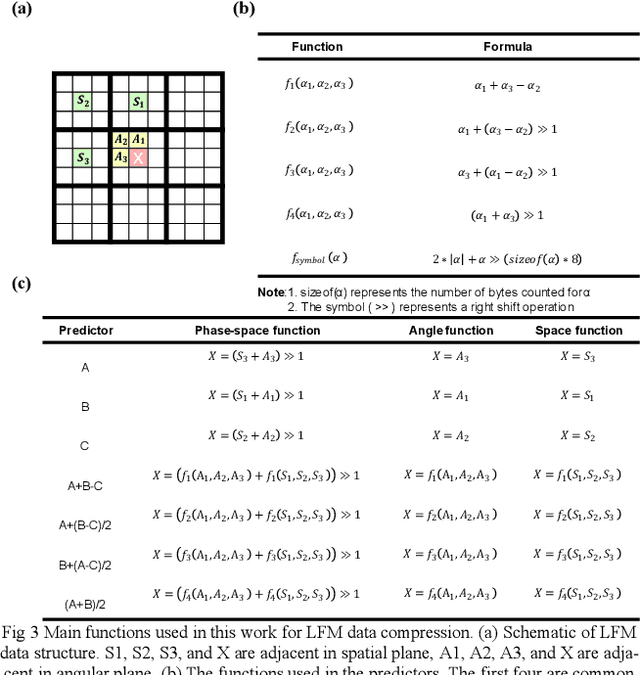
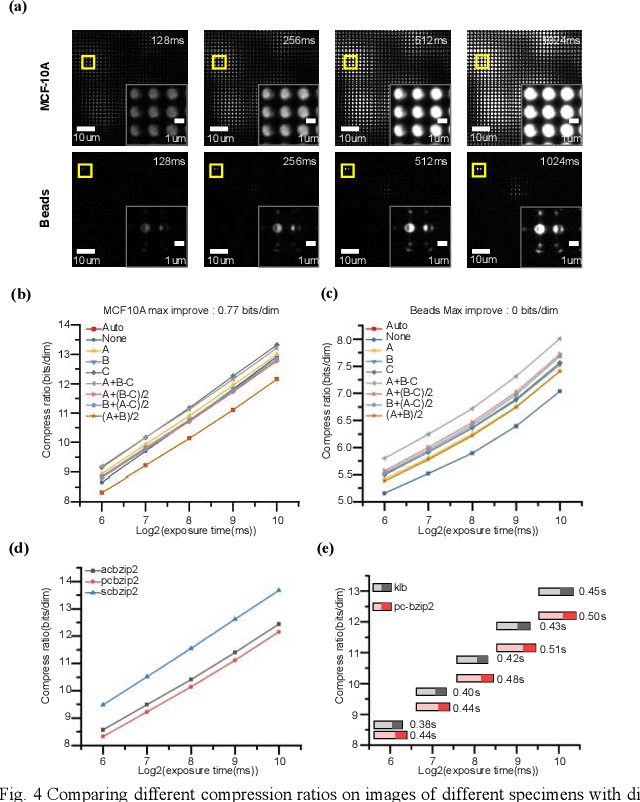
Light-field fluorescence microscopy (LFM) is a powerful elegant compact method for long-term high-speed imaging of complex biological systems, such as neuron activities and rapid movements of organelles. LFM experiments typically generate terabytes image data and require a huge number of storage space. Some lossy compression algorithms have been proposed recently with good compression performance. However, since the specimen usually only tolerates low power density illumination for long-term imaging with low phototoxicity, the image signal-to-noise ratio (SNR) is relative-ly low, which will cause the loss of some efficient position or intensity information by using such lossy compression al-gorithms. Here, we propose a phase-space continuity enhanced bzip2 (PC-bzip2) lossless compression method for LFM data as a high efficiency and open-source tool, which combines GPU-based fast entropy judgement and multi-core-CPU-based high-speed lossless compression. Our proposed method achieves almost 10% compression ratio improvement while keeping the capability of high-speed compression, compared with original bzip2. We evaluated our method on fluorescence beads data and fluorescence staining cells data with different SNRs. Moreover, by introducing the temporal continuity, our method shows the superior compression ratio on time series data of zebrafish blood vessels.
Advancing Test-Time Adaptation for Acoustic Foundation Models in Open-World Shifts
Oct 14, 2023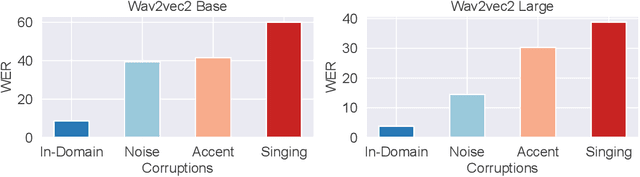
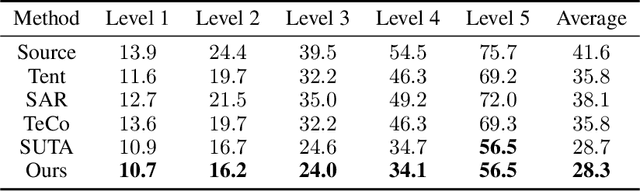
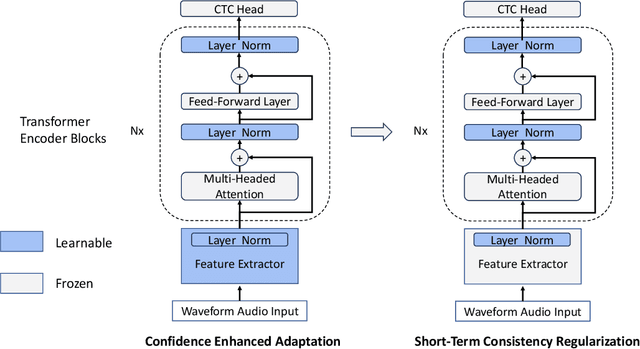
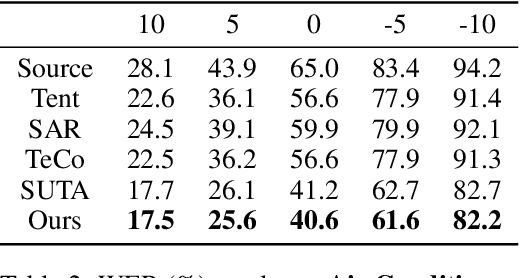
Test-Time Adaptation (TTA) is a critical paradigm for tackling distribution shifts during inference, especially in visual recognition tasks. However, while acoustic models face similar challenges due to distribution shifts in test-time speech, TTA techniques specifically designed for acoustic modeling in the context of open-world data shifts remain scarce. This gap is further exacerbated when considering the unique characteristics of acoustic foundation models: 1) they are primarily built on transformer architectures with layer normalization and 2) they deal with test-time speech data of varying lengths in a non-stationary manner. These aspects make the direct application of vision-focused TTA methods, which are mostly reliant on batch normalization and assume independent samples, infeasible. In this paper, we delve into TTA for pre-trained acoustic models facing open-world data shifts. We find that noisy, high-entropy speech frames, often non-silent, carry key semantic content. Traditional TTA methods might inadvertently filter out this information using potentially flawed heuristics. In response, we introduce a heuristic-free, learning-based adaptation enriched by confidence enhancement. Noting that speech signals' short-term consistency, we also apply consistency regularization during test-time optimization. Our experiments on synthetic and real-world datasets affirm our method's superiority over existing baselines.