 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch Experience of an Undergraduate Student in Computer Vision and Robotics
Jul 14, 2024



This paper focuses on the educational journey of a computer engineering undergraduate student venturing into the domain of computer vision and robotics. It explores how optical flow and its applications can be used to detect moving objects when a camera undergoes translational motion, highlighting the challenges encountered and the strategies used to overcome them. Furthermore, the paper discusses not only the technical skills acquired by the student but also interpersonal skills as related to teamwork and diversity. In this paper, we detail the learning process, including the acquisition of technical and problem-solving skills, as well as out-of-the-box thinking.
Invariant-based Mapping of Space During General Motion of an Observer
Nov 18, 2023This paper explores visual motion-based invariants, resulting in a new instantaneous domain where: a) the stationary environment is perceived as unchanged, even as the 2D images undergo continuous changes due to camera motion, b) obstacles can be detected and potentially avoided in specific subspaces, and c) moving objects can potentially be detected. To achieve this, we make use of nonlinear functions derived from measurable optical flow, which are linked to geometric 3D invariants. We present simulations involving a camera that translates and rotates relative to a 3D object, capturing snapshots of the camera projected images. We show that the object appears unchanged in the new domain over time. We process real data from the KITTI dataset and demonstrate how to segment space to identify free navigational regions and detect obstacles within a predetermined subspace. Additionally, we present preliminary results, based on the KITTI dataset, on the identification and segmentation of moving objects, as well as the visualization of shape constancy. This representation is straightforward, relying on functions for the simple de-rotation of optical flow. This representation only requires a single camera, it is pixel-based, making it suitable for parallel processing, and it eliminates the necessity for 3D reconstruction techniques.
Time-based Mapping of Space Using Visual Motion Invariants
Oct 14, 2023This paper focuses on visual motion-based invariants that result in a representation of 3D points in which the stationary environment remains invariant, ensuring shape constancy. This is achieved even as the images undergo constant change due to camera motion. Nonlinear functions of measurable optical flow, which are related to geometric 3D invariants, are utilized to create a novel representation. We refer to the resulting optical flow-based invariants as 'Time-Clearance' and the well-known 'Time-to-Contact' (TTC). Since these invariants remain constant over time, it becomes straightforward to detect moving points that do not adhere to the expected constancy. We present simulations of a camera moving relative to a 3D object, snapshots of its projected images captured by a rectilinearly moving camera, and the object as it appears unchanged in the new domain over time. In addition, Unity-based simulations demonstrate color-coded transformations of a projected 3D scene, illustrating how moving objects can be readily identified. This representation is straightforward, relying on simple optical flow functions. It requires only one camera, and there is no need to determine the magnitude of the camera's velocity vector. Furthermore, the representation is pixel-based, making it suitable for parallel processing.
Detecting Moving Objects Using a Novel Optical-Flow-Based Range-Independent Invariant
Oct 14, 2023This paper focuses on a novel approach for detecting moving objects during camera motion. We present an optical-flow-based transformation that yields a consistent 2D invariant image output regardless of time instants, range of points in 3D, and the speed of the camera. In other words, this transformation generates a lookup image that remains invariant despite the changing projection of the 3D scene and camera motion. In the new domain, projections of 3D points that deviate from the values of the predefined lookup image can be clearly identified as moving relative to the stationary 3D environment, making them seamlessly detectable. The method does not require prior knowledge of the direction of motion or speed of the camera, nor does it necessitate 3D point range information. It is well-suited for real-time parallel processing, rendering it highly practical for implementation. We have validated the effectiveness of the new domain through simulations and experiments, demonstrating its robustness in scenarios involving rectilinear camera motion, both in simulations and with real-world data. This approach introduces new ways for moving objects detection during camera motion, and also lays the foundation for future research in the context of moving object detection during six-degrees-of-freedom camera motion.
Visual Looming from Motion Field and Surface Normals
Oct 08, 2022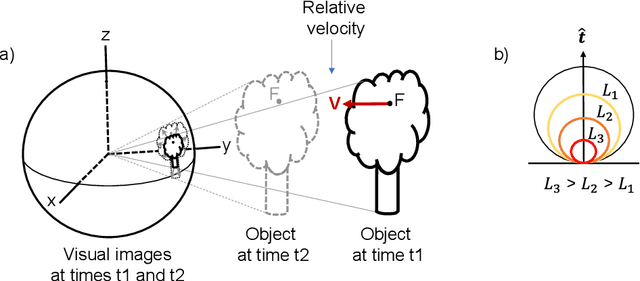
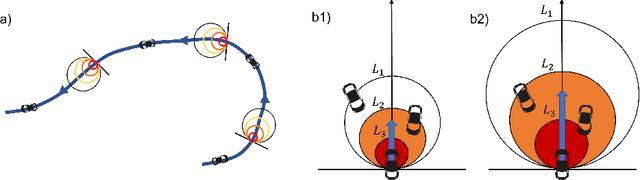
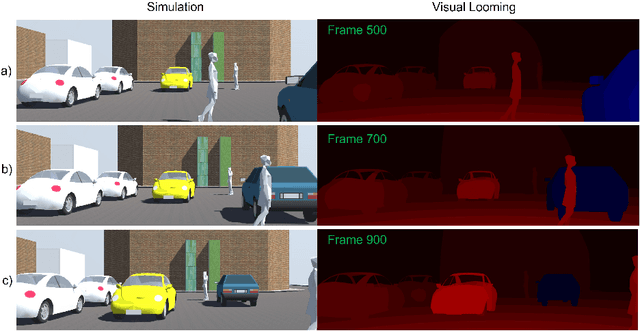
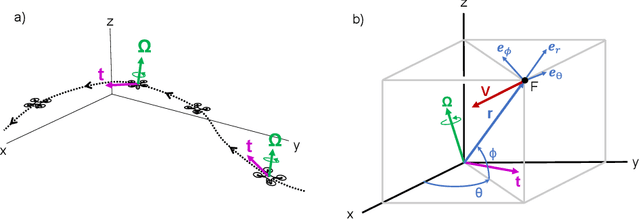
Looming, traditionally defined as the relative expansion of objects in the observer's retina, is a fundamental visual cue for perception of threat and can be used to accomplish collision free navigation. In this paper we derive novel solutions for obtaining visual looming quantitatively from the 2D motion field resulting from a six-degree-of-freedom motion of an observer relative to a local surface in 3D. We also show the relationship between visual looming and surface normals. We present novel methods to estimate visual looming from spatial derivatives of optical flow without the need for knowing range. Simulation results show that estimations of looming are very close to ground truth looming under some assumptions of surface orientations. In addition, we present results of visual looming using real data from the KITTI dataset. Advantages and limitations of the methods are discussed as well.
Estimation of Looming from LiDAR
Mar 15, 2022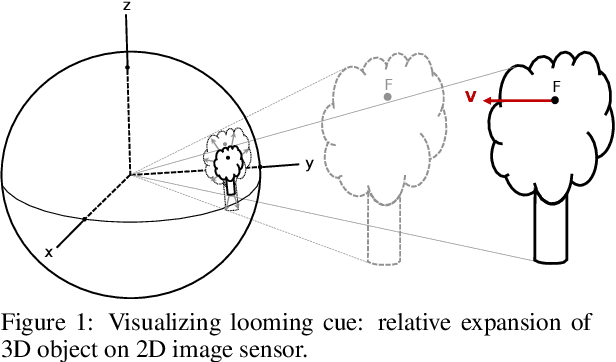
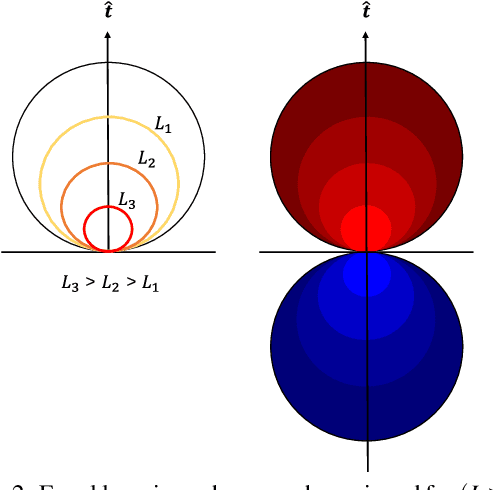
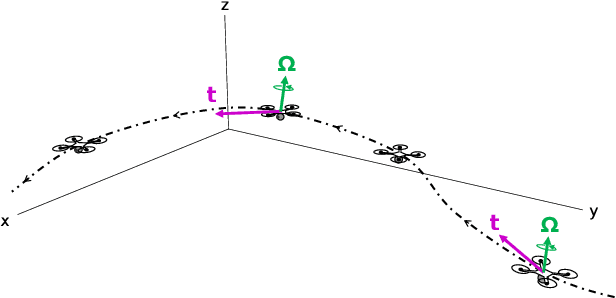
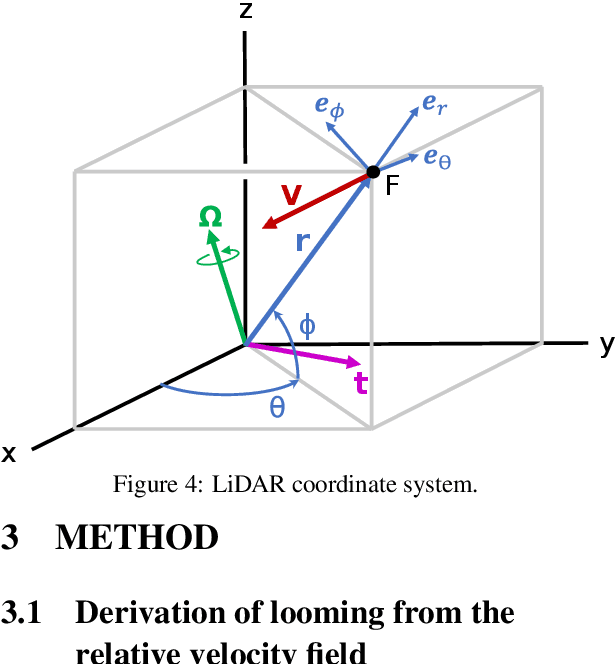
Looming, traditionally defined as the relative expansion of objects in the observer's retina, is a fundamental visual cue for perception of threat and can be used to accomplish collision free navigation. The measurement of the looming cue is not only limited to vision, and can also be obtained from range sensors like LiDAR (Light Detection and Ranging). In this article we present two methods that process raw LiDAR data to estimate the looming cue. Using looming values we show how to obtain threat zones for collision avoidance tasks. The methods are general enough to be suitable for any six-degree-of-freedom motion and can be implemented in real-time without the need for fine matching, point-cloud registration, object classification or object segmentation. Quantitative results using the KITTI dataset shows advantages and limitations of the methods.