 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-Agent Coordination through Common Operating Picture Integration
Nov 08, 2023



In multi-agent systems, agents possess only local observations of the environment. Communication between teammates becomes crucial for enhancing coordination. Past research has primarily focused on encoding local information into embedding messages which are unintelligible to humans. We find that using these messages in agent's policy learning leads to brittle policies when tested on out-of-distribution initial states. We present an approach to multi-agent coordination, where each agent is equipped with the capability to integrate its (history of) observations, actions and messages received into a Common Operating Picture (COP) and disseminate the COP. This process takes into account the dynamic nature of the environment and the shared mission. We conducted experiments in the StarCraft2 environment to validate our approach. Our results demonstrate the efficacy of COP integration, and show that COP-based training leads to robust policies compared to state-of-the-art Multi-Agent Reinforcement Learning (MARL) methods when faced with out-of-distribution initial states.
VioLA: Aligning Videos to 2D LiDAR Scans
Nov 08, 2023



We study the problem of aligning a video that captures a local portion of an environment to the 2D LiDAR scan of the entire environment. We introduce a method (VioLA) that starts with building a semantic map of the local scene from the image sequence, then extracts points at a fixed height for registering to the LiDAR map. Due to reconstruction errors or partial coverage of the camera scan, the reconstructed semantic map may not contain sufficient information for registration. To address this problem, VioLA makes use of a pre-trained text-to-image inpainting model paired with a depth completion model for filling in the missing scene content in a geometrically consistent fashion to support pose registration. We evaluate VioLA on two real-world RGB-D benchmarks, as well as a self-captured dataset of a large office scene. Notably, our proposed scene completion module improves the pose registration performance by up to 20%.
HIO-SDF: Hierarchical Incremental Online Signed Distance Fields
Oct 14, 2023



A good representation of a large, complex mobile robot workspace must be space-efficient yet capable of encoding relevant geometric details. When exploring unknown environments, it needs to be updatable incrementally in an online fashion. We introduce HIO-SDF, a new method that represents the environment as a Signed Distance Field (SDF). State of the art representations of SDFs are based on either neural networks or voxel grids. Neural networks are capable of representing the SDF continuously. However, they are hard to update incrementally as neural networks tend to forget previously observed parts of the environment unless an extensive sensor history is stored for training. Voxel-based representations do not have this problem but they are not space-efficient especially in large environments with fine details. HIO-SDF combines the advantages of these representations using a hierarchical approach which employs a coarse voxel grid that captures the observed parts of the environment together with high-resolution local information to train a neural network. HIO-SDF achieves a 46% lower mean global SDF error across all test scenes than a state of the art continuous representation, and a 30% lower error than a discrete representation at the same resolution as our coarse global SDF grid.
SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments
Sep 22, 2023



Semantic reasoning and dynamic planning capabilities are crucial for an autonomous agent to perform complex navigation tasks in unknown environments. It requires a large amount of common-sense knowledge, that humans possess, to succeed in these tasks. We present SayNav, a new approach that leverages human knowledge from Large Language Models (LLMs) for efficient generalization to complex navigation tasks in unknown large-scale environments. SayNav uses a novel grounding mechanism, that incrementally builds a 3D scene graph of the explored environment as inputs to LLMs, for generating feasible and contextually appropriate high-level plans for navigation. The LLM-generated plan is then executed by a pre-trained low-level planner, that treats each planned step as a short-distance point-goal navigation sub-task. SayNav dynamically generates step-by-step instructions during navigation and continuously refines future steps based on newly perceived information. We evaluate SayNav on a new multi-object navigation task, that requires the agent to utilize a massive amount of human knowledge to efficiently search multiple different objects in an unknown environment. SayNav outperforms an oracle based Point-nav baseline, achieving a success rate of 95.35% (vs 56.06% for the baseline), under the ideal settings on this task, highlighting its ability to generate dynamic plans for successfully locating objects in large-scale new environments. In addition, SayNav also enables efficient generalization of learning to navigate from simulation to real novel environments.
Pixels to Plans: Learning Non-Prehensile Manipulation by Imitating a Planner
Apr 05, 2019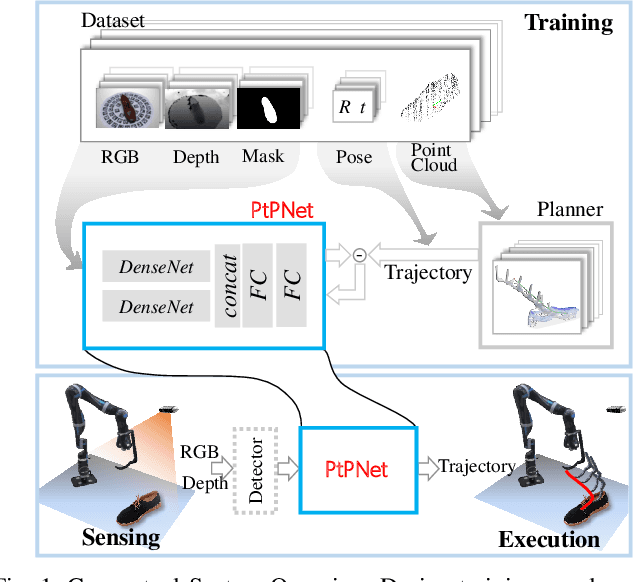
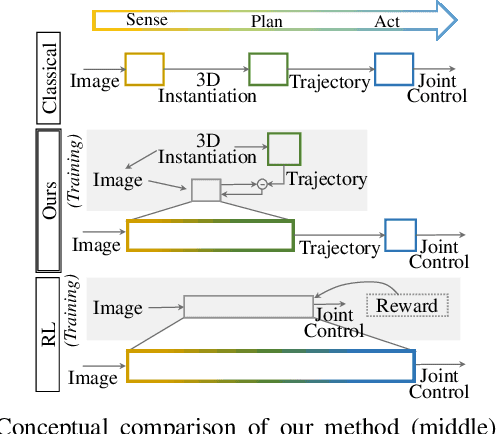
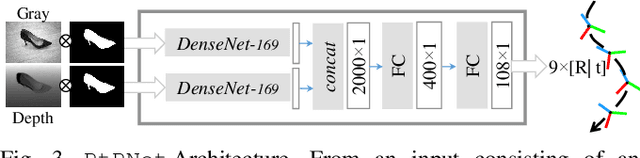
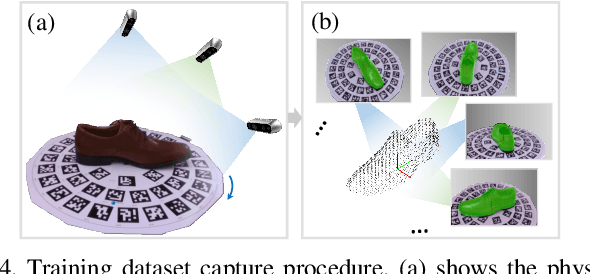
We present a novel method enabling robots to quickly learn to manipulate objects by leveraging a motion planner to generate "expert" training trajectories from a small amount of human-labeled data. In contrast to the traditional sense-plan-act cycle, we propose a deep learning architecture and training regimen called PtPNet that can estimate effective end-effector trajectories for manipulation directly from a single RGB-D image of an object. Additionally, we present a data collection and augmentation pipeline that enables the automatic generation of large numbers (millions) of training image and trajectory examples with almost no human labeling effort. We demonstrate our approach in a non-prehensile tool-based manipulation task, specifically picking up shoes with a hook. In hardware experiments, PtPNet generates motion plans (open-loop trajectories) that reliably (89% success over 189 trials) pick up four very different shoes from a range of positions and orientations, and reliably picks up a shoe it has never seen before. Compared with a traditional sense-plan-act paradigm, our system has the advantages of operating on sparse information (single RGB-D frame), producing high-quality trajectories much faster than the "expert" planner (300ms versus several seconds), and generalizing effectively to previously unseen shoes.